1. 引言
近年来,数字和网络视频监视系统相对于传统系统的优势已变得越来越明显。它们的高度标准化,开放性,集成性和灵活性为安防建筑等其他行业的发展提供了更广阔的发展空间,其中,智能视频监控是网络视频监控领域的主要应用开发方向之一。
在传统系统甚至网络视频监视系统中,已经使用了诸如运动检测和警报之类的图像技术,但是误报率和误报率很高,使得该技术在实际使用中无效。但是,智能视频监控系统能够识别不同的对象,在监控屏幕中发现异常情况,并以最快和最佳的方式发出警报并提供有用的信息,从而可以更有效地帮助安全人员处理危机,并最大程度地减少误报和误报。
近年来,深度学习在各个领域取得了巨大的进展,目标检测领域也不例外。当前的基于深度学习的目标检测方法存在两种方式,一种是以SSD [1] 和YOLO [2] 为代表的one-stage,另一种是以R-CNN [3] 和Fast RCNN [4] 以及Faster RCNN [5] 为代表的two-stage。与Faster RCNN相比,SSD这类one-stage方式虽然准确率低一些,但是其可以在大部分场景下达到实时的结果,因此非常适用于安全帽识别视频监控系统。
2. 基于SSD目标检测的安全帽识别的视频系统
安全帽识别的视频监视系统模型具有三个模块:神经网络模块,识别器模块和后处理模块。神经网络模块中的基本网络使用VGG-16 [6] 网络,然后在VGG-16的基础上添加卷积层以获得更多的特征图进行检测。主要功能是用作特征提取器来提取图像的特征。识别器模块的主要功能是基于神经网络模块提取的特征,生成包含商品位置和类别信息的候选框(此处使用卷积实现);最后的后处理模块的主要功能是对识别器提取的候选帧进行解码和过滤,以输出最终的候选帧。
该系统的整个过程也分为三个步骤:首先,输入一组数据流(图片或视频),然后将它们输入到预先训练的 [7] [8] 分类网络中,以获得不同的特征图大小。传统的VGG-16是修改后的网络,主要将VGG-16的FC6和FC7层转换为卷积层(conv6和conv7),删除所有conv8层,并添加ATROUS算法 [9] (空洞算法)。然后提取层con4_3,conv7,conv8_2,conv9_2,conv10_2和conv11_2的特征图,然后在这些特征图层上方的每个点构造6个不同比例的boxes,然后分别对其进行检测和分类以生成多个boxes。最后,将从不同特征图获得的boxes进行组合,然后使用NMS [10] (非极大值抑制)方法抑制一些重叠或不正确的boxes,以生成最终的boxes (检测结果)。
3. SSD目标检测模型
在我们的网络模型中:输入图像的大小标准化为300 × 300,系统的基本网络结构是VGG-16网络。其结构图如图1所示。
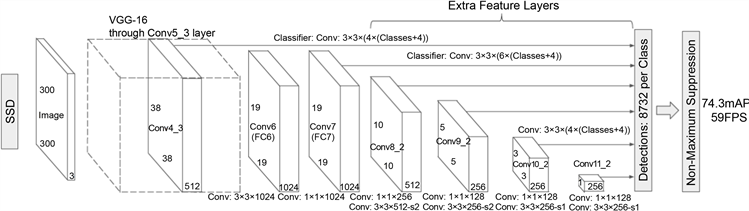
Figure 1. SSD network model structure
图1. SSD网络模型结构
VGG-16网络由一系列3 × 3卷积顺序连接组成。在conv5_3层卷积之前,将合并 stride = 2的最大值,因此该层的输出长度和宽度比原始输入减少16倍。因此该层的输出长度和宽度为[300/2] = [18.75] = 19,通道为512,即基本网络VGG-16的输出大小为512 × 19 × 19。其中,是否输出标记为Y的列被输出并发送到识别器,即最终识别器接受不同大小(5 + 1) = 6 (5个附加输出层和1个基本网络输出)的特征图,分别是10 × 10、5 × 5、3 × 3、1 × 1和两个19 × 19。
conv4_3,conv_7,conv8_2,conv7_2,conv8_2,conv9_2,conv10_2和conv11_2具有不同大小的功能图。目的是能够准确地检测出不同尺度的物体,因为在低级特征图中,接收场相对较小,而高级接收场较大,在不同特征图中的卷积可以达到多目标的目的。
在识别器模块中:该系统的识别器是使用卷积层构造的,并且卷积层的大小为(box numbers * (4 + class numbers)) * channel * 3 * 3,其中box numbers生成特征图上的网格点识别帧的数量,class numbers是类别的数量,包括背景类别,例如,一个4 × 4的特征图,总共4 × 4 = 16个网格点,每个上有3个候选点格,即box numbers = 3,类别中的信息中有p个数据,class numbers = p。识别器处理完C × W × H特征图后,它变成 (box numbers * (4 + class numbers)) * W * H,其中包含W * H * box numbers候选框。
在后处理模块中:第一个后处理是解析候选帧中的数据。每个候选帧由4 + class numbers数据组成:四个位置信息x,y,w,h和class numbers类别信息。如下:
(1)
其中
,
,
,
:所标识物品的宽度坐标,中心点的高度坐标以及物品的高度和宽度。
,
是输入图像的宽度和高度,
,
是候选帧所在的网格的坐标。候选框所在的要素地图的宽度和高度。
,
是相应默认框的默认标准化宽度和高度。有关类别信息,则选择最大的类别:
(2)
Default box生成规则为:
以要素地图上每个点的中点为中心(offset = 0.5),生成一系列同心的默认框(然后,中心点的坐标将被逐步乘以steps,这等效于从要素地图位置进行映射回到原始地图位置)。
使用不同大小的m (在SSD300中为m = 6)特征图进行预测。最低特征图的比例值是
,最高是
。其他层通过以下公式计算:
(3)
使用不同的比率值[1, 2, 3, 1/2, 1/3],通过以下公式计算默认框的宽度w和高度h:
(4)
对于ratio = 0,指定的比例如下,即有6个不同的默认框:
(5)
我们的模型的损失函数分为两部分:计算相应的默认框和目标类别的置信损失以及相应的位置回归。
从匹配到地面真相的默认框的数量在哪里;alpha参数用于调整置信度损失和位置损失之间的比率。默认alpha = 1。
位置回归使用平滑损失,损失函数为:
(6)
置信度损失是典型的softmax损失:
(7)
第二步是在处理后使用NMS (非最大抑制)过滤候选框:当两个候选框的IOU超过框阈值时,将丢弃置信度低的候选框。
4. 实验结果与分析
在本文中,对给定的数据集进行了实验。为了证明该方法的有效性,本文选择了几种当前主流的深度学习对象检测算法进行比较,包括Fast RCNN和YOLO。在精度比较方面,我们选择mAP,即均值平均精度。计算公式如下:
(8)
其中AP代表平均精度,这是通过精度和召回率获得的。精度代表预测的n个阳性样本中真实阳性的数量与预测的n个阳性样本的比例。召回率表示预测的n个阳性样品中真实阳性与模型测试的所有样品中真实阳性的比例。在多标签图像分类中,首先将训练后的模型获得的所有测试样本的置信度得分按降序排序,然后逐步选择n张图片,计算每张图片的精度和召回率,并计算出与各召回率相对应的精度。通过平均值即AP求出的平均精度,即对应于一个类别的平均精度,他表示某个类别中与模型对应的AP的平均值,然后可以得到mAP。
从表1、表2中可以看出,与其他方法相比,SSD目标检测算法的mAP提高了约5%。

Table 1. Compared mean average precision table
表1. 均值平均精度比较表
Table 2. Compared average precision (no security) table
表2. 平均精度(无异常)比较表
细节点:
估计的运行时间:从接收输入到启动算法的正常运行时间分为两部分。第一部分是五秒钟的视频流质量判断。如果视频流正常,则算法开始运行。从打开到返回总共需要大约二十秒钟。
输入:该算法有两个主要输入。第一个是RTSP流的地址;第二个是返回预警信息时的安全令牌。
输入数据来自从工地摄像机实时传输的视频流数据。传输数据的质量与摄像机的质量,网络速度和视频流的设置有关。
数据格式为RTSP视频流格式。RTSP的一般格式如图2:
该算法的输出为警报信息,主要由警报图像组成。开启算法后,输出的返回值采用JSON格式。返回参数为:
1) 状态0成功打开,其他状态关闭;
2) “ ERRORMSG”是发生错误时的错误消息,否则为空。
当算法正常运行时,识别目标时的输出为警报图像,警报时间,警报类型等。
检测效果图如图3,可以看出无论是白天还是夜晚,我们的模型都可以正确检测出未带安全帽的人员。
5. 结论与未来工作
通常,智能视频监控系统大致由两部分组成,即智能视频分析处理子系统和网络视频监控系统。其中,智能视频分析子系统负责实时分析由关键摄像机捕获的连续视频图像内容,分析并记录图片中的各种目标情况。一旦目标运动情况违反预设规则,就会通过网络将其发送到系统。告警信息。网络视频监控子系统的功能是在接收到来自智能视频分析子系统的告警信息后,按照预设的规则,将告警输出,录像,云台等功能链接在一起。该视频监控系统也由这两部分组成,其基本功能主要分为三个主要部分:读取由摄像头发给视频分析服务器的RTSP视频流;实时分析视频流的算法模型;确定目标将警报图像发送到平台,并将其保存在视频分析服务器中。该系统具有以下优点:
1) 在安全帽算法中,由于工地上的人员基本上都带有安全帽,导致缺乏负样本。通过互联网上开放的环境进行搜索,获取负样本与工地的正样本进行混合来对模型进行训练和优化。
2) 在数据集的制作中,我们结合了网上先进的预训练模型,再使用我们标记的工地数据集进行微调。再通过长时间的收集容易出错的场景的数据,对模型进行针对性的优化来确保模型可以胜任日常检测的使用。
基金项目
四川省青年科技创新研究团队专项计划项目(2019JDTD0023)。