1. 引言
近年来,城市拥堵愈发严重,给人们出行通勤都带来了不便,而电动车出行更加方便环保,价格低廉,符合一直以来大众所倡导的绿色生活理念。随着社会对电动车需求的不断增加,国内电动车保有量持续增长 [1],但随着电动车数量的增加,充电成为了新的问题。根据应急救援部公布的数据,自2021年1月至2021年7月,我国共发生6462起电动车引发的燃烧事故,而其中多数发生在其充电过程中,因此,如果事故发生时,电动车放置在室内、楼道等相对封闭的环境中,就容易引发重大伤亡事故 [2] [3]。目前,市面上针对电动车入户问题较为成熟的解决方案,即通过在电梯轿厢内部署电动车检测系统 [4] 来阻止电动车入户。市面上现有的产品中,选用的目标检测模型大多基于SSDMobileNet或YOLOv3进行训练 [5],使用树莓派或第三方定制的硬件设备进行部署。SSDMobileNet虽然解决了小型开发设备性能低的问题,但其即便是进行了优化,训练后的模型在识别率上仍不及YOLO-tiny系列。数据采集上,由于采用专用数据集和开源数据集进行训练,没有考虑到倒车及遮挡等问题,实际应用中的产品达不到其官方宣称的识别率标准。此外,由于硬件设备的问题,训练后的模型仅做了简单的部署应用,本质上仍在特定的深度学习框架下运行,并没有进行高性能推理。本文从数据集的选取入手,使用YOLOX-Nano训练模型,用支持TensorRT加速推理的JetsonNano设备。经实验,本文的系统设备能够更高效的识别各角度及各种遮盖情形下的电动车,通过该设备控制电梯,限制电动车进入,从而解决高层住户电动车入户充电的问题。
2. 相关技术
2.1. YOLOX目标检测网络
YOLOX目标检测网络于2021年由旷视科技发布。其BaseDetection团队总结近两年来目标检测领域各角度的优秀进展,将YOLO系列检测器调整为了Anchor-Free的形式并集成了如解耦头、标签分配、数据增广等技术,使得其性能取得了大幅地提升。研发团队基于YOLOv3-SPP,即DarkNet53骨干和空间金字塔池化(Spatial Pyramid Pooling, SPP),增加了指数加权平均、余弦退火学习率,IoU Loss和IoU-aware分支。另外,YOLOX使用BCE Loss来训练Cls.和Obj.分支,其中Reg.分支使用了IoU Loss。YOLOX的数据增强使用了马赛克(Mosaic)、随机水平翻转(Random Horizontal Flip)、颜色抖动(ColorJitter)和多尺度,随机大小裁剪(Random Resized Crop)因为同马赛克增强有部分重复所以被去除 [6]。
YOLOX网络相比于YOLO系列网络最大的改进点是解耦头(Decoupled head)。一直以来,分类与回归任务的冲突都是在目标检测中常见的问题,YOLO系列的工作也都是使用一个branch就同时完成Obj.、Cls.及Reg.三部分的预测。研发团队在实验中发现检测头耦合会对模型性能产生负面影响,所以YOLOX中采用了轻量解耦头替换YOLO系列惯用的检测头,从而显著改善模型的收敛速度,同时轻量的解耦头可以带来更短的推理耗时。YOLOX解耦头与YOLOv3-v5的头部区别如图1所示。
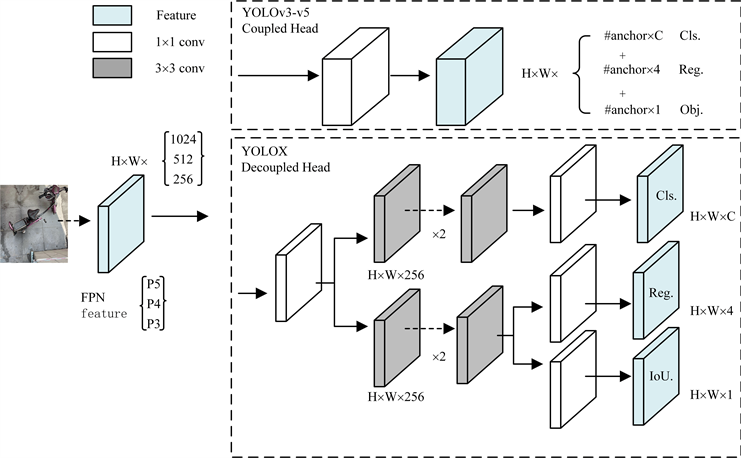
Figure 1. The difference between decoupled head and YOLO head
图1. YOLOX解耦头与传统YOLO头部的区别
2.2. TensorRT加速推理
训练对于深度学习来说是为了获得一个高性能的模型,而深度学习模型在训练阶段,为了能够保证前后向的传播,每次梯度都会进行极小的更新,此时则需要相对较高的进度,像如FP32这样的Float类型。但在推断时,由于没有了训练过程中的反向迭代,因此只需要向前计算即可。由此,在推理阶段即便使用了像如FP16或INT8甚至更低精度的技术仍不会对其推理结果有大的精度损失 [7] [8],也就是说,推理更关注的是低响应时间、低资源消耗、高吞吐量以及方便的部署流程 [9]。TensorRT就是为了解决推理及部署问题提出的,它是由C++、CUDA、Python三种语言编写的一个库,能够促进对英伟达GPU的高性能推理。TensorRT的原理就是通过优化内核选择和组合层来优化网络,以改善延迟、电源效率、吞吐量和内存消耗等问题。此外,为了能够让模型在英伟达GPU上更好的加速运行,英伟达还对TensorRT还做了相应的提速优化:如算子融合、量化、内核自动调整、动态张量显存和多流执行。TensorRT加速推理示意图如图2所示:
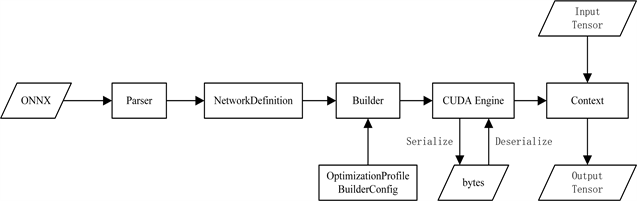
Figure 2. The diagram of TensorRT accelerated inference
图2. TensorRT加速推理流程图
此外,TensorRT在英伟达的支持下不断更新,目前已经支持开放式神经网络交换(Open Neural Network Exchange, ONNX)、Caffe、Uff等类型的解析模型,其中对ONNX路线的支持最好 [10]。ONNX是微软和Facebook合作开发的开放式神经网络交换工具,能够更好的对模型移植部署,在其他框架上进行推理。TensorRT提供了C++和Python接口、深度定制的ONNX解析器和低耦合封装技术,这些都能更好的结合YOLOX等模型进行部署。
2.3. DeepStream SDK
DeepStream SDK是基于英伟达硬件运行的工具,它参考了GStreamer来构建,由一系列插件构成,主要应用于整个视觉流程的解决方案,同OpenCV等视觉库不同,DeepStream建立了一套完整的端到端支持方案,包含视频编解码、TensorRT推理引擎、OpenCV跟踪器以及显示渲染插件等 [11] [12]。DeepStream代码框架示意图如图3所示:
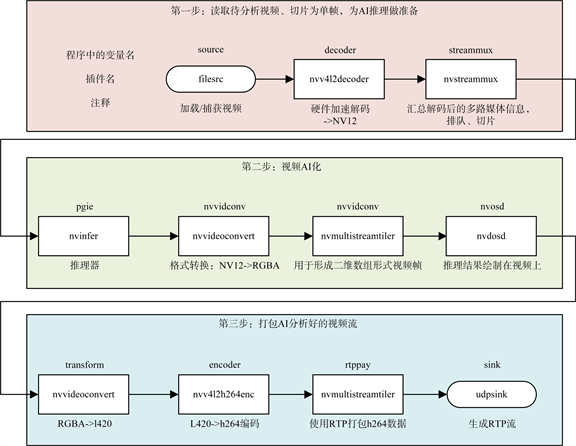
Figure 3. The diagram of DeepStream code framework
图3. DeepStream代码框架示意图
其中nvinfer是核心部分,其内部自带TensorRT INT8/FP16加速功能,是TensorRT的推理插件,理论上只要硬件支持就不需要进行额外的操作,具有更好的兼容性。
2.4. JetsonNano 2GB开发套件
JetsonNano 2GB Developer Kit是英伟达公司在2020年GPU技术大会(GPU Technology Conference, GTC)上发布的全新产品,区别于之前标准版的JetsonNano,内存由标准版的4 GB缩小为2 GB,从B01版本的双CSI相机支持变为单CSI相机接口,优化了散热布局和接口类型,缩小了硬件尺寸。售价上降低了40%,仅为59美元,这也间接降低了产品成本。同时,其核心的GPU没有缩水,仍为128核心麦克斯韦架构,计算能力达到5.3,支持CUDA和TensorRT [13],这颗GPU内核融合了FP16从而提高了性能和能效。低成本高性能也使得它更适合用于小型人工智能设备的研发。
软件支持上,基于Ubuntu 18.04定制的JetPack 4.5.1自带TensorRT 7.1.3,包括对混合精度推理的支持、量化模型的支持、布尔值的张量和空张量等。
3. 电梯内电动车检测系统框架
结合上述技术,本文设计的基于TensorRT加速推理的电梯内电动车检测系统设计流程如图4所示:
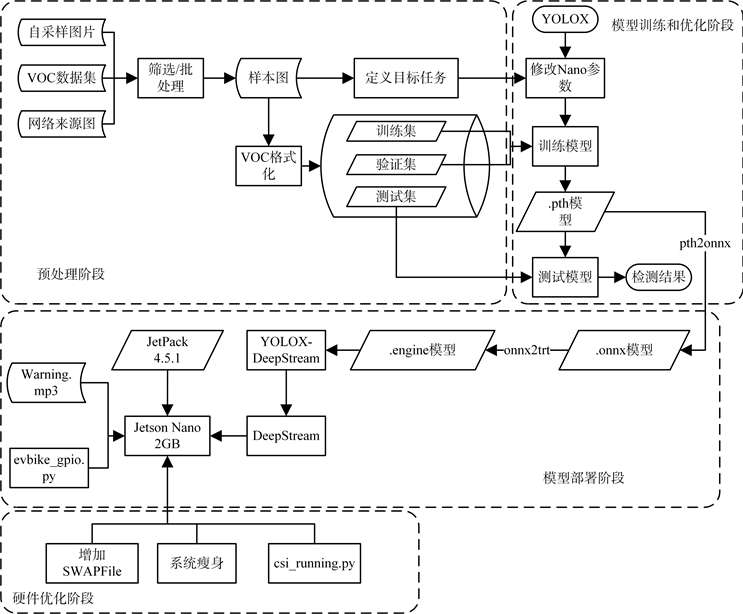
Figure 4. The diagram of DeepStream code framework
图4. DeepStream代码框架示意图
该设计分为四个阶段:预处理阶段,模型的训练阶段,模型部署阶段以及硬件优化阶段。
3.1. 预处理阶段
选定YOLOX网络结构,定义目标任务为电动自行车、电动摩托车和自行车,准备样本图像并按需求对样本图像进行预处理,然后对样本图像进行VOC格式化,得到VOC数据集。然后,将数据按照7:1:2的比例划分为训练集、验证集和测试集三部分。
关于数据集的制作,目标样本图像有三个来源:自行采集、VOC2012数据集(自行车)和网络图片。
3.1.1. 样本图像自行采集
针对自行采集的样本,选定的采集地点分为室内和室外场景,室内场景包括停车场、楼道、电梯以及模拟电梯场景;室外场景选定城市街道及露天停车场。在拍摄光线的选择上,室内场景选择白天及有昏暗灯光的夜晚,室外场景选择天气晴朗光线较弱的下午及路灯开启的夜晚。
在横向对比了市面上数款产品后,本文总结了其在目标检测中错误识别的情况(倒车进入电梯轿厢或衣物等其他物体遮挡大部分目标),为了更好的应用于训练及电梯内场景的应用,本文分别模拟了上述不同情况的目标状态,即包裹有雨衣的非机动车、装有防风棉衣的电动车以及载物状态下的电动车。同时,根据电梯内住户与电动车同框的情形,本文还分别采集了住户骑在非机动车上与住户站在非机动车旁造成遮挡情况的目标图像。此外,为了能够更充分地训练,本文还进行了针对目标的多角度拍摄及多数量拍摄(考虑到电梯内的空间,多数量情况下图像内的有效目标最多不超过3个)。整理完成后的样本如图5所示:
3.1.2. 样本图像自行采集
下载VOC2012开源数据集,对数据集中的图像进行筛选,选出所有包含自行车目标的样本图像,利用python脚本筛选与样本图像同名的标签文件。使用labelme标注工具将筛选后样本图片中的其他类型标签删除。利用python的xml树工具编写脚本,批量修改标签文件的路径,方便后续使用。
3.1.3. 图像样本网络爬取
电商平台的买家评论区跟商品详情中有训练所需的图片,通过爬虫技术爬取各大电商平台的图片,其中搜索关键词为电动车、电动自行车、电动摩托车、自行车。此部分的样本图像来源不可控,存在图片重复、不相关内容和图片质量差等问题,需要按照训练所需的样本需求进行人工筛选。
3.1.4. 数据集制作
将人工采集的样本图像和网络图像进行整合、筛选,结合VOC数据集中的自行车样本图,各类目标样本的数量按1:1:1的比例进行整合。
本文使用ACDSee2018 Pro工具将上述筛选后的样本中人工采集图像和网络爬取的样本图像按照VOC2007数据集的标准,即宽、高最大500像素,水平和垂直分辨率96 dpi,位深24 bit进行等比例压缩,随后打乱顺序重新编号,使用labelme工具进行标注,制成VOC数据集。
最终本文制作的样本数据集包括:12,000张jpg图像,12,000个xml标签,18,536个回归框,其中包括电动自行车、电动摩托车、自行车样本各4000张。三类目标样本数据集的分配情况如表1所示:
3.2. 模型训练阶段
本文主要针对电动自行车、电动摩托车和自行车三类目标进行分类检测,对于目标模型训练在CPU为AMD (R) Ryzen(R) R5-3600 CPU @ 3.60 GHz,内存为32.0 GB DDR4-3600 MHz,显卡为NVIDIA TITAN Xp的电脑上进行,机器配置了Pytorch框架,通过GPU进行训练。由于训练好的目标模型最终需要部署在JetsonNano 2 GB这样的小算力设备上,因此选用YOLOX系列最小结构的YOLOX-Nano,其网络参数量只有0.91 M和1.08 G FLOPs,但却有着比YOLOv3-Tiny、YOLOv4-Tiny等更加优秀的性能。学习率上,使用SGD、nesterov和momentum的优化器及学习率调节器,学习率如公式(1)所示。
(1)
其中lr为学习率,batch_size为一次训练抓取的样本数。学习率初始值为0.01,之后采用带有warmup策略的余弦退火学习率,权重衰减系数为0.0005,并且在最后的15个epoch采用固定的最小学习率以配合数据增强。训练的batchsize为16,epcoh为320。
3.3. 模型部署阶段
上一阶段中,在Pytorch框架下训练得到了.pth格式的目标检测模型,在部署阶段,需要将该模型转化为能被TensorRT使用的.engine模型。
首先为JetsonNano烧入2 GB版的JetPack 4.5.1系统,第一次进入系统后需更新系统组件,安装并更新pip3等相应的功能以及protobuf等支持DeepStream和TensorRT运行的工具库,然后激活系统内自带的GPIO文件和TensorRT文件。录制一段提示音频用于提示用户电动车不允许进入电梯,音频存为.mp3格式。JetPack 4.5.1内置了DeepStream开发工具,本文参考DeepStream文件中自带的YOLOv3-Tiny文件,增加了可用于部署YOLOX的YOLOX-DeepStream。将转换为.engine格式的模型命名为evbike.engine,将该模型文件放入YOLOX-DeepStream中。
本文通过一个Python脚本调用GPIO的11引脚,在CSI相机检测到电动摩托车或电动自行车后上拉一个高电平控制电梯,使得用户不能使用电梯按钮进行关门操作,此时播放提示音频提示用户将电动车驶离电梯,当相机检测不到电梯内存在电动车后,下拉低电平恢复电梯正常运行。基于TensorRT加速的电梯内电动车检测设备工作流程如图6所示:
3.4. 硬件优化阶段
由于Jetson Nano 2 GB版本仅有2 GB内存,故需要增加SWAPFile虚拟内存以获得更好性能。本文针对项目实际的使用情况,对JetPack 4.5.1系统进行瘦身,移除了包括libre-office在内的软件及其他多余的相关依赖。此外,本文修改了开机启动选项,使检测程序能够在开机后自动运行,同时增加一个监测脚本在后台监测目标检测程序的运行状态,一旦发生崩溃或关闭现象,立即重启系统。
4. 实验仿真及结果分析
4.1. 测试数据及实验环境
本文为了实际工程应用的需要,进行了两部分测试,分别为部分样本图片的测试和电梯轿厢内采集的视频影像测试。本文重新选取测试样本,针对经过TensorRT加速推理的YOLOX-Nano模型、未经过TensorRT加速推理的YOLOX-Nano模型、未经过TensorRT加速推理的YOLOv4-Tiny模型和未经过TensorRT加速推理的SSDMobileNet模型进行了横向对比测试。
本次实验测试在CPU为四核ARM® A57 @ 1.43 GHz,GPU为128核NVIDIA Maxwell架构,算力为5.3,内存为2 GB共用显存的JetsonNano 2 GB设备上,系统环境为基于Ubuntu 18.04深度定制的JetPack 4.5.1。样本一选取了测试集样本中的600张图片,样本二则是选取了电梯轿厢内的三段监控视频录像,录像规格为720 p 30 fps,视频码率为2500 kbps,视频编码为h.264,视频时长50秒。
4.2. 实验结果评估及结论
针对本章节描述的两部分样本测试的效果图如图7所示:
本文使用mAP (mean Average Precision)对结果进行评估,mAP是目标检测常用的精度评估指标,通过计算每个分类的AP (Average Precision)再求平均得到,AP是各类目标的检测精度,由P-R (Precision-Recall)曲线积分得到,Precision计算如公式(2)所示:
(2)
式中TP (True Positive)为模型预测为正类的正样本,FP (False Positive)为模型预测为正类的负样本。Recall计算如公式(3)所示:
(3)
式中FN (False Negative)为模型预测为负类的正样本。根据上述计算得到测试结果如表2所示:

Table 2. Object detection results of the four models
表2. 四种模型的目标检测结果对比
分析本次测试结果,可以得出,在针对小型开发设备性能优秀的YOLOX-Nano模型基础上,经过TensorRT加速推理得到了更快的推理速度,模型性能进一步提升。实验证明,本文采用的基于TensorRT加速推理的电梯内电动车识别系统有着高效的目标检测效率,且相比于市面上的其他产品,识别速度更快,准确率更高。此外,经过TensorRT加速推理的YOLOX模型,虽然在部署阶段不可避免地需要进行格式转换,且在由.pth到.onnx再到.engine转换的过程中,精度有所损失,但在精度损失较小的情况下换来更快的推理速度是现阶段的最优选择。
5. 结论
本文总结市面上其他产品的检测缺陷,分类上将电动车细分为电动自行车与电动摩托车,细化了两个目标之间的特征以及两目标与自行车之间的特征。在图像预处理阶段,本文分析实际应用中遭遇的特殊情况,优化了数据集的采集和配比。在神经网络的选择上,本文选用YOLOX网络训练YOLOX-Nano模型,模型性能高于市面其他产品所使用的网络模型。在硬件选择上,本文选用了支持加速推理的JetsonNano开发套件,其2 GB版本在优化和支持完善的情况下也降低了成本。同时,本文针对JetsonNano 2 GB设备进行系统瘦身及优化,增加了虚拟内存,删除了除支持目标检测系统运行及后期系统维护的所有软件依赖。在DeepStream 5.1的基础上编写YOLOX-DeepStream,成功将目标模型、CSI摄像头、GPIO和TensorRT关联起来,经过TensorRT技术加速推理后的目标检测模型以极小的精度损失换来了更快的推理速度。
本文设计的检测设备局限于JetsonNano 2 GB设备的性能,在检测到电动车目标后通过Python脚本调用GPIO接口时,由于相继调用Python脚本与GPIO带来的瞬时系统负载,稳定在30 fps的帧率会出现1~2 s的丢帧现象,因此,在后续的产品优化上需要使用C++代替Python脚本,针对YOLOX-DeepStream进行进一步修改,将GPIO与音频的调用统一封装至DeepStream中。此外,设备在加密与防破解上仍有一定的漏洞,后续优化需为设备部署更好的软硬件加密方式。