1. 引言
我国人口众多,并具有流动性大的特点,因此很容易影响社会的稳定性。近年来,人口流动的规模在不断增加,人口的流动不仅给地区间带来了积极的影响,例如更多的劳动力,更多的高技术人才以及更多的市场需求外,同时也会对社会福利、环境污染、治安管理等带来一定的负面影响。因此,通过统计学方法对地区间人口流动进行预测,不仅可以使人口流入地调整政策更合适地接纳大规模的新居民,也可以使人口流出地在一定程度上弥补由于人口流失带来的损失。
2. 方法
目前国内外对于人口流动原因的研究主要集中在环境,经济以及重大事件上,藏媛,郝枫构建异质劳动力跨期效用模型,匹配CMDS-2017与286个地级市统计数据,采用IV-logit模型考察空气质量变化对流动人口城市留居意愿强度的影响。研究发现空气质量改善会增强流动人口留居意愿强度,但提升能力边际递减 [1]。宫湛秋,孙诚等利用基于信息流理论的因果分析方法,研究了1880年以来观测的AMO与北大西洋海表热通量间的因果关系。结果表明,在多年代际尺度上,从AMO到海表热通量的信息流要远大于二者相反方向的信息流,说明AMO是北大西洋海表热通量异常的因,海洋主导了海气间的热量交换 [2]。
本文将以江苏省为例,聚焦江苏省粮食生产比重最大的水稻,研究自1999年至2018年20年间,江苏省水稻产量和人口变化之间的联系。由于在模型中,水稻产量作为本研究的主要研究对象,其很有可能是内生的,其不仅受到其他扰动项的影响,例如历史因素,产业结构等,在影响被解释变量的同时,也受到被解释变量的影响(人口的增加带来了更多的劳动力,更多粮食的需求,促进了水稻产量的提升)。因此,在实际研究中必须要构建合适的工具变量来进行分析。本文选取江苏省化肥使用量作为水稻产量的工具变量,分析化肥使用量和人口流动之间的因果关系。在目前大量的研究中,对于因果性的分析主要都是利用传统的格兰杰因果关系。但是格兰杰因果检验只是判断两个事件发生的先后顺序在统计学领域是否是显著的,不算真正的因果关系。本文运用的梁氏–克里曼信息流将信息传递的概念引入因果分析,将两个事件之间的信息传递可以定量的表达出来,既简洁,准确率也高。根据两者之间信息传递的绝对值便可以分辨出哪个是“因”,哪个是“果”。梁湘三提出,二维系统下两个事件之间的信息传递
为:
其中
为样本协方差,
是
和由
导出的级数之间的样本协方差 [3]。
3. 数据和变量选取
为研究粮食产量和人口流动之间的关系,本文以江苏省为例,粮食产量选取江苏省粮食生产比重最大的水稻作为研究对象,研究自1999年至2021年23年间,江苏省年水稻产量和人口变化之间的联系。为了使模型的拟合程度更加高,本文还选取江苏省年均气温,年均降水量,年水稻种植面积以及年限额以上餐饮行业营业总收入作为其他解释变量加入模型。以上数据均来自中国统计年鉴 (http://www.stats.gov.cn/tjsj/ndsj/),其中人口数据为年末总人口减去自然增长的人口,使数据可以更好地体现人口流动的变化。
本文运用stata软件进行分析,在线性模型的基础上,模型的R2值为0.96,证明该模型拟合程度较好。在实际分析中,水稻产量作为本研究的主要研究对象,其很有可能是内生的。若模型存在内生解释变量,则需要利用外生的,和解释变量强相关的工具变量来代替解释变量,若工具变量和被解释变量存在因果关系,则根据相关性,就可以推导出解释变量和被解释变量间存在因果关系。本文选择江苏省年均化肥使用量作为水稻产量的工具变量,一方面是化肥使用量和水稻产量有着较强的相关性:化肥使用增加,水稻产量也会相应增加。另一方面,化肥使用和人口流动并没有直接的关系,因此可认为该工具变量是外生的,可以运用到本次研究中。文章所用到的变量标识和单位如表1所示。

Table 1. Variable Identification and Unit Name
表1. 各变量标识和单位名称
4. 实例分析
4.1. 内生性检验
根据方差齐性的不同,内生性检验分为两种:在同方差情况下,运用Hausman检验;在异方差情况下,运用Durbin-Wu-Hausman检验(DWH检验)。根据WHITE检验的结果,检验p值为0.3474,大于0.1,因此可以认为模型不存在异方差,选取Hausman检验。Hausman检验结果如图1,根据图中结果可知,Hausman检验的p值为0.0327,小于阈值0.05,因此可认为水稻产量作为解释变量是内生的,因此需要引入工具变量。
4.2. 不可识别检验
不可识别检验是判断工具变量的个数是否小于内生解释变量的个数,其原假设H0为:工具变量识别不足。在样本并非独立同分布的情况下,该检验需要利用Kleibergen-Paap rk LM统计量进行判断。根据图2显示结果,Kleibergen-Paap rk LM统计量的p值为0.0047,小于0.05,拒绝原假设,证明工具变量的个数至少大于等于内生解释变量个数。
4.3. 弱工具变量检验
该项检验主要是研究选取的工具变量与内生解释变量的相关性强度。在弱相关的情况下,使用工具变量进行估计的结果会相较于OLS的结果相差较大。在非独立同分布的情况下,该检验需要利用Kleibergen-Paap rk WaldF统计量进行判断。根据图2显示结果,Kleibergen-Paap rk WaldF统计量值为15.383,大于显著性15%的临界值,因此可以推断该模型不存在弱工具变量,选用化肥使用量作为工具变量和水稻产量之间的相关性较强。
4.4. 过度识别检验
该检验主要是研究所有的工具变量是否全是外生的。在非独立同分布情况下,该检验利用HansenJ统计量进行判断。由图2结果“(equation exactly identified)”可以看出,此时工具变量个数和内生解释变量个数恰好相等,模型恰足确认,因此可以认为化肥使用量作为工具变量是外生的。
4.5. 因果分析
在本阶段的研究中,文章使用梁氏–克里曼信息流来证明化肥使用量和人口变化之间的因果关系。梁氏–克里曼信息流运用的前提条件为:两条研究的时间序列对象必须是平稳的,且时间间隔相同。根据单位根检验可知,肥使用量和人口变化序列并非是平稳的,带有时间趋势,分别对两序列做一阶差分处理,由图3和图4单位根检验p值可以看出,差分运算后的序列平稳,因此可以进行梁氏–克里曼信息流的求解。

Figure 2. Test results of instrumental variables
图2. 工具变量检验结果

Figure 3. Unit root test of population change
图3. 人口变化的单位根检验

Figure 4. Unit root test of fertilizer usage
图4. 化肥使用量的单位根检验
对两条时间序列进行梁氏–克里曼信息流的求解。根据二维线性模型系统下,
到
的信息流率的最大似然估计
的公式:
可以得出化肥使用量对人口流动的信息传递为0.04934。为探究该因果关系是否是显著的,因此还需对结果进行显著性检验 [4]。文章基于三种不同的显著性水平90%,95%和99%,分别计算三种不同的显著性水平下的置信区间。若0不包含在置信区间中时,即可认为该因果关系是显著的。三种不同的置信区间如表2所示。从表中信息可以看出在90%和95%的显著性水平下,化肥使用量和人口流动之间存在着显著的因果关系。相反的,从表3可以看出,人口流动对化肥使用量信息传递的置信区间均包含0,因此可以判定该因果关系不显著。对比两者可以推导出,化肥使用量是人口流动的“因”,根据工具变量的强相关,进一步可以推导出江苏省水稻产量和江苏省人口流动有着因果关系。在实际运用中,决策部门可以聚焦于当地水稻产量的变化,若水稻产量即将出现大幅上涨或下跌的趋势,那么就应该做好相应的准备,面对可能出现的大规模的人口流动。
Table 2. Confidence interval of fertilizer usage on the population mobility flow information
表2. 化肥使用量对人口流动信息传递的置信区间
Table 3. Confidence intervals of population mobility for information transmission of fertilizer use
表3. 人口流动对化肥使用量信息传递的置信区间
5. 人口预测
5.1. 基于ARIMA模型的人口流动预测
在明确了江苏省水稻产量对江苏省的人口流动有着显著的因果关系之后,本文的下一个目标便是根据水稻产量的变化来预测未来江苏省人口的流动。在本环节,由于模型存在内生变量,所以本文选用两阶段最小二乘对模型进行回归。在得到回归模型之后,本文选取1990年至2013年江苏省年均气温、江苏省年水稻种植面积、江苏省年均降水量和江苏省年水稻产量,利用ARIMA模型对该4个指标进行拟合,并计算出2014年至2018年各指标的预测值,根据回归模型得到未来5年江苏省人口流动的预测值,并与实际数据进行比对,若预测值和实际值较为相似,即可认为该方法准确度较高。
根据2sls回归得到的结果,模型拟合程度的p值为0.00,小于显著性水平0.05,因此可以认为该模型显著性较高,拟合程度较好。模型表现形式如下:
得到关于江苏省流动人口的模型之后,文章将利用ARIMA模型对1990年至2013年江苏省年均气温、江苏省年水稻种植面积、江苏省年均降水量和江苏省年水稻产量进行拟合,并得到2014年至2018年各指标的预测值。由于针对不同变量建模过程较为相似,文章以江苏省年水稻产量为例,进行ARIMA模型拟合。
首先,文章对江苏省年水稻产量进行ADF单位根检验,若时间序列是非平稳的,则需要进行差分处理,使其变为平稳序列,再进行模型拟合。根据计算可得ADF统计量为−3.426482,p值为0.010089,小于显著性水平0.05,拒绝原假设,因此该序列是平稳的。经LB检验,LB检验统计量显著性水平为0.00,小于显著性水平0.05,因此该时间序列并非白噪声序列。做出该平稳序列的自相关和偏自相关图,结果如图5所示。由图中看出,江苏省年水稻产量的自相关图1阶拖尾,偏自相关图1阶拖尾,根据ARIMA模型定阶准则,满足要求的模型有ARIMA (1, 0, 1),ARIMA (4, 0, 1),ARIMA (5, 0, 1),ARIMA (8, 0, 1)和ARIMA (9, 0, 1)。分别计算出该三个模型的AIC值,结果如表4。根据AIC准则,选取AIC值最小的模型,因此对于江苏省年水稻产量选取ARIMA (4, 0, 1)模型。根据模型预测出未来5年江苏省水稻年产量,2014至2018年水稻产量为分别为1790.38万吨、1825.06万吨、1836.22万吨、1828.57万吨、1809.69万吨。

Figure 5. Autocorrelation and partial autocorrelation of annual rice output in Jiangsu Province
图5. 江苏省年水稻产量自相关和偏自相关图
Table 4. AIC value of each model of annual rice production in Jiangsu Province
表4. 江苏省年水稻产量各模型AIC值
分别对江苏省年均气温、江苏省年水稻种植面积、江苏省年均降水量和江苏省限额以上餐饮行业年收入进行ARIMA模型拟合并预测,得到结果如表5。根据该四个变量的预测值计算出2014年至2018年江苏省非自然增长人口数的预测值,并与真实值进行比较,结果如图6。通过对预测值和真实值的对比,发现预测值和真实曲线拟合程度较高,因此该种方法的准确率较好。据此预测出2022至2026年的江苏省非自然增长人口,如表6及图7所示。
Table 5. Predicted values of various variables from 2014 to 2018
表5. 各变量2014年至2018年预测值
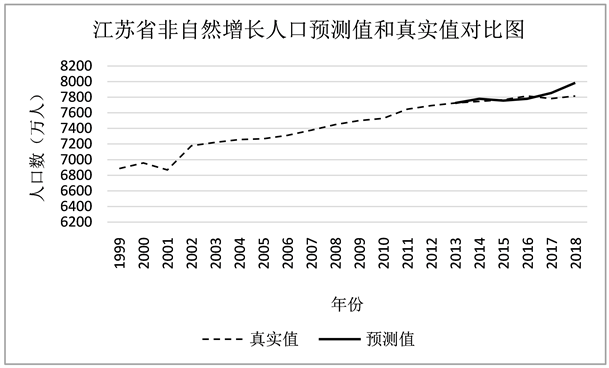
Figure 6. Comparison of predicted and true values of unnatural population growth in Jiangsu Province
图6. 江苏省非自然增长人口预测值和真实值对比图
Table 6. The predicted value of unnatural population growth in Jiangsu Province in the next five years
表6. 未来5年江苏省非自然增长人口预测值
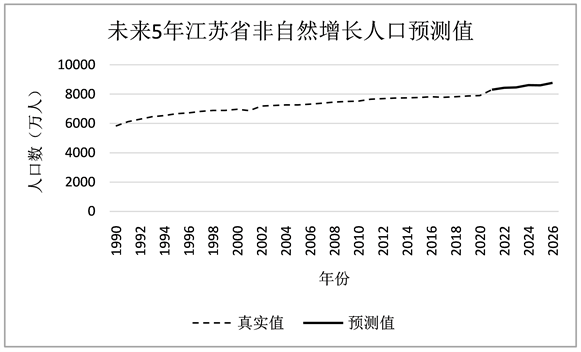
Figure 7. The predicted value of unnatural population growth in Jiangsu province in the next five years
图7. 未来5年江苏省非自然增长人口预测值
5.2. 基于滞后因果关系的人口流动预测
除了利用各变量每一年的数据进行2sls拟合,并建立各自变量的ARIMA模型,计算出各变量的预测值,从而通过线性模型得到江苏省非自然增长人口的预测值这一种方法外,本文还提出了另外一种方法。本文将所有因变量江苏省非自然增长人口滞后若干期,探究在人口数滞后的条件下,水稻产量是否会和人口数之间存在着显著的因果关系。若存在,便可以通过水稻产量的变化,预测出江苏省人口流动的变化。此外,对所有自变量与滞后的因变量这一新的数据集进行两阶段最小二乘回归,得到关于滞后人口数量的线性模型,便可以根据不同年份的数据,计算出未来各年,江苏省非自然增长人口的预测值。经过滞后不同的期数,重新进行工具变量的选取和梁氏–克里曼信息流的计算,本文得出结果:在人口数滞后2年,选取江苏省年化肥使用量作为江苏省年水稻产量的工具变量的条件下,化肥施用量和非自然增长人口数之间存在着显著的因果关系。工具变量检验及化肥施用量对滞后2年江苏非自然增长人口的梁氏–克里曼信息流如图8和表7所示。
不可识别检验中,Kleibergen-Paap rk LM统计量的p值为0.0055,小于0.05,拒绝原假设,证明工具变量的个数至少大于等于内生解释变量个数。在弱工具变量检验中,Kleibergen-Paap rk Wald F统计量为11.374,大于显著性水平15%的临界值,因此该模型中不存在工具变量。由于该模型中工具变量与内生变量的数量相同,所以必定会通过过度拟合检验。因此,在该模型中,使用江苏省年化肥使用量作为江苏省年水稻产量的工具变量是合适的。计算江苏省年化肥使用量和江苏省年非自然增长人口之间的梁氏-克里曼信息流置信区间,结果如表7所示。从表7数据可以看出,在显著性90%和95%的水平下,化肥使用量对人口流动信息传递因果关系的置信区间均不包含0,因此可以认为该因果关系是在90%和95%的显著性水平下是显著的。根据工具变量和内生变量的强相关性,可以认为江苏省年水稻产量和滞后2年的江苏省非自然增长人口之间具有显著的因果关系,且水稻产量是人口流动的“因”。
根据两阶段最小二乘法建立各自变量和滞后2年的江苏省非自然增长人口之间的线性模型,得到模型如下:
该线性模型的R2为0.9241,p值为0.00,小于显著性水平0.05,说明该模型拟合程度较好。根据2020和2021年江苏省年水稻产量,江苏省年水稻种植面积,江苏省年均降水,江苏省年均气温和江苏省限额以上餐饮企业年收入的数据,可以计算出2022和2023年江苏省非自然增长的人口数量,分别为8333.812万人和8574.089万人,相较于之前的数据,江苏省非自然流动人口也呈上升趋势。

Figure 8. Instrumental variable test with a two-year lag
图8. 滞后两年的工具变量检验
Table 7. Confidence interval of fertilizer use on the information transmission of population flow with a lag of two years
表7. 化肥使用量对滞后两年人口流动信息传递的置信区间
6. 结语
本文基于中国统计年鉴上江苏省非自然增长人口数据,利用江苏省化肥使用量作为江苏省水稻产量的工具变量,对数据进行因果分析。经由不可识别检验、过度识别检验和弱工具变量检验,选取化肥使用量作为水稻产量的工具变量是合理的。经过计算化肥使用量和江苏省非自然增长人口数之间的梁氏–克里曼信息流,可得,江苏省化肥使用量和江苏省非自然人口变化之间存在显著的因果关系,且化肥施用量是人口流动的“因”。根据工具变量的强相关,进一步可以推导出江苏省水稻产量和江苏省人口流动有着因果关系。
在对江苏省非自然增长人口的预测阶段,文章采用了两种不同的方法进行实践。第一种方法是根据历年江苏省非自然增长人口数和江苏省年均气温、江苏省年水稻种植面积、江苏省年均降水量和江苏省年水稻产量数据,通过2sls方法建立起工具变量回归模型。得到人口数和各自变量的回归模型后,通过时间序列分析法,对江苏省水稻产量等自变量数据进行模型拟合,分别对各自变量建立ARIMA模型,并通过模型对未来5年数据进行预测。得到各自变量的预测值后,通过先前构建的工具变量回归模型,计算出未来5年江苏省人口数。经过将预测值和真实值进行对比后,该种方法准确率较高,可以用于预测江苏省未来的流动人口。文章选取1999年至2021年江苏省各变量数据,得到2022年至2026年江苏省非自然增长人口,并且人口数呈持续上升的趋势。
第二种预测方法则是将江苏省人口数据滞后若干年,分别计算江苏省化肥使用量和流动人口之间的梁氏–克里曼信息流。如果滞后某一年数的人口数量与化肥使用量存在显著的因果关系的话,便可以根据当前数据,得到未来某一年的江苏省流动人口数。对滞后的数据集进行工具变量检验可得,使用江苏省年化肥使用量作为江苏省流动人口的工具变量依然合适,因此,经过反复试验,文章得出结果:在江苏省非自然增长人口数滞后两年时,与江苏省年化肥使用量之间存在显著的因果关系,所以可以使用该结论对未来江苏省流动人口进行预测。文章对江苏省非自然增长人口和各自变量建立2sls模型,模型R2值为0.9241,证明该模型准确度较高。利用2020年和2021年各自变量的数据,根据2sls模型可计算出2022和2023年的非自然增长人口数,分别为8333.812万人和8574.089万人,相较于2020年的7902.144万人和2021年的8300.6784万人,也是呈持续上升的趋势。
对比两种预测方法,文章更倾向于使用通过研究滞后的流动人口数与化肥使用量之间的因果关系,通过建立2sls模型来计算出流动人口预测值这一方法。在第一种方法当中,需要对每个自变量建立ARIMA模型,计算出各自变量预测值后利用2sls模型进行预测,建立的ARIMA模型数量较高,误差较大,虽然与真实值对比结果较好,但是稳定性不如第二种方法。此外,文章还利用多元LSTM神经网络和随机森林对江苏省未来的流动人口进行预测,但是由于本研究内容的数据集规模较小,使用神经网络和随机森林的误差较大,特别是验证误差保持持续上升的趋势,因此,使用神经网络和随机森林的准确率较低,利用滞后因变量这一方法更适用于本研究内容。
人口的流动不仅给地区带来了新鲜的劳动力,降低了劳动力成本,也带来了更多的物品需求,带动了地区经济发展。高教育人才的流动,会对流入地的技术科技能力带来积极的影响,增强该地区的竞争能力,同时也会对流出地造成不可忽视的损失,在高新技术方面也会有一定的落后。因此,在实际运用中,决策部门可以聚焦于当地水稻产量的变化,若水稻产量即将出现大幅上涨或下跌的趋势,那么就应该做好相应的准备,面对可能出现的大规模的人口流动。此外,本文为应对人口流动的研究提供了一个全新的思路。以往为应对人口流动而提出的一些措施,大多集中在环境条件领域,例如空气污染、水污染等,又或者是教育和产业结构方面,对于例如粮食、服装产业等也与民生息息相关的领域关注较少。因此,本文提出了一个思路,可以将目光更多转移到这些领域,例如粮食、餐饮业、服装业等,分析其与人口流动之间的联系,为人口流动的研究提出建议。
本文同样也存在着一些的不足之处,由于影响人口流动的因素是多样化的,仅从粮食产量这一点来解释人口流动说服力不足。此外,即使在预测过程中,通过两种方法建立的回归模型里,江苏省年水稻产量的回归系数均为负值,也不能断定水稻产量和人口流动是负相关的,还需要结合更多的变量,研究更多的地区进行综合讨论。因此在之后的研究中,希望能将更多变量引入模型中,建立多变量之间的因果模型,对人口流动提供更准确,更客观的预测。此外,由于本研究所涉及的样本数量较少,导致神经网络、随机森林等机器学习方法不能有效准确地运用,这还需要引入更多样本,找到合适的模型,进行进一步的验证与分析。
文章中只对江苏省非自增长人口和江苏省年水稻产量这二者之间的因果关系进行分析,并且只考虑到农业对人口流动的影响这一方面,对问题的研究不够全面。因此,在后续的研究中,希望能建立起多元时间序列之间的因果分析,不仅仅只关注农业,也将餐饮业,服装业等领域引入模型,并且根据不同的时间区间,计算出每一个时间点上,各自的梁氏–克里曼信息流,行成一个随时间变化的,动态的因果网络,并研究更准确,更合适的预测方法,对未来的人口流动进行便捷而有效的预测。
基金项目
国家自然科学基金委员会面上项目(12171247)。