1. 引言
城市区域性质 [1] 指的是将城市进行区域划分,并根据不同区域在社会发展中起到的不同作用来定义区域性质。例如,该区域大部分为小区住宅,则该区域属于居住用地。本文将区域性质划分为四大类,分别是居住用地、商业用地、公共服务用地和科教园区。将城市区域按照不同的性质进行划分,可以更好地针对不同时间段进行交通规划,提升交通路线的利用率和通行率。此外,不同性质的区域之间的车辆通行率会根据时间变化而变化,而且存在非常明显的周期性,因此,可以在不同时间段内,通过对公共交通进行调度,提升公共资源的利用率,降低空车转移率,从而使得公共交通资源的使用更加规律化、高效化、人性化。
1.1. 空车转移率与城市区域性质的关系
交通状况是反映生产生活方式是否健康有序的关键特征。本文通过对与城市交通网络 [2] 相关的大量数据集进行分析后发现出租车的数据为研究基于空车转移率的城市功能区性质提供了一个基本思路。空车转移率(其取值范围为[0, 1])是指出租车在没有乘客的情况下从一个区域行驶到另一个区域的概率。它可以反映一个城市出租车的多样化驾驶条件,为基于出租车流向的城市功能区划分提供了有力的数据支持。空车转移率不仅反映了乘客驾驶出租车的数量,而且还反映了一个地区潜在的生产和生活规律。由于空车转移率会随着时间的变化而变化,所以,根据两个区域之间不同时间段的空车转移率的情况可以判别出两个区域的性质。同样,可以根据时间和两个区域的性质来预测两个区域间的空车转移率。
1.2. 贡献
基于上述研究,我们引入了一个时空模型来捕捉数据集空间相关性和时间依赖性的特征。此外,根据空车的转移率和人们的出行习惯,对数据集进行清洗生成具有明显特征的数据集,可以很大程度上实现预测各种类型城市功能区的任务。我们工作的主要贡献如下:
· 针对城市区域性质划分的问题,本文提出了AttSTFN模型,该模型将城市区域性质划分与出租车空车转移率数据集相结合,利用了城市区域性质划分与出租车空车转移率之间的规律性和周期性,提高了城市区域性质划分的速度和准确率。
· 本文对出租车空车转移率进行了数据设计和应用,通过对数据集进行清洗,删除部分噪声数据,从而使得所选数据集更加符合人们日常出行习惯和空车转移率周期性变化,提升了模型的普适性。
· 本文将传统递归神经网络、编码器–解码器和几个典型的时空模型作为基线来验证本文模型的性能,通过多种不同评估参数的对比结果可以看出,本文模型在城市区域性质划分问题上的实验结果要优于现有基线的划分结果,本文模型在区域性质划分的准确性和稳定性方面更具优势。
2. 相关工作
在已有的城市区域性质判别方法中,基本上是采用传统的统计学方法来实现城市功能区的判别和划分。2017年,丁秋林等人基于城市用户手机上网流量数据,以城市基站为研究对象,从多个角度对城市人口迁移进行数据挖掘,把每个基站抽象为特征向量,最后采用聚类分析的方法来对城市功能区域进行分析,最终对城市区域性质进行分类 [3]。目前,城市功能区分类工作大多采用传统方法(如聚类),很少采用时空模型进行处理。GRU可以通过计算时间序列的变化来计算时间依赖性,提取空间特征的模块可以通过处理区域的面积来计算各个区域的相关性 [4]。
此外,目前关于预测多个地区性质的工作没有考虑太多的人类活动因素。目前的一些工作稍微考虑了根据城市的不同形式和人类活动对城市功能区进行分类。一件作品的总体思想是描述基于建筑和基于区域的景观度量,从建筑层面的块,以衡量城市形态。同时,利用主题模型和语义缩放方法从与人类活动相关的人群来源数据中提取社会经济特征,然后利用随机森林测量这些不同的功能来融合这些特征,最终实现了分类工作 [5]。
然而,人类在城市的运动是划分城市功能区的重要参考标准 [6]。因此,城市功能区的分类应考虑一些新的要素,如人口流动、货物和服务贸易、通信、交通流、服务连接、报纸流通、资金流动等。我们考虑利用出租车在道路上行驶的数据,能够很好地反映人类的出行习惯和各个城市地区的功能信息,探索划分城市功能区的问题。陈斌等人于2017年提出了一种基于轨迹数据和兴趣点的城市功能区识别方法,与传统判别方法不同的是该方法考虑了人类的活动轨迹,通过轨迹数据的自适应密度聚类与基于聚类中心的泰森多边形来划分待识别功能区 [7]。相比于传统的基于路网的区域划分方式,考虑了人类活动轨迹后的城市功能区域划分方法的分类的准确率更高,同时,在完善城市规划,以及使得政策制定和资源配置更加符合人们的真实需求具有重要意义 [8]。
3. 城市区域性质的判别模型
3.1. 问题定义
城市功能区的分类问题可以定义为根据一天内不同时刻的空车转移率预测出发地和目的地的城市用地性质,如公式(1)所示。其中,“AttSTFN”表示建模方法;“a”表示空间注意力池化机制;“Time”表示某个时刻;“Rate”表示在该时刻从出发地到目的地的空车转移率;“S”表示出发地的面积;“E”表示目的地的面积;“Nature”表示经过预测得到的出发地或目的地的性质。将“Time”、“S”和“E”作为模型的三个输入是为了构造时空特征;将空车转移率作为模型的输入是为了完成基于空车转移率预测城市功能区的工作。空间注意力池化机制是整个建模过程的关键部分。对于出发地性质的预测,“a”给出发地较大的权重;对于目的地性质的预测,“a”给目的地较大的权重。
(1)
3.2. 模型算法概述
如图1所示,该模型以目的地面积和出发地面积为输入,与目的地和出发地的相关信息相结合,然后采用拼接的方式将目的地数据和出发地数据相融合。融合后的数据将作为空间特征提取模块的输入数据,在空间特征提取模块中,首先通过线性层对输入数据进行线性化,然后通过一个一维卷积层来提取数据的空间特征,最后,采用Relu激活函数来对一维卷积层的输出数据进行激活。在对数据进行空间特征提取后,将空间特征提取模块的输出数据与时间信息相结合,然后将融入了时间信息的数据作为时序卷积层的输入数据。随后,我们将提取时间特征后的数据输入到空间注意力池化机制,通过空间注意力池化机制将提取时间特征后的数据与出发地面积或目的地面积相结合,然后通过注意力池化机制来突出数据的空间特征。然后对空间注意力池化机制的输出数据采用Elu激活函数来进行激活,数据激活后输入到全连接层,最后将通过全连接层后输出的数据采用Log Softmax激活函数进行激活得到最终的输出结果。在获得输出结果后通过与真实数据进行比较,并通过优化损失函数计算出的损失值来提升模型对城市区域性质判断的准确率。
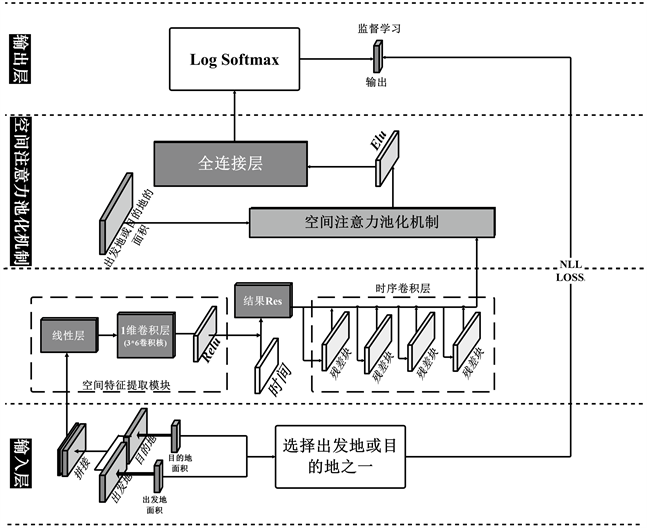
Figure 1. The structure of AttSTFN consists of three main components: a spatial feature extraction module; a temporal convolutional layer for computing time-dependent features; and a spatial attentional pooling mechanism for highlighting spatial features at the origin or destination
图1. AttSTFN的结构主要由三部分组成:空间特征提取模块;用于计算时间依赖性特征的时序卷积层;用于突出出发地或目的地空间特征的空间注意力池化机制
3.3. 空间特征提取模块
数据集将各个区域抽象成了不规则的六边形。我们用最长对角线和最短对角线乘积的一半来近似代替六边形的面积。值得一提的是,在计算面积前,我们需要对经纬度坐标进行标准化,标准化方法为Z-Score标准化。为了方便起见,我们将该方法得到的六边形的面积定义为近似标准化面积。使用近似标准化面积得到的实验结果优于使用精确面积得到的实验结果,我们在表1中给出了对比实验的结果。在计算面积后,我们将出发地和目的地的面积数据进行拼接操作,然后将结果输入到线性层和一维卷积层中以提取空间特征。线性层的功能是降低维度,卷积核对线性层的输出执行卷积操作,以提取区域的空间特征。基于反向传播算法,模型可以确定每个卷积操作的参数。
(2)
公式(2)是Z-Score标准化公式。其中,“Num”是原始数据;“Mean”是平均值;“Std”为标准差;“
”是输出数据。从Z-Score标准化的计算公式可以看出,原始数据与平均值之间的差异在操作过程中被保留。因此,当“Num”等于“Mean”时,“
”等于“Num”。如果“Num”的值大于平均值,则结果为正。相反,如果“Num”小于平均值,则结果将是负数。Z-Score标准化过程可以降低经纬度坐标的较大值。经纬度坐标经过Z-Score函数处理后,值在[−0.994, 0.965]之间波动。因此,与原始的数值过大的经纬度坐标相比,标准化后的经纬度数据更具有可比性,这也从一定程度上加快了收敛速度。
3.4. 时序卷积层
我们设计了一个新颖的时序卷积层来计算数据时间依赖性的特征,如图2所示。时序卷积层有许多优势。首先,它保留了所有的历史信息。它使用因果卷积计算长期的历史信息,并使用空洞卷积来扩大卷积过程的感受野。空洞因子按照凸函数变化,这样使得模型在深层计算时不会出现过大的感受野而造成局部信息丢失。其次,它完全是由卷积网络构成,并使用多层残差结构代替了传统递归神经网络的门控结构。最后,它克服了传统递归神经网络不支持并行计算和训练速度缓慢的现象。
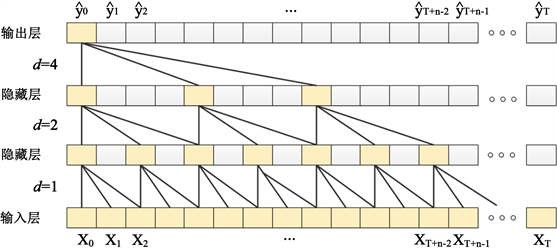
Figure 2. The structure of temporal convolutional layer
图2. 时序卷积层的结构
3.4.1. 因果卷积
因果卷积的思想被应用于追溯更久远的历史信息,因果卷积的公式如(3)所示。
是输入序列,
是隐含层输出序列,
代表滤波器。因果卷积只关注历史信息而忽略未来的信息,
的结果只会由
之前的数据得出。并且K越大,能够追溯的历史信息越多,如果当前层原始输入序列为[0, i],则下一层的原始输入序列就会变成[0, i + 1]。
(3)
3.4.2. 空洞卷积
在深度网络中,为了增加感受野且降低计算量,模型总要进行降采样,这样虽然可以增加感受野,但空间分辨率降低了。为了能不丢失分辨率,且仍然扩大感受野,可以使用空洞卷积。空洞卷积的公式如(4)所示。
(4)
d代表空洞因子,它会根据网络的深度按照2的指数函数进行凸函数变化,增大d或者K都可以增加感受野的范围。然而,在深度网络中,感受野会随着网络层的加深使得远距离卷积得到的信息之间没有相关性,从而造成局部信息的丢失。所以,我们将空洞因子按照2的指数函数进行变化。这种设计模式保证了在深度网络中,感受野的范围受到了一定程度的限制,降低了局部信息的损失。在深层次的特征计算过程中,密集的神经元信息传递也使得模型精度更高。
3.4.3. 残差结构
为了降低训练过程的复杂度,残差结构被用于代替传统递归神经网络中的门控结构,如图3所示。残差结构主要包括两层卷积网络和非线性映射过程。Weight norm层通过参数重写的方法实现数据归一化。Weight norm层常用于加速模型收敛。对权重进行归一化可以保证在梯度回转的时候抑制梯度范围,最终实现梯度的自稳定。
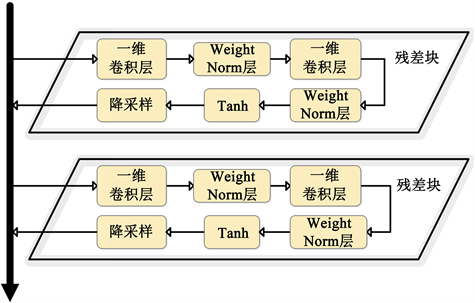
Figure 3. Multi-layer residual structure
图3. 多层残差结构
3.5. 空间注意力池化机制
图4是空间注意力池化机制的示意图。它由两个输入和一个输出组成。“1-Input”是出发地或目的地的近似标准化面积;“2-Input”是时序卷积层的输出。“1-Input”主要被线性层、平均池化层和Tanh函数处理,用于改变尺寸和形状(从[16]到[16, 64]),然后将经过Unsqueeze操作处理后的结果和“2-Input”进行批处理矩阵乘法(bmm)操作。经过bmm运算后,所有的结果都被放大,且分布在0到1的范围内。最后的输出是“Res”,它的形状为[16, 64]。
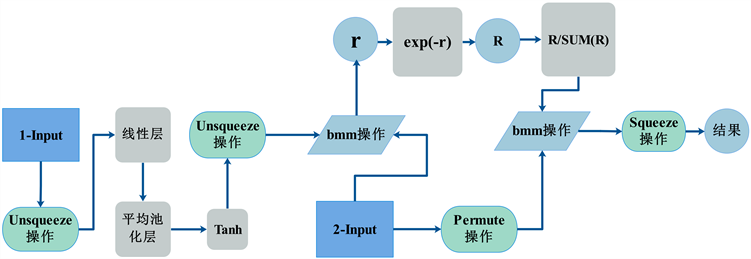
Figure 4. Spatial attentional pooling mechanism
图4. 空间注意力池化机制
(5)
公式(5)是bmm运算的公式。其中,“A”、“B”和“C”是三个矩阵;“*”表示矩阵乘法;“(x, y, z)”表示矩阵的形状;bmm运算的参数是两个三维矩阵,两个矩阵的第一个维度必须相同,后两个维数在维数上需要满足基本矩阵乘法的条件。空间注意力池化机制有两个明显的优势。首先,它可以压缩上层输出的特征数量,减少了参数,便于后处理阶段模型的计算。另一方面,城市交通网络错综复杂,虽然交通流量和人类出行行为是预测一个地区性质的重要工具,但是注意力机制可以根据不同的空间特征更好地区分一个地区是出发地还是目的地。更具体地说,如果我们输入出发地的空间信息,注意力机制将侧重于预测出发地的性质;如果我们输入目的地的空间信息,注意力机制将侧重于预测目的地的性质。空间注意力池化机制为输入的每个元素分配不同的权重参数,从而更多地抑制其他无用信息。它最大的优点是可以一步考虑全局和局部连接,使得计算可以并行化。此外,值得注意的是,用于预测出发地和目的地性质的模型计算过程是相互独立的。
4. 实验
4.1. 数据集
4.1.1. 数据准备
我们使用了中国成都市的空车转移率数据。数据集的时间范围是一天内的0时到23时,时间类型是0到23的整数,单位是小时。滴滴出行盖亚计划提供的数据集是基于滴滴出行平台的海量轨迹数据和订单数据,经过拟合、交叉验证和加权得到的。它可以科学、客观地反映交通流的方向和人们在某一时刻的出行规律,进而反映城市的各种区域性质。改变数据集中空车转移率的趋势,可以反映特定时间点的交通流量和人们出行的主要方向。因此,空车转移率可以间接地反映多方面的功能。此外,每个六边形中轨迹点的收集间隔约为3秒。这个采样间隔确保六边形没有特别短的边,从而确保我们对六边形的面积进行近似替代。我们在数据集中使用两个文件。第一个文件共包括8519个数据,每条数据均包括一个区域的代码和六边形六个点的经纬度坐标。第二个文件总共包括约104万条数据,每条数据包含一个时间点、两个区域代码和此时空车转移率的值。基于以上数据,我们进行了两种分类工作。首先,我们将数据分成两类(居住用地和商业用地)以进行二分类工作。其次,我们将数据分为四类(居住用地、商业用地、公共服务用地和科教园区)以进行四分类工作。
4.1.2. 面积数据处理
由于计算不规则的六边形的精确面积需要大量的计算过程,我们考虑使用最长对角线和最短对角线乘积的一半来近似代替六边形的面积(经纬度坐标已由Z-score函数标准化)。我们进行了对比实验(实验结果如表1所示),实验结果表明,使用近似标准化面积的平均精度比使用精确面积的平均精度高了约3.3%。

Table 1. The average accuracy profile of AttSTFN in predicting the origin and destination when we use the approximate normalized area and the exact area
表1. 当我们使用近似标准化面积和精确面积时,AttSTFN预测出发地和目的地的平均准确率情况
4.2. 指标比较
4.2.1. 基线
我们建立了六种不同的基线来验证模型的性能。包括传统的递归神经网络、一些典型的时空模型,以及Encoder-Decoder。在两种分类任务中,我们分别使用二分类工作的数据集和四分类工作的数据集来训练和评估每个模型。实验结果是这些结果的均值。在实验使用的六种基线如下:
· LSTM [9]:它通过门控机制来控制数据的传输状态。相比普通RNN只机械式地对一种记忆进行叠加,LSTM的原则是保留需要长时间记忆的,忘记不重要的信息。
· AttLSTM:在基础LSTM模型的基础上,增加了本文所述的空间注意力池化机制,分别突出出发地和目的地的空间特征。
· GRU [10]:它的输入输出结构与普通的RNN相似,并且它的处理逻辑与LSTM相似。与LSTM相比,GRU内部少了一个“门控”,参数比LSTM少,但是却能达到与LSTM相似的功能和精度。考虑到硬件的计算能力和时间成本,GRU是更多从事深度学习研究人员的选择。
· AttGRU:在基础GRU模型的基础上,增加了本文所述的空间注意力池化机制,分别突出出发地和目的地的空间特征。
· TCN [11]:它直接利用卷积强大的特性,跨时间步提取特征。TCN使用因果卷积计算长期的历史信息,并使用空洞卷积来扩大卷积过程的感受野。它克服了传统的递归神经网络不支持并行计算和训练速度缓慢的现象。此外,TCN在每一层的卷积核是共享的,内存开销更低。
· Encoder-Decoder:Encoder-Decoder是一个应用于“序列到序列”问题的模型,这意味着模型可以根据输入序列生成另一个输出序列。由于这种结构的灵活性,我们可以选择不同的编码网络和解码网络(比如RNN和RNN、RNN和LSTM、RNN和GRU等)进行训练和验证,然后我们将最有效模型的指标作为Encoder-Decoder的模型指标。Encoder-Decoder的最大限制是编码器需要将整个序列压缩成一个固定长度的向量。这样存在两个缺点:一方面,语义向量不能完全表示整个序列的信息;另一方面,第一个输入所携带的信息将被后面的输入稀释或覆盖。
4.2.2. 定量分析
准确率是用来评价分类模型的指标。该公式可以描述为我们的模型预测的样本的比例,正确地划分了参与预测的所有样本,如公式(6)所示。其中,TP表示真实情况,表示真实情况和预测情况均为阳性;FP表示假阳性情况,表示真实情况为阴性,而预测情况为阳性;FN表示假阴性情况,表示真实情况为阳性,但预测情况为阴性;TN表示真实情况和预测情况均为阴性。该公式不仅仅局限于二分类问题。当我们选择一个类别作为正例,而其他类别是反例时,该公式也适用于多分类问题。
(6)
两个分类任务中所有模型的评价结果如表2所示。基于这些结果,我们根据我们所做的两个分类任务逐一给出了详细的解释。我们在V100GPU上训练2000轮,训练集与评估集的比率为6:1。首先,我们谈谈二分类工作。Encoder-Decoder是将输入序列转换为固定长度向量,然后将当前生成的固定长度向量转换为输出序列的模型。这将有一个明显的缺点,首先输入的空车的时间特征、空间特征和传输速率信息将被后面输入的内容覆盖。如果序列更长,这个问题将更加严重。当然,解码的精度自然会变低。我们尝试了各种编码器网络和解码器模型的组合,并确定出了编码器–解码器模型在该实验中的最佳的匹配策略(编码器为RNN,解码器为LSTM)。然而,在表中列出的模型中,这种精度仍然是最差的;GRU和LSTM都是递归神经网络,它们可以记住长期的事情,因此每个时间点的空间特征将被发送到模型进行训练,并且由于各种类型的数据分布均匀,效果相对较好;空间注意力池化机制的引入使模型能够集中在出发地或目的地的空间特征上并准确地预测其中一种用地的性质。这是因为预测出发地点和目的地的性质包括两个单独的过程。因此,由LSTM结构和空间注意力池化机制组成的AttLSTM的预测效果略优于LSTM;AttGRU由GRU和注意池机制组成。由于使用的参数比一些复杂的模型少,AGRU不仅降低了过度拟合的风险,而且在一定程度上提高了训练效率。当然,“模型的参数越少,收敛速度就越快”这句话不是绝对的;AttSTFN中的时序卷积层使用因果卷积计算长期的历史信息,并使用空洞卷积来扩大卷积过程的感受野。它克服了传统的递归神经网络不支持并行计算和训练速度缓慢的现象。因此,使用AttSTFN的效果均好于使用AttGRU和AttLSTM的效果。此外,我们还发现,随着我们分类工作中类别的增加,准确率呈下降趋势。至于原因,我们总结为两个方面。一方面,随着类别的增加,分类工作变得更加复杂。另一方面,四分类工作的数据集不如二分类工作的数据集多。然而,AttSTFN在四分类工作中仍分别达到了90%和80%以上的精度。
4.2.3. 定性分析
ROC曲线是由水平轴上的假阳性概率(FPR)和垂直轴上的真阳性概率(TPR)组成的图。此外,它是基于受试者在特定刺激条件下由于不同的判断标准而获得的不同结果。曲线下面积(AUC)表示ROC曲线下的面积,主要用于测量模型的泛化性能,泛化性能表示分类效果是否良好。如果模型表现良好,AUC的值就会很大。公式(7)和(8)分别表示FPR和TPR。
(7)
(8)
从图5中我们可以看到,在两种不同的分类工作中,不同模型的性能差距基本上随着类别的增加而逐渐扩大,因为分类工作的复杂性可以间接地反映每个模型的分类能力和利弊。分类工作越复杂,各模型的性能差距越大。首先,在二分类工作中,我们认为LSTM、GRU、AttLSTM、AttGRU和TCN对出发地和目的地的性质具有相似的预测能力,因为这些模型的预测结果之间只有轻微的差距。AttSTFN比这些模型略好,但Encoder-Decoder具有最差的预测能力和最小的AUC值。其次,在四分类工作中,各模型所代表的曲线之间的面积差距大于二分类工作,这一现象表明AttSTFN的优势更加突出。
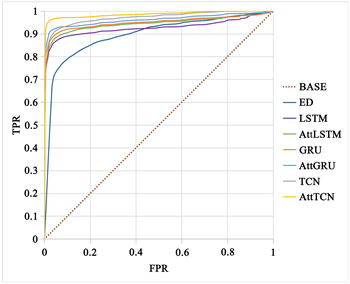 (a)
(a) 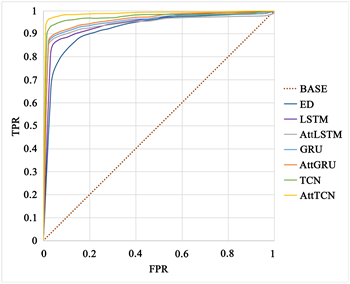 (b)
(b) 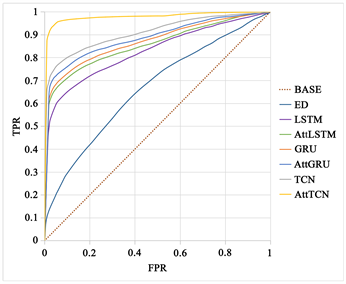 (c)
(c) 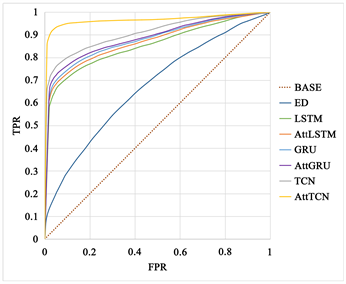 (d)
(d)
Figure 5. ROC curves of different models for the same category case. Where (a) and (b) are the predictions of different models for the origin and destination in the two-category work, respectively; (c) and (d) are the predictions of different models for the origin and destination in the four-category work, respectively; “BASE” denotes the curve of the random classifier; “ED” denotes Encoder-Decoder. If the ROC curve is lower than the diagonal, it means that the classifier is less effective than the random classifier. On the contrary, the effect is better than the random classifier
图5. 同类别情况下不同模型的ROC曲线。其中,(a)和(b)分别是二分类工作中不同模型对出发地和目的地的预测情况;(c)和(d)分别是四分类工作中不同模型对出发地和目的地的预测情况;“BASE”表示随机分类器的曲线;“ED”表示Encoder-Decoder。如果ROC曲线低于对角线,则意味着分类器的效果比随机分类器差。相反,效果优于随机分类器
AttSTFN之所以具有强大而稳定的性能,是因为AttSTFN是一个具有空间注意力池化机制的时空模型。空间特征提取模块可以有效地提取各个区域的空间特征;时序卷积层可以处理长期的时间信息;空间注意力池化机制可以增加出发地或目的地的空间特征权重,以实现对出发地性质或目的地性质的准确预测。与其他传统的时空模型相比,AttSTFN具有明显的优势和显著的效果。
5. 结论及未来工作
空车转移率描述了一天中每个整数时刻交通流向的一般特征,交通流向也是人流方向的关键反映。在考虑了人们的基本出行习惯后,我们将城市的主要功能区分为四类,并且完成了两种不同的分类工作。实验表明,AttSTFN表现良好,其空间注意力池化机制可以有效地区分一个区域是出发地还是目的地。在二分类工作中,AttSTFN的平均准确率达到了0.98和0.95,并在四分类工作中也达到了0.8和0.81。AttSTFN不仅精度相对较高,而且性能稳定。当基线不能很好地预测时,AttSTFN仍然可以稳定地预测。此外,由于时序卷积层可以跨时间步提取特征的特性和特殊的残差结构,它比AttGRU和AttLSTM具有更快的收敛速度和更好的性能。使用AttSTFN可以更好地完成基于空车转移率的城市功能区分类工作。
还有一些问题有待进一步研究。首先,我们应该进一步考虑不同模型的组合,或者使用更复杂的时空模型进行分类工作。我们还可以使用提供更多类别数据的数据集,将城市功能区划分为更多类别。另一方面,我们应该进一步考虑将此模型用于与交通领域相关的其他分类工作当中。
NOTES
*通讯作者。