1. 引言
目前随着科学技术的迅速发展,数据库的信息量也在不断增大,随之提升的还有数据挖掘的技术,即人们从大量繁琐而复杂的信息中收集数据的能力也得到了很大的提高 [1]。大量数据的获取和存储非常方便,但若想从这些数据中发现潜在的规律,预测未来的发展趋势是存在一定困难的。因此如何有效地利用这庞大的数据,并从中分析数据的价值成为当下研究的热点之一。
据报道,从2013年到2020年七年的时间内,美国市场上的鳄梨数量翻了两番,达到了123.1万吨。在此期间,欧洲鳄梨市场的规模增长了5倍,达到了66.7万吨,增长主要是由秘鲁和其他鳄梨来源国推动的 [2]。2020年,欧洲的人均鳄梨消费量为1.11公斤,而令人难以置信的是2003年欧洲的鳄梨人均销量竟然只有区区0.23公斤。尽管欧洲的鳄梨消费量也一直在稳步增长,但仍仅为美国的三分之一。2003年,美国的人均消费量为1.05公斤,目前的鳄梨人均销量为3.71公斤。2019年哈斯鳄梨消费研究(Haas Avocado Consumption Study)显示,尽管在这样的情况下,仍有近50%的美国家庭不吃鳄梨,这意味着如果加以推广美国鳄梨市场的销量可能翻倍 [3]。然而,要增加产量和保持价格稳定,是存在一定难度的,仍有很多工作要做。如果欧洲的消费量与美国相当,那么欧洲市场的规模将增加两倍,达到近200万吨 [4]。但是要实现这一目标将是非常困难的,需要做好推广工作。在这样的背景下,对鳄梨价格的预测就显得尤为重要了。本文便根据往年的鳄梨价格数据,建立了相应的模型,进行了对未来鳄梨价格趋势的预测。
目前国内外价格预测的研究主要有以下两个方向:
1) 市场模拟间接预测方法,利用市场价格由供需关系和市场主体行为形成的机制,通过预测市场的供给和需求情况模拟市场交易得到市场价格,这种方法考虑系统条件和约束来模拟实际市场情况,可以得到更加符合实际的有效的出清价格信息 [5]。但是要由市场模拟得到精确的市场价格预测结果,市场的基础数据必须充分详细准确,但目前市场的数据规模巨大、复杂,同时精确预测是目前仍待研究的问题,因此市场模拟间接预测的方法难以应用到实际生活中。
2) 数据分析直接预测方法,该方法利用大量数据分析挖掘市场价格的自身规律以及和其他相关因素的数据联系并进行数学建模,得到市场价格预测模型,以数学建模方法不同的主要有时间序列分析法、多元回归方法、人工神经网络、支持向量机、组合方法等类别。
为了得到一种具有较强通用性和较高预测效果的价格预测方法,通过阅读文献发现近年来部分学者将随机森林回归方法应用在股票价格预测等领域,取得了较好的效果,而股票价格预测与水果市场价格预测具有较强的相似性,同时大量的研究表明随机森林模型的泛化能力很强、对输入数据的误差不敏感且具备分析输入特征重要程度等优点,有很强的通用性,因此本文利用随机森林方法对鳄梨市场价格进行预测。
2. 数据来源及预处理
本文使用的数据来自kaggle数据库(https://www.kaggle.com),该数据集是关于美国各个地区的鳄梨价格数据,一共包含了18,249行13列数据,13列数据分别对应着13个变量,其中每列数据分别为Date (日期)、Average Price (平均价格)、Total Volume (总成交量)、4046 (PLU为4046的鳄梨售出总数)、4225 (PLU为4225的鳄梨售出总数)、4770 (PLU为4770的鳄梨售出总数)、Total Bags (总包)、Small Bags (小包)、Large Bags (大包)、XLarge Bags (超大包)、type (类型)、year (年)和region (地区),由于数据量过大,本文只展示原始数据的部分情况,在Python软件中实现显示数据前几行的操作,如表1所示,显示的是原始数据的前五行。
通过对数据的查看,我们可以发现,其中鳄梨的类型(type)分为两类,conventional (传统的鳄梨)和organic (有机的鳄梨),地区(region)分为美国的54个地区,分别为Albany,Atlanta,Baltimore Washington,Boise,Boston,Buffalo Rochester,California,Charlotte,Chicago,Cincinnati Dayton,Columbus,Dallas Ft Worth,Denver,Detroit,Grand Rapids,Great Lakes,Harrisburg Scranton,Hartford Springfield,Houston,Indianapolis,Jacksonville,Las Vegas,Los Angeles,Louisville,Miami Ft Lauderdale,Midsouth,Nashville,New Orleans Mobile,New York,Northeast,Northern New England,Orlando,Philadelphia,Phoenix Tucson,Pittsburgh,Plains,Portland,Raleigh Greensboro,Richmond Norfolk,Roanoke,Sacramento,San Diego,San Francisco,Seattle,South Carolina,South Central,Southeast,Spokane,St Louis,Syracuse,Tampa,Total US,West,West Tex New Mexico。
通过对传统鳄梨和有机鳄梨的销量及平均价格的关系绘制相应的图形,得到的分布图如图1所示,从分布图中可以看出,有机的鳄梨平均价格相较传统的鳄梨价格要偏高一些,而且有机鳄梨的销售量也要比传统鳄梨的销售量高一些,由此可以看出,随着全球经济的不断发展,人们的生活水平也在不断的提升,追求生活品质的同时人们对食品的质量要求也在不断提高,人们普遍认为有机食品是更健康的选择,越来越多的人开始追求食用有机食品。因此,有机鳄梨尽管价格要高于传统鳄梨,但其销量却也能高于传统鳄梨。
再将不同地区的两种鳄梨平均价格情况用条形图展示出来,其分布如图2所示,从图中我们可以看出有机的鳄梨价格偏高一些,其中San Francisco和Hartford Springfield以及New York这三个地区的无论是传统的还是有机的鳄梨价格相较于其他地区都要更高一些。这可能是由不同地区的经济发展状况存在一定的差异导致的。而San Francisco和Hartford Springfield及New York这三个地区的经济水平要高于其他地区,所以可能会造成其物价也高于其他地区的情况,毕竟不同地区的物价和当地的经济发展状况是息息相关的。

Figure 1. The average price distribution of avocados
图1. 鳄梨的平均价格分布
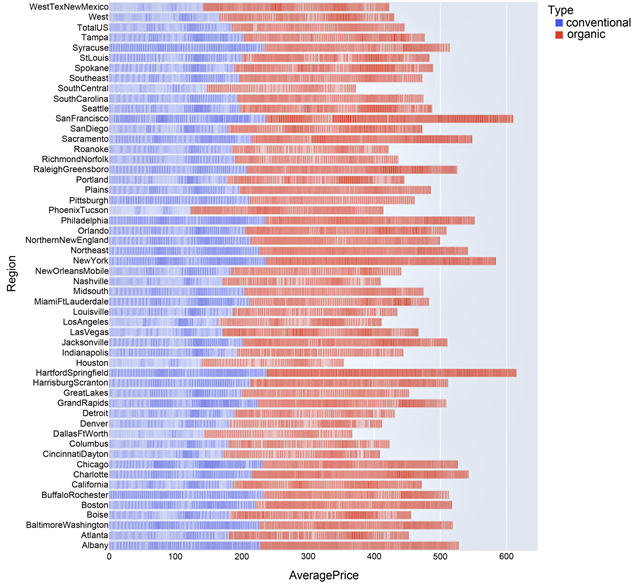
Figure 2. Average price distribution of avocados by region
图2. 不同地区的鳄梨平均价格分布图
3. 数据建模
3.1. 模型介绍
决策树算法是一种用于进行决策分析的方法,其通过对概率的计算,并进行判断最终获得的所计算的概率期望值大于等于零的情况,以此来评估在已知项目存在的风险和项目的可行性的情形下,事情发生的概率及各种的问题出现的可能性 [6]。这是一种很直观的方法,其使用概率来对事物进行分析,并最终通过图形展示出来。因为它的绘制方式与树的分支类似,所以将这个用来决策的分支称为决策树。决策树学习在资料探勘的过程中也十分常见。在这个过程中我们可以采用递归式的方法来进行树的剪枝。在剪枝过程中如果遇到不能再进行分割,或者已经形成一个单独的可以被应用于某一分支的类的,就表明该递归过程已完成了。而随机森林分类器实际上就是应用许多结合起来的决策树的分类结果,从而达到提升分类的正确率的目的 [7] [8] [9]。下面是决策树算法的具体介绍。
决策树由根节点,叶子节点以及非叶子节点组成 [10] [11] [12]。通过对训练集进行回归分析,生成从根节点到叶子节点的路径分析出路径规则。根据路径规则对新数据进行分类或预测。CART是基于信息熵,通过Gini系数最小原则指标来进行节点分裂,对训练集
所输入得空间划分相应的区域,利用递归式的方法将每个样本划入其所对应的区域,并以此得出确定的输出值,其算法步骤如下:
假设自变量特征为j,该特征的取值为s。假设取值s将特征j的空间划分两个区域,其表达式如下:
1) 依次遍历计算每个切分点
的损失函数(loss function, LF),并选取损失函数最小的切分点。
其中,
,
分别为
,
区间内的输出平均值。
2) 将划分的两部分迚行计算切点,依次进行,直到不能继续划分。
3) 将输入空间划分成M个部分
,最终生成的决策树为:
而Pearson相关系数是取值范围在−1和1之间的一种用来描述自变量与因变量之间的相关程度大小的方法,相关性大小可通过Pearson相关系数的绝对值来进行比较,其绝对值越大,则代表相关性越强。大于0代表正相关,小于0代表负相关 [13]。其计算公式为:
其中
是自变量,
是因变量。
随机森林属于算法原理就是由多个弱分类器组合成一个强分类器 [14]。其采用bootstrap抽样方法来对训练集进行随机有放回的抽样,这里假设抽取m个样本,并在bagging的基础上对每棵决策树进行随机特征的选择,然后即可对这m个样本分别建立决策树模型,在决策树模型中先进行一次分类,可以得到m个分类结果,再对这m个结果进行投票,选择最高票数的分类结果作为最终的随机森林预测类别。随机森林算法的步骤分为如下几步:首先输入训练集D,利用bootstrap抽样形成k个训练子集Dk,再从原始全部特征中随机抽取m个特征,并利用特征对训练子集Dk进行训练,然后将随机选择的m个特征做出最优切分,分别得出这k颗决策树的预测结果,最后根据决策树分类得到的k个预测结果,进行预测结果的投票操作,将得票数最高的分类结果作为最终的随机森林预测类别。
为了提高随机森林算法的预测效果,本文尝试将特征选择方法与改进的网格搜索法相结合,从而实现对鳄梨价格的预测。在建立模型之前首先利用Pearson特征选择方法删除部分无关的数据特征,再利用改进的网格搜索法对决策树的参数进行调优,选择适当的参数进行建模,通过优化后的k颗决策树所构成的随机森林来得到预测结果。其算法过程如图3所示。

Figure 3. Random forest model based on Pearson feature selection
图3. 基于Pearson特征选择的随机森林模型
3.2. 建立模型
在建立模型之前先对部分变量名称进行调整,将“4046”重新命名为“Small/Med Hass”,将“4225”重新命名为“Large Hass”,将“4770”重新命名为“Extra Large Hass”,然后通过求各变量之间的相关性系数,来判断变量之间的关系。
相关性系数是介于[−1, +1]之间的。当相关性系数介于[−1, 0]之间时,表明变量呈负相关;当相关性系数介于[0, 1]之间时,表明变量呈正相关关系;当相关性系数为0时,变量之间不存在相关性。相关性系数越接近1,变量之间的相关性越强,相关系数越接近0,则认为变量之间的相关性很弱。当相关性系数的绝对值处于不同的区间范围时,对应有不同的说法,当其介于0.1~0.3之间时,认为两变量呈弱相关;当其介于0.3~0.5之间时,认为存在中度相关;当其大于0.5时,则认为两变量具有强相关性。
将各变量之间的相关关系绘制成热能图如图4所示。从图中我们不难发现,本研究中平均价格和年份与其他变量的相关性不是特别的强,而其余变量之间却均存在很强的相关性,原因主要是由于这些其他的变量均与销售量的联系十分紧密。
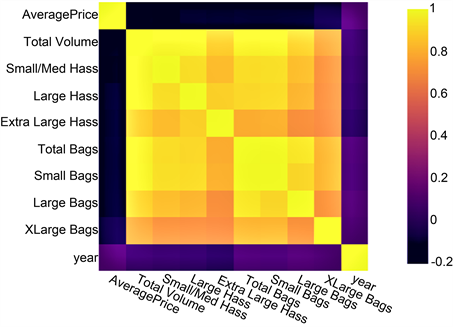
Figure 4. A heat diagram of the correlation between variables
图4. 各变量之间的相关关系热能图
在建立模型之前本文首先对数据进行了特征的筛选,通过软件实现,选择得分最高的四个变量作为特征变量,分别为“Total Volume”(总成交量),“Total Bags”(总包),“type”(类型),“region”(地区)。选择这几个特征变量之后需要进行数据集的划分,划分数据集之后对决策树进行调参,参数调整过程中max_leaf_nodes值对应的Mean Absolute Error值如表2所示。从表中可以看出,在当max_leaf_nodes值由5变50时Mean Absolute Error值减少了0.033,当max_leaf_nodes值由50变500时Mean Absolute Error值减少了0.05,而当max_leaf_nodes值由500变5000时Mean Absolute Error值仅减少了0.003,变化并不大,说明此时提升max_leaf_nodes值效果不大,因此最终选择max_leaf_nodes值为500。
本研究分别采用了两种方法来对鳄梨价格进行预测,两种方法分别为决策树算法和随机森林算法,并对两种算法的预测结果进行了比较。其中决策树的Mean Absolute Error值为0.247,决定系数R2值为0.646,而随机森林得到的Mean Absolute Error值为0.118,决定系数R2值达到了0.820。通过Mean Absolute Error值和决定系数R2的对比结果来看随机森林的预测效果都明显优于决策树。采用五折交叉验证将数据集划分为五份,选取一份作为测试集,另外四份作为训练集,并重复五次,每次选取不同的训练集。对每次训练都求出平均绝对误差,并队伍此轮显得平均绝对误差求均值,结果如表3所示。
通过以上预测结果的平均误差的对比,我们可以看出本文所采用的经过特征筛选后的随机森林模型取得了较高的预测精度,较相同条件下的决策树平均误差而言相对减少了12.9%。由多次测试的误差分布来看,随机森林模型的预测效果较为稳定,误差的标准差也比较小,而决策树的多次预测误差标准差比较大,预测效果的波动较大,认为其预测能力不够稳定。不难发现,经过特征筛选的随机森林模型的预测精度相比一般模型有一定的提高,说明了特征筛选对提高模型的预测误差具有正向作用。另外从预测模型的训练时间来看,我们发现随机森林模型所需时间更短,具有更高的计算效率,更加适应大规模样本的训练。综上所述,从整体效果来看,经过特征筛选的随机森林回归模型具有较强的优越性。

Table 3. Five fold cross validation results
表3. 五折交叉验证结果
4. 结论与建议
本文将随机森林回归应用到鳄梨的价格预测中,利用随机森林特征重要度分析的功能对输入的特征进行筛选,从而降低了无关变量的干扰,进一步提高了模型的预测精度,根据鳄梨市场数据特点构建出价格预测模型。本文所采用经过特征筛选后的随机森林模型得到的Mean Absolute Error值为0.118,决定系数R2值达到了0.820,该模型取得了较高的预测精度,较相同条件下的决策树平均误差而言相对减少了12.9%。由多次测试的误差分布来看,随机森林模型的预测效果比较稳定,误差的标准差也比较小,通过验证分析得到的结果也表明本文建立的预测模型具有较高的稳定性和预测精度。因此本文提出的基于随机森林回归的特征筛选的预测模型是一种通用性较强且可行的思路和方法。
经研究分析,认为基于随机森林的预测模型具有较高效果的原因主要为:随机森林回归的子模型决策回归树具有简单的树结构能更好地适应市场价格和实时影响的大量输入;装袋算法这种集成学习方法的应用,避免了模型过拟合,相对其他模型减小了模型的泛化误差。因此进一步研究可以考虑:1) 结合随机森林回归树模型能同时接受输入多种类型数据的特点,充分考虑市场中各类难以量化的因素对市场价格的影响进行预测;2) 利用随机森林的装袋算法,以其他市场价格预测模型作为子模型构造新的集成学习模型并测试其预测效果。
同时,通过本文的研究,也能为除了鳄梨以外的其他商品提供价格预测的建议及方向,即在进行价格预测的时候可以考虑多种方法结合以提高预测模型的预测精度。在进行预测时,特征变量的选择也十分重要,选择合适的特征变量可以提高预测的精确度,甚至还能够加快模型的预测速度,从而达到提高模型的泛化能力及预测效率的目的。
NOTES
*通讯作者。