1. 引言
艾滋病,全称获得性免疫缺陷综合症(acquired immune deficiency syndrome, AIDS),是由艾滋病病毒(HIV)引起并导致人类免疫功能受损,对人类造成严重危害的一种恶性传染性疾病 [1]。艾滋病具有传染性强、致死率高的特点,并且目前尚无有效的彻底治愈方法,已经成为一个全球性的公共卫生问题 [2]。本病的传播途径主要是母婴传播、性传播和血液传播等 [3]。
四川是一个人口大省,艾滋病的发病人数也在全国位居前列,所以对艾滋病的预测和防控就显得尤为重要。国内外研究传染病发病人数的方法有很多,例如时间序列模型、灰色预测模型、动力学模型 [4]、机器学习方法等,并且都取得了不错的效果,其中应用最广的是时间序列模型。但采用灰色GM(1,1)模型和机器学习方法对四川省艾滋病发病人数进行分析的文献相对较少,基于此,为了比较这两种方法在预测效果上的优劣以及得到较为可靠的未来艾滋病发病人数,本文采用残差修正GM(1,1)灰色预测模型以及BP神经网络模型来对四川省艾滋病发病人数进行预测并比较,从而探究四川省艾滋病的流行趋势,为疾病的预防控制提供参考意见。
2. 研究方法与模型建立
2.1. 残差修正GM(1,1)模型
灰色系统理论是以部分信息已知、部分信息未知的小样本、贫信息的不确定性系统为研究对象。GM(1,1)模型作为灰色预测模型的代表,由于其所用原始数据较少,预测精度较高等优点近年来被广泛地应用于医学卫生领域 [5]。
2.1.1. 建立GM(1,1)模型
GM(1,1)模型建立过程如下:
1) 构建原始数据序列:设原始数据序列为
,对原始数据做一次累
加生成处理,生成的序列为:
,其中,
,
;
2) 均值生成:对一次累加生成值
进行均值处理,得到数据序列:
,其中
,
,
,通常可取
;
3) 建立白化微分方程:建立灰色GM(1,1)白化形式的微分方程:
其中
表示发展系数,
表示灰色作用量。利用
、
和
分别建立数据矩阵B和数据向量
:
,
求解
和
:
4) 得出预测序列:
,其中:
,
;
将预测模型得到的序列作递减还原,得到估计的原始序列,其中:
,
.
以及
。
2.1.2. 检验精度
选择后验差检验法来确定预测序列
与原始序列
的拟合精度。检验方式的标准如表1所示 [6],其中方差比
(
为残差数列标准差,
为原始数列标准差):

Table 1. Model accuracy comparison table
表1. 模型精度对照表
2.1.3. GM(1,1)模型的修正
当数据的模型精度等级为2~4级时,认为GM(1,1)模型的预测效果不好,这时选择对模型进行修正。在此可以对原始数据序列与拟合数据序列计算得到的残差序列也使用灰色GM(1,1)模型进行拟合预测,最后再将得到的残差预测数据
加到已经算出的预测值
,
上,用这样的方法来修正原灰色GM(1,1)模型。同样残差序列使用2.1.1中的方法来进行拟合,得到残差拟合值:
此时修正后的预测数据序列可表示为
,其中
,
。
对残差修正后的预测数据进行精度检验,当模型的精度达到合格时,GM(1,1)模型残差修正停止。
2.2. BP神经网络算法
BP神经网络(back-propagation neural network)是一种多层前馈的神经网络(见图1),该网络的主要特点是信号向前传递,误差反向传递;在前向传递的过程中,需要输入的数据作为输入信号从输入层经过隐藏层逐层处理,到输出层输出;如果与真实输出信号存在误差,网络就转入误差反向传播过程,并根据误差大小来调整各层神经元之间的连接权值和偏倚。当误差达到预期时,网络学习的过程就会结束,之后得到调整后的输出值 [7] [8]。
对于隐藏层层数的确定问题,有理论证明:隐藏层节点数越多,网络结构越复杂,网络的训练误差越小;但如果隐藏层节点数过多,虽然网络的续联误差会变小,但是容易出现过度拟合的情况。在研究中一般取隐藏层层数为1~2,隐藏层节点数为
,其中m代表输入层节点数,n代表输出层节点数,a是0~10之间的常数 [9]。

Figure 1. BP neural network structure diagram
图1. BP神经网络结构图
2.3. 预测评价指标
本文用平均绝对误差(MAE)、平均绝对百分比误差(MAPE)用于评价模型的预测效果。计算公式如下:
3. 实证研究分析
3.1. 数据来源
本文收集了2005~2017年的四川省艾滋病发病人数月度数据,所有数据来自中国公共卫生科学数据中心(https://www.phsciencedata.cn/Share/)。文中的发病人数由艾滋病感染对象的发病日期按季度累计得到。以2005年第1季度到2016年第4季度作为训练样本,2017年第1季度到第4季度作为验证样本。
3.2. 残差修正GM(1,1)模型建立
3.2.1. GM(1,1)模型
将2005~2016年的数据按季度分为四个部分,对每个部分进行GM(1,1)模型的建立,得到每个季度的方差比C和小概率误差P如表2所示:
Table 2. Model-level evaluation of the number of patients in each quarter
表2. 各季度发病人数模型级评价
由上表可以看出,第1季度和第2季度模型合格;第3季度和第4季度的模型精确等级不高,模型不合格,此时对这两个季度的模型进行修正。
3.2.2. 修正GM(1,1)模型
采用GM(1,1)模型残差修正建模方法,利用模型残差修正对第3季度和第4季度建模,经过一次修正,模型精度等级变为1级。此时得到第3季度、第4季度的残差拟合模型分别为:
由上述公式计算出2005~2016年第3、4季度的残差拟合值并加到3.2.1算出的原拟合值上,由此得到的值作为最终的第3、4季度四川省艾滋病发病人数的预测值,并与实际数据进行对比,得到四川省2005~2017年各季度艾滋病发病人数实际值和预测值的对比图,如图2所示:

Figure 2. Comparison of GM(1,1) model prediction
图2. GM(1,1)模型预测对比图
3.3. BP神经网络模型
由于BP神经网络模型采用的是sigmoid转换函数,所以输入和输出的数据处理在0~1之间(称为数据的归一化处理)。本研究将数据按
进行标准化后分析,处理后的数据可得到表3。
Table 3. Standardization of raw data in each quarter
表3. 各季度原数据标准化
利用标准化后的数据建立BP神经网络模型,将它作为输入数据,即从2005年第1季度开始到2016年第4季度结束,以每四季度标准化的数据作为输入,四个季度后的下一季度标准化数据作为输出,如此滚动运行。例以2005年第1、2、3、4季度标准化数据作为输入,2006年第1季度的标准化数据作为输出等,对神经网络进行训练。
本研究正向传递过程的输入信号长度为
,输出信号长度为1,隐藏层取1,根据经验公式
隐藏层节点数根据经验公式取4~13,通过调节隐藏层节点数,获得了10个不同的训练结果。选择其中MAE、MAPE最小的训练结果作为最终的BP神经网络模型的参数。各节点数对应的MAE和MAPE如表4所示:
Table 4. Evaluation of the corresponding number of nodes in the hidden layer of the BP neural network model
表4. BP神经网络模型隐藏层各节点数对应的评价
由表4可以看出,当隐藏层节点数为13时,MAE和MAPE最小,分别为237、6.97%,因此确定隐藏层节点数为13。建立好BP神经网络模型后对数据进行拟合和预测,并与实际发病人数数据进行对比,得到四川省2005~2017年各季度艾滋病发病人数实际值和预测值的对比图,如图3所示:
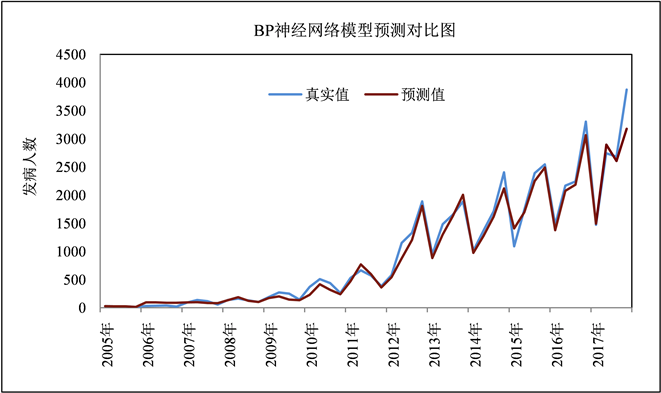
Figure 3. Comparison of BP neural network model prediction
图3. BP神经网络模型预测对比图
4. 模型预测结果比较
本文使用2005第1季度~2016年第4季度作为测试数据,2017年第1季度到第4季度作验证数据,预测结果如表5所示:
Table 5. Comparison of prediction results between GM(1,1) and BP neural network (2017)
表5. GM(1,1)与BP神经网络的预测结果比较(2017年)
由表5可见,利用残差修正GM(1,1)模型最终得到2017年四川省艾滋病发病人数预测的MAE、MAPE分别为1019、40.23%,利用BP神经网络模型最终得到2017年四川省艾滋病发病人数预测的MAE、MAPE分别为236、6.97%。通过比较MAE、MAPE以及绝对误差这三个评价指标,发现BP神经网络模型的预测精度高于残差修正GM(1,1)模型,在预测四川省艾滋病发病人数方面具有更好效果,并且两种模型的预测结果表明四川省艾滋病发病人数仍然会呈现出上升的趋势。因此有关部门应提前做好应对措施、制定防控方案。
5. 讨论
艾滋病在全球范围内受到极大重视,正确地预测艾滋病的发展趋势有助于艾滋病的控制和防护。
时间序列分析是利用数据序列的时间效应和记忆效应通过建立模型来预测疾病的未来发展趋势,GM(1,1)灰色预测模型属于一种短期的时间预测模型,优点是所需样本少,利用较少的数据预测数据的发展趋势,再对模型得到的残差进行修正,可达到较大的精确度;机器学习算法近年来产生了巨大的发展,其中BP神经网络在各界运用较为广泛,技术相对成熟,在数据方面也发挥了极大的作用。
所以,本研究决定使用GM(1,1)灰色预测模型和BP神经网络模型对四川省艾滋病发病人数进行预测并比较,结果证明BP神经网络机器学习模型的预测要比残差修正GM(1,1)模型的更加精确,可以用于艾滋病发病人数的有效预测。但是该模型与其他常用的数学模型一样,主要是从数据来反映疾病的发展趋势,得到的结果是建立在历年数据的基础上,如果数据参数发生了变化,预测的值也相应地会发生改变。另外,在实际生活中,艾滋病的发病因素还有很多未被考虑到本文的模型中,这些因素也会影响模型的预测效果。因此,在制定艾滋病的预防措施时,还应该考虑其他因素对预测结果的影响。
致谢
在本次论文的撰写中,我得到了我的导师戴教授的精心指导,不管是从开始定方向还是在查资料,查数据准备的过程中,一直都耐心地给予我指导和意见,使我在撰写论文方面都有了较大提高。在此,我对戴老师表示诚挚的感谢以及真心的祝福。
还要感谢的是各位师兄师姐,没有师兄师姐的解惑以及对我的学业的帮助,是没有这篇论文产生的,在论文写作期间,他们不仅给予了我学习上的帮助,创造了学习的氛围,更会在生活上给我提出很有效的建议。再次感谢戴老师和各位师兄师姐的帮助!