1. 引言
传统上,参数估计是基于单一模型的假设,该模型的选择是一个模型选择的过程。这种方法忽视了模型的不确定性 [1],导致参数估计的过拟合。
在许多应用领域进行模型参数估计时,考虑模型不确定性的情况越来越普遍。这种不确定性之所以会出现,是因为我们不能确保模型选择过程总是会选择相同的最佳模型。传统上,经过模型选择过程挑选出最佳模型之后,再使用挑选出的最佳模型来进行参数估计。该参数的估计依赖于这个最佳模型的选择。由于模型选择的方法一般依赖于挑选出的最佳模型,这样就会丢弃其他模型所特有的信息。这种方法忽视了模型的不确定性。为了解决模型选择带来的这些问题,需要考虑在某种程度上接受所有的候选模型。考虑到这个问题的重要性,人们开始深入学习并研究模型平均方法,其作为一种简单、通用、易理解的方法,应用于多个模型的研究过程。这解决了出现的模型不确定性问题。模型平均方法的出现起初更多应用在点估计上,后来随着理论研究的深入,区间估计也开始使用这种方法。
模型平均有Beyes模型平均 [2] 和频率模型平均 [3] 两方面,本文主要介绍频率模型平均。在频率方法
的设置中,模型平均估计
定义为单个模型估计的加权和:
其中
是模型
下的估计,模型权重
是由信息准则决定的,例如AIC [4],和式是基于R个候选模型的集合。
目前已经提出了一些构造频率模型平均置信区间的方法。形式为
的Wald区间,其中
是标准正态分布的
分位数。其依赖于
的标准差
的精确估计,Hjort和Claeskens [5] 表明
估计的困难性,以及Wald区间在覆盖率方面表现很差。Buckland [6] [7] 等人提出了
的一些选择。
另一个可选的构造频率模型平均置信区间的方法是MATA-Wald [8] 方法,由Turek和Fletcher [7] 提出。在MATA方法中,每个置信限度定义为满足单个模型Wald区间错误率的和等于期望错误率的结果,MATA在小样本时的覆盖率方面要强于现有的模型平均的方法。Fletcher和Turek [9] 将MATA的构造方式应用到轮廓似然区间中,提出了模型平均轮廓似然区间,轮廓似然区间在偏态数据的拟合上表现出明显的优势。Kabaila [10] [11] [12] 等人研究了MATA置信区间的一些性质。Yu [13] 等人提出了MATA区间的转换版本。
本文利用单模型下参数的Bootastrap置信区间以及类比MATA-Wald模型平均置信区间的构造原理,构造了Bootstrap模型平均置信区间,通过模拟计算来说明其优势。第二部分,介绍了Wald区间的构造方法以及相应的标准差的估计、MATA-Wald模型平均置信区间的方法及Bootstrap模型平均置信区间的构造方法。第三部分,分别在响应变量是正态和偏态的情形下进行了模拟研究,从上下错误率、覆盖率和平均区间长度分别比较了Wald区间、MATA区间和Bootstrap区间的表现性能。第四部分,对本文的研究进行了总结。
2. 方法及思想
假设考虑R个候选模型
,感兴趣的参数
对所有模型都有相同的解释意义。假设模型平均估计
近似服从正态分布,其中
和
分别对应模型
的权重和参数
的估计。计算参数
的
Wald置信区间形式为
其中
是标准正态分布的
分位数,
是
方差的估计。尽管这种方法很简单,但是计算一个合适的
的估计是很困难的。由Burnham [5] 和Anderson等人提出的两种
估计为
(2.1)
(2.2)
是自由度为
的t分布的分位数,
是与模型
相关的残差的自由度。由Cauchy-Schwarz不等式可知,
,则根据(2.2)式得到的Wald置信区间比由(2.1)式得到的Wald置信区间长度宽,故其覆盖率大,本文我们只考虑(2.2)式得到的Wald置信区间。Wald区间在覆盖率方面表现得很差,并且忽视了
的非正态性 [8],下面基于单个模型来获取参数
的模型平均置信区间。
假设恰有一个候选模型是真实的,记
为未知的指示变量,如果模型
为真,则
否则
,假设我们知道
的真实分布记为
,参数
的置信区间
满足下列方程
(2.3)
因为
是未知的,我们用与模型相对应的基于某种信息准则的模型权重
来估计(2.3)中的
,则参数
的置信区间
满足下列方程
(2.4)
如果不知道
的真实分布,假设每个模型的学生化的参数估计
服从标准正态分布或t分布,即
为标准正态分布或者t分布的分布函数,获取的参数
的
的置信区间即为z版本或者
t版本的MATA区间,本文我们考虑t版本的MATA区间 [8]。
但是如果相应变量是偏态的,或者正态假设不明显时,使用Wald区间和MATA区间会导致比较差的覆盖率。本文利用参数Bootstrap 方法构造变量的分布,即用参数估计
的Bootstrap分布
来近似(2.4)中的分布
,从而计算参数的模型平均置信区间。
设样本
来自模型
的分布
容量为n的样本,
是参数
的极大似然估计。下面给出计算参数模型平均估计的计算步骤。
l 对于来自分布为
的样本,选取Bootstrap样本量B,比如
;
n 对于
,从
产生容量为n的Bootstrap样本;
n 计算出
的极大似然估计
;
n 由
给出
的Bootstrap分布
。
求
和
满足下列方程
(2.5)
其中
为某种信息准则下模型
的权重。那么
为参数
的Bootstrap模型平均置信区间。
3. 数据模拟
本节对Bootstrap模型平均置信区间的优良性进行评判,并与已有的与Wald区间,MATA区间进行比较,最终从区间的频率性质和区间长度这两方面进行评价。区间的频率性质用以下两个指标:覆盖率;上下错误率。
进行模型选择时,权重的选择是基于信息准则AIC
其中
为第i个模型的AIC。
3.1. 线性模型
考虑正态线性模型,包括两个预测变量
和
,5个候选模型
。所有模型的响应变量
,并且
指定如下:
随意设置
,选择
,这样所有的模型都倾向于依据样本容量的范围分配非平凡权重。
和
是在每轮模拟中随机产生的,并且
,样本量大小分别取
这17种情形(见表1)。对于感兴趣的参数选取为预测空间
各个点的
值,为了简单起见,这里只考虑
生成分布的50%处分位数和
生成分布的90%处分位数。这里模拟次数为105次。在计算Bootstrap模型平均置信区间时,Bootstrap样本量取
。
图1展示了响应变量均值的三种区间的上下错误率和覆盖率随样本容量n的变化形势,图1的左图上方为三种区间的上错误率。为了表示方便,下错误率取负值后展示在图1的左图下方。表1展示了3种区间估计的平均区间长度。由图1和表1可以看出:
1) 下错误率方面,Bootstrap区间要好于其它两种区间,更接近名义错误率。上错率和覆盖率方面,Bootstrap区间整体要好于Wald区间,略逊于MATA区间。
2) 平均区间长度方面,Bootstrap区间是最窄的。
3) 随着样本量的增加,三种区间估计方法都逐渐接近名义覆盖率,并且平均区间长度区别越来越小。
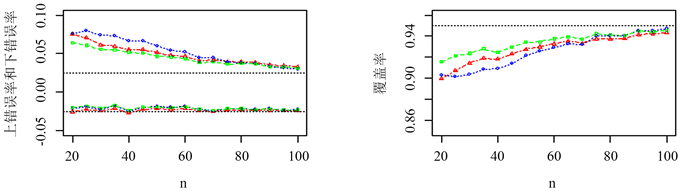
Figure 1. Error rate and coverage of Bootstrap (red triangle), MATA (green square) and Wald (blue circle) interval estimates of linear model mean
图1. 线性模型均值的Bootstrap (红色三角)、MATA (绿色方形)、Wald (蓝色圆形)区间估计的上下错误率、覆盖率

Table 1. Average interval lengths of three interval estimates of linear model mean
表1. 线性模型均值的三种区间估计的平均区间长度
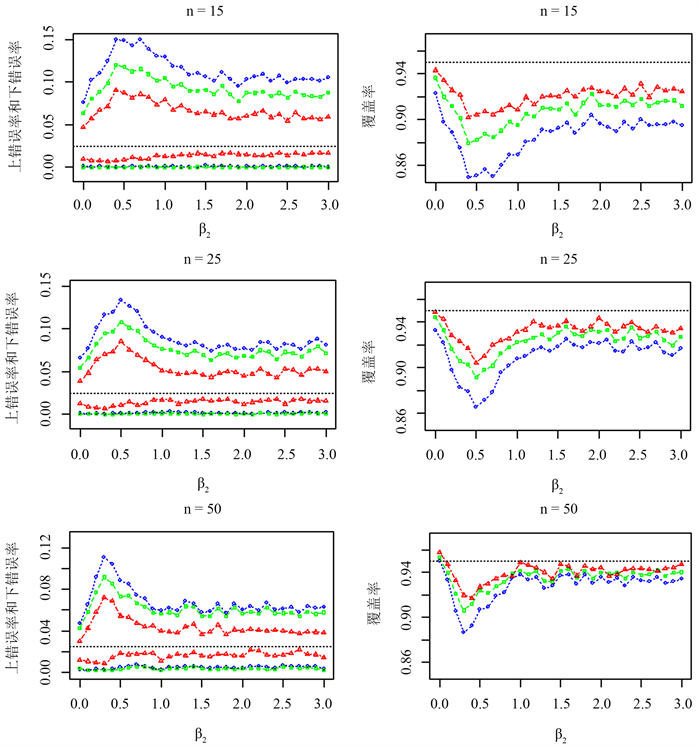
Figure 2. Upper and lower error rates and coverage of Bootstrap (red triangle), MATA (green square) and Wald (blue circle) interval estimates of the mean of lognormal model
图2. 对数正态模型均值的Bootstrap (红色三角)、MATA (绿色方形)、Wald (蓝色圆形)区间估计的上下错误率、覆盖率
Table 2. Average interval lengths of three interval estimates of lognormal model when n = 50
表2. n = 50时对数正态模型的三种区间估计的平均区间长度
3.2. 对数正态模型
下面考虑对数正态的偏态数据情形。设观察值
满足
,我们希望去估计
期望
。模型平均基于以下两个模型:
未指定
我们设置
,
。我们分别考虑了
及样本容量
的不同情形,模型数据由
产生。这里模拟次数为5000次。在计算Bootstrap模型平均置信区间时,Bootstrap样本量取
。
图2展示了
三种情形下均值的三种区间的上下错误率和覆盖率随
的变化形势,图2的左图上方为三种区间的上错误率。为了表示方便,下错误率取负值后展示在图1的左图下方。表2给出了样本量
时三种区间的平均区间长度。由图2和表2可以看出
1) 当样本容量较小时,比如
,Bootstrap区间的上、下错误率和覆盖率要明显优于MATA区间和Wald区间,并且更接近名义上、下错误率2.5%和名义置信水平95%。随着样本容量的增大,三种区间的表现性能越来越接近,Bootstrap区间的上、下错误率和覆盖率总是优于MATA区间和Wald2区间,并且更接近名义水平。
2) 当
逐渐增大时,也就是两个模型
和
之间的差异越来越大时,三种模型平均置信区间的表现越来越好。
3) 在样本量
时,Wald区间长度最短。Bootstrap区间的平均区间长度略低于MATA区间,并且随着
的增大,两种区间的平均区间长度的相对差异也很小。
4. 结论
无论是Wald区间还是MATA区间,都是在参数估计或者参数估计的变换近似服从正态分布的假设下构建的,本文提出了Bootstrap模型平均置信区间,它是基于将参数估计的Bootstrap分布来近似其真实分布从而得到的一种模型平均置信区间。
当响应变量是正态数据时,我们研究了在线性正态模型下Wald区间、MATA区间和Bootstrap区间的表现性能。模拟结果表明,Bootstrap数区间在下错误率方面优势明显,一直稳定在名义下错误率附近。上错误率方面,Bootstrap区间整体上也是仅次于MATA区间,并且在平均区间长度方面,Bootstrap区间较其他三种区间是最窄的。可以看出数Bootstrap 区间缩短了区间长度,牺牲了一些覆盖率的表现性能。
当响应变量是偏态数据时,我们研究了对数正态模型下三种区间的表现性能。模拟结果表明,Bootstrap区间要优于其他两种置信区间。特别是在上错误率方面,Bootstrap区间提供了更低的更接近名义水平的上错误率。除此之外,下错误率和覆盖率也优于其他两种区间。在样本量很小时,Bootstrap区间的优势最明显。随着样本容量的增加,三种区间的表现越来越接近。在平均区间长度方面,MATA区间和Bootstrap区间相差不大。
因此,当响应变量是偏态的,甚至正态假设不明显时,都会导致MATA区间或者Wald区间的错误率和覆盖率很差。Bootstrap区间适应性比其它两个区间要强。特别是在响应变量是偏态的情况下,覆盖率是最好的。所以在不知道响应变量是否是正态的情况下,Bootstrap区间是一个不错的选择。