1. 引言
随着统计理论的逐步完善与计算机技术的迅速发展,国内外已有很多相关领域的专家学者针对人类语言展开了深入的研究并且已取得了丰硕的成果。Steels发现了人类语言在句法、语法、语音、语义等层面存在复杂的网络结构,扩展了人类语言学体系的研究领域和视角 [1]。Ricard等指出语言是一个复杂网络,构成网络的结点可以是词、概念、句子等文本单元,结点之间以句法、语义、语音、拓扑等产生关系 [2]。丛进、刘海涛等人 [3] 介绍了人类语言学中常用的几种网络模型,包括小世界网络 [4] [5]、词共现网络 [6] [7] 等,指出了复杂网络作为一种研究人类语言学的新思路的重要性。
关于语言文本内部存在的规律行为,众多学者也作了深入的研究。对于非汉语言文本的标度行为研究,Altmann等介绍了在单词层次和单词字母层面中无标度规律的演化行为 [8]。Choudhury等对涵盖了3大语系的7种语言(英语、法语、德语、孟加拉语、爱沙尼亚语、印地语、泰米尔语)构建了词共现网络,通过整体拓扑特征进行深入比较,揭示了7种语言网络的共同特征 [9]。Montemurro等和Bhan等通过去趋势波动分析法(DFA)对韩、英语文本进行分析,发现韩语和英语的无标度行为 [10] [11]。Kulig对英语、德语、法语等西方语言文本中标点符号的使用进行了分析,发现在语言体系中标点符号的使用也满足无标度特征 [12]。
此外,对于汉语言文本的标度行为,Deng等从汉字使用频率角度对中国近现代小说加以研究,发现了中文同样存在无标度行为 [13]。Yang等使用去趋势波动分析法(DFA)和扩散熵分析法(DEA)对《红楼梦》文本进行分析,发现文本的句子序列产生于分数布朗运动 [14]。孙龙龙等对中国古典长篇小说四大名著使用去趋势波动分析法(DFA)进行研究,发现各不同章节的标度指数存在差异 [15]。Liang等从复杂网络角度对小说、散文、新闻报道、科普文章4种中文语料构建了字共现网络和词共现网络,发现了各种体裁的文本均满足无标度特征 [16]。以往学者研究语言网络时选择的研究对象多为诸如英语的表音文字体系,而关于诸如汉语的表意文字体系的研究较少。实际上,汉语言文本与西方语言文本存在较大差别,即中国的汉字起源于图像符号 [17],经过数千年演化后使得中国人的语言表达方式与西方产生较大差别。
随着文本语料的数据量增加,为了观察从宏观到微观不同时间尺度的结构特征[],国内学者对复杂网络的时间序列分析进行了深入的研究,Zhang等 [18] 第一次提出将非周期时间序列映射为网络的方法,通过提取时间序列周期,并将每个周期视为节点,计算每一对节点的相关强度,得到节点之间的相关强度矩阵。若强度大于一个阈值,节点之间连边,进而构建成为复杂网络。Xu等 [19] 提出了将网络中的每个节点与其邻近的k个邻居连接起来的方法。有文献使用了一种递归网络方法依据节点之间的关联强度构建网络 [20]。此外也有很多学者利用句法依存网络 [21] [22] 研究复杂网络在语言分类中的应用。
上述的时间序列被映射为一个静态网络,因此不能反映出复杂系统的动态行为。为了解决这个问题,本文从字层面对四大名著中的《红楼梦》文本展开研究,从状态转移网络的视角,通过文本字频构建局部状态,将相应的时间序列转化为复杂网络,对文本的标度规律以及网络结构进行了系统地分析,并在此基础上研究语言的写作风格。本文的结果一方面为《红楼梦》的作者争议提供了定量解释,另一方面为观察汉语所具有的特殊性和普遍性提供了新视角 [23]。
2. 数据描述与方法
2.1. 数据描述
本文数据采用中国四大名著中的《红楼梦》的文本数据,首先从网站 https://zh.m.wikisource.org/wiki/Wikisource/下载相应的电子版文档,然后整理校对相关文档,并对文本进行初步统计,忽略所有标点符号,得到《红楼梦》小说中的全文字数、章节数、字种数,最后将文本依据各个汉字的出现频繁程度转换为全文0-1序列。
本文统计了《红楼梦》中文本总字次C,统计得出字种数K,平均汉字频率为Avg,表1展示了《红楼梦》文本的相关统计数据。所有汉字的字频的序列记为
。记
,
为阈值系数。对于第i个汉字,若
则划分为频繁字,反之则划分为非频繁字。将频繁字记为数字1,非频繁字记为数字0,得到全文0-1序列。
例如:在《红楼梦》中摘取一段文字:“因曾历过一番梦幻之后,故将真事隐去,而借‘通灵’之说,撰此《石头记》一书也”。假定“因”、“过”、“一”等为频繁字,“曾”、“历”、“番”等为非频繁字。因此,该句话转换为0-1序列:“100110001100010100001101010101”。

Table 1. Relevant textual statistics
表1. 相关文本统计数据
2.2. 状态转移网络
2.2.1. 状态转移网络方法
步骤1为得到序列片段,将大小为S的窗口沿全文0-1序列
从前向后以步长为S滑动,其中N为序列长度,得到序列片段:
,
, (1)
得到的M种序列片段是对0-1窗口中对应的不同局部状态的描述。
步骤2 将每一个0-1序列片段映射为一种状态,得到所有状态集合
,表2展示了不同滑动窗口取值S中的0-1序列片段对应的状态名称。
步骤3 建立局部状态之间的状态转移网络。即在0-1序列中若一个状态
紧挨着另一个状态
,其中
,则构建从
到
的有向连接,由此可以得到状态链:
, (2)
遍历状态链,若在状态链中任意位置的两个状态对应的序列片段相同,则视为相同的状态。从状态链中可以得到状态的出现次数,即网络节点的度;而状态链中不同状态之间转移次数则表示网络中节点的连边权重;状态之间的转移方向表示节点之间的连边方向。在网络图中,以节点形态的大小表示状态的度,以网络连边的粗细表示状态之间的连边权重。从状态转移网络的结构特征中,可以观察到时间序列中隐含的动力学特征。
Table 2. Sliding window s = 5 , s = 6 corresponding series segments and state names
表2. 滑动窗口
、
时相应序列片段及状态名称
2.2.2. 阈值的选择
在形成状态转移网络的过程中,节点的出现频率即为网络节点的度。若网络中某个节点的度远大于其他节点,则该节点被称为中心节点。从度的分布图中很容易发现中心节点,但该中心节点的结构也有可能出现在随机网络中,即完全用中心节点代表原时间序列的特征是不准确的。随机打乱原始时间序列,并将该序列也按照上述方法构成状态转移网络,如果原时间序列网络中某个节点的度远大于随机打乱次序构成的网络中该节点的度,则该节点就被称为一个基本图(motif),即模体。模体可用来代表原时间序列中存在的典型局部状态。
为保证固定的时间序列长度下的模体数目和节点出现频数具有统计意义,滑动窗口S取5和6。对比不同倍数
下阈值
对应的原始序列与打乱序列的度分布,注意到当
、
时,模体较为明显,可表示序列中存在的典型局部状态。此时频繁字的字种数为102,得到不同窗口下《红楼梦》全文的状态转移网络的度分布,如图1所示。
2.3. 去趋势波动分析(DFA)
去趋势波动分析法(DFA)适用于分析非平稳性时间序列的长程相关性,该方法的优点是能有效地去除序列中各阶的趋势成分,并检测含有噪声和多项式趋势信号的长程相关记忆。假设一时间序列为
,其中N为序列长度。首先,由长度为S的滑动窗口沿时间序列滑动,得到时间序列片段
,其中
,用k阶多项式:
, (3)
进行拟合,其中
、
为拟合参数。拟合曲线作为每个时间序列片段的趋势。从原序列片段中减去相应的趋势值,可得到去趋势时间序列
:
, (4)
其中
,如果原时间序列存在长期相关性,则存在:
, (5)
其中,H为标度指数,若
,则表明时间序列可用随机游走表示;若
,表明时间序列为长期持续的记忆性过程;若
,表明时间序列为持续的反记忆性过程。

Figure 1. Degree distribution when the threshold
. (a1) shows the degree distribution of state transition network when the window size
; (a2) presents the degree distribution of state transition network when the window size
图1. 阈值
时,《红楼梦》的度分布。(a1) 为窗口
时状态转移网络度分布图;(a2) 为窗口
时状态转移网络度分布图
3. 实验与结果分析
当滑动窗口
和
时,构建状态转移网络分别分析《红楼梦》前80回和后40回每句字数时间序列,结果如下。
3.1. 滑动窗口s = 5
1) 状态转移网络
当滑动窗口
时,《红楼梦》前80回以及后40回的0-1序列均出现32种状态,如图2所示。图2(a1)~(b1)分别为由前80回和后40回的0-1序列构成的状态转移网络。为更清楚观察网络结构,将原网络(图2(a1)~(b1))中连边强度小于120、60的边从状态转移网络中过滤掉,得到图2(a2)~(b2),称为强化状态转移网络。将原时间序列随机打乱,并通过状态连边关系构建转移网络,在此基础上过滤掉连边强度小于120、60的边,得到图2(a3)~(b3),称为随机强化状态转移网络。在强化状态转移网络图以及随机强化状态转移网络图中,节点的大小代表相应节点的度;节点连边的粗细代表相应节点之间的连边强度。
在状态转移网络(图2(a1)~(b1))中可发现节点的自连边现象。状态(1)、(32)作为强自连边节点均出现在前80回和后40回中,自连边强度如表3所示,《红楼梦》前80回中状态(1)的自连边强度为1090、状态(32)的自连边强度为828,因此这些节点的自连边现象也出现在强化状态转移网络中;在后40回强化状态转移网络中状态(1)的自连边强度为703,状态(32)的自连边强度为168。此外,后40回与前80回的状态(1)的自连边强度比值为0.64,而后40回与前80回的状态(32)的自连边强度比值为而0.20,二者比值的差占总重要自连边强度比值的52.1%。
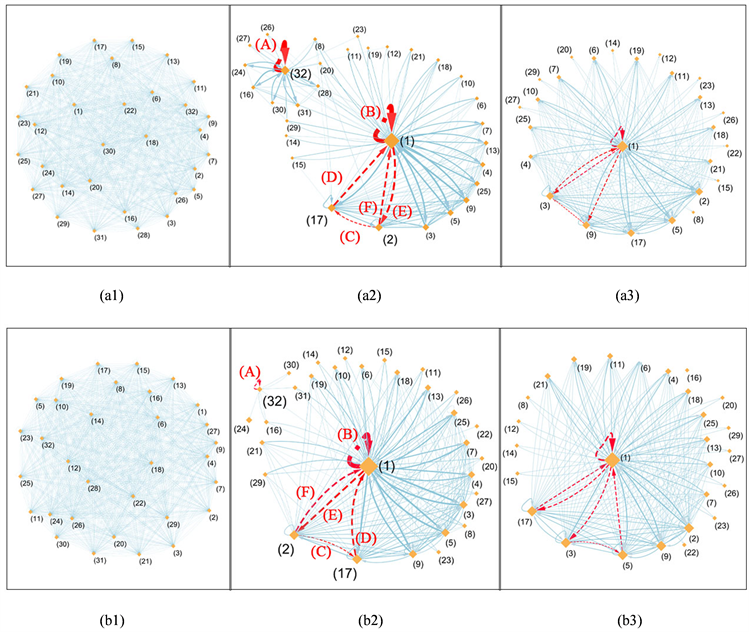
Figure 2. State transition network when the window size
. Red letter numbers and dashed lines represent the links with large weight. In (a2) and (b2), edges (A) and (B) represent self-links, the edge set (C, D, E) represents the important triangular cycles and the edge set (E, F) represents the important bidirectional cycles
图2. 滑动窗口
时的状态转移网络。红色字母编号与短划线标注的为权重较大的连边。(a2)和(b2)中的边(A)、(B)代表自连边;边集合(C, D, E)代表三角重要循环;边集合(E, F)代表双向重要循环
Table 3. State names and occurrence of self-links of the first 80 and last 40 episodes
表3. 前80回和后40回自连边状态及强度
在《红楼梦》前80回和后40回的强化状态转移网络中,均出现了连边强度很大的三角重要循环,如图2(a2)~(b2)中红色短划线标注的循环所示,前80回和后40回的强三角循环均为(1)→(2)→(17)→(1)。前80回和后40回三角循环中各边的连边强度如表4所示,其中连边强度最小的均是(2)→(17)的连边;而前80回中连边强度最大的是(17)→(1)的连边,后40回中连边强度最大的是(1)→(2)的连边。此外,前80回中(1)→(2)的连边强度与后40回中(1)→(2)的比值为0.58,而后40回中(17)→(1)的连边强度与前80回中(17)→(1)的比值为0.54,连边比值的差值占2个连边比值总和的3.4%。
Table 4. State names and occurrence of triangular cycles of the first 80 and last 40 episodes
表4. 前80回和后40回中三角循环连边强度
在强化状态转移网络(图2(a2)~(b2))中,也出现了连边强度很大的双向重要循环,如图中红色虚线标注的双向循环所示,前80回、后40回的双向重要循环均为(1)→(2)→(1)。节点连边强度如表5所示,在循环(1)→(2)→(1)中,前80回与后40回的强度最大的连边均为(1)→(2)。前80回中双向重要循环的连边强度差占总连边强度的11.1%;后40回中双向重要循环之间的强度差占总强度之和的7.5%。
Table 5. State names and occurrence of bidirectional cycles of the first 80 and last 40 episodes
表5. 前80回和后40回中双向循环连边强度
在随机强化状态转移网络(图2(a3)~(b3))中,也存在连边强度很大的自连边现象、三角重要循环与双向重要循环。前80回随机强化状态转移网络中三角循环为(1)→(9)→(3)→(1),双向重要循环为(1)→(3)→(1);后40回中三角循环为(1)→(3)→(5)→(1),双向重要循环为(1)→(17)→(1)。分别对比前80回和后40回强化状态转移网络(图2(a2)~(b2))和随机强化状态转移网络(图2(a3)~(b3)),可以发现原序列随机重组后状态转移网络的拓扑结构变化较大,这是因为状态转移网络依赖于序列元素顺序而非序列元素分布。
2) 度分布
《红楼梦》前80回和后40回状态转移网络度分布也存在差别。如图3所示,将前80回和后40回二者进行比较:前80回中状态(1)的度远大于后40回的状态(1) (比值为0.81),而前80回中状态(2)和后40回的状态(2)的度相差极小(比值为0.91),比值差值占二者之和的5.8%。而前80回中状态(31)的度和后40回的状态(31)的差值较小(比值为0.81),前80回中状态(32)和后40回的状态(32)的度差值幅度增大(比值为0.61),比值差值占二者之和的14.1%。另外,一些被过滤掉的边以及度较小的节点也存在差别。
3) 模体的性质
图4(a1)~(b1)分别为《红楼梦》前80回和后40回原始序列与随机序列构成的网络的度分布;图4(a2)~(b2)分别为《红楼梦》前80回和后40回的节点度比值分布图,该比值为原始时间序列构成的网络节点度与随机打乱次序序列构成的网络节点度之比。根据模体的定义,可以从图4(a2)~(b2)中发现《红楼梦》前80回和后40回的主要模体,《红楼梦》前80回中与模体1 (motif1)、模体2 (motif2)、模体3 (motif3)、模体4 (motif4)相对应的状态为(32)、(1)、(16)、(31);后40回为(32)、(1)、(31)、(16)。可以发现状态(1)、(16)、(31)、(32)均作为模体出现在《红楼梦》前80回、后40回中,并且出现比率最高的均为状态(32)。不同之处在于前80 回中出现频率最低的为状态(31);后40回出现频率最低的为状态(16),详见图4(a2)~(b2))。

Figure 3. Normalized degree distribution of the state transition network for the first 80 and last 40 episodes when the window size
图3. 滑动窗口
时,前80回和后40回状态转移网络的度经过归一化后的分布结果
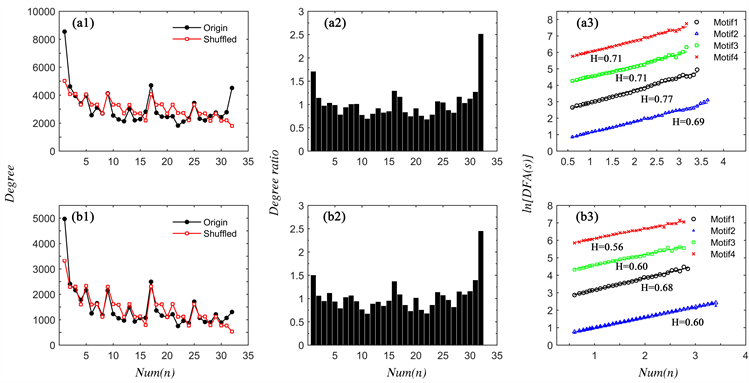
Figure 4. Degree, degree ratio, and scaling behaviors of the first 80 and last 40 episodes when the window size
图4. 滑动窗口
时,前80回和后40回的度分布、度比值分布、标度指数图
图4(a3)~(b3)分别为《红楼梦》前80回和后40回对应模体位置序列的标度指数。可以发现前80回与后40回的模体位置序列的标度指数存在一些差别。前80回对应模体标度指数均值为0.72,而后40回对应模体标度指数均值为0.61;对比四个模体,前80回对应标度指数普遍大于后40回,表明前80回的长程相关性与后40回相比普遍更强。
Table 6. Average scaling exponent of different text range when the window size s = 5
表6. 滑动窗口
时,不同文本范围对应模体标度指数均值
标度指数均值如表6所示。将《红楼梦》前、中、后40回进行比较,前40回与中40回对应标度指数均值接近,而后40回与二者相差较大,表明前、中40回的长程相关性与后40回相比均更强;同时,全文对应标度指数均值为0.71,比较后40回,进一步表明后40回与全文整体的偏离程度较大。
3.2. 滑动窗口s = 6
1) 状态转移网络
当滑动窗口
时,同样分析《红楼梦》前80回和后40回0-1序列,如图5所示:此时前80回与后40回的状态均有64种。在状态转移网络中,对比前80回和后40回强化状态转移网络中的循环(三角重要循环、双向重要循环),循环节点、循环方向也基本相同,前80回和40回三角循环中连边强度最小的均是状态(2)→(33)的连边,但前80回中连边强度最大的是状态(1)→(2)连边,后40回中连边强度最大的是状态(33)→(1)的连边。在双向重要循环中,前80回循环(1)→(3)的整体连边强度大于(3)→(1),而后40回则相反(前80回中双向重要循环的连边强度差占总连边强度的8.0%;后40回中双向重要循环之间的强度差占总强度之和的3.6%)。

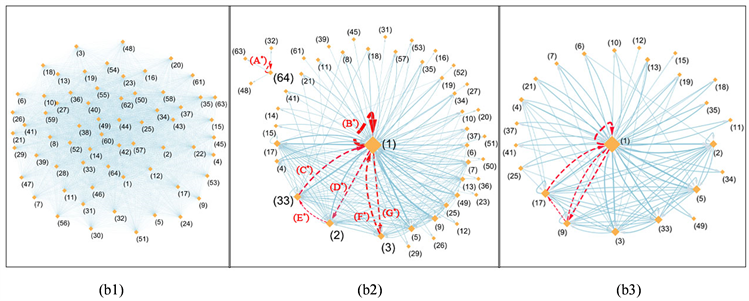
Figure 5. State transition network when the window size
. Red letter numbers and dashed lines represent the links with large weight. In (a2) and (b2), edges (A*) and (B*) represent self-links, the edge set (C*, D*, E*) represents the important triangular cycles and the edge set (E*, F*) represents the important bidirectional cycles
图5. 滑动窗口
时的状态转移网络。红色字母编号与短划线标注的为权重较大的连边。(a2)和(b2)中的边(A*)、(B*)代表自连边;边集合(C*, D*, E*)代表三角重要循环;边集合(E*, F*)代表双向重要循环
2) 度分布
滑动窗口
时,将前80回和后40回的归一化后的度分布进行比较,如图6所示:前80回中状态(1)的度远大于后40回的状态(1)(比值为0.80),而前80回中状态(2)和后40回的状态(2)的度差值幅度缩小(比值为0.86),比值差值占二者之和的3.54%。而前80回中状态(63)的度和后40回的状态(63)的差值较小(比值为0.64),前80回中状态(64)和后40回的状态(64)的度差值幅度增大(比值为0.59),比值差值占二者之和的4.3%。
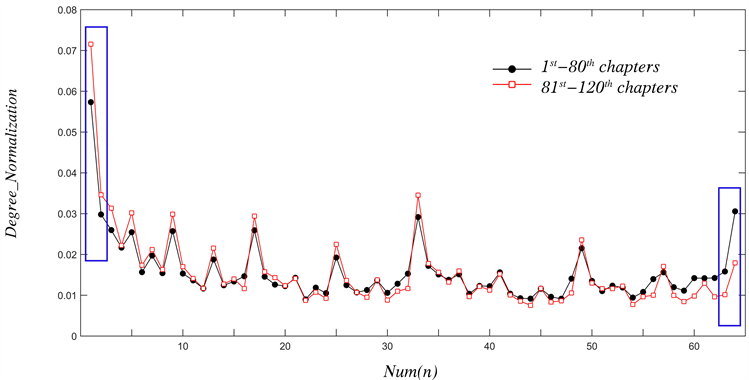
Figure 6. Normalized degree distribution of the state transition network for the first 80 and last 40 episodes when the window size
图6. 滑动窗口
时,前80回和后40回状态转移网络的度经过归一化后的分布结果
3) 模体的性质
从度比值分布图(图7(a2)~(b2))中可得到《红楼梦》前80 回和后40回主要模体。前80回模体对应状态为(64)、(1)、(63)、(32),而后40回模体对应状态为(64)、(1)、(32)、(48)。可以看出《红楼梦》前80回和后40回的差别与相同之处。相同之处在于前80回和后40回的模体中均出现第1种和第64种可见图结构;不同之处在于前 80回中另外两种模体分别为第63个和第32个可见图结构,后40回中另外两种模体为第32个和第48个状态。
从模体位置序列标度指数图(图7(a3)~(b3))中可发现《红楼梦》前80回与后40回的差异。《红楼梦》后40回(图7(c3))中对应模体的标度指数普遍小于前80回的标度指数。前80回对应模体标度指数均值为0.72,长程相关性较好;而后40回对应模体标度指数均值为0.56,标度指数较小,长程相关性较差。此外,前、中40回的标度指数均值分别为0.71、0.67,说明前、中40回的长程相关性比后40回更强;并且全文的标度指数均值为0.69,对比后40回,同样表明后40回与全文的偏离程度较大。
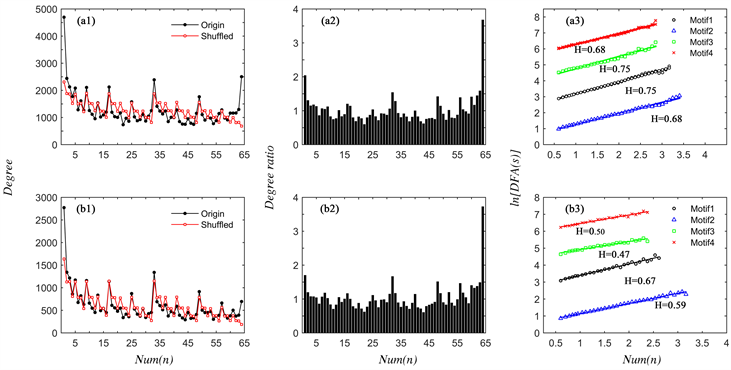
Figure 7. Degree, degree ratio, and scaling behaviors of the first 80 and last 40 episodes when the window size
图7. 滑动窗口
时,前80回和后40回的度分布、度比值分布、标度指数图
3.3. 不同窗口长度的结果对比
当滑动窗口
和
时,对比《红楼梦》前80回和后40回结果。无论滑动窗口的值取
或
,定性而言,强化状态转移网络的形状都基本相同。对比前80回和后40回强化状态转移网络中的循环(三角重要循环、双向重要循环),循环节点、循环方向也基本相同。但定量而言,《红楼梦》前80回和后40 回结果存在一些明显的差别。
从强化状态转移网络中的三角重要循环来看,当滑动窗口
时,前80回和后40回的三角循环中连边强度最小的均是(2)→(17)的连边,但前80回中连边强度最大的是(17)→(1)的连边,后40回中连边强度最大的是(1)→(2)的连边。当
时,前80回和40回的三角循环中连边强度最小的均为状态(2)→(33)的连边,但前80回中连边强度最大的是状态(1)→(2)连边,后40回中连边强度最大的是状态(33)→(1)的连边。重要循环中连边强度的不同表明了前80回与后40回的网络拓扑结构不同。
从模体结构以及模体位置序列标度指数层面看,前80回和后40回也存在一些明显差别。当
时,前80回的模体结构为状态(32)、(1)、(16)、(31);后40回模体结构为(32)、(1)、(31)、(16)。前80回模体位置序列标度指数均值为 0.71,后40回的均值为 0.61;当
时,前80回模体对应状态为(64)、(1)、(63)、(32),而后80回模体对应状态为(64)、(1)、(32)、(48)。前80回模体位置序列标度指数均值为 0.72,后40回的均值为0.56。即《红楼梦》前80回与后40回的模体结构有所区别,且后40回的标度指数普遍小于前80回的标度指数。
Table 7. Results of two-sample t test for the data of the first 80 and last 40 episodes
表7. 前80回和后40回的双样本t检验结果
本文对《红楼梦》中前80回和后40回的模体的位置序列标度指数进行双样本t检验,检验结果如表7所示。当
与
时,《红楼梦》中前80回和后40回的模体的位置序列的标度指数差异均显著(P < 0.05),即说明《红楼梦》的前80回和后40回的标度指数存在较为明显的差别。
4. 结论
本论文从文本语言的角度出发,选取的研究对象为《红楼梦》,通过将文本序列转化为复杂网络定量地研究了汉语文本语言,具体研究内容及结果如下:
利用状态转移网络方法将《红楼梦》前80回与后40回的文本依据各个汉字的出现频繁程度转换为全文0-1序列,并将其映射为状态转移网络来探究文本语言的写作风格及特征。通过分析状态转移网络的特征,得到《红楼梦》前80回和后40回中的相同点:1) 状态的度分布的形状基本相同;2) 强化状态转移网络中重要循环的节点、连边方向相同。相同点说明了文本语言的整体行文风格在一定的历史时期和社会环境下趋于一致。
《红楼梦》前80回与后40回对应的状态转移网络的不同之处:1) 重要循环连边强弱的差异;2) 模体对应状态的差异;3) 位置序列标度指数值的差异。结果表明:当时,前80回的四种模体的标度指数与后40回相比普遍高出0.10左右。不同之处表征了《红楼梦》前80回与后40回的语句特征以及结构的区别,语句特征和语句结构在很大程度上体现了不同作者的行文风格。
实验结果表明,《红楼梦》前80回和后40回的写作风格存在一定差异。目前暂无文献记载二人有直接联系(如:师徒关系),大多数学者认为《红楼梦》一书是由曹雪芹创作了前80回,之后十余年的时间里高鹗在曹雪芹前80回本的基础上续写了后40回 [24]。本论文从复杂网络层面探究了汉语言文本的行文风格与特征,在一定程度上为《红楼梦》的作者分歧提供了数据支撑与定量解释。