1. 引言
为抢抓人工智能发展的重大战略机遇,构筑我国人工智能发展的先发优势,近年来我国在人工智能领域密集出台相关法律法规及政策。例如,2017年7月,国务院发布《新一代人工智能发展规划的通知》,描绘了未来十几年我国人工智能发展的宏伟蓝图,确立了“三步走”目标。2020年7月,五部门印发《国家新一代人工智能标准体系建设指南》,明确提出建立国家新一代人工智能标准体系,加强标准顶层设计与宏观指导。世界各国也均加快了人工智能方面的研发和产业布局,发展人工智能相关理论、算法和技术已经成为当前各主要经济体在未来保持国际竞争和技术优势的重要手段,并已经成为各国科技或产业政策的重要内容。
在上述背景下,近年来人工智能相关研究呈现快速增长趋势,相关研究文献也出现了高速增长。然而文献的种类繁杂、质量参差不齐,不同种类之间又存在信息重复等各种各样的问题,因而在短时间内检索到高质量的满足自己需求的人工智能领域文献以及从检索到的文献中快速发现更多隐含的信息,是研究者面临的一大难题。
为对人工智能的发展和热点进行精准把握,近年来学者们进行了丰富的研究,主要包括相关规划、政策和专利分析,但对人工智能领域的研究文献进行分析的较少。如臧维等 [1],袁野等 [2],李首骏 [3],高长元等 [4] 分别对我国人工智能相关的政策和合作专利进行文本量化研究,探索前沿趋势。李牧南和王雯殊 [5] 基于主题建模的文本分析思路进行内容挖掘,研究人工智能相关科学主题的演进模式。吕一博等 [6],魏雪飞 [7] 采用文献分析软件(如CiteSpace和Endnote),按照内置文献计量方法进行可视化分析。在数据的选取上,大多学者选择研究人工智能在某一领域的热点内容,如医疗、教育等方面 [7] [8],对人工智能主题文献的综合研究较为匮乏。在上述研究基础上,本文将中文期刊论文、学位论文以及外文期刊的中国作者论文作为数据来源,将近三年人工智能有关的高水平文献作为研究对象,采用共词分析法、构建LDA主题发现模型,对文献的关键词和摘要进行两方面研究,绘制人工智能领域知识图谱,可更为全面的揭示研究热点,追踪人工智能技术的发展以及在其他领域应用的前沿问题。
2. 模型理论及建立
2.1. 共词分析理论
共词分析本质上是一种共现分析方法,基本原则是先统计一组关键词中任意两个词在一组文档里某一篇中是否共同出现,再统计这种共同出现情况的次数并构建对称关键词共现矩阵。在共现矩阵中关键词共现次数可能相差较大不利于数据分析,需要把关键词共现矩阵进行归一化处理转化为关键词相关矩阵。其中,文档-关键词矩阵中“1”表示某个关键词在某篇文档中至少出现过一次,即这个关键词属于这篇文档;共现矩阵中对角线数字表示该关键词在一组文档中的词频,其余位置数字表示任意两个不同关键词在一组文档中共同出现过文档的篇数。
2.2. LDA主题模型的建立
话题模型主要用于处理离散型数据如文本集合,在信息检索、自然语言处理等领域又广泛的应用。其中隐狄利克雷模型(LDA)是话题模型的典型代表。假定数据集包含
个话题和
篇文档,用
个
维向量
表示数据集即文档集合,
个
维向量
表示话题,
的第
个分量
表示文档
中词
的词频,
的第
个分量
表示话题
中词
的词频。通过统计文档中出现的词来获得词频向量
,LDA认为每篇文档包含多个话题,用向量
表示文档
中所包含的每个话题
的比例,进而通过以下步骤由话题生成文档
:
1) 根据参数为
的狄利克雷分布随机采样一个话题分布
;
2) 按如下步骤生成文档中的
个词:
a) 根据
进行话题指派,得到文档
中词
的话题
;
b) 根据指派的话题所对应的词频分布
随机采样生成词。
于是,LDA模型对应的概率分布为
其中
和
通常分别设置为以
和
为参数的K维和N维狄利克雷分布,如
其中
是Gamma函数。显然,
和
是式中待确定的参数。
给定训练数据
,LDA的模型参数需通过极大似然法估计,即寻找
和
以最大化对数似然
但由于
不易计算,上式难以直接求解,因此实践中常采用变分法来取近似解。若模型已知,即参数
和
已确定,则根据词频
来推断文档集所对应的话题结构(即推断
,
和
)可通过求解
然而由于分母上的
难以获取,上式难以直接求解,因此本文采用变分法进行近似推断。
3. 实证分析
3.1. 数据获取及预处理
数据库通常具有下载文献相关信息的功能,但下载数量有限制,如果研究者所需文献数量较大,文献数据获取将会损失较多科研时间。识别数据库反爬虫机制、使用Python软件编写爬虫程序,可快速获取所需信息。
本文使用Request模块抓取网页数据,Lxml模块解析数据,爬取2019~2021年以人工智能为关键词的高水平文献,共计10315篇。数据来源于中国知网(CNKI)数据库和Web Of Science数据库。高水平文献含三部分:第一部分是中文期刊文献。中文期刊需被北大核心、SCI、EI或CSCD收录,这类期刊具有信息量大、利用率高、权威性强等特点,数据涉及文献篇名、作者、刊名、发表时间、关键词、摘要、机构、文章链接等。第二部分为人工智能领域被CNKI收录的硕博士学位论文,硕士和博士是科研的中坚力量,他们的研究课题一定程度上代表着我国人工智能领域的科研水平。第三部分是被Web of Science收录的中国学者发表的高水平人工智能文献。其中,外文期刊需被SCI收录,SCI收录的文献能够全面覆盖全世界最重要和最有影响力的研究成果。具体检索时,作者关键词选择为Artificial Intelligence,地区选择为CHINA,文献类型仅限于论文,并排除综述类文章,确保后续分析的准确性。爬取得到中文期刊文献5575篇,硕博学位论文2305篇,中国作者发表在外文期刊的文献2255篇。
爬取到的文献数据参差不齐,需对数据进行预处理,便于后续分析。首先,文献根据研究需要需删除研讨会综述、课题介绍、会议通知、卷首语、会议记录、课题通过鉴定、读后感、简介、研讨会简介、书评、成果鉴定会、学院以及学校简介信息、人物专访、投稿须知、会议纪要、出版信息、目录信息、公告等无关内容。其次,进行基础预处理操作:删除摘要或者关键词缺失的文献、删除重复项。得到有效中文期刊文献4896篇,学位论文1828篇,中文作者在国外期刊发表的论文1715篇,共计8439篇。最后,进行进一步的预处理操作,对英文大小写进行统一化处理、对文献摘要进行分词处理、去除停用词,对文献关键词进行分列。预处理流程图如图1所示。
3.2. 文献基本信息描述
本文通过运用文献的描述计量方法,以在CNKI和Web of Science中爬取到的近三年人工智能领域的有效文献数据为基础,展示文献的来源单位、外文期刊收录情况、文献作者群等,反映人工智能领域的研究现状。
研究发现北京邮电大学、吉林大学、电子科技大学等院校对于人工智能领域的相关研究较多,近三年北京邮电大学相关论文量可达60篇,硕博学位论文排名前20名的授予单位见图2。在外文期刊中,中文作者发表在IEEE Access期刊的该领域论文较多,近三年相关文献达253篇,Neurocomputing和IEEE Network期刊相关论文数量位居二、三位,均在30篇左右;排名前20名的外文期刊(见图3)中近50%的期刊由IEEE出版。通过统计文献作者的发文频次,研究发现中文期刊文献中肖锋、何大安等学者在该领域的发文量较多,见图4。

Figure 2. Ranking of degree awarding units of master’s and doctoral degree thesis
图2. 硕博学位论文学位授予单位排名

Figure 3. Ranking of foreign language journals containing Chinese authors’ papers
图3. 收录中国作者论文的外文期刊排名

Figure 4. Chinese journal paper author word cloud map
图4. 中文期刊论文作者词云图
3.3. 关键词共词分析
利用软件Python对预处理后的关键词构造共词矩阵,根据共词矩阵解析文献关键词之间的网络关系数据,进一步通过Gephi软件计算关于网络分析的宏观指标和微观指标并进行可视化展示。
由于关键词出现的频率符合长尾分布,大量的关键词词频为1,对词频较高的关键词进行共现分析才有意义,所以在共词分析中,需要自定义高频关键词 [9]:1) 中文期刊文献:高频关键词限定最低频次为5。2) 学位论文:高频关键词限定最低频次为3。3) 外文期刊文献:高频关键词限定最低频次为3。关键词共现网络宏观指标如表1所示。
根据表1可知:1) 中文学位论文整个网络的平均度数只达到了5.75左右,说明整个网络各个节点直接关联程度比较低,而外文期刊关联程度较高。2) 中文学位论文整个网络的密度为0.006,相比来说是处于比较松散的状态,节点之间交流传递比较差。3) 外文期刊文献关键词的平均聚类系数为0.587,平均路径长度为1.733,相较其他两种更具有小世界性的特征。
除了表1中的指标参数,微观视角可以根据介数中心度、紧密中心度、离心率三个指标去度量每个节点上的关键词在网络中的作用 [10]。本文以介数中心度为度量指标,指标越大越可以被认为是网络的中心节点或者说中心关键词。可以发现中文文献中指标前三位的关键词是一致的。外文文献中深度学习、机器学习关键词也在前三的位置。具体见表2所示。

Table 2. Micro perspective: Top 10 keywords of betweenness centrality index
表2. 微观视角:介数中心度指标Top10关键词
接下来,将基于微观指标,结合网络共现图对高水平文献的研究内容进行进一步探索。首先,需过滤一些意义不大的节点。由于很多关键词不是中心关键词,这些节点(关键词)与其他节点的关系并不紧密,即度很小。为了在可视化展示时更加清晰明了,本文设定节点的限制条件为:1) 中文期刊和学位论文文献:度最小为4;2) 外文期刊文献:度最小为10。其次,本文采用ForceAtlas2算法进行网络可视化布局,该算法具有运行速度快、处理的图形规模大的特点,在实际运行中,此算法形成的网络图更易进行社区发现。再次,将含有关键词信息的边文件和节点文件导入软件Gephi,运行ForceAtlas2布局算法,采用Louvain算法计算模块度,判断是否适合进行社区发现,本文的文献模块度计算结果如表3所示。
Table 3. Modularity calculation results of literature
表3. 文献模块度计算结果
在实际网络分析中,模块度若在0.3~0.7之间,说明聚类效果很好。由表3可知,三类文献有很好的聚类效果,均适合进行社区发现。最后,对无向网络共现图进行外观调整。以度为渲染方式,调整节点尺寸,根据社区划分选择区别度较大的颜色,以便更加直观的进行可视化展示。最终得到的三类文献的网络共现图分别如图5~7所示。
3.4. 基于摘要的LDA主题模型
本文对摘要进行LDA主题模型的搭建,以识别摘要中蕴含的主题,挖掘摘要中隐藏的信息,从而探索人工智能领域文献的热点研究方向。
首先,对文献摘要进行分词处理,将词组向量化,生成模型语料库。在这个过程中,由于有些词不具有重要意义,但在结果中占比较高,影响到了主题模型的权重判断,因此本文在常用停用词列表的基础上,增添了如“人工智能”、“技术”“研究”等词汇,将不想投入模型计算的一些高频词过滤掉,提高了模型提取的准确率。其次,使用Jupyter Notebook中gensim模块实现LDA模型的搭建,并基于变分推断EM算法求解每一篇文档的主题分布和每一个主题中词的分布。再次,在gensim模块中使用层次狄利克雷过程(HDP),自动确定适合语料库的主题个数。最后,选取最重要的10个主题,输出各个主题的前30个特征词,通过pyLDAvis进行可视化分析,动态显示各个主题下的特征词。可视化结果如图8所示。

Figure 5. Chinese journal literature network co-occurrence atlas
图5. 中文期刊文献网络共现图谱
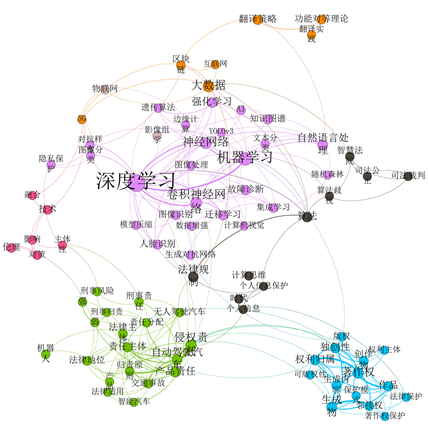
Figure 6. Network co-occurrence atlas of master’s and doctoral dissertations
图6. 硕博学位论文网络共现图谱

Figure 7. Co-occurrence map of Chinese authors and foreign periodicals
图7. 中国作者外文期刊文献网络共现图谱

Figure 8. pyLDAvis visualization-theme dynamic diagram
图8. pyLDAvis可视化–主题动态图
本文将中文期刊论文、学位论文、外文期刊中文作者论文的摘要分词结果作为原始语料,调用LDA模型,得到了三种论文来源的各主题相关词汇。对三种来源文献的相同主题进行合并后,得到了近三年我国人工智能领域文献的研究热点,概括如下:
1) 技术融合促产业发展:利用大数据、人工智能、5G通信、区块链、云计算等新技术,推动媒体融合、金融科技、新基建、经济高质量发展。2) 人工智能技术应用的担忧与解决策略:包括隐私保护、算法歧视、教育公正、技术滥用、社会伦理、智慧司法决策风险、著作权、知识产权、作品独创性、可版权性等;3) 人工智能在教育领域的应用:主要聚焦于自适应学习、人机协同、智慧图书馆,加快推动人才培养。4) 人工智能在影像组学领域的应用:将体层摄影(CT)、X线计算机、磁共振成像与人工智能结合,辅助肺结节及肿瘤的评估、新型冠状病毒肺炎的诊断、皮肤癌的分类、糖尿病视网膜病变检测、及骨骼影像处理等。5) 机器学习的技术融合与应用:热点方向为计算机视觉、自然语言处理及模式识别。
4. 结束语
本文运用文献的描述计量、文本挖掘等定性定量分析技术,针对我国人工智能领域的高水平文献,从文献的关键词和摘要两个方面共同分析人工智能领域的研究热点。通过对关键词进行共现分析,可以发现人工智能应用广泛,大数据相关不断火热,深度学习、机器学习算法在国内外理论研究中均占有主要地位;通过对摘要进行LDA主题模型的建立,挖掘近三年我国人工智能领域蕴含的研究主题,发现比较热门的主题包括技术融合促产业发展、人工智能技术应用的担忧与解决策略、人工智能在教育领域、影像组学的应用、机器学习技术的融合与应用五个主题,这对研究者快速发现人工智能领域的主题热点具有一定的参考价值。