1. 引言
随着城市化进程的加快和经济的飞速发展,城市人口不断增长,伴随着城市交通量也急剧增加,这给城市交通系统带来了巨大的压力。城市道路容量和交通流量的不平衡引起了严重的交通拥堵,严重影响了城市的发展和居民的日常生活 [1]。交通拥堵会造成能源消耗、环境污染和降低城市运营效率,解决交通问题是政府和人民面临的重要挑战。实时、准确地识别与评估城市交通状态能够科学管理城市交通系统和引导居民出行。
近年来,交通拥堵问题引起了许多国内外学者的兴趣,他们对此已经做了大量的研究工作,这些研究工作分为理论研究和应用研究,理论研究主要包括交通状态评价指标的研究,应用研究主要是交通状态识别及交通流量预测。国内外学者针对识别交通状态和评价交通系统的交通评价指标做了多方面的探究。Anjaneyulu等研究了各类速度指标与交通流量之间的关系并选择了车速变异系数作为拥堵指标识别交通拥堵情况 [2]。Litman等分析了影响交通拥堵成本的各种因素,总结了包括服务水平、行程时间、平均速度、平均通勤时间、拥堵持续时间、延误时间等交通拥堵评价指标,提出了各种减少拥堵的策略 [3]。黄艳国等根据城市路网拓扑,通过仿真实验,验证了交通状态判别指数模型的有效性 [4]。另外,世界各国根据自己国家的道路交通状态,制定了不同的交通状态评价体系。美国的许多大城市面临严重的交通拥堵问题,基于道路服务水平,美国道路状态评价指标根据平均行程速度、车辆流量与通行能力的比值以及负荷系数等三个指标分为6种 [5]。我国制定了《城市交通运行状态评价规范》,采用基础性指标(平均交通流量、平均行程速度等)、特征性指标(行程时间比、延误时间比等)及综合性指标(拥堵里程、行程时间等)等作为交通运行状态的评价指标 [6]。
准确识别城市的交通状态是缓解和解决交通拥堵的前提。大数据、云计算、物联网等计算机技术的迅速发展,为我们识别交通状态提供了新思路和新途径。An等提出了一种基于网格级拥堵检测方法,该方法包括拥堵检测、反复拥堵检测及反复拥堵的演化过程等三个步骤,并应用哈尔滨市实地采集的GPS轨迹数据对该方法的有效性进行了验证 [7]。何兆成等构建道路状态判断模型,提出城市区域交通状态模式识别与分类方法,以广州市出租车数据为例,研究分析了城市交通状态分布特性 [8]。基于GPS轨迹数据、道路网络和POI数据,Wang等提出了一种三个阶段的预测框架,以探讨路段之间的拥堵相关性 [9]。研究结果表明道路拥堵具有明显的方向性和传递性。熊励等构建了基于神经网络的城市拥堵识别模型,以上海部分区域的交通数据集为例验证了模型的有效性 [10]。Guo等根据路网拓扑和交通流量建立动态有向加权复杂网络模型,提出了基于社团划分的城市交通网络动态拥堵预警方法,并实证研究了济南市交通网络 [11]。以城市多源数据为基础,Song等结合K-均值聚类和城市地理信息挖掘城市交通拥堵的时空模式,确定影响交通拥堵的关键因素,其研究结果能够识别潜在交通拥堵路段,并有助于指导城市土地使用的规划 [12]。以淮安市的出租车轨迹数据为基础,黄子赫等提出了基于密度聚类方法的道路拥堵识别算法,通过出租车运行情况识别城市道路拥堵状态,并对拥堵程度进行区分 [13]。
然而,在现有交通状态识别问题研究中,绝大部分研究都是从车流量、路段平均速度、延误时间、行程时间等单一要素出发,没有综合考虑多个相关要素对城市交通拥堵的影响,使得对城市交通状态的识别结果不能准确反映其交通状态。另外,出租车GPS轨迹数据包含大量的连续型时空轨迹数据集,它是城市大数据的重要组成部分,为我们研究城市交通网络动态特征提供了有效数据。为了更准确地识别城市交通拥堵状态,本文以车辆GPS大数据为基础,结合主成分分析和核模糊C均值聚类方法,构建基于多个交通要素的城市交通状态识别模型,并对兰州市交通状态进行实证研究。
2. 综合交通状态评价指标体系建立
2.1. 交通状态评价指标的选择
在文献 [2] [3] [4] [5] [6] 中讨论了多种交通状态评价指标。如果仅采用一种指标进行交通状态评估,结果可能存在一些偏差,但若选择的指标参数太多,则会增加计算复杂度并且难以平衡指标间的关系。选取评价指标遵循原则是用较少的指标将城市交通状态较为全面、精确地刻画和反映出来。基于这一原则,本文选择路段平均速度、交通流密度、行驶时间指数、拥堵指数和车道占有率等五个指标综合评价城市交通状态。
2.1.1. 路段平均速度
路段平均速度是指给定时间段内,某路段上所有行驶车辆的速度平均值。
(1)
其中,
是指给定时间段内第j条道路路段上行驶的第i辆车辆;N表示该时间段内第j条道路路段上所有车辆总数。
2.1.2. 交通流密度
交通流密度是指给定时间段内,某路段单位长度上的车量数。
(2)
其中,
表示某时间段内第j条道路路段上的车流量数;
是指第j条道路路段的路段长度。
2.1.3. 行驶时间指数
行驶时间指数表示为给定时间段内路段上车辆实际行驶时间与自由流行驶时间的比值。
(3)
其中,
表示第j条道路路段车辆实际行驶所需时间;
表示第j个路段在自由流条件下所需行驶时间。
2.1.4. 拥堵指数
拥堵指数是车辆行驶延误时间与自由流行驶时间的比值:
(4)
其中,
表示第j条道路路段车辆实际行驶所需时间;
表示第j个路段在自由流条件下所需行驶时间。
2.1.5. 车道占有率
车道占有率指给定时间段内所有车辆在某路段上的实际行驶时间之和与给定时间的百分比率:
(5)
其中,
表示在观测时间段内第j条道路路段上第i辆车的行驶时间;N表示在观测时间段内通过第j条路段的车辆总数;
表示观测时间段。
2.2. 指标权重的构建
基于上述五个交通拥堵评价指标,我们建立综合交通状态评价指标体系,但这些指标在评价模型中的重要程度不同,通过权重反映了各指标在多属性评价模型中所起的作用。因此,我们需要确定各类指标在评价模型中的权重。与主观权重法相比较,基于主成分分析的客观赋权法 [14] 克服了主观赋权法在指标权重选择上的主观因素影响,该方法确定的权重客观反映了指标间的真实关系,既能体现出评价指标的相对重要性,也能反映出指标间的差异性。本文采用该方法确定交通拥堵状态识别模型中各指标权重。基于主成分分析的客观赋权方法的具体步骤为:
1) 给定数据集
,其中
,n为样本总数,l为样本的特征个数。建立数据集
的相关系数矩阵
。计算相关系数矩阵
的特征值
以及各特征值对应的特征向量
。主成分载荷系数矩阵表示为
。
2) 计算各个主成分的贡献率
和累积贡献率
。
3) 选取累积贡献率 ≥ 85%的前p个主成分。计算各指标在选取的p个主成分组合中的系数:
,其中
。
4) 计算各指标权重:
,然后对指标权重归一化得:
,其中
。
2.3. 基于核模糊C均值聚类的交通状态识别模型
模糊聚类是以模糊理论为基础对数据进行分类的一种无监督机器学习算法。核模糊C均值聚类算法 [15] (kernel-based fuzzy C-means clustering algorithm, KFCM)应用最广泛模糊聚类算法之一,它基于隶属度和聚类中心建立目标函数,通过对目标函数的优化迭代,计算聚类中心和隶属度,直到目标函数收敛迭代停止,样本数据分类完成。该算法通过核函数将原始空间中的点映射到高维特征空间中,将原本线性不可分的数据变成线性可分或近似线性可分,能够克服了FCM算法的不足之处。
给定数据集
,设k为分类数目,
为每个聚类的中心,
是第i个样本对应第j类的隶属度函数,b为指数权重因子,将
通过非线性特征映射到高维线性空间,则在高维特征空间下的目标函数和约束条件为:
(6)
(7)
其中,
和
分别表示
与
在高维空间中的像:
(8)
高斯核函数由于其所对应的线性空间是任意维数,映射的问题线性可解,被应用的最为广泛,其定义为:
(9)
将(9)代入(8)得:
(10)
从而得到KFCM更进一步的目标函数,即:
(11)
根据核函数特征空间与内积的关系式可推导出KFCM算法的聚类中心和隶属度函数公式为:
(12)
(13)
通过迭代不断求解(12)式和(13)式,直至公式(11)收敛,得到最优解。
模糊C均值聚类的缺点是聚类个数人为确定,这导致确定聚类个数具有较强的主观性,为了避免这个问题,本文采用吸引力传播聚类算法 [16] (Affinity Propagation Clustering, AP)确定最佳聚类个数。AP算法通过计算数据点之间的两种信息,即吸引信息和归属度信息,并不断迭代更新吸引信息矩阵和归属度信息矩阵,直到选出N个聚类中心且结果保持不变,并确定每个数据点与聚类中心的归属关系后算法结束。该算法能自动算出最佳聚类数而不需要在运算之前确定聚类的个数,因此是计算最佳聚类数目的常用方法之一。本文采用AP算法确定最佳聚类个数。

Table 1. Traffic state recognition model based on kernel-based fuzzy C-means clustering
表1. 基于核模糊C均值聚类的交通状态识别模型
本文基于核模糊C均值聚类的交通拥堵识别算法的基本步骤为:1) 根据数据集,采用主成分分析客观赋权法确定各个评价指标的权重;2) 对样本数据进行核模糊C均值聚类并得到聚类结果;3) 定义并计算综合评级指标
,其中
为指标权重,
,
为聚类中心;4) 根据
的值确定城市交通状态的等级。具体算法如表1所示。
3. 实验结果及分析
3.1. 研究区域
兰州市是甘肃省的省会城市,地处中国西北,是典型的带状组团式结构,城区主要坐落于河谷地狭长的地带内。受南北两山限制,交通拥堵在这个河谷型城市变得越来越严重。兰州是2019年中国十大拥堵城市之一 [17]。本文以兰州市主要城区——城关区、七里河区、安宁区和西固区这四个区域为研究对象,该区域中含有227条道路,1022个路段。
3.2. 数据集
本文数据集是2017年3月6日到2017年3月12日兰州市出租车的GPS轨迹数据。该数据集是连续7天的数据,具有一定的代表性,恰好体现了工作日和休息日的城市交通状态和居民出行规律。GPS轨迹数据主要包含车辆ID、经度、纬度、瞬时速度、记录时间、行驶方向和车辆载客状态等信息,轨迹点采样间隔时间最大为30 s。
在使用前对原始GPS数据需预处理,首先,清理原始GPS数据中的冗余值,并通过地图匹配识别方法,剔除区域边界外和不在路网上的离群点和异常值,应用线性插值方法对缺失值进行补充;然后,通过MNTG [18] (Minnesota Traffic Generator)获得兰州市主城区路网拓扑信息;最后,采用几何特性的方法对出租车轨迹数据和路网拓扑进行匹配,获得有效的数据集。
3.3. 城市整体交通状态评估
由于各个交通状态评价指标数据量纲不同,在建模之前,我们先对其进行标准化处理来统一这些交通指标量纲。假设某交通评价指标
,
,
,标准化公式为
,经过数据标准化后,每个交通评价指标都是具有相同尺度的无量纲量。数据分析之后,如果需要评价指标的真实值,可采用反标准化方法得到,反标准化公式为
。本文中在进行核模糊C均值聚类算法的过程中,我们设定参数取值分别为指数权重因子
,收敛精度
,高斯核函数参数
。
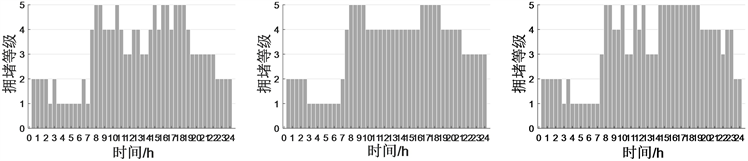 (a) 周一 (b) 周二 (c) 周三
(a) 周一 (b) 周二 (c) 周三 (d) 周四 (e) 周五 (f) 周末
(d) 周四 (e) 周五 (f) 周末
Figure 1. The overall traffic status of Lanzhou on weekdays and weekend
图1. 兰州市工作日和周末的整体交通状态
我们以30分钟为时间间隔,对周一到周日每天24小时的交通基础数据进行统计,计算城市路网每个路段的各个交通状态评价指标均值,建立城市交通状态识别模型,本文在实验部分采用AP算法,分别对兰州市周内连续五个工作日和周末的交通数据集进行最佳聚类个数确定,我们发现最佳聚类个数基本分为五类,只有周二的数据集的最佳聚类个数划分为四类,再结合我国《城市交通运行状况评价规范》 [6],最终将兰州市交通状态划分为五个等级,这五个等级分别对应畅通(1级)、基本畅通(2级)、轻度拥堵(3级)、中度拥堵(4级)和严重拥堵(5级),五个等级的综合评级指标值对应区间分别为
,
,
,
和
。图1为兰州市周内连续五个工作日和周末的交通状态。
根据图1可知,在7:30~22:00时间段内,城市拥堵状态转换频繁,但路段基本处于拥堵状态,而且中度拥堵和严重拥堵状态较多,说明城市道路在一天内交通流量都比较大,该结果与兰州是中国十大拥堵城市之一的结论一致。另外,工作日和周末城市交通状态有区别,工作日的7:30~8:30,17:00~19:00时段拥堵级别为严重拥堵,说明这两个时间段路段拥堵状况最为严重,与工作日的早晚上下班、上学放学的高峰期契合,另外,工作日的交通拥堵状态相比周末拥堵状态更严重。和工作日相比较,周末的交通高峰时段大约是10:30~11:00和13:30~19:00。这是由于周末上班族和学生休息,故没有明显早高峰,居民出门较晚,故第一个高峰时段是10:30~11:00,第二个高峰时段是午饭之后,居民出门逛街娱乐,即13:30~18:30。实验结果与城市居民的出行特征相符。
 (a) 工作日 (b) 周末
(a) 工作日 (b) 周末
Figure 2. Proportion of road sections with different congestion levels within 24 hours during the weekdays and weekend
图2. 工作日和周末24小时各拥堵等级路段占比
由图1可知,城市交通状态在工作日呈现相似状态,但工作日和周末的交通状态明显不同,我们分别计算各个路段工作日和周末的平均交通统计量,用识别算法识别各路段的交通状态,分析不同时间段内呈现五种交通状态的路段的比例。实验结果如图2所示。
由图2(a)可知,工作日7:30~9:00和12:00~20:00的时段内,严重拥堵和中度拥堵路段的比例较大,接近30%。比较图2(a)和图2(b),我们发现和工作日相比,周末畅通路段比例较大,发生中度以上拥堵的时间段有差异,与图1结果一致。工作日和周末的畅通和基本畅通路段的比例大约都是50%,这个和工作日的比较接近。不论是工作日还是周末,从早晨7:00到晚上23:00,轻度、中度和严重拥堵比例之和都接近50%,这再次说明兰州市确实为全国十大堵城之一。
3.4. 路网交通状态动态演化及可视化
通过48个交通状态快照图,可观察城市各个路段24小时的交通状态随时间的演化特征。由于篇幅所限,我们分别选择工作日和周末的几个典型时段做分析。
图3工作日六个时段(5:30~6:00,6:00~6:30,7:30~8:00,8:00~8:30,18:00~18:30,18:30~19:00)的交通状态的可视化,其中7:30~8:30和18:30~19:00对应工作日的早高峰和晚高峰时段。由图3(a) (b)与图3(c) (f)比较可知,5:30~6:00和6:00~6:30道路交通状态良好,部分路段呈现轻度拥堵。在早高峰和晚高峰时段,中度拥堵和严重拥堵的道路路段激增,许多区域出现交通拥堵现象。从区域来看,四个城区中,城关区拥堵路段最多,其次为七里河区,安宁区交通状态最好。城关区主要交通拥堵区域西起解放门立交桥,东至瑞德大道,在早高峰和晚高峰时段,这些区域内的道路大部分都是中度拥堵和严重拥堵。该结果与兰州市城市功能区域分布特征一致。兰州市的中心区是城关区。城关区是甘肃省的政治中心和文化中心,是党、政、军机关驻地,兰州市主要商圈都分布在城关区中心地带。另外,该区域常驻人口密度大,使得该区域交通流量比较大。在七里河区,西起柳家营什字,东至解放门立交桥的西津路是主要拥堵路段,该路段经过了西站什字、兰州中心、小西湖等主要商圈。安宁区在高峰期仅有个别路段拥堵,这些路段基本都位于中小学周边,拥堵时段基本与学校上学、放学时间同步。另外,安宁区是科教文化中心,区域内19所高等学府和科研院所,该区域没有大型商圈、大中型企业和政府职能部门,常驻人口中学生占一半,所以,人口流动较小,区域内交通状态比较好。
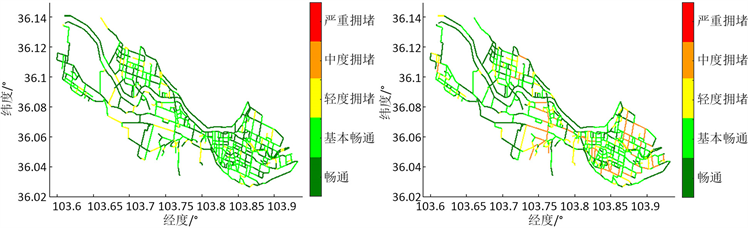 (a) 5:30~6:00 (b) 6:00~6:30
(a) 5:30~6:00 (b) 6:00~6:30 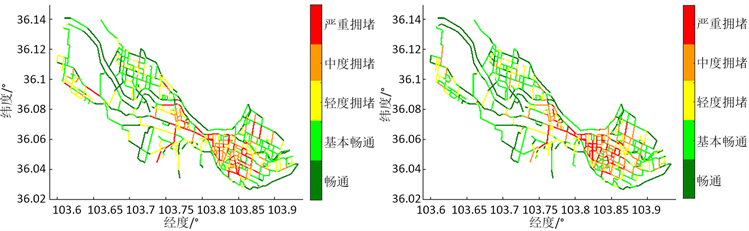 (c) 7:30~8:00(d) 8:00~8:30
(c) 7:30~8:00(d) 8:00~8:30 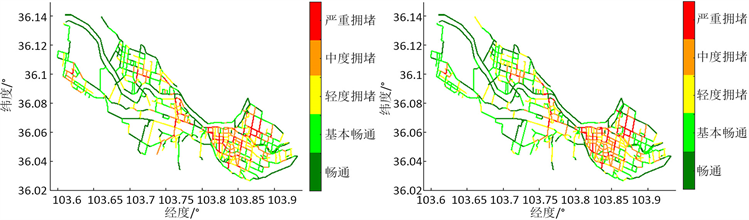 (e) 18:00~18:30 (f) 18:30~19:00
(e) 18:00~18:30 (f) 18:30~19:00
Figure 3. Visualization of traffic status at different periods of working days
图3. 工作日不同时段的交通状态可视化
图4周末四个时段(7:30~8:00,8:00~8:30,18:00~18:30,18:30~19:00)的交通状态的可视化。显然,7:30~8:00和8:00~8:30两个时段并非周末的高峰期,交通状态良好,部分道路轻度拥堵,仅有少量道路中度拥堵。18:00~18:30和18:30~19:00是周末的交通高峰期,中度拥堵和严重拥堵的路段较多,但是,和工作日相比较,周末高峰期的交通状态略好。
4. 结论
本文建立了基于多指标的交通状态评价体系,以城市交通大数据为基础,采用主成分分析赋权方法确定各个指标的客观权重,用于刻画每个指标对交通状态的影响力。根据交通状态的模糊特性,采用核模糊C均值聚类算法对交通状态进行分类识别,并以兰州市出租车GPS数据为基础,实证研究了兰州市的城市交通状态的分布特征和演化特征。研究结果表明,兰州市交通状态分为5个等级,在7:30~22:00的时段内,城市交通整体上呈现拥堵状态,拥堵程度与居民出行特征相符合。拥堵路段空间分布有较大差异,集聚特征比较明显,经常性拥堵路段出现在白银路、麦积山路、甘南路、南滨河路、中山路、平凉路,晏家坪路以及西津路等。
城市交通状态及演化规律研究,能够提供城市路网中拥堵路段的时空分布信息,可为居民出行提供指引,为城市交通管理和有效控制提供科学依据。但本文仍存在一些不足,出租车仅是城市众多交通方式的一种,难以全面反映城市整体交通状态。今后考虑增加地铁、公交以及共享单车等多源交通大数据,用于挖掘更具普适性、更深层次的城市交通的时空动态演化规律。
 (a) 7:30~8:00 (b) 8:00~8:30
(a) 7:30~8:00 (b) 8:00~8:30 (c) 18:00~18:30 (d) 18:30~19:00
(c) 18:00~18:30 (d) 18:30~19:00
Figure 4. Visualization of traffic status at different periods of weekend
图4. 周末不同时段的交通状态可视化
基金项目
本论文得到国家自然科学基金(No. 71761031)资助。