1. 引言
BP神经网络是一种多层前馈网络,算法以梯度下降为基础,主要特点是信号的前向传递及误差的反向传播,其拓扑结构由通过权值、阈值相关联的输入层、隐含层、输出层构建。随着模型预测应用的发展,BP神经网络开始用来解决越来越复杂的工业数据拟合问题,算法局限性也越来越凸显。因此必须设计一种高效的优化方法,来代替经验操作,以找到网络结构及关联参数的最优组合。
作为人工智能领域的一个重要分支,遗传算法在整体搜索和优化计算方面不依赖于梯度信息,其高度的全局寻优能力更适用于大规模并行分布处理场景。但需注意的是,在与BP神经网络有机结合中,必须对传统遗传算法的编码及解码规则进行改进,以应对在同时优化网络结构及初始参数时,权值及阈值个数因为隐含层节点数发生改变而造成的编码染色体长度变化的问题 [1] [2] [3]。
2. BP神经网络及遗传算法概述
2.1. BP神经网络相关概述
根据映射定理可知,单隐含层BP神经网络可以通过调整各设定参数在任意
平方误差范围内对目标函数进行逼近。所以在处理实际问题时,设计单隐含层的BP神经网络在理论上便可以满足应用需求,其空间结构最终只与隐含层节点数相关。
如图1所示为典型的单隐含层BP神经网络拓扑结构图,其中n为输入层节点数,
是神经网络的输入;m为输出层节点数,
是神经网络的预测输出;
和
为神经网络的权值,
和
为隐含层及输出层的阈值。
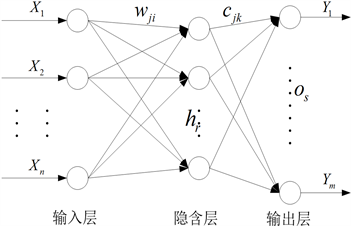
Figure 1. Topological structure of BP neural network with single hidden layer
图1. 单隐含层BP神经网络拓扑结构图
设 为初始设定的最大隐含层节点数,则有表1所示权值、阈值个数关系。

Table 1. The number of weights and thresholds
表1. 权值、阈值个数
2.2. GA遗传算法相关概述
遗传算法是对自然进化过程的模拟,它的基本原理是将问题的解映射到遗传空间的染色体基因上进行操作,进而寻求问题的解 [4],由此整理出GA算法的数学模型为式(1)所示:
(1)
式中,c为编码及解码规则;f为适应度函数,是遗传算法在进化搜索中的唯一依据,用以评价一个解的好坏;P0为初始总群,初始化种群为随机产生的种群规模为P的初始个体,既P个染色体;s为选择操作、j为交叉操作、b为变异操作;t为停机条件。既根据设定的条件终止算法的运行并输出最终的结果,可以是迭代次数,也可以是个体适应度值等其它设定条件。
3. 决策基因式遗传算法建模
3.1. GDGA的编码及解码
在编码及解码时,需将表1所示关系考虑在内 [5]。本课题中GDGA构建的染色体编码第一部分由二进制字符串构成,其包含的遗传信息就是隐含层节点数,称之为决策基因;对于权值、阈值取值如果使用二进制编码,会显得十分冗长,且其解码后在步进区间、精度很低 [6],所以第二部分包含权值、阈值取值遗传信息的编码由实数字符串构成,如图2所示。
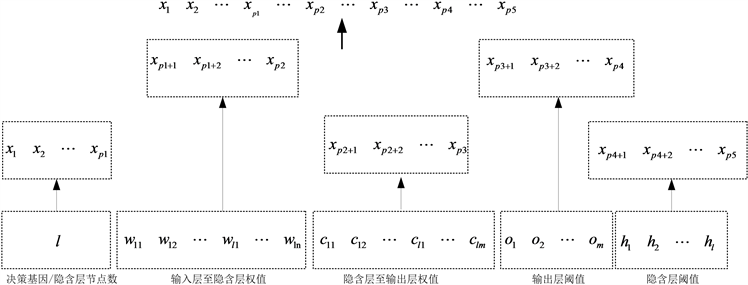
Figure 2. Schematic diagram of hybrid coding rules
图2. 混合编码规则示意图
为方便编码,此时可令式(2)成立:
(2)
p1取正整数,p2、p3、p4、p5的取值与p1相关,关系参考表1。设隐含层节点数解码后值为
,则有:
(3)
在进行最终的解码前,必须按照一个映射关系进行预解码,以克服隐含层节点数对染色体长度的影响。本课题引入决策算子的概念,来对这种映射关系进行建模。
根据式(3)进行决策基因解码后得到
,可知区间
内的隐含层节点不参与建模,结合图2,染色体中的基因有式(4)所示映射关系,即为决策算子。
(4)
3.2. 染色体的锁存及调用
在一个遗传算法流程内,染色体在进行决策算子操作后,其表征权值及阈值部分的基因会根据决策算子置零无用的遗传信息,在满足停机条件前的每一次循环迭代内,被归零的遗传信息都需复原以遗传给下一迭代个体,所以对这些染色体都需进行一次“备份”,目的是在下一次可以方便的进行调用。
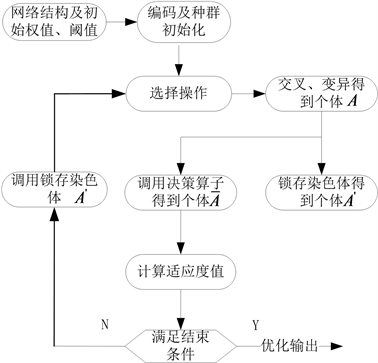
Figure 3. Flow chart of decision genetic algorithm
图3. 决策基因式遗传算法流程图
针对此问题,本文在传统GA算法流程上增加染色体的锁存及调用操作。假设进行交叉、变异操作后的个体为A,则令个体
,
即为锁存的染色体,在下一次迭代前,调用
即可复原所有被置零的遗传信息,而个体A的遗传信息则会在决策算子操作后被个体
所覆盖,如图3所示。
3.3. 算法自适应改进
1) 适应度函数
在一般遗传算法中,适应度函数可以取误差平凡和的倒数,如式(5):
(5)
其中r为测试集的样本个数;
为模型输出的预测值;
为测试集的期望值。显然误差平凡和越小,适应度值越大。对于隐含层节点数多的网络,其前期进化较快,且在相同的约束条件下,本课题更期望获得一个结构简单的网络,所以对适应度函数增加指数系数,如式(6)所示:
(6)
其中,
为当前隐含层节点数与最大隐含层节点数的比值,作为强制系数,当适应度值F差不多大小时,当前隐含层节点数越小,
越小,
就越大,该个体被选择的可能性亦随之增大。
2) 交叉、变异操作
假设种群中两个配对个体为a、b,易知决策基因部分只需采用单点交叉及变异即可,而实数编码部分的初始权值及阈值则可做自适应改进。
A、交叉操作。采用非一致交叉,并引入自适应参数,如式(7)、(8)所示。对参数
进行了指数变化,
、
分别为个体a、b的适应度值,在进化初期,
较小,参数值
较大,算法的搜索空间也相应较大;在进化后期,
较大,参数值
较小,则可以驱使种群在最优点附近聚集 [7]。
(7)
(8)
B、变异操作。其变异率如式(9):
(9)
式中
为要变异个体
的变异率,
;k为
之间的常数,
为种群中最大的适应度,
是要变异个体的适应度,
是种群的平均适应度。规定区间
,
、
取值如式(10)、(11)所示:
(10)
(11)
在区间
中任意取
代替
完成变异操作,
、
为该基因编码时规定的取值上下限。
4. 工程应用
4.1. 干熄焦烧损率及数据获取
干熄焦(coke dry quenching)是一种通过循环气体的换热作用将进入干熄炉的炽热焦炭冷却后排出的系统,烧损率作为评价该系统的一个重要经济参数,是焦炭在干熄炉内因氧化、碳溶等反应造成的质量损失的量化数据 [8]。若能准确的预测烧损率的数值并做相应的工艺控制,可以创造巨大的效益。干熄焦烧损率定义公式如式(12)所示,其中
为统计时间内平均烧损率,%;
为统计时间内入干熄炉前焦炭计量值;
为统计时间内干熄炉排出焦炭累计值。
(12)
根据工艺原理挑选18组输入数据如表2所示。本课题的数据采集自铜陵某焦化厂190 t/h干熄焦现场,剔除失真数据后,选取1000组作为训练集数据,200组作为测试集数据。
4.2. 仿真对比
输入输出层参数已确定,根据经验公式,一般在区间[4, 15]内取隐含层节点数建立单隐含层BP神经网络,考虑到GDGA的编码方式,结合式(2),取隐含层最大节点数15,GDGA优化后节点数为9。为了对比突出算法优化的有效性,取隐含层节点数2、9、14分别建立BP神经网络进行训练,设定迭代次数500,目标误差0.001,训练周期如表3所示,其中BP-2模型在迭代500次后未收敛至误差范围之内,未统计。
Table 3. Training period of different network models
表3. 不同网络模型的训练周期
从表中可以看出,GDGA-BP模型训练周期最短,其次是具有相同网络结构的BP-9模型。以测试集分别对BP-4、BP-9、BP-14、GDGA-BP模型进行测试,其预测结果如图(4)所示,可见GDGA-BP模型的输出最贴近期望输出,误差最小。
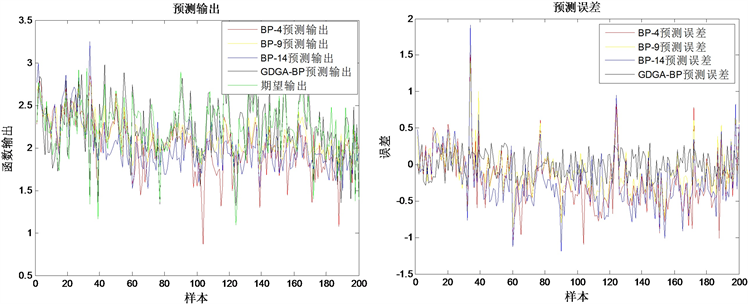 (a) 预测输出 (b) 预测误差
(a) 预测输出 (b) 预测误差
Figure 4. Matlab simulation verification
图4. MATLAB仿真验证
为了更直观的展示几个模型的拟合能力,选择预测输出与期望的平均绝对误差、均方误差、均方根误差和平均百分比误差来评价模型,评价结果见表4。
Table 4. Simulation error calculation results
表4. 仿真误差计算结果
通过仿真误差计算结果对比可以看出,GDGA-BP模型具有更快的收敛速率及预测精度,算法性能更加优越。
4.3. 工艺试验
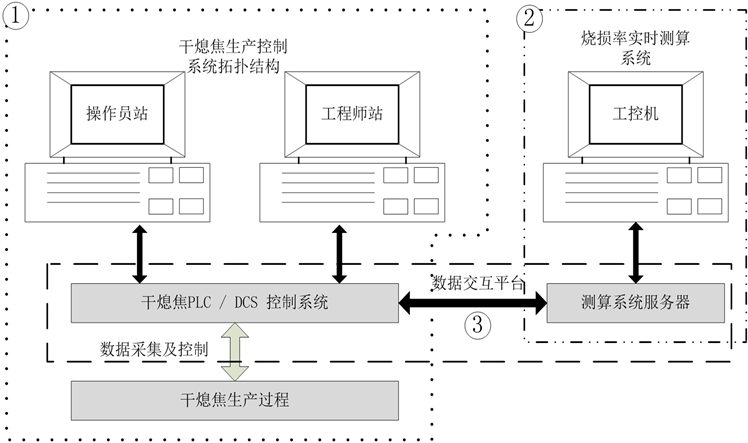
Figure 5. Hardware implementation diagram
图5. 硬件实现示意图
为验证建立的GDGA-BP模型对生产工艺的指导作用,搭建硬件实验平台如图5所示。图中①为干熄焦集中控制系统,②为烧损率测算系统,其由上位机及服务器构成,储存、运算预测模型,③为数据交互设施。实验平台实物如图6所示:

Figure 6. Physical drawing of hardware platform
图6. 硬件平台实物图
实验平台搭建完成后,通过数据交互,将预测值显示在干熄焦中控上位机画面上,提供给操作人员参考。为验证模型的实用性,使用两组数据进行对比,对比结果见图7(a):第一组为红色数据,既观测到但未进行工艺调整的数据,均值为2.06%;第二组为绿色数据,既观测到且进行工艺调整的数据,均值为1.63%。两组数据都为每分钟记录一次,共240组。
 (a) 预测性能示意 (b) 差值
(a) 预测性能示意 (b) 差值
Figure 7. Comparison chart of model application data
图7. 模型应用数据对比图
由图可见,调整过后的烧损率数值明显低于未调整的观测值,绿色线的波动更加频繁便是工艺调整带来的影响。图7(b)为调整值与观测值的差值曲线,其平均值为−0.43,既在该统计对比时段内烧损率平均降低了0.43%。
5. 结论
通过对BP神经网络隐含层节点数及权值、阈值关系的分析,提出了基于决策基因的遗传算法并构建了GAGD-BP神经网络模型。仿真实验结果表明,该算法可同时优化BP神经网络的结构及初始权值、阈值,有效提高BP算法的性能。在干熄焦烧损率测算的硬件实验中,该模型亦实时、准确的测算出了烧损率的数值并指导工艺操作降低了焦炭燃烧损失。
另外在模型的训练过程中,有过拟合的现象出现,这是因为在输入层变量的选择中,只参考了工艺原理,不可避免的引入了一些无关变量,且变量之间不相互独立。如何有效的对输入变量进行筛选,并应用到GDGA-BP模型中亦是下一个研究方向。
基金项目
国家重点研发计划:2019YFC1908004。