1. 引言
目前生活的社会是一个高速发展的社会,科技发达,信息流通,人们之间的交流越来越密切,生活也越来越方便,大数据就是这个高科技时代的产物。国际数据公司(IDC)报告称,2011年全球创造了约1.8 ZB (=1021字节)的数据 [1]。如物联网,网络物理系统,智慧城市 [2],智能医疗,智能导航 [3] 等每天都会产生和收集大量数据 [4]。大数据时代给日常工作生活带来了巨大便利,如果能够合理并高效地对海量数据进行处理,就有可能产生巨大的商业价值。
近年来人工智能技术高速发展,已经广泛应用在社会生活的各个方面 [5] [6],成为人类社会智能进化的重要技术手段之一。而人工智能的发展决定了大数据技术的发展,由于人工智能技术具有强大的特征提取和抽象能力,整合多源信息,处理异构数据。大数据技术也为人工智能技术的发展提供了充足的训练样本。两者相得益彰。
人工智能算法——支持向量机(SVM)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。同时支持向量机也是一种广泛应用的机器学习算法,例如在在医疗,金融生物信息等领域。Devikanniga等 [7] 使用支持向量机进行有效诊断肝病,Farhadian等 [8] 使用支持向量机设计了牙周病决策诊断支持系统。Sivaram等 [9] 使用支持向量机进行金融产品收益预测。Byvatov等 [10] 将支持向量机应用在生物信息学中。
大数据时代,在本地计算资源和存储资源有限的情况下,对于大规模数据处理是一件很苦难的事情,而云计算服务可以很好地解决这个问题,本地设备可以将数据外包给计算能力和存储能力都很强的云服务器,并向云服务器支付一定的费用,从而换取相应的计算服务,将支持向量机(SVM)外包训练给云计算服务提供商,有利于不熟悉支持向量机技术和本地计算资源有限的数据所有者使用完整的支持向量机分类功能。但支持向量机的训练通常需要庞大的数据样本进行支撑,因此将支持向量机训练外包给云服务器是合理高效的。
但是将支持向量机训练给云服务器会产生数据安全问题,可能会导致意思隐私数据泄露。例如,病人的生理特征数据以及诊疗数据关系到病人的个人隐私,如果可能会造成社会歧视并且对病人造成更大的心理伤害。金融机构的用户数据关系到用户的财产安全,一旦泄露可能会使不法分子有机可乘,给用户带来财产损失。而训练产生的机器学习模型也是模型拥有者的知识产权,其中包含着商业价值,一旦泄露可能会导致巨大损失。因此在对数据进行外包计算时,需要在不影响计算结果的情况下。设计加密算法保护数据的隐私性。一些现有的工作也考虑外包训练支持向量机的数据的隐私性,Wang等 [11] 使用同态加密技术外包了医疗物联网支持向量机模型的训练,Liu等 [12] 使用顺序最小优化技术实现了用于药物发现支持向量机模型的安全外包训练,Lin等 [13] 使用随机变换技术外包训练支持向量机模型,Serrano等 [14] 使用同态加密外包训练了支持向量机模型。
对于支持向量机的隐私保护训练,Laur等 [15] 和Omer等 [16] 随后提出了基于安全多方计算和HE技术的分布式隐私数据支持向量机的隐私保护协议。Lin等 [13] 提出了在外包设置中训练支持向量机的协议。他们通过随机线性变换扰动数据来实现隐私保护。最近,Shen等 [17] 和Wang等 [11] 分别研究了智慧城市和互联网中隐私保护的SVM训练。尽管如此,他们的协议都涉及耗时的同态加密操作。而耗时的同态加密会增加客户端开销。同时对于训练样本密文数据的访问模式,即:标签相同的密文数据对应的明文数据标签也相同。
本文讨论了外包SVM训练中的数据隐私以及分类标签隐私问题,并设计了一种从在加密数据中训练SVM的方案。使用Householder矩阵对样本数据进行加密,使用Householder矩阵加密可以降低计算复杂度,并无需公开数据的实际内容。同时使用置换矩阵盲化样本与其分类标签的对应关系,并且加密后的数据不影响最终的分类模型。同时由于使用的是加密后的样本数据,因此服务提供商无法获得真实的支持向量机模型,除非使用来自数据提供者发送的加密样本测试数据。同时还设计了一个三方框架,来保证训练过程安全可靠并且保持高效。包括数据提供者(Data provider)、云服务器(Cloud server)、分类测试者(Data tester),基本流程如下所示:首先数据提供者将数据进行加密,然后将SVM训练任务外包给云服务器,云服务计算获得相应的模型参数后将其发送给数据提供者,最终机器学习模型部署在数据提供者方以供其他数据测试者进行分类测试。具体来说,本文的贡献可以概括如下:
1) 协议从两个方面实现了隐私保护的目标。(1,1)云服务器无法知道样本数据内容和样本数据的分类标签的真实数据。(1,2)由于使用了Householder矩阵对数据进行加密,云服务器无法生成真实的支持向量机训练模型。
2) 协议是高效的。通过使用Householder矩阵、置换矩阵实现隐私保护要求,避免了沉重的(完全)同态加密操作。隐私保护技术的简洁性和易用性使本文设计的协议获得了高性能。此外,通过外包,数据提供者(DP)实现了可观的计算节省。去后进行了大量的实验来验证理论主张。
本文的剩余组织部分如下:第2节介绍系统架构,威胁模型和设计目标。第3节列出本文使用的基本数学工具。第4节具体给出了PPOSVM协议的设计,并在第5节分析了它的正确性、安全性和效率,第6节对PPOSVM协议性能进行了实验评估。最后总结工作在第7节。
2. 系统架构、威胁模型和设计目标
2.1. 系统架构
如图1所示,PPOSVM协议由三方组成,数据提供者(Data provider)、云服务器(Cloud server)、分类测试者(Data tester)。
DP,数据提供者拥有大量的训练样本数据,他希望通过云服务器训练相应的支持向量机分类模型。由于样本数据的内容存在潜在的敏感性,他希望云服务器无法知道真实的样本数据内容以及样本数据对应的分类标签。
CS,它是一个云/边缘服务器,具有强大的计算、数据分析和存储资源。出于经济目的,它可以与资源受限的客户共享计算资源,帮助他们完成计算任务。然而,它可能是好奇的。
DT,当支持向量机模型部署到DP上时,他可以将测试样本发送到DP以获取分类结果。
2.2. 威胁模型
系统中的云服务器采用与之前的隐私保护机器学习分类服务相似的“诚实但好奇”的威胁模型。假设云服务器对数据提供者的数据样本内容,数据样本和分类标签的对应关系以及训练后的支持向量机模型感兴趣,但是它只能访问中间结果,不能访问任何最终结果。假设云服务器会遵守协议内容,同时努力推断自己感兴趣的内容,并且假设各方之间不会串通。
2.3. 设计目标
本文设计云辅助的隐私保护支持向量机外包训练(PPOSVM)协议,以确保系统中的所有各方都能高效、安全地运行,并最终实现准确的结果。现在,详细阐述以下目标
1) 正确性,如果所有参与者都忠实地执行分配的计算任务,该协议能够最终获得正确的支持向量机模型。
2) 高效性,由于将支持向量机模型训练任务外包到云服务器,最终PPOSVM协议所设计的计算过程成本必须要低于本地计算的成本。
3) 输入隐私,样本数据内容和其分类标签可能包含敏感信息,所以应该对云服务器不可见。
4) 输出隐私,训练后的支持向量机模型含有商业价值,应该向云服务器保密。
3. 预备知识
在这一节中将介绍一些基本概念和设计中使用的工具。
3.1. 支持向量机
支持向量机(SVM),首先由Vapnik [18] 提出,是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。SVM模型是将实例表示为空间中的点,这样映射就使得单独类别的实例被尽可能宽的明显的间隔分开。然后,将新的实例映射到同一空间,并基于它们落在间隔的哪一侧来预测所属类别。除了进行线性分类之外,SVM还可以使用所谓的核技巧有效地进行非线性分类,将其输入隐式映射到高维特征空间中。假设有m个训练样本实例,每个实例由
包含第i个实例的属性和它的类别标签
。支持向量机最终求解以下二次规划问题,找到最优超平面
。
(1)
在目标函数中最小化
意味着最大化两类数据之间的边际。通过拉格朗日乘子法将有约束问题转
换为无约束问题,最后求解SVM可以转化为求解SVM的对偶问题。
(2)
将(2)转换为矩阵形式为
(3)
其中训练数据样本矩阵
,n表示数据样本维数,m表示训练所需的数据样本数量,
为拉格朗日乘子的
对角矩阵,对角线为拉格朗日乘子
,Y为数据样本的分类标签的m维向量,
。
表示对D中所有元素求和。
3.2. 豪斯霍尔德变换(Householder)变换
在本文的设计中使用了一种特殊的正交变换Householder变换,由n维向量
生成的Householder变换H可以被定义为:
这里
Q是一个
的正交矩阵,I是单位矩阵。对于任何
,
。
3.3. 随机置换及其在矩阵上的作用
n阶(随机)置换
是集合
上的(随机)双射,可以表示为:
其中
是
的一个(随机)重排。任一随机置换可由一个众所周知的高效洗牌算
法Alg.1生成 [16]。
给定一个n阶置换
,一个
阶矩阵
,
定义A上的左置换
为
,
例如,取
的排列
,
矩阵A为
.
所以
.
接下来给出一个简单但有用的性质
引理1.对于任何
矩阵
,一个n维列向量
,一个n阶置换
,有
.
4. 隐私保护的支持向量机训练外包(PPOSVM)协议
本节将介绍设计的PPOSVM协议,用m来表示数据拥有者训练支持向量机模型所需要的样本
的量
,可能有时候需要大量数据样本来进行模型训练。根据支持向量机原理,需要使用云服务器来求解一个二次规划问题,并最终由云服务器返回相应的训练结果参数以供数据拥有者计算支持向量机模型
。正如前文所说的,云服务器可能会对数据样本
,样本分类标签
以及支持向量机模型感到好奇。因此无法将实际的数据样本以及样本分类标签发送给云服务器。本文使用Householder矩阵Q对数据样本进行保护同时使用置换矩阵
对分类标签进行加密。
如图2所示,PPOSVM=(DPtoCSKEYGEN, DPtoCSENC, CSTraining,DPModleCon,DTTest)的具体过程如下:

Figure 2. Support vector machine training outsourcing model
图2. 支持向量机训练外包模型
1) DPtoCSKEYGEN:数据拥有者(DP)生成n维随机向量
,其中
为随机均匀选取
比特实数。同时,调用Alg.1输出n阶随机排列
,所有这些都应该由数据拥有者保密。
2) DPtoCSENC:数据拥有者对数据样本
,分类标签
进行加密,
然后数据拥有者将
和
发送给云服务器。(如图2步骤(1) (2)所示)
3) CSTraining:云服务器收到支持向量机训练任务后,执行相应的SVM训练算法,例如,SMO算法。计算相应的二次规划问题 [19] [20] [21],
(4)
其中
表示与向量q相关的Householder矩阵,
表示对矩阵
所有元素求和。获得相应满足式子(4)条件的的模型参数
。并将模型参数
返回给数据提供者。(如图2步骤(3)、(4)所示)
4) DPModleCon:数据提供者计算
。解密后的D按照行序选择
,然后使用模型参数
计算相应的支持向量机模型
。
w可以由以下式子求出
(5)
b可以由以下式子推出
由于
,两边同时乘
得
,又因为
,所以
,
即
. (6)
数据拥有者使用(5)、(6)两式可以得到SVM最优超平面,数据拥有者将SVM模型部署于自身。(如图2步骤(5)所示)
5) DTTest:在SVM模型部署到数据拥有者方时,数据测试者可以向数据拥有者发送分类请求和测试样本
,测试样本的分类结果标签
由下面的公式判定:
当数据拥有者获取分类结果标签
时,将其发送给数据测试者。(如图2步骤(6)、(7)所示)
5. 正确性、安全性和效率分析
这一节将详细分析PPOSVM协议的正确性,安全性,高效性。
5.1. 正确性分析
根据设计目标中正确性的含义,定义
定义1 隐私保护的支持向量机外包训练协议是正确的。
使用诚实但好奇的云服务器完成训练任务,那么使用加密数据进行计算不会影响最终的分类结果。支持向量机训练任务需要解决的是以下二次规划问题
(7)
加密算法使用到Householder变换矩阵Q以及随机置换矩阵
,因此将加密后的二次规划问题表示如下
(8)
经过展开后可以得到
(9)
Householder变换产生的矩阵Q为正交矩阵,而置换矩阵本质上是混淆了训练数据样本与分类标签之间的关系,根据正交矩阵的性质
,可以将式子(9)化简为
(10)
对于
,仅需要将矩阵D中所有元素求和即可。对于式子(10)获得的模型参数矩阵为
,因此数据拥有者收到加密的模型参数矩阵后,只需要对其进行解密可以获得正确的模型参数矩阵
。经过以上数学分析,PPOSVM协议可以实现与原问题相同的解决方法与结果,因此满足正确性的定义。
5.2. 安全性分析
首先讨论输入输出隐私,根据设计目标,可以证明
定理2 对于任意规模的输入矩阵
,提出的支持向量机外包训练算法满足输入隐私性。
证明:首先证明数据样本内容的隐私性,即云服务器知道加密后的训练样本矩阵
,云服务器能够恢复真实训练样本矩阵X的概率可以忽略不计。根据加密算法得到加密后的
,而
,
取决于正交矩阵Q,那么
,云服务器恢复X的概率为
.
此概率显然是微不足道的。
其次证明样本与标签对应关系的隐私性。即使云服务器知道加密后的训练样本矩阵
,云服务器能够恢复真实训练样本分类标签Y的概率可以忽略不计。
对于训练样本分类标签Y,使用随机置换对其进行加密
,
取决于随机置换
,那么
,云服务器恢复Y的概率
这显然是微不足道的。通过上述证明,可以说明设计的协议满足输入隐私。
定理3 对于任意规模的输入矩阵
,提出的支持向量机外包训练算法满足输出隐私性。
证明:在云服务器知道输出的参数矩阵
后,证明云服务器获得真实的D的概率,由于
,所以云服务器获得真实的D的概率为:
这显然是微不足道的。通过上述证明,可以说明设计的协议满足输出隐私。
5.3. 效率分析
在本节中,将展示PPOSVM协议也满足高效率要求。也就是说,与在没有云服务器帮助的情况下本地实现支持向量机的训练,设计中的数据提供者可以获得可观的计算时间节省。
在DPtoCSKEYGEN过程中,数据提供者需要进行次n随机数生成操作和m次置换操作,这是效率很高的。
在DPtoCSENC过程中,由于矩阵乘法的关联性和Householder矩阵的简洁构造,数据拥有者可以通过快速矩阵向量乘法高效地计算,避免了耗时的矩阵–矩阵乘法。即,
因此在整个支持向量机训练过程中数据提供者的时间开销是
。因此的协议可以实现以下时间节省
.
6. 实验分析和实验效果评价
为了全面评估PPOSVM协议在实践中的实际性能,在本节中对PPOSVM协议进行实验分析。为了响应设计目标中的效率要求,实验着重于模拟数据提供者和云服务器的时间开销,并将其开销与无需外包的算法进行比较。
6.1. 实验环境
DP端实验环境配置:Intel(R)Core(TM)i5-8500T 2.10GHz CPU和8GB RAM的笔记本电脑上,实验中使用Pycharm community 2021模拟数据提供者。云端实验环境配置:Intel(R)Core(TM)i7-9750H 2.6GHz和16GB RAM的MacBookPro,实验中运行Pycharm community 2021模拟云服务器。
6.2. 实验方法
一个设计良好的外包协议应该确保数据提供者节省计算时间,并且使用协议执行支持向量机训练总时间开销应该大大少于数据提供者自己完成支持向量机训练的时间开销。因此,从以下两个角度通过实验评估PPOSVM协议的有效性。1) 比较PPOSVM协议中数据提供者的时间开销与数据提供者自己完成支持向量机训练的时间开销。2) 将PPOSVM协议中数据提供者的时间开销和云服务器的时间开销的总和与数据提供者自行完成支持向量机训练的时间进行比较。
6.3. 实验结果和分析
在实验中有两个重要参数
,由于在实际应用中训练样本维数一般是固定的,因此在确定训练样本维数的情况下改变训练样本数目,进行了表1~3三组实验。

Table 1. Privacy-preserving support vector machine outsourcing training protocol experimental results ( n = 10 )
表1. 隐私保护的支持向量机外包训练协议实验结果
Table 2. Privacy-preserving support vector machine outsourcing training protocol experimental results ( n = 20 )
表2. 隐私保护的支持向量机外包训练协议实验结果
Table 3. Privacy-preserving support vector machine outsourcing training protocol experimental results ( n = 30 )
表3. 隐私保护的支持向量机外包训练协议实验结果
具体实验描述如下,固定训练样本维数
,
,
,改变训练样本数量m,m在100~200之间变化,步长为50。为了避免出现偶然的数据点,因此得到的每个数据都是算法运行10次的平均运行时间,
表示数据拥有者对数据样本以及分类标签进行Householder变换以及随机置换的时间开销,
表示数据拥有者对模型参数进行解密的时间开销,
表示支持向量机训练任务本地设备独立计算所需要的时间开销,
表示将支持向量机训练任务外包到云服务器进行计算所需要的时间开销。同时用两个指标
、
来表示设计的协议的效率。从图3和图4可以看出,随着训练样本数量不断提高,
、
两个指标也不断提升,这表明,随着训练样本数的增加,所提出的支持向量机训练外包协议可以节省更多的计算量。

Figure 3. Ratio of local computing time to protocol running time
图3. 本地计算时间和协议运行时间之比
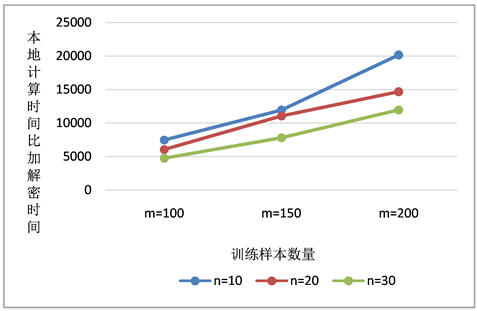
Figure 4. Ratio of local computing time to encryption and decryption time
图4. 本地计算时间和加解密时间之比
6.4. 对照比较
在这一节中比较了协议和其他的相关保护支持向量机训练外包协议的不同,如表4所示。
Table 4. Comparison of existing work
表4. 现有工作对比
7. 总结
本文提出了一种新的高效且隐私保护的外包支持向量机方案,该方案支持安全训练,以保护训练数据样本以及分类标签。同时使用了高效的Householder变换以及随机置换对数据样本以及分类标签进行加密,安全性分析表明,该方案在诚实好奇模型下是安全的。性能评估表明方案可以节省数据提供者的计算开销。美中不足的是,协议设计了支持向量机模型的训练外包。使用云服务器对其他机器学习模型的外包训练也是一个非常有趣的问题。