1. 引言
碳达峰、碳中和(“双碳”)作为我国提出的两阶段碳减排目标,具有重要的战略意义。实现双碳目标是我国实现可持续发展的内在要求和构建人类命运共同体的责任担当 [1]。
加强技术创新,推动新能源战略发展是实现双碳目标的重要途径。
风力发电是新能源战略发展的重点之一。在风力发电过程中,风电机组的运行数据会对风电场协调优化以及功率预测产生直接的影响,但是由于设备自身状况或者极端的自然因素等原因,风电机组运行数据的采集工作会受到影响。因此研究风电机组异常数据检测与清洗方法,对提升风电场运行维护的准确性和经济性有重要意义 [2],对双碳目标的实现有重要的推动作用。
当前在风机监测方法中,异常数据的检测与清洗是当前研究的热点,一些高校和机构对其进行了深入研究。朱倩雯等 [3] 采用四分位法进行处理,但在异常数据占比变大时,识别效果会变差;Wang [4] 提出了基于的数据检测方法,并假设概率密度函数符合正态分布,但是这与实际风功率的概率密度函数状态不符,导致其通用性不高;娄建楼等 [5] 提出组内最优方差算法,虽然对堆积型数据有一定效果,但是个例性较强,应用的鲁棒性较差;沈小军 [6] 采用变点分组与四分位相结合的方法进行异常数据检测,但是存在正常数据误删的现象;Zhang [7] 提出利用局部离群因子(Local Outlier Factor, LOF)算法,基于密度去筛选异常值点,可以很好地识别分散型异常数据,但是对堆积型数据不能有效识别。胡阳等 [8] 提出使用置信区间等效边界法进行异常数据的识别与清洗,但是边界的偏差会导致数据出现误删或者漏删的情况,对结果造成影响。
虽然当前风机数据清洗取得了显著的成果,但仍存在数据误删、通用性较差、鲁棒性差等问题。本文首先基于异常产生的机理分析了风电机组不同异常值的分布特征,并进行了分类。然后依据异常值分布特征提出了基于密度聚类与区间密度聚类(DBSCAN-Interval DBSCAN)组合的异常检测模型,最后从方法的有效性、合理性以及结果上进行了分析验证。
2. 异常数据特征
在风电场基于SCADA采集回的风电机组原始运行数据中,往往包含大量的异常数据。造成这些异常数据的本质是机组出现故障以及由于失修、弃风限电等多种原因出现的停机或者低性能运行导致;或者受到电磁干扰、风机脱网、极端天气等。由于不同原因造成的异常数据在风速–功率曲线上也会有不同的呈现。大致可分为底部0功率堆积数据、恒功率异常数据和周围分散性异常数据。各类数据大致分布情况如图1所示。
分析图1可知:
1) 曲线底部0功率堆积异常数据。此类数据通常由于机组故障、检修或者通信故障等原因造成。在该类情况下,机组的理论输出功率应该为零,但由于若风机的叶片未转动,但风机的测控系统需要电力驱动 [9],则导致数据中会出现为负值的情况。
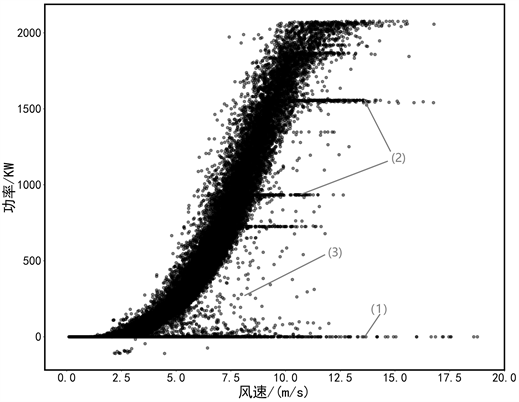
Figure 1. Diagram of distribution of Wind speed-Power abnormal data
图1. 风速–功率异常数据分布示意图
2) 曲线中部恒功率堆积数据。这类数据在风速–功率曲线中常表现为一条或多条低于正常功率曲线的密集带。造成此类故障的原因常是弃风限电,可能因为按照调度计划要求,使机组一直按低于正常功率的状态运行,进而产生了恒功率堆积数据。在风电场实际运行过程中,由于当前电网消纳能力不足等原因,使得机组强制弃风已是常态 [10]。
3) 周围分散型异常数据。这类异常数据在风速–功率曲线中变现为在功率曲线附近低密度且无规律的散点。此类异常数据的产生常由极端的天气、信号传播中的噪声等随机因素造成的,也正是因为随机因素的不确定性导致此类数据在功率曲线外随机分布。
根据上述几类异常数据的分布特征和产生原因可知,堆积型数据往往是由于设备故障和限风弃电等原因造成的,并且没有办法在短时间内恢复。而分散性异常数据则是由短时间可以恢复的状态或者故障产生的,这些因素是随机产生是,存在不确定性因此表现为分散状态。
针对分散型、堆积型异常数据的检测方法,本文将依次进行其原理解析。
3. 基于改进密度聚类的异常检测方法
3.1. DBSCAN密度聚类方法
DBSCAN密度算法是假设能够通过样本分布的紧密程度确定聚类结构 [11],并可以将一定密度的部分划分成簇。该算法可以由给定的参数Eps和Minpts来确定一个簇,其中Eps表示确定的邻域半径,Minpts 表示在以Eps确定的邻域中,核心点至少应该包含对象的数量。
在确定参数的前提下,DBSCAN算法的思想如下:
1) 初始化样本集D中所有对象的状态,设为未访问;
2) 遍历样本集D的每个对象t进行判断,如果t已经被归入某个簇或被标记为异常值点,则结束判断,否则,继续执行;
3) 检测对象t的Eps邻域,如果包含的对象数不小于Minpts,则标记对象t为核心点,并将本身以及邻域内所有对象放入新簇C;
4) 对于t的Eps邻域内未被处理的对象,检查其邻域,并与Minpts比较,将不小于Minpts的对象,将其与其邻域中未归入簇的对象加入C。
3.2. Interval DBSCAN密度聚类方法
DBSCAN方法对于边界不清晰的异常数据处理有一定的局限性,本文基于区间的密度聚类方法(Interval DBSCAN),是将普通的密度聚类方法在全局参数上的聚类,划分在局部参数进行聚类。通过对数据某一变量按照一定范围进行拆分,将整体数据分成多组数据,再每组进行聚类,最终将每组结果进行整理,达到分离异常数据的目的。
3.3. DBSCAN-Interval DBSCAN算法实现过程
针对风机SCADA数据分布的特点,提出利用二次密度聚类的方法将风机的运行数据进行清洗。具体流程如图2所示。
1) 首先将数据进行第一次密度聚类,此次聚类会识别出分散型的异常数据,但是由于底层堆积数据以及恒功率数据也具有高密度的特点,且与正常数据值界限不清晰,所有会存在未被识别的情况,将进入第二次密度聚类识别;
2) 第二次密度聚类方法利用分区域的方法,将全局数据进行拆分,在每个小区间利用DBSCAN算法。将数据集按风速进行划分,以风速a的间隔分成多个区域。得到每个小区间的数据集
为:
(1)
式中:
为第
个区间的数据集;
为落在第
个区间的元素。
3) 在每个小区间内使用密度聚类方法,对数据进行识别,可以有效的识别出未识别出的堆积数据。
4. 算例试验
4.1. 数据样本
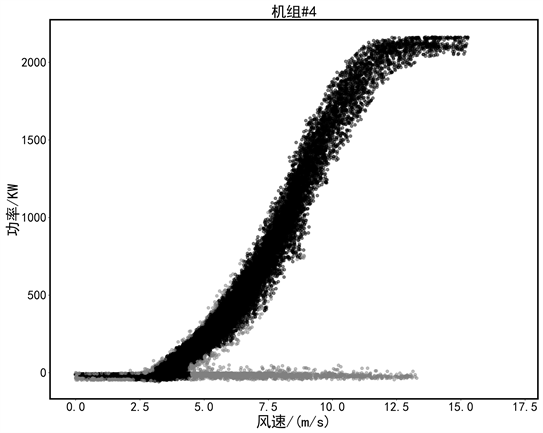
为验证提出的方法的实用性,选取国内某风场一年的SCADA真实运行数据进行验证,该风场风机的基本参数为:额定功率2000 kW,切入风速3 m/s,切出风速25 m/s。这里分别选取异常数据分布比较典型的4#、5#号机组数据来进行验证。其连续一年的原始数据如图3所示。
4#机组数据,异常值多为周围分散型数据,以及0功率堆积异常数据;5#机组存在更多的限电数据,堆积异常数据特征明显。
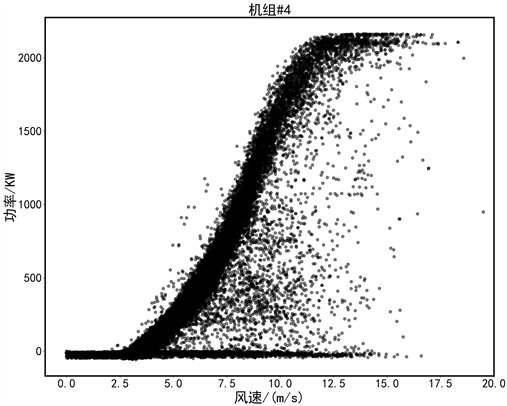 (a) 4#机组
(a) 4#机组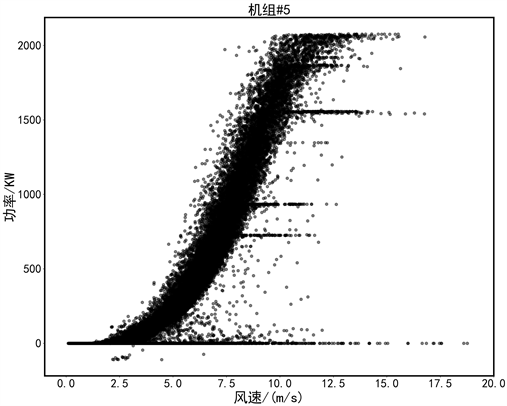 (b) 5#机组
(b) 5#机组
Figure 3. Raw data of two wind turbines: 4、5
图3. 4#、5#两台机组数据样本
4.2. 异常数据点识别
根据第2节提出的方法,建立异常数据识别模型,利用基于密度聚类法与基于区间的密度聚类法(Interval DBSCAN)的异常检测,对原始数据进行处理,获得清洗后的风电机组运行数据。
首先,利用基于密度的DBSCAN模型分别对2台风电机组进行聚类。通过多次合理性实验,调整最优参数,确定出聚类半径Eps为0.07,类内最小样本数Minpts为16,聚类结果如图4所示,其中灰色圆点为聚类结果中的离群噪声点,黑色圆点表示正常数据。
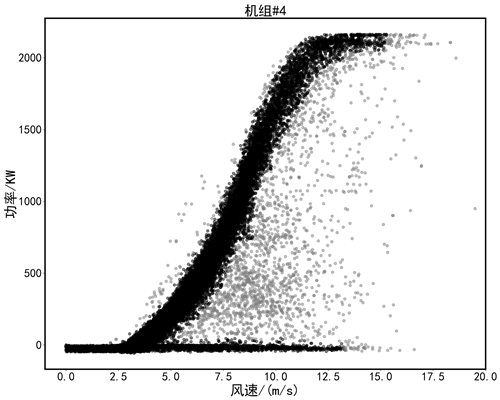 (a) 4#机组
(a) 4#机组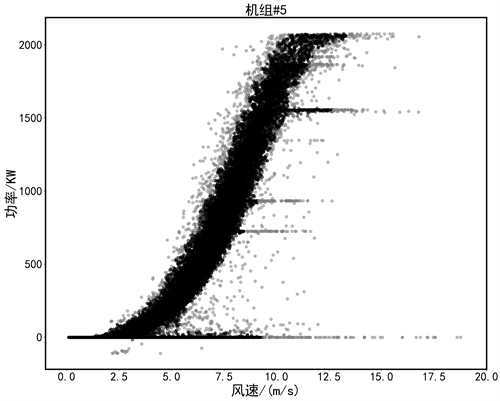 (b) 5#机组
(b) 5#机组
Figure 4. Outlier identification of DBSCAN
图4. DBSCAN的离群点识别
由DBSCAN模型的离群点识别结果可知,虽然检测出大量离群异常值点,但是对于下方0功率堆积点、恒功率限电点,并没有很好的识别。
Figure 5. Outlier identification by region
图5. 分区间的离群点识别
第二步采用改进的离群点检测模型继续进行识别,将风速按照0.5 m/s的间隔划分,对每个区间中P-V (功率–风速)散点图进行离群点检测。如图5所示,可以看到通过划分区间后,底层堆积的限电数据以及恒功率的限电数据可以很好的被识别出。图6为通过划分区域的离群点检测模型得到的检测结果。
 (a) 4#机组
(a) 4#机组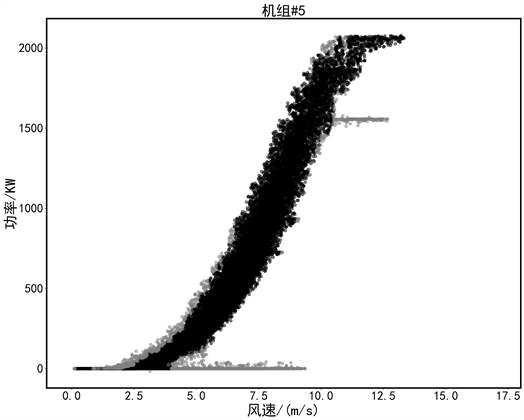 (b) 5#机组
(b) 5#机组
Figure 6. Improved outlier identification
图6. 改进的离群点识别
经过两次离群点检测与剔除后,环绕型数据以及堆积型数据都有被很好的识别,获得最终数据如图7所示。从图中可以看到,分散型异常数据和堆积型异常数据有明显的被剔除,可以很好的反应风速–功率曲线的特征,因此可以证明方法的实用性。
 (a) 4#机组
(a) 4#机组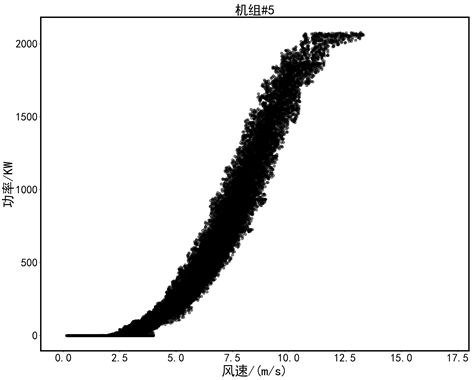 (b) 5#机组
(b) 5#机组
Figure 7. P-V scatter diagram of wind turbine after cleaning
图7. 风电机组清洗后的功率–风速散点图
4.3. 算法对比分析
为证明DBSCAN-Interval DBSCAN算法在进行数据清洗过程中的合理性和有效性,本文利用4号风电机组,从清洗效果和异常数据检测量等维度对比分析了基于区间的DBSCAN以及孤立森林(Isolation Forest)异常值检测方法。两种方法对数据清洗效果图如图8所示。从效果上可以看到孤立森林的方法对堆积型和分散型异常数据都没有很好的识别,基于区间的DBSCAN算法虽然检测出较多异常数据,但是整体上还是存在漏检的问题。
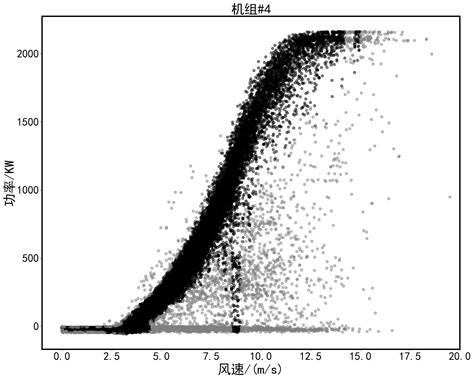 (a) I_DBSCAN
(a) I_DBSCAN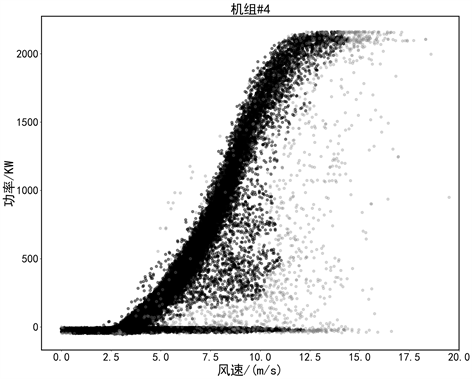 (b) I_Forest
(b) I_Forest
Figure 8. Effect comparison chart
图8. 效果对比图
如表1所示,在数据检测率上对四种方法进行了对比,可以看到本论文的方法对异常数据的检测率是存在明显优势,在四号机组上有8.2%的检测率,Interval -DBSCAN有6.7%的检测率,而DBSCAN和Isolation Forest为4.1%和3%,仅有其50%左右的检测率,证明了本方法的实用性。

Table 1. Data cleaning effects of different methods
表1. 不同算法数据清洗效果
5. 结论
为了解决风电机组中的异常数据对风电机组性能分析带来的负面影响,本文总结与分析了异常数据的数据类型以及产生原因,建立了两次密度聚类的异常数据识别模型进行处理。通过实验例证分析表明:
1) DBSCAN方法可以很好地识别环绕型分散数据,第二次基于区间的DBSCAN方法对堆积型数据的识别效果显著。
2) 由清洗后的各机组功率–风速曲线可以看出,异常数据剔除效果好,证明了本文提出方法的合理性。
本文在基于区间的密度聚类算法的改进上进行了初步的研究,提出在各区间进行聚类算法时,考虑到划分区间后,区间数量会增多,针对调优参数过程,在依据数据的物理特性以及机组设备的运行原理的前提下,可以采用自适应确定DBSCAN算法参数的方法进行调优处理,这也是后面工作的研究方向。数据清洗是对风电数据进行深一步挖掘处理重要的先导工作,本文中的方法对后续的风电工作提供了良好的支持。
NOTES
*通讯作者。