1. 引言
进入21世纪以来,随着经济社会的飞速发展,金融市场的健康稳定对于促进国家经济发展的意义越来越重要。在此背景下,怎样选择合适的评估模型和指标系统、科学地衡量企业信用风险,具有高度的理论意义和现实意义。
企业的信用风险评估体系的建立主要分成两部分,首先是建立合适的指标体系,通过指标可以明确企业的信用情况,以及进行借贷的风险性大小;其次是结合信用风险指标体系建立合适的评估模型,通过模型可以在贷前能够识别风险企业,协助金融机构建立行之有效的风险管理机制 [1]。
近年来,随着大数据时代的到来,相较于传统评估方式强依赖于专家意见,现阶段评估方法多为参考专家意见与业务场景建立评估模型。1993年张更生、蒯本江提出建立信贷风险预警体系,系统阐释了信贷风险的来源,以及信贷风险的九类特征,包括资金流动比率、负债比率资产流失比率等 [2]。张雷,王家琪等人提出基于RF-SMOTE-XGboost的银行用户个人信用风险评估模型,所建立的模型在评估时具有更好的精度与收敛性 [3]。
时至今日,信用风险评估领域的研究已十分丰富,但此类问题涉及情况较为复杂、特征繁多,在模型的训练过程中,仍然存在着过拟合,特征选取困难等诸多问题。本文选择优化后的随机森林算法,利用随机森林算法降低过拟合风险,将特征选取与模型训练过程相结合,建立了基于随机森林算法的信用评估模型,并以某金融信贷机构披露的我国上市公司数据为例,测试了模型的准确性,一定程度上解决了上述问题,有效提高了预测精度。
2. 理论基础
2.1. 随机森林
随机森林最早是由Breiman等多位学者共同提出的一种机器学习算法。原理可看作从原始训练样本集中有放回地重复随机抽取K个样本生成新的训练样本集合,训练多个决策树
共同参与分类决策的组合模型,
为服从独立同分布的随机变量,完成训练后得到分类模型序列
,再用它们构成一个多分类模型系统,最终分类结果采用简单多数投票
法 [4]。最终的分类决策:
,其中
表示组合分类模型,
是单个决策
树分类模型,Y表示输出变量(或称目标变量),
为示性函数。
由于随机森林在训练的时候,每一棵树的输入样本都不是全部的样本,对于特征的选择也同样是随机的,两次随机采样的过程使得随机森林很大程度上避免了过拟合的问题。除此之外,两个随机性的引入也使得模型具有较好的抗噪能力。
2.2. 基于特征递归消除的随机森林模型
随递归特征消除(RFE)是Guyon等人基于支持向量机提出的。主要原理是将特征集合初始化为整个数据集合,每次剔除一个排序准则分数最小的特征,直到获得最后的特征集来达到特征筛选的目的 [5]。本文选择了基于特征递归消除法的随机森林模型即改进后的随机森林模型,将随机森林模型与递归特征消除法相结合,将指标的筛选与模型的训练融合,具体步骤如下:
假设第i个特征的排序准则分数定义为:
每次迭代中去除排序准则分数最小的特征,然后运用剩余的特征训练随机森林,进行下一次的迭代。具体算法步骤如下:
步骤1:原始数据进行预处理,把集合X变为
步骤2:对数据集合
构建模型,根据模型准确度进行特征选择,所得到的对应特征引子集为
;
步骤3:将得到的特征子集进行
合并,得到最终的特征子集为
,输出由该特征子集所构成的模型。
3. 实证分析
3.1. 数据描述与预处理
实验数据为某金融机构对于2010~2019年间a股上市公司信用评级以及各公司各类财务数据汇总得到,包含信用评分,资产负债率、企业规模、销售收入增长率等共计58个指标,共34540条数据,表1为部分特征格式枚举。其中信用评分60分及以上定义为信用良好,用标签1代替;反之则用标签0代替。实验所用编程语言为R语言。
由于原始数据部分特征存在缺失和异常,为保证模型训练的准确性需要对数据进行预处理。预处理方式主要包括以下三类:
去除唯一属性:对于无意义的唯一属性特征进行删减,如股票代码;
处理缺失值:对于大量样本都存在缺失的特征进行删减,对极小部分存在大量特征值缺失的样本进行删减,对少量缺失部分数值型特征的样本进行多重插补;
数据标准化:对各个特征进行归一化处理,统一将数字映射到[0,1]上,处理公式如下
预处理后共有2025条有效数据,剩余34个特征,其中正向样本1746条,负向样本279条。
3.2. 实现过程
数据进行预处理后,基于改进随机森林算法,同时进行模型特征的选取以及模型的训练。将所有样本按照7:3的比例进行随机抽样,分别构成训练集与测试集,并利用训练集对模型进行训练,利用测试集对模型的效果进行检验,最后通过合理的模型评价指标对模型的预测效果进行评价,主要流程见图1。
3.3. 实验结果
3.3.1. 评价指标
经过实验数据的预处理,处理后的数据中正负项样本数量存在不平衡的情况,即信用良好的企业样本远多于信用较差企业样本,所以在评价指标的选取上,需要同时关注对于正、负项的分类能力,在样本不平衡的情况下,依然能够对模型做出合理的评价。而AUC对样本类别是否均衡并不敏感。
故在众多评价指标中选择AUC (Area Under Curve)作为核心评价指标,同时选取准确率A (accuracy)、精准率P (precision)与召回率R (recall)作为辅助评价指标。
本文将正常样本作为正样本,违约样本作为负样本,则混淆矩阵定义如下表2:

Table 2. Confusion matrix definition table
表2. 混淆矩阵定义表
基于混淆矩阵定义的TP、FN、FP、TN,评价指标定义如下:
AUC为ROC曲线下面积,ROC曲线核心关注两个指标
其他指标
根据以上指标可以系统评价模型准确性。
3.3.2. 结果分析
再经过模型的训练与测试后,共选取15个指标,模型AUC为0.687。进行指标筛选及模型训练的过程中,随着指标数增多accuracy变化如图2所示,在训练集中,17个特征入模时,模型accuracy达到最高为0.87。模型ROC曲线如图3所示。
为对比模型效果,故使用常见的几种分类算法分别建立模型,模型效果如表3所示。
如表3所示,对比其他单分类器与多分类器模型表现,本文模型AUC最高,对比其他模型,有效避免了过拟合的情况,同时提升了对于坏样本的识别能力。Xgboost模型由于过拟合,出现了AUC过低的情况,而lda模型则出现了对于坏样本识别率极低的情况,故证明选取的模型评价指标较为合理,且本文模型有较好的表现。
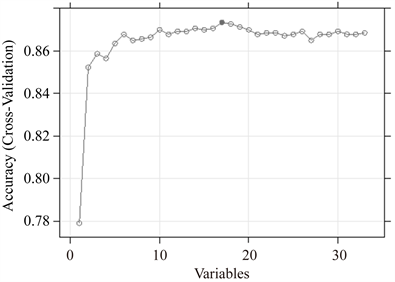
Figure 2. Feature selection based on RFE
图2. 递归特征消除法特征选择
Table 3. Model performance evaluation table
表3. 模型性能评价表
4. 结束语
本文选择合理的模型评价指标后,基于改进随机森林的信用风险评估模型,以上市公司数据为例训练模型,并通过对比分析其他常见分类器算法模型表现,验证了该模型对于指标较多的信用风险评估类问题具有更强的适用性,一定程度上解决了此类模型通常存在的过拟合,以及指标的选取困难的问题,具有一定的理论意义和现实意义。