1. 引言
新一代泛在网的高速发展促使信息数据呈现爆炸式发展,截至2021年6月,中国网民规模达10.11亿,较2020年12月增长2175万,互联网普及率达71.6%;在各类信息中,最常用的文本数据类型呈指数级增长,因此如何快速准确地定位目标文本数据,成为现阶段持续研究的热点和难点 [1]。
目前主要采用搜索引擎解决上述问题,但搜索引擎被检出的原始信息普遍存在冗余化、离散化、偏离化等不足,通常需要用户进行二次确认导致效率低下。因此,采用简短概要信息对文本数据进行描述的方法被提出,使得用户通过摘要实现对原文信息的传递领会,实现信息定位的效率性和准确度提升。但具体使用过程中,海量的文本数据规模致使常需采用人工方式进行文本摘要结果的二次核准,导致耗费巨大、实时性差、描述失真等问题不断出现,甚至出现刻意夸大扭曲事实的情况。
为解决人工生成摘要的局限性,自动文本摘要(Automatic Text Summarization, ATS)技术应运而生 [2]。传统的专家系统自动文本摘要方法,根据既定规则截取原文片段组成摘要,难以适应不同领域的文本摘要,规则化的结果往往易出现关键信息缺失、信息冗余、语义错误等弊端,无法满足实际使用需求。新一代的自动文本摘要技术融合深度机器学习技术,以标准篇或多篇文档为准则,实现文本关键信息摘要的自动、快速、准确、实时地生成保存,并保证摘要语义通顺、简洁准确,可有效弥补人工摘要的不足。
随着数据量和数据类别的不断丰富,以及计算能力的大幅提升,以神经网络为代表的深度机器学习技术在自然语言处理、图形图像处理等领域得到显著而有效地应用。与传统专家系统的规则文本自动摘取技术不同,基于深度学习的文本摘要可实现原始文本特征的自动提取,通过端到端学习,极大简化自动文本摘要模型的复杂性,并随着运用次数和场景的增加,可持续实现精确度、准确度的提升,较基于规则的方法更具前景。现阶段,基于深度学习的文本自动摘要技术的难点集中在集合外词语难以生成、摘要与原始语义不匹配等方面。
针对当今的文本摘要模型难以生成集外词以及缺乏对单词之间的联系进行有效建模的问题,本文提出了一种基于改进子词单元的生成式文本摘要模型。主要创新点集中在使用改进的子词分割算法将一个完整的单词分割成不相交的子词单元,实现同一含义但不同形态单词之间的联系加强,例如受单复数、时态影响的单词,有助于模型对单词之间的联系进行建模。同时,通过粒度更小的子词单元构成集外词,从而更好地体现单词之间的联系,缓解集外词难以生成的问题。
2. 自动文本摘要的形式化定义
自动文本摘要技术始于20世纪50年代的Luhn等人 [3],给定输入文本
,其中
为输入词汇表,m为输入文本长度,
为第i个输入文本单词。自动文本摘要系统根据输入文本生成摘要
,其中
为输出词汇表、n为生成摘要长度,
为第i个生成摘要的单词,生成的摘要应该满足
条件。
发展至今主要分为4类,根据输入文档数量的不同可分为单文档摘要和多文档摘要,根据输入文本长短的不同可分为短文本摘要和长文本摘要,根据输入输出语言的异同可分为单语言摘要、多语言摘要和跨语言摘要,根据输入文本领域的不同可分为新闻摘要、法律摘要等 [4]。本文从生成摘要中的句子或单词是否完全来自于输入文本的角度出发,将自动文本摘要分为抽取式(Extractive)文本摘要、生成式(Abstractive)文本摘要,如图1所示。
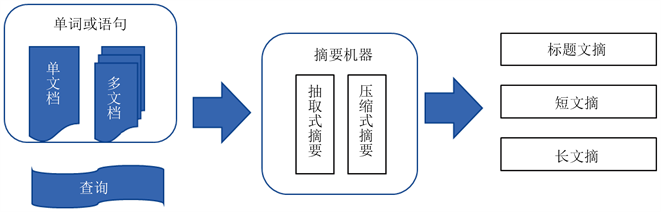
Figure 1. Automatic text abstract classification model diagram
图1. 自动文本摘要分类模型图
2.1. 抽取式文本摘要技术
抽取式文本摘要(Extractive Text Summarization, ETS)从输入文本中抽取出特定词句组成最终摘要,生成摘要中的每个单词yi都属于输入文本中,即
。ETS技术包含输入文本的词句重要度得分计算、基于得分的句子筛选及组成两个过程,包括基于统计特征的方法(Statistical-Based)、基于主题的方法(Topic-Based)、基于图的方法(Graph-Based)和基于神经网络的方法(Neural Network-Based)四种 [5]。
1) 基于统计特征技术(Latent Statistical Indexing)结合句子的统计特征来评估相关重要程度,然后根据重要程度对句子进行选择后组成摘要,在研究初期得到了广泛使用;
2) 基于主题的方法通过隐含语义索引(Latent Semantic Indexing)、概率潜在语义分析(Probabilistic Latent Semantic Analysis)和隐含狄利克雷分布(Latent Dirichlet Allocate)等模型计算文档的主题分布,然后根据计算得到的主题分布对文档中句子的重要程度进行评估并加以选择;
3) 基于图的方法将输入文本作为一张图处理,将原文句子作为节点,句子间的关联作为节点边,其中最为具代表的为Text Rank算法 [6]。
4) 基于神经网络的方法作为最近的研究热点,将神经网络引入到抽取式文本摘要当中,取得良好效果 [7]。
2.2. 生成式文本摘要技术
生成式文本摘要(Abstractive Text Summarization, ATS)中存单词y_i未在输入文本中出现过,ATS首先构建模型对原始文本进行理解,然后以模拟人类的方式对原文进行概括生成摘要。与抽取式摘要不同,生成式方法生成的摘要中的词语或者句子不必完全来自于原文,较ETS具备更大的灵活性,模型输出的摘要也更像人工生成的摘要。但是,由于生成式文本摘要中包含文本理解、句子改写、同义词替换等底层自然语言处理,这导致相比较于抽取式文本摘要模型,生成式文本摘要模型的训练要更加困难。
近年来,随着大规模文本摘要数据集的出现以及算力的提升,人们逐渐将研究的重点放在生成式文本摘要上 [8]。按照方法的不同,ATS技术分为基于图的方法(Graph-Based)、基于模板的方法(Template-Based)和基于神经网络的方法(Neural Network-Based)三种。
3. 自动文本摘要不足分析
自动文本摘要在序列模型和注意力机制得到大规模应用后获得长足发展,但依旧存在以下三方面主要问题:
1) 生成式文本摘要模型难以生成低频词、罕见词等集外词(Out of Vocabulary, OOV)。在进行文本摘要之前首先需要构建词汇表白名单,生成摘要中的单词均来自于该词汇表。词汇表容量大小限制并不会收入所有词语,导致诸如地名、人名、民族语言等低频词不在词汇表中,在外的这部分单词为集外词。在摘要生成时,集外词会被映射为未知,从而导致模型泛化能力的降低,显著影响生成摘要的可读性。
2) 生成式文本摘要模型难以在单词间建立有效的模式联系。以英文为例,时态、语态、词态、复数等因素导致大量的派生词以及前缀和后缀出现,如果以完整单词作为输入输出模型,会难以在单词之间的联系建立可靠联系,严重影响摘要表现。例如“think”、“thinks”、“thought”、“thinking”等,还存在表示词性的前缀或后缀等。
3) 生成式文本摘要模型难以实现对关键信息建模的清晰和充分抽取。绝大部分的生成式文本摘要大都基于序列模型构建并采取端到端训练,训练过程中的编码器会同时对关键信息和噪声进行编码,现有的序列到序列模型缺乏对输入文本噪声的过滤建模过程。
4. 基于子词单元的改进
4.1. 基于概率和粒度的融合
针对难以生成集外词、缺乏单词间联系的两个问题,现有的解决方法可以分为两类:
1) 综合考虑词汇表中单词概率分布的生成概率和输入文本中单词的拷贝概率两个因素,模型根据拷贝概率从输入文本中直接拷贝集外词到输出摘要当中,代表性包括指针生成器(Pointer-generator)模型、拷贝网络(CopyNet)等。拷贝概率的引入可以适当缓解集外词难以生成的问题,但依旧不能对单词间联系进行建模。
2) 降低输入输出文本中单词的粒度,例如将单词转为不相交的子词单元,并通过细粒度的子词单元表示集外词。此外,由于不同单词之间可能会共享某一个子词单元,所以将单词分割为子词单元能够使模型更好地对单词与单词之间的联系进行建模。代表算法为字节对编码算法(Byte Pair Encoding, BPE),BPE将单词将输入输出文本中的单词分割为不相交的子词单元,但由于子词分割是在有限语料上训练得到,在训练语料规模较小情况下的子词分割方式未必是最优解、甚至是不恰当的分割,影响单词联系和模型性能。
4.2. 基于子词单元的序列到序列文摘模型
基于Transformer的编码器–解码器框架构建模型整体结构,通过编码器对输入文本编码获得符合深度模式处理的文本表示,通过解码器对文本表示进行解码,输出生成摘要,如图2所示。
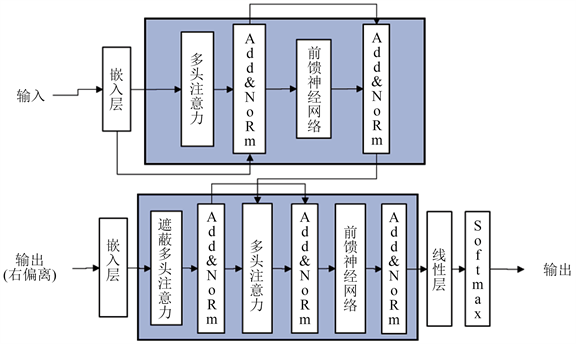
Figure 2. Frame diagram of encoder-decoder based on Transformer
图2. 基于Transformer的编码器–解码器框架图
4.2.1. 编码器
输入文本
模型编码器由N个相同的编码层堆叠构成,第i层编码过程如公式(1)、(2)、(3)所示:
(1)
(2)
(3)
其中,
表示编码器第
层对于输入文本x中第i个单词
的编码,第
层的输出为第 层的输入。SelfAttention()表示对输入应用自注意力(Self-Attention)机制,LayerNorm表示层标准化,FeedForwardNetwork表示前馈神经网络(Feed Forward Network),
和
为计算过程的中间结果。
自注意力机制是注意力机制的变体。注意力机制包含查询矩阵Query、键矩阵Key和值矩阵Value输入参数,根据 和 计算注意力分布
,如公式(4)所示:
(4)
其中Likelihood表示兼容函数,其目的是计算查询矩阵Q和键矩阵K之间的相似度,也就是注意力分布
。通常,Likelihood有加性(Addictive)、权值映射(General)和点积(Dot-Product)三种方式 [9],如公式(5)所示:
(5)
其中,
和
为训练参数,tanh为激活函数。将注意力分布
和值矩阵相乘,得到基于注意力的文本表示,如公式(6)、(7)、(8)所示:
(6)
(7)
(8)
其中,d为矩阵Q维度,Q为解码器前一时刻的输出,而K为编码器对输入文本的编码表示。多头注意力(Multi-Head Attention)机制将H进行多次线性变换得到多组Q和K,并将自注意力机制计算得到的结果连接起来进行线性变换,如公式(9)所示:
(9)
W为可训练参数,hn为注意力头个数,
为
。多头注意力能够从不同的角度对文本进行编码,获得更好的文本表示。
4.2.2. 解码器
解码器对编码器输出H进行解码生成摘要。解码器为N层,且每层除多头注意力模块和前馈神经网络模块外,还有一个解码器注意力模块EncDecAttn()用于联合编码器和解码器。EncDecAtt()中的K和V来自于编码器的输出H,而Q来自于解码器第l层对输入的编码
。
解码器最后一层的输出经线性变换后,通过Softmax()函数得到词汇表上的概率分布
,通过概率分布
得到当前步的输出单词,如公式(10)所示:
(10)
4.3. 文本的子词单元表示
4.3.1. 字节对编码算法
字节对编码算法包含子词词汇表构建和子词分割两个步骤,其中子词词汇表构建算法基于频率统计,包含训练语料D和合并次数n两个参数。其生成过程是,将训练语料D中的所有不重复字符加入到词汇表V中构建初始词汇表,将每个字符为一个单独的子词单元,合并频率最高的两个相邻子词单元并加入词汇表。循环n次算法结束时,子词词汇表构建完成。子词词汇表记录了子词的分割方式,可通过子词词汇表对训练样本中的单词进行分割。
本文使用算法1来对原始文本进行子词分割。如算法1所示,子词分割算法输入原始文本D和子词词汇表V,返回经过子词分割的文本D'。
算法1子词分割算法
Step1:读取原始文本D并进行分词;
Step2:将子词词汇表V根据子词长度从长到短排序;
Step3:for原始文本D中的每个单词do;
Step4:for子词词汇表中每个子词单元do;
Step5:尝试将单词中的子串替换为当前的子词单元,重复;
Step6:重复第4步,最终生成经过子词分割的文本D';
通过上述算法构建子词词汇表,可以得到假设训练语料中包含m个字符,子词分割过程共包含n次合并操作,则最终的词汇表大小介于m + n到2m + n之间。
4.3.2. 改进的字节对编码算法
由于训练语料是有限的,将当前语料中频率最高的子词单元对合并可能并不是最优的选择,其原因在于子词分割方式过拟合于训练语料,当训练语料规模较小时,该问题会更容易发生。为了缓解这个问题,本文在子词词汇表的构建过程中添加噪声扰动,提出细粒度字节对编码算法FG-BPE (Fine Grained Byte Pair Encoding)。通过选择概率和频率高的子词单元对进行合并,实现对原始文本分割的更加合理的结果,如算法2所示。
算法2 细粒度字节对编码算法FG-BPE
Step1:读取训练语料D并进行分词;
Step2:在每个单词后加符号< /w >表示单词结束,统计单词频次;
Step3:将每个单词分割为字符序列,此时子词单元为单个字符,初始的词汇表V由单个字符组成;
Step4:while当前合并次数小于n do;
Step5:统计语料D中相邻的两个单元对出现的频次;
Step6:设置当前待合并的单位对为频率最高的单元对;
Step7 ::if random()
then;
Step8:设置当前待合并的单元对为频率次高的单元对;
Step9:重复第7步,直到结束;
Step10:将当前待合并单元对中的两个子词单元合并为一个单元,并加入到词汇表V中;
Step11:重复第10步,直到结束。
算法2中通过概率p与频率次高的子词单元融合考虑进行合并。
5. 实验
5.1. 训练目标
模型的训练目标是在给定输入文本x以及模型参数
的情况下最大化生成每个目标单词的概率,其等价于最小化模型生成的单词和目标单词之间的负对数似然(negative log-likelihood),如公式(11)所示:
(11)
其中,D为训练数据集,x为输入文本,y为目标摘要,
为模型的参数。
5.2. 评价规则
针对生成的文本评价规则,包括人工和自动两种,其中人工评价方法从是否易读、句子之间是否连贯、是否存在语法错误、摘要中的指代是否明确、摘要是否覆盖了原始文本中的关键内容、是否存在冗余的问题六方面衡量摘要质量;人工评价方法会引入评价人的主观倾向,当数据量较大时不太可行。为了解决人工评价摘要缺点,很多自动评价摘要的方法出现,其中具有代表性的有ROUGE (Recall-Oriented Understudy for Gisting Evaluation)和meteor,本文采用ROUGE规则进行评判。
ROUGE是Lin [10] 基于召回率提出的文本摘要自动评价指标,该方法通过计算参考摘要(Reference Summaries)和摘要间基本单元(n元组)的重叠程度来衡量模型摘要质量。ROUGE通常包含以下几种指标:
· ROUGE_N:该指标统计参考摘要和模型生成摘要n元组之间的共现召回率,如公式(12)所示:
(12)
其中S代表了参考摘要中的句子,
代表n元组,
表示s中n元组的数量,
表示模型生成的摘要和参考摘要匹配的n元组数量。
· ROUGE_S:该指标与ROUGE-2类似,区别在于ROUGE_2二元组单词必须相邻,而ROUGE_S中的二元组不一定相邻。
· ROUGE_L:该指标根据模型生成的摘要和参考摘要间的最长公共子串(Longest Common Subsequence, LCS)衡量模型生成摘要的质量,如公式(13)所示:
(13)
其中,X为参考摘要、m为参考摘要长度、Y为模型生成摘要、n为生成摘要长度。
5.3. 实验集及效果
本文使用公开的自动文本摘要数据集Gigaword [11] 进行实验,Gigaword作为大规模的自动文本摘要数据集,由400万条模型输入的新闻以及模型输出的标题摘要组成。本文将1,198,668条样本划分为训练集,将2,397,335条样本划分为验证集,将399,556条样本划分为测试集,输入平均长度为32个字符,输出摘要平均长度为9个字符。
在Gigaword数据集上各模型的实验结果表明,使用原始子词分割算法,模型取得了37.71 (ROUGE_1)、18.43 (ROUGE_2)和34.87 (ROUGE_L)的结果;使用改进子词分割算法,模型取得了37.92 (ROUGE_1)、18.94 (ROUGE_2)和35.05 (ROUGE_L)的结果。分别在ROUGE_1上提升了0.21、在ROUGE_2上提升了0.51、在ROUGE_L上提升了0.18。
实验结果证明,本文提出的柔性粒度字节对编码算法FG-BPE通过使用改进的子词分割算法,在保证同一含义的前提下,将完整单词分割成保持不同形态间联系的子词单元,实现面向单词间联系的有效建模系,模型性能得到有效提升;在此基础上,通过粒度更小的子词单元构成集外词,有效缓解了集外词难以生成的问题。
下一步研究在于,如何跳出两段式噪声过滤步骤,设置全局向量实现噪声过滤算创新法,避免计算过程中的信息损失。
基金项目
《基于自然语言处理技术的招投标公共服务平台研究与应用推广》,2020年度贵阳市国家创新城市“百城百园”行动项目,贵阳市科技局(筑科项目[2020] 22号)。