1. 引言
中国是世界上最大的猪肉生产国和消费国,据国家统计局数据,2020年中国生猪出栏量高达5.2亿头,占世界总产量的52%,2020年生猪产业值占农业总产值的比重达18% [1]。猪肉也在畜牧产品中占有主要地位,我国猪肉的消费量占世界猪肉消费量的一半,因此其价格的变化影响着我国居民的生活质量水平。所谓“粮猪安天下”,足见养猪业作为中国食品安全的基础产业和战略产业,不仅关系到国民经济发展,也与社会稳定息息相关。近年来,猪肉的价格浮动区间较大,且猪肉价格受到饲养成本、市场需求、疾病等诸多不确定因素的影响而出现难以把控和预测的特点,这不仅使养猪户出现不敢养和积极性不高的问题同时也给其他相关产业带来了一定影响。因此,预测与稳定猪肉市场的价格会对整个养猪行业健康发展有重要的意义 [1]。
社会科学研究者一般通过市场调研的方法进行定性的分析,没有进行定量分析,结果不准确。猪肉价格预测本质上是一个回归问题,即通过易测得的变量来预测不易获取的变量。随着数据驱动、人工智能的发展,大数据分析的方法在预测猪肉价格、预测产量等方面有了深入研究。多元统计回归就是其中一个分支。最小二乘回归 [2]、岭回归 [3]、主元回归 [4]、偏最小二乘回归 [5] 等多元统计回归模型都有应用于价格分析、预测中,但它们能进行预测的前提是数据之间是线性关系,而猪肉价格预测是一个复杂的多维非线性问题 [6] [7] ,因此线性方法无法挖掘变量间的非线性特性。
神经网络可以拟合任意非线性函数,能深入挖掘变量间的非线性特性。李阳等人构建了基于灰色预测–反向传播(GM-BP)神经网络预测模型对猪肉价格进行了有效预测 [8]。刘青松等人提出基于自回归–循环神经网络(AR-RNN)的多变量水位预测模型 [9]。赵圆芳等人提出基于LSTM循环神经网络的质量预测方法 [10]。以上文献表明用神经网络做预测可以提高预测结果的准确性,但神经网络模型是一个黑箱模型,不具备可解释性。
机器学习不仅能解决非线性模型的问题,相比神经网络具有更好的解释性,而且机器学习不需要大量数据也能预测拟合地很好,因此,机器学习在价格回归等方面有着比较广泛的应用。张方怡等人以贝叶斯网络为理论依据,利用Hugin Lite软件拟合猪肉合格率模型 [11]。姜百臣等人基于集成经验模态分解的遗传算法改进支持向量机来预测猪肉价格 [12]。Jumin Ellysia等人根据马来西亚收集的数据,应用决策树回归来预测太阳辐射的变化 [13]。陈帅通过研究相关文献发现生猪价格受各种因素影响,运用逐步回归、随机森林及神经网络等方法综合分析得出影响生猪价格的几个主要因素 [14]。
考虑到猪肉价格与其他因素之间的复杂多模态非线性关系,本文使用随机森林对猪肉价格进行预测。针对收集的猪肉价格影响因素(如玉米价格,牛肉价格等),建立多棵决策树构建随机森林模型,对猪肉价格实现精准预测。
2. 猪肉价格影响因素分析
猪肉价格市场是开放和多元性的系统,经过阅读大量研究文献与市场调查实证分析可知影响猪肉价格的因素总体上可分为以下四个方面:供给关系、需求关系、成本、市场外因 [15]。在供给方面主要受到猪肉产量、生猪存栏量和出栏量等。需求方面主要受到居民消费水平、其他肉食产品价格等影响。成本方面主要有仔猪费用、育肥猪饲料、人工成本、生猪价格、玉米等影响。市场外因主要包括自然灾害原因、疫病等影响。影响猪肉价格波动的原因是多维和非线性的,在此本文结合前人研究成果 [16] ,特选取生猪价格、仔猪价格、猪粮比价格、豆粕价格、玉米价格、鸡肉价格、牛肉价格、羊肉价格、育肥猪饲料价格、鸡蛋价格、活鸡价格,共11种影响因子进行猪肉价格预测研究。
3. 方法介绍与数据来源
猪肉价格与其影响因素之间是复杂且非线性的关系,随机森林又具有较强的高维数据处理能力,还能对各个影响因素的重要性进行解释,适用于猪肉价格的预测与研究。故本文采用随机森林进行猪肉价格预测。
3.1. 决策树
决策树作为随机森林算法的基学习器,是研究随机森林算法必不可少的部分。随机森林就是由多棵决策树构成的。决策树中分别有根节点、叶节点和中间节点。决策树在构建时,由根节点开始分裂,分裂经过多个中间节点,最终到达叶节点。在这个过程中,决策树中的节点即为各个特征,从各节点分裂而出的路径表示特征可能选取的值。决策树的输出规则是唯一的,即最终输出值是唯一的。换句话说,从根节点开始仅能到达唯一的叶子节点,因此可以用来分类及预测 [17]。
在决策树的分裂过程中,属性分裂方式是择优录取即选择分裂时结果最好的属性进行分裂。比较分裂结果的好坏有多种方法,依据这些方法可以分为CLS、ID3、C4.5、CART等节点分裂算法 [17]。本文主要使用的是ID3节点分裂算法来进行建模预测。
ID3算法结合了信息熵理论,并将其属性节点分裂的方法。它的主要规则是:首先计算各个属性的信息增益,选择信息增益大的节点进行分裂。设数据集为D,包括了n个不同的类别
,其中
是数据集D中
类元组的集合,
是D元组的个数,
是
元组的个数。
D中元组的期望信息可以表示为
(1)
其中,
为
类元组出现的频率。
若用属性A将D分为若干个子集
,基于A划分D的期望信息表示为:
(2)
其中,
充当第j个划分的权值。
越小,划分的纯度越高。
根据上两式可得到信息增益为:
(3)
3.2. 随机森林算法原理
随机森林具备两种随机思想,分别是样本选取时的bagging思想和特征选择时的随机子空间思想。对每一个bootstrap样本构建决策树,然后将所有的决策树的预测结果集成进而生成随机森林的预测结果。在集成决策树结果时,回归算法就对决策树的预测结果取平均数,分类算法就采取众数投票的方式。
随机森林是由多棵决策树
组合形成的模型。其中
为服从独立分布的随机变量,x为自变量,T为决策子树的个数。
(1) 分类模型预测结果为:
(4)
上式中,
表示分类结果,Y表示分类类型,I表示示性函数。
(2) 回归模型预测结果为:
(5)
上式中,
表示回归预测结果,
表示基于x和
的输出。
3.3. 随机森林构建过程
随机森林构建步骤为:
(1) 利用bagging思想进行有放回抽样,要产生N棵决策树,就需要从原始数据集合中有放回的抽取N次形成N个样本子集,这其中每个样本子集所包含的样本量大概是原始数据集合样本量的2/3 [17]。
(2) 对所抽取的训练子集,利用随机子空间思想,随机抽取f个特征作为特征子空间,从特征子空间中挑选最优特征并以此开始进行节点分裂,进而构建决策树。在节点分裂时,对于回归模型,则基于均方误差建立回归树;对于分类模型,则基于基尼指数建立分类树 [17]。
(3) 重复步骤(1)、(2),生成T棵决策树。对每一颗决策树,任由其生长,不对其进行剪枝,最终由这T棵决策树构成整个随机森林 [17]。
(4) 综合T棵决策树的预测结果,汇总得到随机森林的预测结果。对于回归模型,采取取平均方式;对于分类模型,采取投票方式 [17]。
3.4. 数据来源
为了有效保证本次预测结果的准确性,在选取猪肉价格等相关数据因素时,数据均来源于中国畜牧业信息网、布鲁克农业数据平台并结合实地调研与文献统计而来。本文数据选取2010年1月~2020年12月生猪价格、仔猪价格、猪粮比价格、豆粕价格、玉米价格、鸡肉价格、活鸡价格、牛肉价格、羊肉价格、育肥猪饲料价格、鸡蛋价格,这些月度价格为研究对象,共计132组数据。
4. 预测结果及分析
本文选取2010年1月~2020年12月生猪价格、玉米价格等11类月度价格为研究对象,随机挑选60%组数据作为训练样本,剩下40%组数据作为测试样本,利用随机森林模型对其进行预测、检验。
4.1. 模型评估指标
为了评价预测性能,本文使用均方误差(MSE)作为模型的评价准则,定义如下:
(6)
其中:
为真实值,
为预测值,m为数据长度。显然,均方误差值越小,预测精度越高,预测模型效果越好。
4.2. 基于随机森林的猪肉价格预测建模
将132组数据随机打乱,其中随机挑选60%组数据用作训练样本,剩下的40%组数据用作测试样本,对猪肉价格预测模型进行检验。这里设置随机森林的决策树模型数目为100,即将100棵决策树的效果进行集成,将不同决策树的结果整合以获得最终随机森林的结果。此外,我们建立了单棵决策树模型和支持向量机模型对猪肉价格进行预测,并于随机森林的效果进行比较。
4.3. 模型的效果与分析评价
利用python平台分别编写关于决策树算法、支持向量机算法、随机森林算法三种预测方法的相关程序代码,在运行计算后并将其预测结果绘制如图1所示。通过对输出的预测猪肉价格与真实的猪肉价格计算得到三种预测模型的均方误差如表1所示。
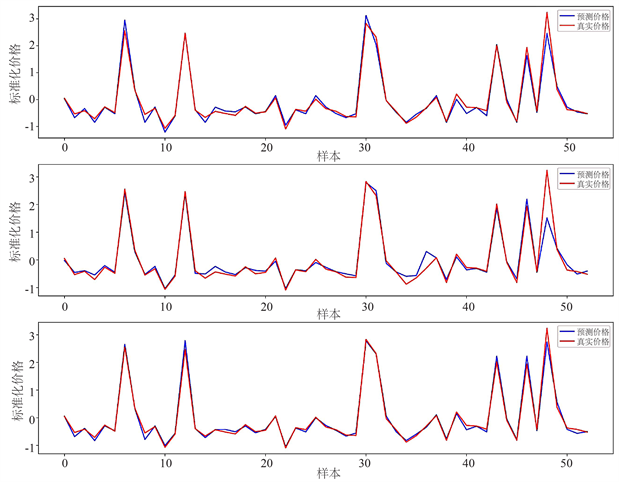
Figure 1. Comparison chart of three model predictions: decision tree, support vector machine, and random forest
图1. 三种模型预测对比图:决策树、支持向量机、随机森林

Table 1. The mean square error of the three forecasting models
表1. 三种预测模型的均方差
从图1中可以看出,在验证的40%猪肉数据中,随机森林的猪肉价格预测值和真实值是最接近的,而决策树预测在[10, 15],[45, 50]这两个区间偏差较大,支持向量机预测在[46, 50]预测偏差较大。由此可以得出随机森林在猪肉价格预测建模中做的最好。而从表1可以看出,随机森林预测模型的均方误差是0.081,在三种模型中,其均方误差是最小的,也即真实值和预测值差距最小。
5. 结论
由于猪肉价格与其他因素之间的复杂多模态非线性关系,本文采取了随机森林预测模型对猪肉价格进行精准预测,并同时使用了决策树模型、支持向量机模型进行对比实验,实验结果表明,使用随机森林预测猪肉价格,其真实价格和预测价格拟合程度最优,且均方误差最小,达到了预测精度的要求范围,因此可以说明该模型对于我国猪肉价格的预测具有较大的适用性。
对于猪肉价格的影响不仅包括供给关系、需求关系、成本、市场外因的影响,同时也容易受到疫病的影响。因此在实际的猪肉价格预测过程中还存在一些“理想处理因素”和主观性因素。所以在以后的研究过程中应当提高数据的准确性以及处理方法的融合性,来进一步提高预测的准确度,提高猪肉价格预测的准确率。