1. 引言
传统推荐系统方法主要包含基于内容的推荐方法、基于人口统计学的方法和协同过滤方法 [1] [2] [3],其中运用和后续发展最多的是协同过滤方法。原始协同过滤方法通过研究用户对项目的评分矩阵,分解出用户特征和项目特征,然后基于用户特征和项目特征为用户推荐相似项目或者为用户推荐与其相似的用户喜欢过的物品。近年来随着深度学习的兴起,深度学习也被运用在了推荐系统中并且大大提升了推荐准确度。深度学习在推荐系统中的运用主要分为三类,分别是DeepFM类模型,卷积神经网络和循环神经网络 [4] [5] [6],其中多层感知机和卷积神经网络主要用来学习输入数据的特征 [7],学习特征之间的相互关系,而循环神经网络主要用来处理用户行为序列 [8],从序列中学习用户的特征演化。
序列推荐是推荐系统的一个研究方向,序列推荐 [9] 通过研究用户按照时间产生项目交互序列,从序列之间的相关性出发研究用户兴趣随时间变化的特征,从而做出推荐。
序列推荐的挑战主要有两点:1) 用户的偏好和需求是随时间动态变化的 [10],并且用户与项目的交互通常发生在连续的上下文中;2) 如何从长序列中学习长期序列之间的依赖关系和高阶顺序依赖关系 [11]。对于这两个挑战,目前的解决方法是高阶马尔可夫模型和循环神经网络类模型。高阶马尔可夫模型 [12] 可以学习序列数据之间的高阶依赖关系,但其模型需要估计的参数随着阶数的增长呈指数型增加,不适用于长序列数据。传统的循环神经网络 [13] 如RNN除了可以学习序列数据之间的依赖关系,还能学习数据的顺序关系,但当序列过长时,RNN会出现梯度消失/爆炸的问题。后来出现的LSTM模型通过引入门控单元一定程度解决了RNN的长距离依赖问题,但是RNN,LSTM等循环神经网络等都对序列的次序有很强的假设:1) 任何临近的商品在序列中都是高阶依赖关系;2) 输入的数据有严格的次序相关性。从这两个假设可知,当输入的数据不是严格符合次序相关性时,循环神经网络类模型的表达效果不佳。
从上面可以看出,目前主流的两种方法都有着一定的限制性。为了更准确地学习用户序列的特征,另一个突破点是结合多个方法的混合模型。例如,Tang等人 [14] 提出了分别使用RNN和注意力对不同距离关系的序列进行特征捕捉,从而达到了对序列的长距离依赖关系的学习。Li等人 [15] 则使用GRU预测出用户对电影的体裁偏好,然后结合改进的协同过滤进行电影推荐。Li等人 [16] 还提出了DESR的模型,分别使用混合高斯模型和胶囊网络学习用户的偏好和需求。这些模型都将用户数据分段,然后根据数据的特点分别使用不同的模型,这样做的好处是可以根据数据的特点选择更适合的模型。
然而以上模型的推荐准则都是使用例如用户偏好和物品相似度等标量进行推荐,用户偏好和物品的相似度越高,则该物品越容易被推荐。但是单一标量准则忽略了用户的偏好方向,只能表达标量所表达的信息,容易为用户推荐相似度高但是不符合用户偏好/需求的物品。根据这个情况,DESR模型首次提出了偏好方向的概念,偏好方向定义为短期需求指向长期偏好,使用偏好方向进行推荐的优点是:综合了用户的长期偏好和近期的需求从而提高了推荐的准确性,减少了不相关推荐的风险。
尽管使用偏好方向的推荐综合考虑了用户的长期偏好和短期需求使得推荐更准确,但是DESR模型对于用户的长期偏好只是固定聚类表达了其单一的长期偏好,并没有考虑其长期偏好之间的依赖性和顺序演化,同样对于用户的短期需求也没有考虑其短期序列之间的依赖性。综上所述,可以建立模型来模拟用户长期和短期序列之间的依赖性和顺序演化,提升推荐的准确性。本文的贡献:
1) 根据用户行为习惯个性化划分用户序列。根据每个用户不同的行为习惯特征,自适应地划分用户的长期和短期序列;
2) 使用带选择器的多头自注意力机制进行用户潜在长期偏好提取并学习长期偏好之间的依赖性和顺序演化,增加用户本质长期偏好的权重,减小噪声行为对长期偏好提取的影响;
3) 使用带注意力的胶囊网络表示用户短期需求,通过增加模型对用户近期需求的关注度来抽取用户短期需求序列的潜在特征;
4) 基于短期需求指向长期偏好的用户偏好向量的方向进行推荐,使得模型专注于用户偏好和短期需求,提升模型推荐的准确性。
2. 相关工作
2.1. 带选择器的多头自注意力机制
多头自注意力机制在自然语言处理的任务中获得了很好的运用,其优点主要在于将输入序列映射到多个不同的特征子空间从而更好的学习输入元素之间的依赖关系。结合了位置向量的多头自注意力机制克服了RNN类模型中的长序列数据导致的梯度消失/爆炸问题,还可以并行运算,增加了模型的工程实现能力。在本文中,使用结合选择器的多头自注意力机制,可以很好地提取用户长期序列中潜在的长期偏好,减少噪声行为的影响。
2.1.1. 多头自注意力机制
假定有一个h个头的多头自注意力模型,输入序列为
,其中第i个头的计算过程如下:
(1)
(2)
其中
,
是放缩因子,作用是防止softmax函数由于内层的内积过大而造成梯度爆炸/消失,dk为嵌入的维度。则多头自注意力的计算公式为:
(3)
其中WO为待学习参数矩阵,h个头的注意力权重计算除了使用点积,还可以使用拼接或者感知机等方式进行结合,本文使用点积。
多头自注意力还加入了位置向量来学习序列之间的顺序关系。位置向量加在注意力权重计算之前,加入的形式为直接与输入序列的编码相加,位置向量构造公式为:
(4)
即将ID为p的位置映射为一个dpos维的向量,其第i个元素的值为PEi(p)。
2.1.2. 选择器模块
传统自注意力网络模型考虑所有输入的元素,然而自注意力模型计算每个元素表示的时候仅仅只是将所有的输入的元素考虑在内,而没有考虑其对于当前元素的相关性。使用基于选择机制的自注意力可以针对每个计算表示的元素,动态地选择与之具有相关性的子集,然后作为输入进行后续的自注意力计算。
选择器注意力的计算过程为:
(5)
(6)
选择器模块对初始注意力权重进行sigmoid操作,保留大于阈值的权重,去掉小于阈值(本文选取阈值为0.5)的权重进而达到减小噪声影响,保留影响大的数据的作用。
2.2. 胶囊网络
胶囊网络是由Hinton [17] 提出的一种可解释性的神经网络。胶囊网络最初用于图像识别领域,相比于传统CNN模型,胶囊网络可以学习特征之间的位置关系并且可解释性更强,其结构见图1:
图1中,胶囊网络的通过一种迭代的“动态路由”算法抽取输入数据的特征,通过动态路由算法,多次迭代之后输出的向量会聚集成可以代表之前输入向量高层特征。假设有底层输入特征
,经过胶囊网络提取高层特征
的计算过程如下:
(7)
(8)
(9)
(10)
其中Wi由反向传播确定,ci的值由动态路由算法确定。Squash()称为挤压操作,用来“挤压”向量的模值且不改变向量方向。
动态路由算法确定ci值的伪代码如下:
3. 基于方向性偏好的个性化序列推荐模型
3.1. 模型结构
本文提出的基于方向性偏好的个性化序列推荐模型SDESR的框架如图2所示,其主要分为四部分:1) 输入层:输入用户的历史行为序列并自适应地划分为长期序列和短期序列,然后进行编码;2) 长期偏好提取层:使用带选择器的多头自注意力机制基于长期序列提取用户的长期偏好;3) 短期需求推断层:使用基于注意力的胶囊网络提取高层用户短期需求特征;4) 方向性偏好推荐层:根据前两步求出的用户长期偏好和短期需求向量构建用户的偏好向量,最后根据偏好向量推荐符合用户短期需求和长期偏好的物品加入用户的推荐列表。
3.2. 自适应划分历史行为序列
由于每个用户的行为习惯不同,其偏好的形成和演化过程也不同,所以需要根据用户的行为习惯来划分用户的行为序列,于是本文提出习惯因子特征habit_factor,根据习惯因子特征自适应地划分用户短期行为序列会话。
假定有用户u的行为序列嵌入
,每个行为发生的时间戳与上一次行为的时间间隔序列为
,对于一个包含
个行为的序列片段
,其习惯因子特征为:
(11)
其中D()表示方差。习惯因子特征刻画了该段行为序列中每个行为发生的时间与前一行为发生的时间紧密性以及该段行为序列内部联系的紧密性。给定阈值hf (由数据的分布特点决定),本文将
的行为划分成同一段短期行为序列。
3.3. 长期偏好提取
由于每个人的偏好是不断演化的,并且受到之前的行为影响会丢弃或者新生成一些长期偏好,所以在用户的序列数据中存在一些噪声行为,根据此考虑在学习用户长序列数据特征时“去伪存真”,使用选择器自注意力保留用户本质的偏好,去除不相关的噪声行为的影响。
长期偏好提取部分以用户长期序列编码矩阵作为输入,输出用户的长期偏好向量,具体结构框架如图3所示:

Figure 3. Selector multi-head attention network framework
图3. 选择器多头注意力网络框架
给定用户长期序列行为的编码矩阵
,首先输入带h个头的选择器多头自注意力网络学习用户行为在不同特征子空间的依赖和顺序关系,其中第i个头的计算过程为:
(12)
(13)
(14)
其中
,
,
,
为经过位置编码后的序列矩阵,
。最后将所有头的输出拼接并线性映射成k个长期偏好表示
:
(15)
(16)
其中WC和WO为待学习的参数。
选择器多头自注意力模型的目标函数为:
(17)
其中ylong为用户目标推荐列表中所有标签的均值。
3.4. 短期需求提取
用户当前的需求主要受近期的行为影响,并且影响程度随着时间的前溯减弱。基于此,在胶囊网络中引入注意力机制,对胶囊网络的输出进行注意力加权来对用户短期需求进行提取。
模型输入用户的短期行为序列
,输出提取的用户短期需求特征
。模型训练时,第i段短期行为序列的下一次行为嵌入
作为其标签。
预测需求特征
的计算过程如下:假定胶囊网络有d个输出胶囊,对一组含有M条记录的样本,输出其d个胶囊分别学习到的d个特征
,将第M条记录嵌入作为注意力的查询Qm分别对d个特征进行注意力加权:
(18)
(19)
其中
,
,
。
虽然用户最近一次行为最能代表其近期需求,但是推荐列表不是一次性的推荐,而是对用户未来一段时间的预测,需要考虑用户需求的演化性,所以为了更好地预测用户未来一段时间的行为,增加La作为辅助损失,自定义损失函数Loss如下:
(20)
(21)
(22)
其中,decapj是第j组短期序列的标签,
是第j组短期序列的第i个预测需求特征。
是第j组短期序列的d个预测特征的均值,decap_sj是第j组短期序列的下s条标签的均值,
是辅助损失的权重。增加了辅助损失的模型更能综合表达用户未来一段时间的综合需求。
3.5. 偏好向量计算及推荐
给定目标用户的k个长期偏好向量
,短期需求向量decap,则用户的偏好向量一共有k个,其中第 个偏好向量scapi为:
(23)
给定候选物品嵌入
,模型为每个用户推荐固定个数LR个物品,根据角度矩阵Angle和距离矩阵Dis构成的得分矩阵Score给出推荐:
(24)
(25)
(26)
其中
,
,
为Dis的最大值。
根据推荐准则Score可以看出,对于候选物品集合中的每一个物品,若其方向与偏好向量方向夹角越小,其距离短期需求向量的距离越小,则其被推荐的概率就越大。
4. 实验结果与分析
4.1. 数据集及实验设置
4.1.1. 数据集
本文在真实电影数据集movielens-1m上进行实验,该数据集包含了电影推荐服务[movielens] (http://movielens.org)的5星评分和自由文本标记活动的信息。其中有9742部电影的100,836个评级和3683个标签。
4.1.2. 实验设置
本文仿真实验在macOS 11.4环境下进行,使用python3.8,基于pytorch框架进行开发实验。
本文将数据集中用户的电影历史记录按照时间戳排序,将用户按照8:2的比例划分数据集。首先基于电影标签数据使用Struc2Vec图嵌入方法构建每部电影节点与其对应标签节点的图并计算电影节点的嵌入表示。根据Struc2Vec算法原理,拥有相同或者相似的标签的电影节点其嵌入表示向量之间的距离也越近。
4.2. 评价指标
给定目标用户的预测推荐列表
和标签电影列表
,基于方向偏好的评价指标定义如下:
1) 推荐列表准确度
(27)
(28)
其中ti为推荐列表中的待推荐电影嵌入,dismax为距离归一化参数,取所有电影嵌入之间距离的最大值。
2) 长期偏好准确度
(29)
acc_pre是衡量推荐列表中待推荐电影与目标用户的长期偏好的准确度,acc_pre值越大,则表示推荐列表越符合目标用户的长期偏好。
3) 短期需求准确度
(30)
acc_de是衡量待推荐电影符合目标用户短期需求的准确度,acc_de值越大,则推荐列表越符合目标用户短期需求。
4.3. 对比模型
为了验证本文提出的SDESR模型的有效性,选取以下模型作为对比模型:
1) RAND:基于随机的方法,基于本文的数据集是从用户电影历史记录中没有的电影中随机生成推荐。
2) LSTM:长短时记忆网络,可以学习序列之间的顺序性和长距离依赖关系,相比于RNN其能在更长的序列中有更好的表现。
3) KFN:原理与KNN相似,即根据邻居的行为提供推荐。
4) DESR:首次提出使用方向性偏好进行推荐的模型。
4.4. 实验结果与分析
4.4.1. 模型训练超参数分析
本节主要分析SDESR模型中两个主要模型的超参数影响。首先是带选择器的多头自注意力网络的超参数precap_num,其表示多头自注意力网络输出长期偏好的个数,实验结果见图4:

Figure 4. The influence of precap_num on the MSE
图4. 自注意力网络输出长期偏好个数对模型精度影响
从图4可以看出,当precap_num = 5时,模型的MSE最小,对于用户的预测偏好最准确,于是选取输出长期偏好个数k = 5。
其次是带注意力的胶囊网络训练超参数:decap_len和kernel_size,分别表示胶囊网络损失函数的标签个数和胶囊网络中每个胶囊抽取序列的窗口长度。实验结果如图5:
 (a) 胶囊窗口长度对模型结果影响
(a) 胶囊窗口长度对模型结果影响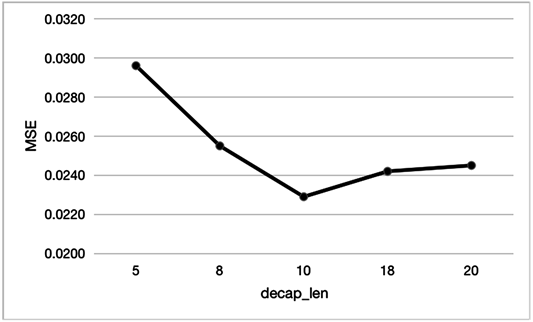 (b) 标签个数对模型结果影响
(b) 标签个数对模型结果影响
Figure 5. Capsule network model hyper parameters
图5. 胶囊网络模型超参数
从图5可以看出,当窗口长度kernel_size = 7,标签个数decap_len = 10时,模型效果最好。
最后是模型的推荐超参数m_base,其表示得分矩阵中短期需求距离矩阵的权重,当m_base值越大时,符合用户短期需求的物品越会被推荐,实验的结果见图6。
从图6可以看出,随着m_base值增加,模型的长期偏好准确性上升幅度很小,短期需求准确性上升幅度最大,总体准确性上升幅度也随着短期需求上升而上升。根据实验结果,本文选取m_base = 0.9。
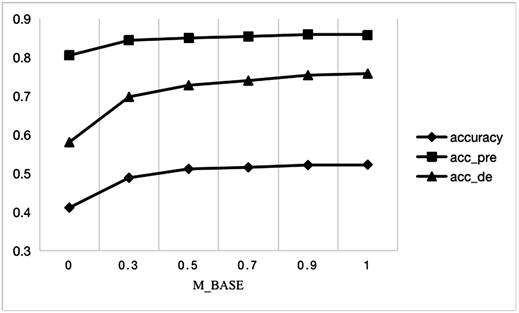
Figure 6. The influence of m_base on the model recommendation effect
图6. 得分矩阵超参数对模型推荐效果影响
4.4.2. 模型结果分析
基于上一节确定的超参数值,在为用户推荐LR = 10个电影的情况下,对比了本文提出的模型和对比模型之间的效果,对比结果见表1:

Table 1. Comparison results of different models
表1. 不同模型对比结果
从表1可以看出,本文提出的SDESR模型在三个指标下的表现效果均为最佳,其中总体准确度accuracy相比DESR模型提升了52%,相比传统序列推荐模型LSTM提升了15%,相比KFN和RAND分别提升了超过80%。在长期偏好准确度acc_pre方面,SDESR模型比DESR模型提升了28%。短期需求准确度acc_de方面,SDESR模型相比DESR提升了76%。综上所述,SDESR模型在长期偏好和短期需求表达方面表现均优于对比模型,相比基于标量的推荐,基于偏好向量的推荐更加符合用户偏好。
4.4.3. 模型意外性推荐效果分析
一个好的推荐系统不仅要推荐符合用户偏好的项目,还要有开拓用户视野的能力,本节探究了m_base参数对模型多样化和差异化推荐的影响,定义模型多样性指标div和差异性指标difference:
(31)
(32)
其中LH为目标用户历史记录中的电影数,div反映了推荐列表中各推荐项目之间的不同程度,difference反映了推荐列表与用户历史记录的差异程度。实验结果见图7:
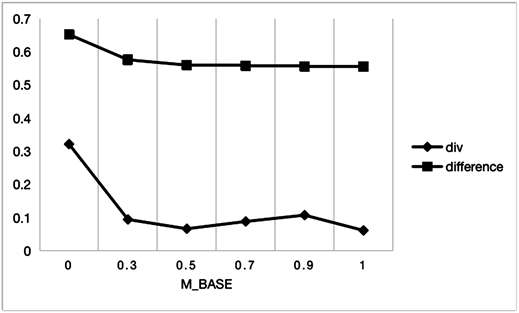
Figure 7. The influence of m_base on model diversity and differentiated recommendation
图7. m_base对模型多样性和差异化推荐的影响
从图7可以看出,随着m_base值增加,即当模型越来越关注用户短期需求时,模型的多样性和差异性效果均下降。其中模型推荐差异性随着m_base值增加下降幅度较小,而多样性下降和波动幅度较大,说明m_base值主要影响模型的推荐多样性,即模型越关注用户的短期需求,模型推荐的物品越单一化。
5. 结束语
目前大部分推荐模型主要基于用户偏好与项目之间的相似度等标量进行推荐,忽略了用户的偏好方向,本文基于方向性偏好,综合用户长期偏好和短期需求为用户推荐既符合用户偏好又专注用户需求的物品。本文提出的基于方向性偏好的个性化序列推荐模型,利用用户的序列数据,使用带选择器的多头自注意力机制学习长序列数据中的顺序关系和依赖关系,保留重要特征,去除噪声信息,有效地提取了用户的长期偏好,并且专注用户的近期需求,通过提高模型对于用户近期的需求信息的关注来提高用户的短期需求预测准确度从而提升模型的推荐效果。实验结果表明,本文提出的模型相比于原模型在长期偏好和短期需求方面的推断准确性有很大的提升,使得本文模型的推荐效果进一步提升,但本文提出的模型在多样性推荐和差异性推荐方面还未有很有效的解决方法,希望在未来的工作中提供更加多样化的推荐。