1. 引言
蒸发式冷凝器(EC)是一种常用于冷库降温的换热设备 [1]。EC在运行过程中,循环的喷淋水喷淋到换热管壁面,主要通过喷淋水的蒸发与对流换热将管内工艺系统的循环制冷工质的热量放散到管外空气中。在EC运行期间,喷淋水与管外壁发生热交换,使喷淋水不断蒸发,水中的盐类和杂质被浓缩,换热管外壁出现结垢,增加了管内外的传热热阻,缩短了换热管的使用寿命,增加了设备的运行成本 [2]。结垢是工业界与学术界中十分关注并且是一个长期存在的问题,90%以上的工业换热器都存在结垢问题,因此人们越来越重视对阻垢的研究 [3]。综合目前国内外研究结果得出:阻垢方法大致可分为化学阻垢、物理阻垢、绿色阻垢三类,其中使用化学阻垢剂最为普遍,但含氮和磷的传统化学阻垢剂会导致水体富营养化,且增加了水处理系统设计和污水回收或排放的困难,而绿色阻垢剂在水体中的存在不会对生态环境造成恶劣的影响 [4]。
在传统研究中,影响阻垢率的因素是多方面的,采用传统手段进行数据处理非常困难且效率低下 [2]。值得注意的是,人工神经网络技术经过几十年的发展已具备优异的非线性映射和泛化能力,只要选择合适输入变量及网络参数,其输出值可以任意精度逼近期望值 [5]。早在20世纪50年代,第一代神经网络就被提出,它的算法只有两层,主要解决线性问题,当函数稍微复杂一些,该神经网络无法得到有效解 [6]。经过后人的努力,解决了第一代神经网络所遇到的问题,为后面的研究提供了极大的帮助,大量神经网络得以构建,比如多层感知器 [7]、BP神经网络 [2]、PT神经网络 [8]、DNN神经网络 [9]、CNN神经网络 [10]、RBF神经网络 [11]、GRNN神经网络 [12] 等。目前处理非线性问题最常用的神经网络有BP与GRNN [13],本文采用PCA对网络输入数据进行降维并通过预测结果选取合适的网络模型。
为此搭建了模拟蒸发式冷凝器运行的喷淋水系统,将柠檬酸(CA)加入喷淋水中并计算出阻垢率,采用各模型进行预测并选取最优的模型。
2. 实验研究
2.1. 阻垢机理
CA是一种通过微生物发酵而产生的有机酸,分子式为C6H8O7,结构如图1所示。

Figure 1. Molecular structural formula of CA
图1. CA分子结构式
由于CA有着自身的特异性以及螯合作用,在工业中应用比较广泛 [14]。换热管壁与喷淋水换热生成的水垢主要成分是碳酸钙(CaCO3),柠檬酸会与碳酸钙在一定温度下发生化学反应,水垢就会溶于酸,在柠檬酸含量充足的情况下,水垢的溶解度会随着温度的升高而增大。
CA在水中电离过程如式(1)~式(3)所示:
(1)
(2)
(3)
2.2. 实验系统与实验原理
2.2.1. 实验系统
实验系统如图2所示,主要由循环水泵、增压水泵、模拟蒸发式冷凝器喷淋结垢实验装置、铂电阻、温度采集仪、pH采集仪、电导率采集仪、浮子流量计、电加热、补水箱等装置组成。
2.2.2. EC模拟装置
图3为模拟EC的实验装置,主要由风机、收水器、喷淋管、水槽、模拟换热管、壳体组成。
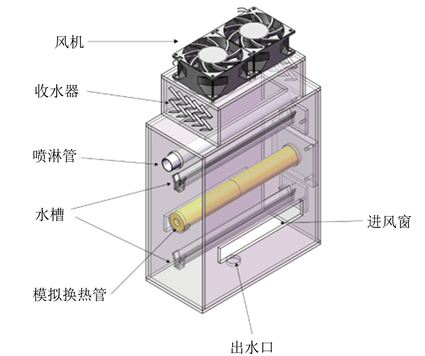
Figure 3. Simulation of countercurrent closed tower experimental device
图3. 模拟逆流闭塔实验装置
模拟换热管相关参数列于表1。

Table 1. Parameters of simulated heating tube
表1. 模拟换热管相关参数
实验装置的壳体用有机玻璃板制成,上有与风机和喷淋管的接口,两侧有进风窗,底部有出水口。进风窗长度为160 mm,宽度为25 mm,进风口顶端和换热管底部的高度差为40 mm。
2.2.3. 测试环境
实验相关条件如表2所示。
在表2条件满足之后,把喷淋水的硬度提升为1000 mg/L,并同时加入CA,此时水质波动剧烈,待稳定(0.25 h)之后每隔10 min采集一组数据。因喷淋水蒸发和垢在换热表面的析出,喷淋水的硬度会产生变化,故采用补水箱自动补水,并适时加入配好的CaCl2和NaHCO3溶液,通过监控pH值和电导率σ以使水质基本保持稳定。
阻垢率η按式(4)定义,单位为%。
(4)
式中:
与
分别为相同时刻未加CA与加CA两组实验计算所得的污垢热阻,该时刻污垢热阻按式(5)计算,单位为(m2∙℃)/W。
(5)
式中:
为t时刻的传热系数,
为实验起始时的传热系数。
传热系数K通过采集到的模拟换热管的电加热功率P、模拟换热管内壁面温度Tbi、喷淋水在模拟换热管外壁面上的平均温度Ts,结合模拟换热管几何尺寸(内外直径及管长)和导热系数,计算得到。详细的热阻测量原理参考文献 [15]。实验共获得了180组数据。
3. BP神经网络与GRNN神经网络预测结果分析
3.1. 主成分分析
水质因素(电导率σ、pH值)、实验工况因素(模拟换热管外壁面温度Tbo、喷淋水在模拟换热管外壁面上的平均温度Ts)、实验持续时间τ,均对阻垢率η有影响,各个因素间具有强非线性耦合,模型计算复杂度高。主成分分析法的思想是将高维度的相关变量转变为低维度互不相关且能代表原始数据大部分信息的新变量,降低模型计算复杂度,其流程如图4所示。
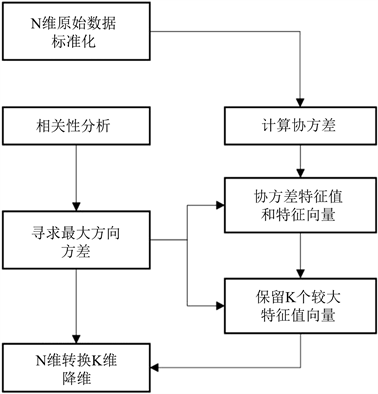
Figure 4. Flow diagram of principal component analysis
图4. 主成分分析流图
3.1.1. 各影响因素之间的相关分析
各影响因素之间的相关关系如表3所示。
Table 3. Correlation coefficient matrix of influencing factors
表3. 影响因素间相关系数矩阵
结果表明:众多因素之间有强烈的相关性。因此在建立η预测模型之前,需要采用PCA降维处理消除各影响因素间的相关性。
3.1.2. 各影响因素的主成分分析
主成分分析结果如表4所示,一共有5个主成分,主成分Y1和Y2的特征值分别为3.937和1.910,贡献率分别为58.738%和38.203%,累计贡献率达到96.94%,累计贡献率超过95%满足作为主成分的条件,说明前两个主成分能够很好代替各影响因素的主要信息。因此,选取前两个主成分Y1、Y2作为η预测模型的输入节点。
Table 4. Principal component analysis of each influencing factor
表4. 各影响因素的主成分分析
3.2. 神经网络结构及其相关评价指标
BP和GRNN神经网络的的基本结构都是由输入层、隐含层和输出层组成。
相关评价指标
用于表示神经网络预测结果的相关参数主要是:相关系数(R)、均方根误差(RMSE)、平均绝对百分比误差(MAPE),它们的表达式为式(6)~(8)。
(6)
其中:N为样本个数、x为输入值、y为输出值。
(7)
式中:ai为实际输出值,pi为预测值。
(8)
3.3. 神经网络的构建
选择180组数据中随机的144组数据作为训练样本,余下36组数据作为验证样本,分为以下几个步骤对数据进行处理:
1) 确定输入节点。未经PCA处理的参数为τ、Tbo、Ts、σ、pH值;PCA处理后的输入节点为Y1和Y2。
2) 确定隐含层节点。BP神经网络隐含层神经元个数n通常由黄金分割法按式(9)确定。GRNN神经网络隐含层节点数采用newgrnn函数设置。
(9)
式中:a为输入节点个数、b为输出节点个数、k为常数,k的范围为[1~10]。
3) 确定输出节点参数为η。
4) 归一化处理。为了使数据统一、可靠性更高、便于计算,采用式(10)的归一化函数mapminmax进行数据处理。
(10)
式中:x为被归一化的值,y为归一化之后的值。
3.4. 网络模型的训练与优化
3.4.1. BP神经网络运行结果
根据式(9)得出未经PCA处理的隐含层节点数范围为[4~14],经PCA处理后的隐含层节点数范围为[2~12],PCA处理前后的网络运行时间随着隐含层节点数的变化规律如图5所示,经过PCA处理后,相同隐含层节点下神经网络的运行时间降低3s。
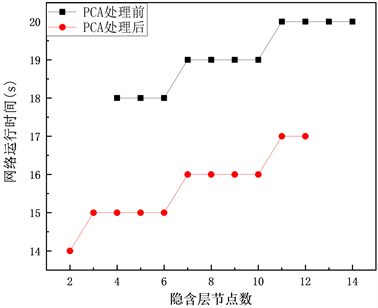
Figure 5. Variation of network running time with the number of hidden layer nodes before and after PCA processing
图5. PCA处理前后网络运行时间随隐含层节点数的变化情况
图6(a)~(c)为降维前后BP模型运行之后各参数变化情况。
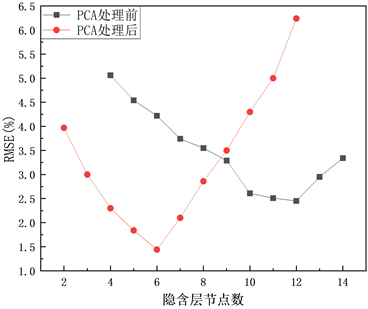 (a)
(a)  (b)
(b)  (c)
(c)
Figure 6. The variation of parameters of BP model with the number of hidden layer nodes before and after PCA processing
图6. PCA处理前后BP模型各参数随隐含层节点数的变化情况
综合图5与图6(a)~(c)的结果得出:经过PCA降维后,BP的网络运行时间从20s降为15s,误差指标RMSE、MAPE分别从2.45%、3.6%降为1.44%、2.38%,相关系数R从0.9745升高到0.9885。
为了选取最优的迭代次数,采用MAPE值作为评价指标,从迭代1000次开始并以1000为间隔递增,直到第20,000次时MAPE值趋于平稳,神经网络模型预测结果最佳,故选择20,000步作为最佳迭代次数。MAPE随着迭代次数的变化关系如图7所示。
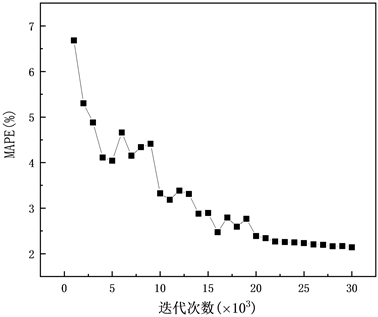
Figure 7. Changing trend of MAPE value with number of iterations
图7. MAPE值随着迭代次数的变化趋势
3.4.2. GRNN神经网络运行结果
采用相同的数据用GRNN神经网络进行训练。spread值是一个扩展常数,表示函数的光滑程度,对于数据的训练至关重要,spread过大或过小都不能很好地预测模型。如果spread值过大,则会导致过拟合;如果spread过小,则会导致拟合结果远离实际值。spread的范围为[0~2],设定spread的初值为0.1,以0.1间隔递增,降维前后GRNN模型运行之后各参数变化情况如图8(a)~(c)所示。
经过PCA处理后,GRNN的最优spread由0.6变为0.2,网络运行时间从0.8s降为0.4s,误差指标RMSE、MAPE分别从1.78%、2.85%降为1.04%、1.98%,相关系数R从0.9853升高到0.9966。
 (a)
(a) 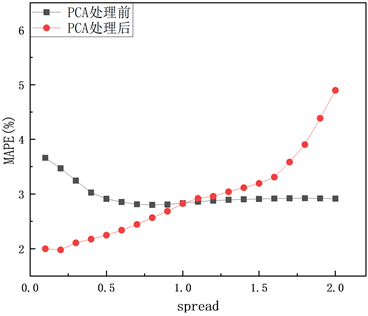 (b)
(b)  (c)
(c)
Figure 8. The variation of parameters of BP model with spread values before and after PCA processing
图8. PCA处理前后GRNN模型各参数随spread值的变化情况
3.4.3. 模型比较及分析
从3.4.1与3.4.2的结果分析得出:经过PCA处理后的网络模型相较于未经过PCA处理的网络模型来说,模型的运行时间更短,在实际应用中能够明显的提高工作效率,RMSE和MAPE更小,R更大,说明误差小,预测精度更高。
图9为经过PCA处理后两种模型的线性回归分析对比图,从图中可以发现经过PCA处理后的GRNN模型的相较于BP模型的线性拟合更加接近45˚线且数据更加集中,表明该模型预测精度更高。
经过PCA处理后的两种模型相对误差如图10所示,BP模型的最大相对误差为8.74%,主要集中在4%以内,平均相对误差为2.38%;GRNN模型的最大相对误差为−4.44%,主要集中在3%以内,平均相对误差为1.98%。可见经PCA处理后的GRNN模型的误差更低。
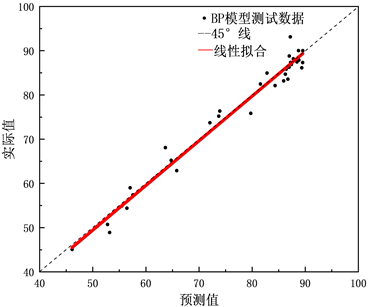
Figure 9. Linear regression analysis of predicted and actual values of the two models after PCA treatment
图9. 经PCA处理后的两种模型的预测值与实际值的线性回归分析
对以上结果,从理论上分析是因为GRNN模型相较于BP模型来说,不需要进行权值的处理,以径向基网络为基础,非线性映射能力更强、收敛速度更快。GRNN模型中人为调节参数很少,只有一个spread值,而BP模型需要人为调节的参数很多,有隐含层节点数、迭代步数等参数,这个特点决定GRNN模型得以最大可能地避免人为主观假定对预测结果的影响;而经过PCA处理后,原有的两两相关的变量合成了线性无关的低维变量,减少了模型的计算时间以及计算的复杂度。

Figure 10. Relative errors of the two models after PCA treatment
图10. 经PCA处理后的两种模型的相对误差
4. 结论
经过PCA处理之后,模型的输入参数由τ、Tbo、Ts、σ、pH值变成Y1和Y2,且两者的累计贡献率达到了96.94%。
经PCA处理后的GRNN模型预测的R为0.9966,平均相对误差为1.98%;而经PCA处理后的BP模型预测的R为0.9885,平均相对误差为2.38%。由此可见,前者的R更接近1,而平均相对误差也更小。
因此,在经过PCA处理后,BP模型与GRNN模型的预测结果都有所提升,并且经过PCA处理后的GRNN模型对EC管外壁阻垢率的预测性能明显优于BP模型。
基金项目
中国博士后科学基金(No. 2020M681347)。
NOTES
*通讯作者。