1. 引言
随着社会的发展和科学技术的进步,人们愈发关注自己的身体健康情况,但随之面临的是困扰已久的“看病难”问题。在整个就诊流程中,化验通常是整个流程最重要的一环,由此产生的医学化验单最能反映患者的身体健康情况。当前,医疗体系中信息系统种类繁多,虽然电子病历已有一定发展,但各医院之间的电子病历数据互不相同,给医患均带来了一定的负担。高效、准确的解读化验单,并以合理的方式去管理化验单是整个医疗行业所面临的重大问题。
同时,针对患者转院转诊、报销等一系列问题,电子病历也不能很好的解决上述问题。因此,将纸质化验单上的数据经识别转换为文字信息,并利用电子档案等方式对信息进行存储是解决上述痛点问题的最佳方式。将图片信息数字化,既降低了患者就诊、报销时的负担,也能够提高医生问诊过程的效率,进而解决“看病难”的问题。
在医学化验单OCR识别的全过程中,布局识别是其中的关键步骤之一。通常来说,医学化验单由表格辅助线可以分为三大区域:医院信息区、患者信息区和化验项区。上述三大区域,每部分所包含的信息不同,且每部分可以独立看作少线表。因此,在OCR识别过程中,首先需要对化验单进行布局识别,将不同的区域切分,并利用相应的方法进行后续识别工作。布局识别的目标是识别非结构化医学化验单中不同信息的区域,并识别每个区域的类别。由于医学化验单布局的多样性和复杂性,此任务难度较大。
目前,针对医学化验单布局识别问题,尚未提出相关研究方法。与本任务相似任务主要是文档的布局识别方法研究,针对文档布局识别任务,有部分学者提出了一些解决此任务的深度学习模型。已提出的研究一般从任务的视觉特征出发,采用自顶向下的策略将布局识别任务定义为目标检测或图像分割任务,但此类模型的实验结果较差。
针对医学化验单是少线表的特点,可以引入表格线关系作为分析特征。传统的表格线检测方法主要使用手工设计的特征,如利用隐式马尔科夫模型进行检测。这些特征对于布局变化不具有鲁棒性,尤其是对于版式繁多的医学化验单更加不适用。基于深度学习的表格线检测方法主要是基于VGG和GNN的方法,相较于传统方法,他们对于样式变换的鲁棒性更强,识别准确度更高。但单一的表格线特征不足以完成医学化验单布局识别任务。
为解决上述问题,在本文中,我们采用融合区域特征和辅助表格线特征提取的方法,提出了用于医学化验单布局识别的模型。首先,医学化验单以图像的形式作为模型的输入;其次,采用基于VGG的Unet模型提取医学化验单图像的表格线特征,并将其输出与原始医学化验单图像一同送入基于Mask R-CNN的深度学习网络提取图像的区域特征,实现上述特征的融合,对待识别区域之间的关系进行建模,并生成最终的精确坐标和语义标签。
本文的工作主要有三点贡献:
1) 提出了融合区域特征和辅助表格线的布局识别框架,是一种全新的医学化验单布局识别办法;
2) 提出了一个全新的多布局的医学化验单数据集;
3) 与先前的模型对比,本文提出的方法在识别准确率上有较大提升。
2. 相关工作
针对医学化验单的布局识别的相关研究较少,与本任务相关的工作主要有文档布局识别任务和图像分类任务。
2.1. 文档布局识别
已提出的文档布局识别研究根据利用特征的数目,可以分为利用一维特征模型和多维特征模型两大类。有研究提出将视觉特征与语义特征相结合,首先,通过卷积神经网络提取视觉特征,然后通过文本嵌入图引入语义特征;然后,使用检测或分段模型(例如Mask RCNN)生成布局目标候选区域。虽然基于视觉特征和语义特征的方法能够较好地捕获空间信息,但仍然有两大方面的局限性:第一,语义信息有限。不同粒度的语义所表达的信息不同,以单一粒度嵌入的文本对于识别各部分元素的贡献是有限的。第二,缺乏对文档各区域之间关系的建模。文本图像中不同区域之间有较为密切的关联关系,正确对其关系进行建模可以显著提高布局分析的准确度。
一维特征模型主要从视觉特征或者语义特征进行文档布局识别方法的研究 [1] [2] [3]。利用图像视觉建模的研究主要使用了基于CNN的模型 [4],主要完成了对图像中的文本段落 [5] [6],标题行 [5] 和文档中表格 [7] 的识别任务。同时,利用语义特征建模的研究主要利用文档的语义信息,结合NLP相关任务,来解决文档布局识别的任务 [8] [9]。但是,上述两种研究都仅利用了单一模态的特征,任务效果也与特征工程有较强的关联性,因此模型的鲁棒性较差,对于版式变化繁多的医学化验单并不适用。
多维特征模型将视觉特征和语义特征相融合,进行文档布局识别任务。根据主要依赖的方法,可以分为两大类:基于NLP的方法和基于CV的方法。在基于NLP的方法中,PubLayNet [10] 是文档图像布局识别的大型数据集,包含超过36万个文档图像,用多边形边框分割标注文档各区域布局情况。MMPAN [11] 是主要依赖与NLP模型进行文档布局识别任务的框架之一,但上述方法表现出利用视觉信息不足的缺点,导致其模型效果欠佳。基于CV的模型主要利用了基于目标检测或图像分割的方法,MFCN [12] 在上述方法的基础上,引入了文本的语义信息,并在网络的最后一层引入了字符级的语意信息。虽然上述方法效果较好,但也有较为明显的缺陷:使用的语义有限,模型融合的策略较为简单,各模块之间相互依赖较少。
2.2. 图像分类
图像分类任务是指利用某种深度学习模型。在输入图像后,图像分类器模型根据图像输出对应的分类标签。Alex Krizhevsky在2012年ILSVRC提出的CNN模型取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet [13]。这也是首次将深度学习用于大规模图像分类中。ResNet (Residual Network)是2015年ImageNet图像分类、图像物体定位和图像物体检测比赛的冠军。针对随着网络训练加深导致准确度下降的问题,ResNet提出了残差学习方法来减轻训练深层网络的困难 [14]。
3. 研究方法
3.1. 模型结构简介
我们提出融合区域特征和表格线识别的模型(Fusion of Regional Features and Table Line Recognition Model, FRFTLR),由三部分组成:区域特征卷积网络、表格线提取网络和特征融合网络(如图1所示)。首先,基于医学化验单是少线表的特征,使用表格线提取网络(第3.2节),提取化验单图像的表格线特征,其中以医学化验单图像作为输入;其次,将表格线提取网络的输出与原始医学化验单图像一起送入到区域特征卷积网络(第3.3节),实现特征融合的目的,并作为最后的输出,生成最终结果。
3.2. 表格线提取Unet网络
Unet属于全卷积网络(Fully Convolutional Networks, FCN)的一种变体。作者在设计Unet模型时,主要目的是解决医学生物图像相关问题,由于Unet实验效果确实很好,研究者将其广泛应用与语义分割的任务上,语义分割即将一张图像作为输入,模型的输出为图像中分割物体的准确轮廓。常见的语义分割任务主要有表格线检测任务,工业瑕疵检测分割,医学图像检查分割任务等。Unet是典型的编码-解码(Encoder-Decoder)结构,主要结构简洁,即上采样、下采样和跳跃连接三部分具体来说,使用Encoder部分来实现特征提取,每经过一次下采样,通道数翻倍;Decoder部分主要包含由一个2 × 2的上采样卷积层(ReLU)、Concatenation以及2个3 × 3的卷积层(ReLU)反复构成;在最后一层通过一个1 × 1卷积将通道数变成期望的类别数。Unet网络结构如图2所示,由于Unet的网络结构是对称的,且形似英文字母U所以被称为Unet。
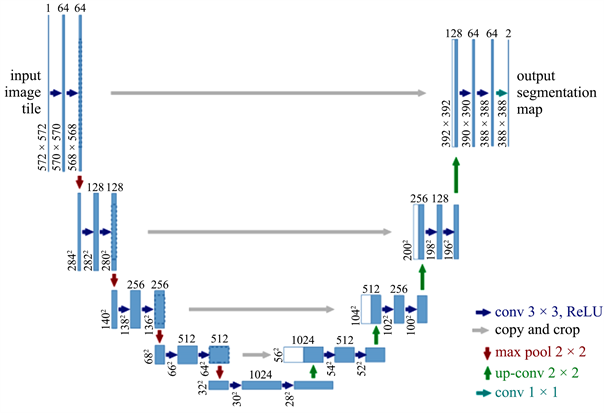
Figure 2. Table line extraction network Unet model structure
图2. 表格线提取网络Unet模型结构
3.3. Mask R-CNN区域特征提取网络
Mask R-CNN目标检测算法是由何凯明等人对Faster R-CNN进行改进而提出的目标检测框架,该算法可以同时完成目标检测与分割任务。Mask R-CNN算法相较于Faster R-CNN算法,选择基于ResNet网络替换后者的VGG网络。Mask R-CNN实现目标检测任务由两大步骤实现:第一个步骤是使用基于FPN网络,对输入图片利用神经网络进行处理,进而生成对应的候选框集和;第二个步骤是对候选框集合的分类,并实现边框和mask回归任务。
Mask R-CNN在COCO等自然场景图像数据集上表现出了良好的分割效果,但对于医学化验单或文本图像等相关数据尚无相关实验结论。本文研究的医学化验单布局识别是要将输入的医学化验单实现对医院信息区、患者信息区、化验项及结果区这三个类别实现实例分割。
在进行提取医学化验单区域特征研究时,首先将医学化验单图像和前序网格线提取网络输出的特征图一起输入到基于ResNet101的卷积神经网络中提取特征;其次将由ResNet网络生成的特征图(Feature Map)送入到区域生成网络(Region Proposal Network, RPN)中,生成提取候选框;随后将上述网络输出的Feature Map和提取候选框一起输入到RoI Align层,由RoI Align层得到的特征图进行两大分支的处理,第一将基于全卷积网络(Fully Convolutional Networks, FCN)对输出进行mask预测,并利用全连接层(Fully Connected Layers, FC)完成Sofamax分类和Bbox边框回归任务,最终完成医学化验单布局识别任务。基于Mask R-CNN构建的医学化验单布局识别算法的网络结构如图3所示。
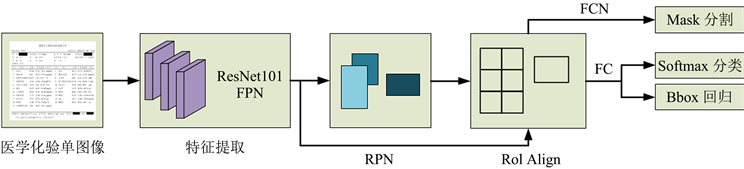
Figure 3. Regional feature extraction network Mask R-CNN model structure
图3. 区域特征提取网络Mask R-CNN模型结构
4. 实验
4.1. 数据集
目前没有公开的医学化验单图像数据集来完成医学化验单布局识别研究任务。根据实际调研,若采用人工标注海量化验单数据作为本文的训练集,会面临费时费力且成本高的问题,因此考虑采用人工合成数据的方法。基于以上思路构建了基于SVG的自标注医学化验单图像数据集。SVG是一种图像文件格式,它的英文全称为Scalable Vector Graphics,意思为可缩放的矢量图形。它是基于XML (Extensible Markup Language),由World Wide Web Consortium (W3C)联盟进行开发的,严格来说应该是一种开放标准的矢量图形语言,能够实现带有文字位置的自标注信息。在本模块中,事先设定模板所需的行和列数目,即可生成对应的数据;此外,考虑真实的医学化验单图片伴随倾斜、扭曲、畸变、变色等常见问题,进而基于OpenCV实现对生成数据的加噪功能,避免数据差异性的问题,这部分数据将作为本文训练集的来源。
测试集采用从某三甲医院获取到的真实医学化验单图片,使用Labelme图像标注工具对化验单进行区域标注,并采用数据增广的方式,进一步扩充测试集的样本数。
4.2. 实验参数
本文提出的模型是在 PyTorch 框架下实现的。实验参数设置如下,在RPN中,设定7个anchor ratios,分别为0.02、0.05、0.1、0.2、0.5、1.0、2.0,用来处理大小和比例不同的文档元素。由SGD优化器进行训练,设置batchsize = 2,momentum = 0.9,weight-decay = 10−4。将初始学习率设置为10−3。设置模型训练的epoch为30。所有实验均在 Nvidia GeForce GTX 2080Ti GPU上进行。
4.3. 实验结果
在医学化验单布局识别实验中,为更有效的评估模型效果,采用不同IoU (Intersection over Union)的平均准确率mAP (mean Average Precision)对模型的识别效果进行评价,将医院信息区的mAP定义为Hospital mAP、患者信息区的mAP定义为Personal mAP、化验项及结果区的mAP定义为Test item mAP。定义基于IoU = 0.5的mAP为mAP50,基于IoU = 0.75的mAP为mAP75,定义mAP对医学化验单布局识别整体性能进行评价。IoU的计算如公式(1)所示,AP值计算如公式(2),mAP值计算如公式(3)。
(1)
(2)
(3)
上式中,area(P)指的是预测的Bbox集合或Mask集合;area(G)指的是真实的Bbox集合或Mask集合;P为精确率;R为召回率;N为训练集大小。其中精准率(P)和召回率(R)的计算如公式(4) (5)。
(4)
(5)
在上述公式中,TP定义为模型能够识别正确的正样本数,TN定义为模型能够正确识别的负样本数,定义FP为模型识别错误的正样本数,定义FN为模型错误识别的负样本数。本实验采用基于不同IoU阈值的mAP来评价医学化验单布局识别结果,对比四种不同的深度学习网络,得到的模型效果评价指标结果见表1。

Table 1. Model comparison experiment results
表1. 模型对比实验结果
4.4. 消融实验
考虑本文提出的模型所利用的信息主要包含区域特征和表格线特征提取两大部分。为探究这两部分特征对于提高医学化验单布局分析的重要性,本节对上述两大特征在医学化验单数据集上进行了消融实验。实验结果如表2所示。
Table 2. Results of ablation experiments
表2. 消融实验结果
其中,区域特征提取仅使用了Mask R-CNN模型,表格线特征提取仅采用了Unet模型,特征融合为完成的模型结构。实验结果表明,表格线特征对于医学化验单布局识别的影响因素更大,这与医学化验单属于少线表,表格线有较强的引导功能相符合。特征融合实验也表明,融合上述两种特征,对于实验效果提升有较大帮助。
5. 结论
本文提出了融合区域特征和表格线特征用于医学化验单布局识别的模型。首先,利用Mask R-CNN卷积网络提取医学化验单布局的区域特征;其次,针对医学化验单属于少线表,线条具有强引导性的特征,使用Unet网络提取医学化验单表格的表格线信息;最后,对上述两种信息进行特征融合,并输出最终结果。与先前的模型对比,本文提出模型的性能有显著提升;消融实验也表明表格线对于布局识别有较为重要的作用。在未来,将研究本文的模型,并将其扩展到其他任务,如文档布局识别等。
基金项目
北京市自然科学基金项目,项目资助号:L192026。
NOTES
*通讯作者。