1. 引言
生存分析在生物医学,工程中应用广泛。比如我们经常关心患某种疾病的病人的生存时间,工业产品的使用寿命,以及广义的生存时间,如某个感兴趣事件发生的时间。生存时间研究方法有非参数分析,参数分析方法和半参数分析方法。半参数分析方法的灵活性,稳健性和有效性介于其它两种方法之间,所以是最常用的一种方法。在生存分析数据的收集中,常常会遇到聚类数据,也就是个体之间不是完全独立的。比如数据是来自于各个医疗中心,或者是以家庭为单位收集的,还有的数据是一个个体的事件的重复发生。来自同一医疗中心的个案或同一家庭的个案或同一个体的多次复发数据,叫做成簇数据或聚类数据。同一个聚类的数据是有关系的,不同的类之间相互独立。
聚类失效时间的研究方法有边际建模方法和混合效应建模方法。在边际建模中,对同一个类的每个个体建立边际模型,建模时,对个体之间的关系不作任何假定,而在模拟部分,对同一类内个体间的关系进行一些假定 [1] [2] [3]。在混合效应模型中,对同一类的个体用一个共同的脆弱变量来说明个体之间的相关性 [4] [5]。以上文献大部分围绕着Cox模型 [6] 和加性风险模型。实际上加性乘积模型具有更强的灵活性。文献 [7] 提出一个广义加性乘积风险模型,以后的学者在此基础上进行进一步推广。文献 [8] 对带有辅助生存信息的加性乘积模型进行了统计推断。文献 [9] 对复发事件和终止事件进行联合分析,假设终止事件的风险率函数服从加性乘积模型。
加性乘积模型在聚类失效时间中的应用比较少,这篇论文是将加性乘积模型应用到聚类失效时间中。分析影响慢性肉芽肿病风险率函数的因素,以及影响方式。论文第一部分介绍了模型形式,估计方法和渐近理论证明,第二部分进行了数值模拟,验证提出的方法,第三部分对实际数据进行分析,第四部分是论文的总结和展望。
2. 模型和估计过程
2.1. 模型
首先把全部对象根据某个属性聚成n个簇。设第i个类中有
个对象,其中
,并用
表示第i个簇中第j个对象的失效时间,
为右删失时间,
表示观察到的生存时间,
表示第i类中第j个对象是否删失,
,
为协变量向量。
表示试验终止时间。
的风险率函数的定义如下:
对风险率函数
建立加性乘积模型,给定协变量
,
的情况下,假设风险率函数满足:
(1)
式中:
是基准风险率函数;
是协变量
的效应,表示对风险率函数的乘积效应;
是是协变量
的效应,表示对风险率函数的加性效应。
2.2. 模型估计过程
引入潜在的计数过程
和观测到的计数过程
以及风险过程
,根据风险率函数模型和计数过程的定义,得
进一步得到以下的零均值过程:
。
根据文献 [10] 中的广义估计方程的思想,我们建立以下的估计方程:
(1)
(2)
(3)
由(1)式可得:
,
将
代入式(2)进一步计算得
(4)
其中
。
将
代入式(3)进一步计算得
(5)
其中
。
接下来,我们应用牛顿迭代法,对方程(4)和(5)进行求解,得到
的估计。应用牛顿迭代法时,需要求出方程(4)和(5)左边表达式对
的导函数。记:方程(4)的左边表达式为
,方程(5)的左边表达式为
。
类似的,可以计算出:
,
把这四项写成矩阵形式,并记:
其中
,
,
其中
是
的极限,由大数定律可知
。
2.3. 估计量的渐近性质
首先给出一些正则条件。
(C1) 协变量
.是有界的;
(C2) n组观测
,
.是相互独立的;
(C3)
在
的邻域 H 上可逆。
定理1:在以上正则条件下,方程(4),(5)的解在
邻域 H 内存在且唯一,将这个解记作:
,且
是
的相和估计。
证明:记
,
。
可以证明
。由于
,再根据大数定律,以及
关于
的连续性,可知在
邻域内,
依概率一致收敛到
,由假设:
在
邻域内可逆,这样当n充分大的时候,
在
邻域内可逆。由逆函数定理(Rudin, 1976) [11],可以证明
在
邻域内存在唯一解
。再由中值定理,在
邻域内存在一个点
使得,
,当n充分大时,等号左边依概率收敛于0,等号右边的
可逆,因此当n充分大时
。
定理2:在正则条件下
渐近服从
维的正态分布,
渐近服从
,其中
。
证明:根据函数中值定理,有
,
,
因为
,
其中,
是均值为0的随机变量,而且
相互独立。所以由中心极限定理
渐近服从正态分布
。前面已有
再结合
,可得
渐近服从多元正态分布
。
3. 数值模拟
首先,生成
个独立的类,每一个类的大小为2。协变量为
和
分别服从参数为0.5的二项分布和区间(0, 1)的均匀分布,设失效时间的风险率函数模型为
,设
,
分别取(0.5, 0.5),(1, 0.5),(0.5, 1)。取试验截止时间为τ = 2,删失时间C取区间(0, v)上的均匀分布,v可以变化使得删失控制在30%~70%之间。首先生成基准失效时间
,其中
服从均值为0,方差为
的正态分布,
服从均值为0,方差为
的正态分布。参数
表示不同类间的异质性,
则表示同一类内不同对象的异质性,其中
取三种情况分别为0.25,0.5,0.75。该模拟重复进行500次。上述条件下的模拟结果如表1,表2,表3所示,其中EST,SE,ESE和CP分别代表参数估计的均值,样本标准差,标准差的渐近估计,以及正态近似条件下,
的95%置信区间下的覆盖率。从表1~3中的EST,SE,ESE和CP值都可以看出,当样本量变大时参数估计的均值越接近真值,随着样本量增加样本标准差和标准差的渐近估计越来越接近,CP也越来来越近似于95%,可以得到本文提出的估计方法模拟效果良好,在其他参数设置下,得到结果是差不多的。

Table 1. Estimation for β0 = (0.5, 0.5)
表1. β0为(0.5, 0.5)的估计
Table 2. Estimation for β0 = (1, 0.5)
表2. β0为(1, 0.5)的估计
Table 3. Estimation for β0 = (0.5, 1)
表3. β0为(0.5, 1)的估计
4. 应用
在这部分我们采用提出的方法分析一个临床医学数据 [12] gamma干扰素治疗慢性肉芽肿性疾病的研究。数据共有128名慢性肉芽肿性疾病患者,被随机分为两个组,gamma干扰素组和安慰剂组,每个病例的数据给出了患者发生重复严重感染的时间,在进行中期分析时,65名安慰剂患者中的20名和63名gamma干扰素患者中的7名都至少经历过一次严重感染。在这里,我们把每一个个体视作一个簇,每个个体的各次复发的间隔时间视为簇中的成员。
假设数据可以由加性–乘积模型拟合,即
,定义
为治疗代码,如果病人接受gamma干扰素治疗则取1,如果病人在安慰剂组则取2,
为规范化后的个体年龄。
通过本文的方法可以得到的
的估计分别为:
,
,标准差分别是0.2242和0.0011,检验P值分别为2.3996 × 10−4和0.01689,根据
的值的大小,能够得出当
时比
基准风险率函数低,由此可见用gamma干扰素治疗的风险比安慰剂组的风险更低,而且P值小于0.05,说明gamma干扰素治疗能显著降低感染慢性肉芽肿病的风险率函数,根据
的值的大小以及相应的P值,可以得出年龄越大感染慢性肉芽肿病的风险显著地越低。具体地,固定年龄时,干扰素治疗组的风险率在时刻t时比安慰剂组的风险率绝对数值降低
,固定治疗组别时,年龄每增加10岁,风险率的绝对数值降低4.8 × 10−4。另外我们给出累积的基准风险率函数的估计
,由它可以得到
在每个时刻的近似估计,见图1 (横坐标为所有个体的复发事件的间隔时间t,单位为天)。

Figure 1. Estimation for
图1.
对时间的函数图像
为了对模型的拟合优度进行检验,我们对残差进行分析:我们来绘制残差
关于个体复发
的散点图,见图2 (横坐标为所有个体的复发的标识,128个个体共有203个复发),其中
残差图可看出,残差随机分布在[−2, 2]中,因此不拒绝给出的模型。
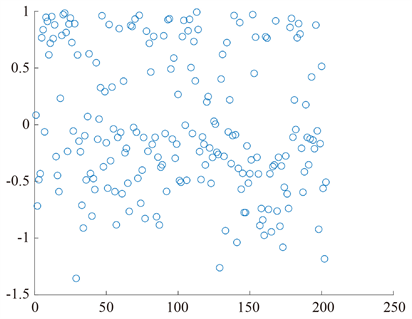
Figure 2. Scatter of residual vs. individual
图2. 残差对个体的散点图
5. 总结
在这篇论文中,我们对聚类失效时间建立了边际加性乘积风险率函数模型,应用估计方程的思想进行统计推断,在计算中,我们使用了牛顿迭代法,得到参数的估计,应用大数定律证明估计量的相合性,应用中心极限定理证明估计量的渐近正态分布,并给出估计量的渐近方差,然后进行数值模拟验证提出的方法,模拟结果表现较好,最后将提出的模型和方法应用于实际数据,找到gamma干扰素治疗和年龄对慢性肉芽肿病的影响方式。未来我们将考虑在模型中加入随机效应项表示同一类之间的相关性,利用的数据信息更充分,相应的估计方法也更具有挑战性。