1. 引言
近年来,我国作为纺织生产和出口的第一大国,纺织工业正在高速地发展,并在国民经济中发挥着重要作用。但是,由于人眼的主观性和织物图片成像质量差,使得传统的人眼检测手工分类方法己不能满足高质量和高精度的服装生产要求。随着计算机技术的融入,标准织物的疵点分类方法主要分为两部分:织物特征提取和分类器设计。其中织物特征提取过程对瑕疵的检测分类影响力较大,它直接决定了提取的特征是否能够很好地描述该图像。因此,通过采取可靠且精准的织物图像特征提取技术对纹理复杂、差异较小的织物疵点图像进行处理,在纺织工业中具有很强的现实意义和研究价值 [1] [2] [3] [4]。
在织物疵点图像分类领域上,学习训练样本方法大致可分为机器学习法 [5] [6] [7] 和训练法 [8] [9]。本文研究基于字典学习的织物疵点分类方法属于训练法,该方法有出色的学习性能、明确的可解释性以及在有限的图像数据情况下依然具有较好的分类性能等优点,因此在图像分类领域取得了大量的应用与研究 [10] [11] [12]。最近,WU等 [13] 提出基于通用字典的局部机织物纹理稳定表征应用于织物图像分类中,但对于复杂纹理织物的疵点分类来说,目前提出的大部分字典学习模型只适用于简单、均匀纹理的织物图像,少部分的疵点分类方法也只能针对特定的纹理织物图像,对复杂纹理织物疵点图像的分类相对较少。这是由于复杂纹理的织物图像背景结构的复杂性、瑕疵信息的形态多样性、瑕疵信息的隐蔽性(瑕疵区域与背景纹理区域在颜色对比度上、结构上可分性较差),使得复杂纹理织物检测较难实现,因此针对复杂多样的织物纹理特征检测的字典学习方法仍然需要很大的改进空间。在字典学习方法改进上,Yang等 [14] 提出了费舍尔判别字典学习方法(Fisher discrimination dictionary learning, FDDL),该方法利用判别特征来构建字典,并将判别准则作用在编码向量上,以此来提高编码向量的鉴别能力,提高学习效果;Jiang [15] 等提出了基于类别标签一致的KSVD (Label consistent KSVD, LC-KSVD)的字典学习方法通过引入样本的类别标签信息提升稀疏表示系数判别性,间接提升字典的判别性能;Vu等 [16] 提出了面向判别性特征的字典学习(Discriminative Feature-oriented Dictionary Learning, DFDL)应用于组织病理图像中,主要强调的是抑制类内差异和类间模糊并有效地提取了组织图像特征。上述方法对提升字典的判别性能作出了较大贡献,在图像分类中取得了较好的效果。
在Vu等 [16] 提出的DFDL实验中表明,DFDL方法相比其他方法取得了更好的特征提取效果,在构建鉴别性字典上得到了很大的突破,强调抑制类内差异和类间模糊的思路十分合理且有效,于是本文受此启发,在面向织物图像特征上,对其进行研究。但由于组织图像与织物图像有差异,织物图像中存在大量的纹路信息,布匹的材料各异,相同类别的织物中纹路与材料结构变化较大,不同类别的织物中纹路与材料结构也存在一定的相似性,因此可能会导致不同织物之间的特征距离小于同类织物之间的特征距离。综上,在DFDL方法下所得到的正常织物字典与瑕疵织物字典可能较为相似,不能有效地判别正常织物样本与瑕疵织物样本。为了面向织物图像,提高织物特征字典的判别性以及分类性能,本文在抑制类内差异和类间模糊的面向判别性特征的字典(Discriminative Feature-oriented Dictionary Learning, DFDL)优势上结合对稀疏系数进行线性判别约束 [17] [18] (Linear Discriminant Analysis, LDA),提出了一种基于LDA的类别约束字典学习分类方法,并在阿里云天池布匹疵点检测数据集、工厂实时收集的织物数据集以及本文课题组采集的少量疵点织物图像中进行实验分类。
2. DFDL基础理论
2.1. DFDL基础理论介绍
假设有c类训练样本,将图像中的小块矢量化为列向量
,可以得到第i类的训练样本矩阵和互补样本矩阵
和
。
本文中
表示类i的字典,
表示训练样本Y在字典D分解得到的稀疏系数,其中
表示第i类训练样本Yi在字典D分解得到的稀疏系数,字典学习的主要优化方案是为了获得更好的字典
来更准确的表示训练样本数据。
2.2. DFDL方法
Vu等 [16] 提出了面向判别性特征的字典学习(DFDL)方法主要为了构建特定特征的字典Di,使得每类的字典都能更大程度的代表第i类样本,但不能表示其互补样本。具体而言,需要对字典学习:
越小越好,
越大越好。
式中:
为尺度因子;Ni为第i类样本特征个数;
为互补样本特征个数;
为稀疏系数的控制稀疏项;
表示Frobenius范数。
DFDL方法可以看出在字典学习过程中没有考虑样本间稀疏表示系数之间的差异,可能会使得正常字典和瑕疵字典之间的判别性较低,影响对织物图像的学习性能。
3. 基于LDA的类别约束字典学习织物疵点图像分类方法
为了设计针对织物疵点特征的分类性能更好的字典学习分类方法,本文改进常规的字典学习模型。在抑制类内差异和类间模糊的DFDL模型的优势上,结合对稀疏系数进行线性判别约束 [17] [18],建立具有织物判别特征的字典进行分类,提出基于LDA的类别约束字典学习织物疵点图像分类方法。以天池布匹疵点图为例,该方法的整体流程如图1所示。
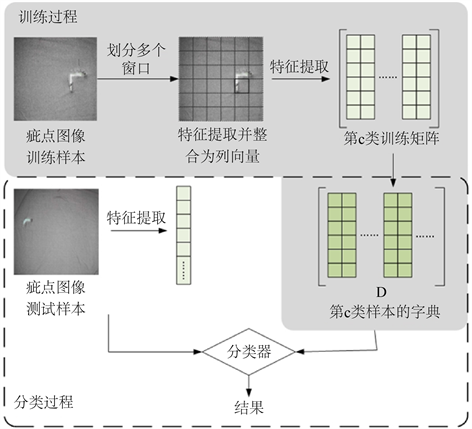
Figure 1. Flow chart of classification method of fabric defect images based on class constraint dictionary learning based on LDA
图1. 基于LDA的类别约束字典学习织物疵点图像分类方法流程图
3.1. 基于LDA的类别约束字典学习模型构建
在DFDL的基础上,引入线性判别分析 [17] [18] 的约束,使得同类样本在字典学习中分解的稀疏系数距离尽可能的接近,对应的是不同类分解的稀疏系数距离尽可能的远离,由此来增强字典的判别性。因此,首先定义新的类内散度矩阵Sw和类间散度矩阵Sb,由线性判别分析 [17] [18] 可知散度矩阵求的是协方差矩阵。由于协方差矩阵在运算过程中较为复杂,所以利用F-范数的平方代替协方差矩阵(F-范数的平方为协方差矩阵的迹)。因此,可设稀疏系数的协方差矩阵的迹为第i类的类内散度矩阵Sw,迹越大说明稀疏系数的离散程度距离越远。虽然新的Sw代替协方差矩阵忽略了其结构,但是更易于研究,类间散度矩阵Sb也是如此。
综上,所以只需要:
越小越好,
越大越好。
式中:
和
分别表示Si和S的均值向量(第i类稀疏系数的类中心和所有稀疏系数的类中心);Ni为第i类样本数量;
为样本的稀疏系数。
为了方便,以下开始仅考虑一个类,即使用Y,D,S,N代替Yi,Di,Si,Ni等。 基于上面的论点,可以定义新的目标函数:
(1)
式中:
为尺度因子;N为第i类样本特征个数;
为互补补样本特征个数;
为稀疏系数的控制稀疏项;
为互补样本的稀疏系数的控制稀疏项;
为第i类样本的稀疏系数;
为第i类互补样本的稀疏系数;
和
分别表示第i类稀疏系数的类中心以及所有稀疏系数的类中心;
为正则化参数;
、
为了权衡类别内差异和类别间差异;
为了解决非凸且不稳定的问题;
为常量为了权衡
和等式的关系。
3.2. 基于LDA的类别约束字典学习模型优化求解
由于该模型是凸函数,所以使用迭代方法来找到字典的最佳解决方案。迭代过程中通过在固定字典D的同时优化稀疏系数S和
来进行,然后通过固定稀疏系数S和
优化字典D,以此迭代求解。
在稀疏编码步骤中,可以通过下列式子来解决:
(2)
(3)
式(2)~(3)这两个稀疏编码问题相同只需对其中一个问题求解然后进行组合解决。
由于所有类中心是由每一类类中心得到的,所以类间散度矩阵推导得
,式中k为常
数。即可得
(4)
由
,
得
(5)
经上述讨论将稀疏系数最终目标函数简化为
(6)
(7)
从目标函数(7)可以看出,只要在实际应用中选择合适的参数,则目标函数的Hessian矩阵可以是半正定的,因此目标函数对于S是凸的。由此可以将其一阶导数设为零并获得解析解。令函数F(S),
(8)
其中第一项求和是字典学习的基本目标函数。这里,对S利用一个简单的2-范数约束编码矩阵求解,使得字典学习过程快速有效。
(9)
求导并设为零
最优解为
(10)
在更新字典D步骤中,需要优化以下目标函数
(11)
由
,可得到
;
。
将目标函数(11)更新为如下式子(12)
(12)
式中:
是
的最小特征值,矩阵
是半正定的,
所有特征值都是非负的,所以目标函数(12)是凸的。
本质上目标函数(12)与目标函数(11)相同,此类更新字典D问题 [19] 采用以下迭代,收敛得到学习字典
的最优解。
(13)
(14)
式中:
为第i类更新字典的第k列;
为矩阵
坐标
处的值;
表示矩阵
的第k列。基于LDA的类别约束字典学习的优化过程如算法1所示。
3.3. 织物图像分类器
对不同织物样本进行基于LDA的类别约束字典学习,得到各自的字典矩阵
与
,对测试样本分别进行稀疏表示,求出稀疏重构误差向量,求得分类统计量构建织物图像分类器实现织物图像的分类,具体步骤如下:
· 将测试图像分块,在测试图块中随机选取多个图块组成测试样本Z,通过
(15)
式中:ω是正则项参数。
利用SPAMS工具箱中的OMP [20] 算法求解式(15)在字典矩阵
与
下的稀疏编码系数和
和
。
· 计算测试样本稀疏重构误差向量,即
(16)
式中:
是测试样本在字典矩阵
稀疏重构误差向量;
是测试样本在字典矩阵
下稀疏重构误差向量;diag是矩阵对角矩阵。
· 计算分类统计量,即
(17)
式中:N是测试样本数;A是分类向量;B是分类统计量。
· 构建分类器,分类统计量B与测试样本最佳阈值对比,分类统计量B大于测试样本最佳阈值测试样本为正常样本,反之则为疵点样本。
4. 实验结果及分析
为验证本文方法在织物疵点图像的有效性,采用阿里天池布匹疵点检测数据集中的织物样本、工厂实时收集的织物疵点织物样本以及本文课题组采集的少量疵点织物样本进行实验,并与其他方法进行对比分析。实验均在Windows 10系统电脑上进行,电脑处理器Intel(R) Core(TM) i5-6500 CPU@3.20 Gi Hz,4 Gi内存,实验平台为Matlab R2020a。
4.1. 阿里天池数据集的实验结果及分析
在每个实验中,从训练样本中随机抽取10,000个40像素 × 40像素的小块,每类学习100个基础的字典。阿里天池布匹疵点检测数据集分为正常和瑕疵织物,尺寸为2560 × 1920像素,如图2所示为同一材质不同的正常织物与瑕疵织物各4张。每个类有500张,随机选择300张图片进行训练,剩下的用于测试。在此数据集中λ,λ2和ρ分别设置为0.01、0.001和0.001分类性能最优。(实验参数分析见第4.4节。)
 (a) 正常织物
(a) 正常织物 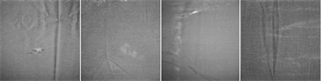 (b) 瑕疵织物
(b) 瑕疵织物
Figure 2. Tianchi cloth defect detection data set
图2. 天池布匹疵点检测数据集
在阿里天池布匹疵点数据集上应用本文提出的基于LDA的类别约束字典学习方法,与FDDL [14],DFDL [16],SRC [21] 和LC-KSVD [15] 进行分类性能比较,表1分别为不同字典学习方法下,天池布匹疵点数据集织物样本中分类的平均准确率以及平均运行时间(10次实验所取的平均值)。

Table 1. Classification accuracy and running time of Tianchi cloth defect dataset
表1. 天池布匹疵点数据集的分类准确率以及运行时间
由表1易得出本文方法与其他方法相比,在天池布匹疵点织物图像中分类准确率最高,而且训练时间都稳定地排在前列。需要注意的是,和DFDL方法相比,本文方法不仅分类准确率提升了约2.37%,而且运行时间仅仅是DFDL方法的十分之三。本文方法的训练时间远远不如SRC方法,但分类准确率提升约9.45%。综上,本文字典学习方法判别性更强,提取织物图像的特征更好,对天池布匹疵点数据集具有更好的分类效率和准确率。
4.2. 工厂实时收集的织物数据集的实验结果及分析
为进一步验证该方法对织物的适用性,本节将其应用于工厂实时收集的织物疵点数据集中,所有图像为640像素 × 640像素,如图3所示为同一材质不同的正常与瑕疵织物图像各4张。每个类各有100张,在正常和瑕疵的图像中各随机选取50张为训练样本,剩下的作为测试样本,每张图像提取200个小块,每块的尺寸为20像素 × 20像素,则正常与瑕疵样本分别为10,000个小块。
在此数据集中λ,λ2和ρ分别设为0.0001、0.0001和0.001分类性能最优。将本文方法与FDDL [14],DFDL [16],SRC [21] 和LC-KSVD [15] 在实时工厂数据集进行分类的平均准确率以及平均运行时间(10次实验所取的平均值)如表2所示。
 (a) 正常织物
(a) 正常织物  (b) 瑕疵织物
(b) 瑕疵织物
Figure 3. Real-time factory fabric defect detection dataset
图3. 实时工厂的织物疵点检测数据集
Table 2. Classification accuracy and running time of Tianchi cloth defect dataset
表2. 工厂实时收集的织物数据集的分类准确率以及运行时间
由表2易得出本文的方法与其他方法相比,在工厂实时收集的织物图像中分类准确率最高,而且训练时间都稳定地排在前列。综上,本文字典学习方法判别性更强,提取织物图像的特征更好,对实时工厂的织物疵点图像分类适用且高效。
4.3. 本文课题组采集的少量疵点织物图像的实验结果及分析
为验证当实际样本量较少时该方法对织物的适用性,本节将本文方法应用于本文课题组采集的织物图像数据集中如图4所示,所有图像为256像素 × 256像素,各有30张。
 (a) 黑线 (b) 阴影 (c) 裂缝
(a) 黑线 (b) 阴影 (c) 裂缝
Figure 4. A small number of defective fabric images collected by the research group
图4. 课题组采集的少量疵点织物图像
在黑线和阴影的织物疵点图像中分别随机选取5、10、15张图像作为训练样本,随机从训练样本中抽取10,000个20像素 × 20像素的图像小块。λ,λ2和ρ分别设为0.0001、0.0001和0.001,然后对剩下的疵点图片测试可得分类准确率分别为92.40%,95.00%,98.33%。(10次实验所取的平均值。)
在黑线和裂缝的织物疵点图像中分别随机选取5、10、15张图像作为训练样本,随机从中抽取10,000个20像素 × 20像素的图像小块。λ,λ2和ρ分别设为0.0001、0.0001和0.001,然后对剩下的疵点图片测试可得分类准确率分别为93.00%,96.00%,98.33%。(10次实验所取的平均值。)
由此可见,该学习方法的分类性能在不同数量的训练样本情况下都连续稳定,并且随着训练样本数量的增加,其分类准确率也在持续上升,表明该方法在不同情况下的织物疵点图像仍然具有实用性和较好的稳定性。
4.4. 实验参数分析
本文中参数ρ平衡学习字典的类内差异和类间模糊,参数ρ的设定参考了DFDL [13] 方法给出的经验值0.001。本文方法不同之处在于增加了稀疏系数约束项的惩罚因子λ和λ2。为了阐述惩罚因子λ和λ2对分类性能的影响,图5给出随参数λ和λ2变化时本文方法在不同织物图像的分类效果。由图看出天池布匹图像在λ = 0.01,λ2 = 0.001时分类效果最优,实时工厂图像在λ2 = 0.0001,λ = 0.0001时分类效果最优。
 (a) 参数λ和λ2对天池布匹图像分类效果的影响
(a) 参数λ和λ2对天池布匹图像分类效果的影响 (b) 参数λ和λ2对工厂实时收集的织物图像分类效果的影响
(b) 参数λ和λ2对工厂实时收集的织物图像分类效果的影响
Figure 5. The classification effect of this method on different fabric images when the parameters λ and λ2 change
图5. 参数λ和λ2变化时本文方法在不同织物图像的分类效果
5. 结论
基于字典学习的织物疵点分类方法存在不能有效提取织物特征字典问题,具体表现在得到的不同类的织物字典之间相似度高、判别性弱,不能有效地构造具有织物鉴别特征的字典用来分类。为了提高针对织物特征的字典学习方法的判别性以及分类性能,本文提出基于LDA的类别约束字典学习的织物疵点图像分类方法。通过施加稀疏性约束来使每个类具有判别性的字典,然后利用线性判别约束同类样本在字典学习中分解的稀疏系数距离尽可能地接近,不同类分解的稀疏系数距离尽可能地远离,增强了字典的判别性。因此,类中的任何样本都更能被关联字典表示,互补样本更不能被该字典表示,最大程度地减少类内差异和增强类间差异。同时,在类间的细微差异上鼓励在该类别中找到代表性的字典,使得较大的类间差异阻止一个类稀疏表示其他类的样本,获得了较好稀疏表示性能。最后,利用学习织物字典对测试样本进行稀疏表示得到的重构误差向量设计了分类方案,实现了织物图像的分类。在阿里天池布匹疵点检测数据集和实时工厂中的数据集上的实验结果表明,本文方法能有效提取织物图像的分类特征,与同类方法相比,具有更好的织物图像分类结果。
基金项目
国家自然科学基金(61601410);浙江省科技厅重点研发计划项目(2021C01047, 2022C01079);东北大学流程工业综合自动化国家重点实验室联合基金(2021-KF-21-03, 2021-KF-21-06)。
NOTES
*通讯作者。