1. 引言
随着时代的发展,以及科技的进步,时序数据(按照时间顺序变化的数据)与人们的生活息息相关,在军事、金融、医疗、网络安全方面都得到了很好的体现,尤其是在工业化高度发展的今天,工厂时序数据的异常检测成为了数据分析领域的热门研究方向。所谓异常值是指与其他观测值表现相差较大以至于产生怀疑的观测值 [1]。异常检测的任务是根据数据分析的形式,找出哪些数据实例与其他数据实例表现不同,即异常值 [2]。
由于异常的不可预知性以及高度变化性,人们通常将异常检测任务视为无监督学习 [3],传统的有监督学习并不适用于时序数据的异常检测。有很多研究人员开发出了一些比较有效的异常检测方法,其中包括一些聚类模型,通过聚类不同的数据样本来预定义异常值得分来判别异常。同样,基于距离的方法,例如K最近邻算法 [4],其算法是通过计算每个数据样本和相邻数据的平均距离来获得异常得分,从而达到异常检测的效果。还有一些分类方法,例如一类支持向量机 [5],通过对训练数据的密度分布进行建模,将时序数据分为正常值和异常值。虽然在很多研究中证明了这些方法的有效性,但是对于处理多元时序数据,他们的异常检测效果差强人意。之后研究者提出了自回归综合移动平均(ARIMA)模型 [6],虽然可以对多元时序数据进行有效异常检测,但是只能模拟线性特征,无法有效表示系统的非线性特征,并且对噪声相对敏感,抗噪能力差。
由于传统的机器学习方法表现出了诸多的弊端,研究者们将目光放到了基于深度学习的无监督异常检测的方法上。例如深度自编码高斯混合模型 [7],将高斯混合模型与深度自动编码器有效结合,对多元数据的密度分布进行建模,从而达到时序数据异常检测的目标。LSTM编码解码器 [8] 利用长短时记忆网络对时序数据的时间依赖性进行建模,相较于传统方法,泛化能力得到了增强。但此类模型依旧存在弊端,他们只考虑了时间序列的时间依赖性,在真实系统中,往往具备若干传感器,所接收到的多元时序数据具有复杂性,不同的时间序列间也表现出时间依赖性和相关性特征,如何将他们有效结合从而达到异常检测的效果成为了研究者们有待解决的问题,这也使得关于时序数据的异常检测成为了一项具有挑战性的工作。
所以本文构建的基于XGBoost的多维自注意卷积门控循环编码器不仅考虑了多维时序数据的时间性特征,并且将时序数据的相关性特征也有效提取,二者有机结合,提高了时序数据异常检测的有效性和准确性。其中采用XGBoost对多变量输入进行特征提取和筛选,能够做到有效缩短训练时长,并将多余特征变量剔除,增强了网络的健壮性和准确性。
2. 基于XGBoost的多维自注意卷积门控循环编码器
2.1. 问题阐述
异常检测的目标是有效地处理、分析真实数据集,利用特定算法识别出异常点。假设给定N个长度为m的时间序列,可用公式表示为
(2.1)
其中N表示变量个数,m表示时间序列的长度。
2.2. 特征筛选
如图1(1)所示,本文采用XGBoost对实验数据集中数据进行特征筛选,过滤无关变量,保留有效变量。XGBoost是一种基于梯度提升决策树(GBDT)的极致梯度提升算法。该思想在 [9] 中正式提出,作者提到XGBoost基本思想与GBDT相同,但是进行了很多优化,比如为了优化损失函数,提高计算精确度,采用二阶泰勒公式进行展开;使用正则项来简化模型,避免过拟合;采用Blocks存储结构,实现并行计算。
其目标函数包含两部分,分别为损失函数与正则化项,可表示为:
(2.2)
其中
是损失函数,
为预测值,
是正则化项,表示k棵树的复杂度。由于
(2.3)
所以目标函数可表示为
(2.4)
为了优化损失函数,根据二阶泰勒公式展开,则损失函数可表示为
(2.5)
其中
为损失函数的一阶导数,
为损失函数的二阶导数,这里的求导是指对
求导,去除常数项
,损失函数可表示为
(2.6)
为了优化正则化项,将正则化项展开,得到
(2.7)
因为
棵树的结构已经确定,所以可视为常数,所以去除常数项
,则正则化项可表示为
。
定义一棵树,设置叶子结点的权重向量为w,叶子结点的映射关系为q,则
,
,之后定义树的复杂度
,则
(2.8)
其中T表示叶子结点的数量,
表示叶子结点权重向量的
范数。本文将属于第j个叶子结点的所有样本
划分到一个叶子结点的样本集合中,可用数学公式表示为:
(2.9)
则XGBoost的目标函数可以表示为:
(2.10)
将
代入目标函数得:
(2.11)
最后将所有训练样本,按照叶子结点进行分组得:
(2.12)
定义叶子结点j所包含样本的一阶偏导数之和为
,叶子结点j所包含样本的二阶偏导数之和为
,将其代入目标函数得:
(2.13)
最后通过目标函数求解最优解来计算各个特征重要性得分。根据提供的总样本中各个特征的重要性分数,进行无关变量的剔除,得到处理后的多变量时间序列
(2.14)
其中
,n表示变量个数。
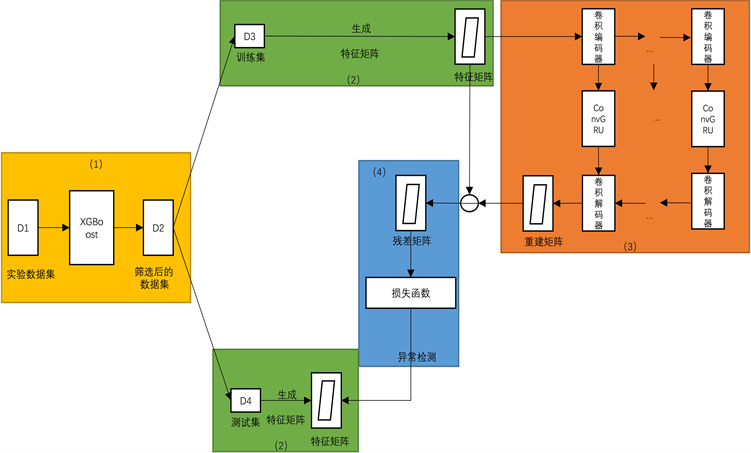
Figure 1. The MDACGA block diagram based on XGBoost: (1) feature selection based on XGBoost; (2) Generate the characteristic matrix; (3) Extracting correlation and temporal features; (4) Loss function
图1. 基于XGBoost的MDACGA框图:(1) XGBoost特征筛选;(2) 生成特征矩阵;(3) 提取相关性、时间性特征;(4) 损失函数
2.3. 构建特征矩阵
论文 [10] 中提到,不同时间序列间的相关性是表征系统状态的重要因素,为了提取不同时间序列间的相互关系,根据 [11] 中提到的方法,利用前面处理过的多变量时间序列,取特定时间长度的时间序列片段,然后将不同时间序列片段两两内积,形成
的特征矩阵
,如图1(2)所示。假设两个时间序列,取时间窗口为w,时间序列片段可表示为
和
,则他们之间的相关性
按下列公式计算:
(2.15)
其中
为缩放因子(
)。这样构造的特征矩阵
不仅具有不同时间序列间的相关性特征,而且对输入的噪声具有鲁棒性。
2.4. 提取相关性特征
如图1(3)中所示,本文利用全卷积编码器 [12] 来对特征矩阵进行编码,提取不同时间序列间的相关性特征。将前面构建的特征矩阵看作是一个张量
,之后将其输入进若干卷积层,假设
表示第
层的特征映射,那么第l层的输出可表示为:
(2.16)
其中
表示卷积运算,
为激活函数,
表示大小为
的
卷积核,
为偏置项,
表示第l层的输出特征图。
之后,利用缩放指数线性单元(SELU) [13] 作为激活函数,设置四个卷积层,分别具有32个步长为
,大小为
的卷积核;64个步长为
,大小为
的卷积核;128个步长为
,大小为
的卷积核;以及256个步长为
,大小为
的卷积核。
2.5. 提取时间性特征
前文利用卷积编码器所提取的相关性特征映射在时间上依赖之前的时间步,早在 [14] 中就已提及使用ConvLSTM来捕获视频序列中的时间信息,但是需要计算大量的参数,耗时较长。相比较于ConvLSTM而言,ConvGRU具有相似的结构、相似的建模效果,但是参数较少,训练时间较短。与此同时,传统的ConvLSTM和ConvGRU在处理时间序列时,随着时间序列长度的增加,效果明显下降。为了有效处理长时间序列,如图1(3)所示,本文提出基于注意力机制的ConvGRU,能够有效提取前一个时间步所包含的信息。假设给定第l个卷积层
和之前的隐藏层
,ConvGRU [15] 作为GRU的拓展可定义为:
(2.17)
(2.18)
(2.19)
(2.20)
其中
表示卷积操作,
表示哈达玛积,W,U,b分别表示ConvGRU的可学习参数:前向连接权值、循环连接权值和偏置参数。
和
分别表示ConvGRU的复位门和更新门,
为(t−1)时刻隐藏状态,
则为(t-1)时刻候选状态,最后得出t时刻隐藏状态
。与GRU相比,ConvGRU的卷积运算保留了空间拓扑,在二维特征图上使用二维权值核。考虑到并不是前面所有的时间步都与
相关,所以采用注意力机制,来自适应地选择与当前时间步相关的时间步和聚合信息,从而将特征映射到一个精炼的输出特征图
,公式如下:
(2.21)
(2.22)
其中
表示矢量,
为缩放因子。即取最后一个隐藏状态
作为上下文向量,通过softmax函数度量前几步的重要度权重
。基于注意力机制的ConvGRU很好地在每个卷积层联合建模带有时间信息的特征矩阵的空间结构。
2.6. 卷积解码
卷积解码器的作用是对前一步所得到的特征矩阵进行解码,从而得到重建后的特征矩阵,卷积解码器 [12] 表达式如下:
(2.23)
其中
表示反卷积运算,
表示串联运算,
为激活单元,
为第l个卷积层的滤波核和偏置参数。具体而言,本文按照逆序将ConvGRU第l层的
输入进反卷积神经网络中。输出特征图
与前一个ConvGRU层的输出串联,将他们之间的串联表示进一步输入到下一个反卷积层,最终得到输出
(重建后的矩阵),如图1(3)所示。
卷积解码器使用与卷积编码器相对应的四个反卷积层,分别为128个步长为
,大小为
的卷积核;64个步长为
,大小为
的卷积核;32个步长为
,大小为
的卷积核;以及3个步长为
,大小为
的卷积核。该卷积解码器能够有效联合ConvGRU和反卷积层的特征映射,提高了异常检测的性能。
2.7. 损失函数
对于MDACGA而言,目标定义为特征矩阵的重建误差,即:
(2.24)
如图1(4)所示,本文采用 [16] 中提到的Adam优化器和小批量随机梯度下降法来最小化上述损失。经过若干训练阶段后,学习到的神经网络参数可被用来推断验证集和测试集中数据的重建特征矩阵。最后,利用残差特征矩阵进行异常检测。
3. 实验验证与结果分析
3.1. 实验数据及特征筛选
本实验利用田纳西-伊斯曼(TE)仿真平台生成的TE标准数据集来进行算法验证,该仿真平台是美国Eastman化学公司依靠实际化工反应过程开发的开放性化学仿真平台,具备公认性和权威性。该平台采集到的数据与时间关联性强,并且变量间具备相关性特征,所以在工业控制以及故障检测领域都得到了广泛的应用。整个TE数据集由两部分构成,包括训练集与测试集,由于所有的数据都是通过22次不同的实验产生的,所以其中包含了52个观测变量以及21种不同的故障类型。本实验选取1417个正常时间点,其中插入7个含有故障类型一的时间点,8个含有故障类型二的时间点,8个含有故障类型三的时间点,8个含有故障类型四的时间点。首先利用XGBoost来进行特征变量的重要性筛选,如图2所示,选取出评分较高的46个控制变量,实验数据集具体参数见表1:

Figure 2. The XGBoost feature filtering
图2. XGBoost特征筛选

Table 1. The specific parameters of the experimental data set
表1. 实验数据集具体参数
3.2. 评价指标
本文使用精度(Precision)、召回率(Recall)和F1分数(F1 Score)三个指标来评估本文的方法和对比模型的性能。
(3.1)
(3.2)
(3.3)
其中Prec表示精度,Rec表示召回率,TP、TN、FP、FN分别表示真阳性、真阴性、假阳性和假阴性的数量。Prec为精确率,等于TP比上检测结果为正常的样本(
),
,Prec越大表示精确度越高;Rec为召回率,等于TP比上实际为正常的样本(
),
,Rec越大表示召回率越高。为了达到异常检测的目标,使用验证数据集上的最大异常分数来设置阈值。在测试集中,任意时间点异常得分超过阈值将被视为异常。
3.3. 实验结果与分析
本文采用基于XGBoost特征筛选的MDACGA与两种深度学习算法进行对比,其中包括LSTM算法 [17]、MSCRED算法 [11] 以及MDACGA算法,根据表2可以看出不同检测算法在使用XGBoost与未使用XGBoost进行多元时序数据异常检测时的性能,其中在都未使用XGBoost进行特征筛选的情况下,实验后计算得到的MDACGA的精度优于其他两种算法,说明甄别错误的能力明显优于其他两种算法;根据三种算法的召回率比较,可以得出LSTM与MSCRED倾向于将数据标记成正常数据,而MDACGA则在数据标记方面比较均衡。在都使用XGBoost进行特征筛选的情况下,结果亦是如此。
Table 2. The abnormal detection results of different algorithms
表2. 不同算法异常检测结果
由图3~5可以看出,使用相同算法进行异常检测,在有无使用XGBoost进行特征变量筛选的前提下,相同算法表现出了不同的异常检测结果,其中可以看到,使用了XGBoost的算法,无论是异常检测的精确性,还是异常检测的稳定性,相较于未使用XGBoost的算法,表现都要更加优越。尤其是使用XGBoost进行特征筛选之后,模型都表现出了更好的健壮性与适应性。
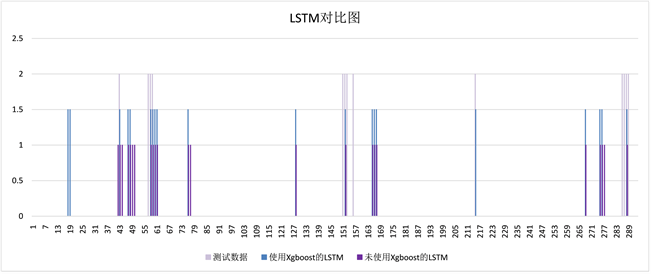
Figure 3. Using XGBoost to filter the abnormal detection results of LSTM before and after feature selection
图3. 使用XGBoost进行特征筛选前后的LSTM异常检测结果
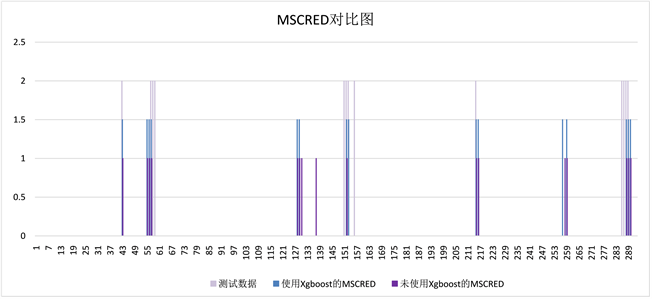
Figure 4. Using XGBoost to filter the abnormal detection results of MSCRED before and after feature selection
图4. 使用XGBoost进行特征筛选前后的MSCRED异常检测结果
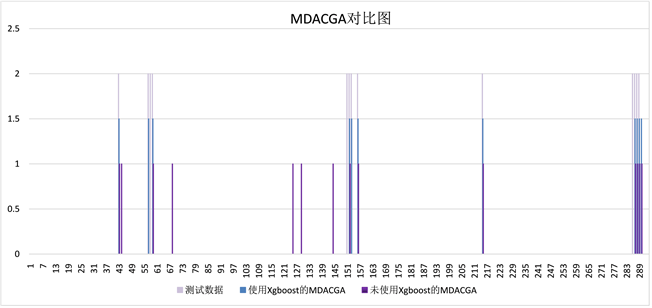
Figure 5. Using XGBoost to filter the abnormal detection results of MDACGA before and after feature selection
图5. 使用XGBoost进行特征筛选前后的MDACGA异常检测结果
4. 结语
在真实数据集上的实验结果表明,基于XGBoost特征筛选的MDACGA在多变量时间序列的异常检测方面,具有有效性;与其他两种深度学习算法相比,基于XGBoost特征筛选的MDACGA在异常检测方面具有优越性;并且使用XGBoost进行特征筛选有效提高了算法进行异常检测的准确性。但是工业数据集种类繁多,在数据集过大、传感器变量过多时,由于噪声过大,导致异常检测结果不尽如人意;数据集过小,传感器变量过少时,由于相关性特征不够明显,结果亦是不够理想,所以在后期研究中,将提高该检测模型的抗噪性与泛化性。