1. 引言
葡萄一直是我国人民最喜爱的水果之一,其食用方式涵盖鲜食、制酒、榨汁、果干等,其中鲜食比例高达80% [1]。对于鲜食葡萄而言,风味是影响消费者选购的最重要因素。随着农业育种技术及栽培技术的迅速发展 [2] [3],人们愈加关注葡萄的风味及品质 [4],因此研究消费者对葡萄风味喜爱偏好对葡萄产品的选育及种植有极为重要的意义。
以往的研究者多基于葡萄理化性质之间的关系,采用主成分分析、聚类分析等统计学方法进行分析,这些方法着重于研究葡萄数据之间的相关性及差异性,但忽略了消费者对葡萄的主观偏好因素 [5] [6] [7],事实上鲜食葡萄的风味评价更应当结合消费者的主观偏好。同时,这些方法简单地认为可溶性固形物、总酸等因子与品质呈正负相关,专注于鲜食葡萄中可溶性固形物及总酸的研究 [8],忽视了糖和酸之间的交互影响。然而毛岳忠等进行了深入量化研究,证实了糖和酸含量差异对感官味觉具有明显交互影响 [9]。
机器学习是一种多领域交叉学科,在农业等领域应用较多。目前将机器学习模型应用于葡萄相关领域,如葡萄酒品质评价已有相应的研究工作。曾祥燕 [10] 及刘颖 [11] 等人分别将BP神经网络和RBF神经网络应用于葡萄酒的评价分析。Trivedi A等人使用随机森林模型与逻辑回归模型对葡萄酒品质预测 [12]。Aich S等人使用SVM对葡萄酒的品质进行分类预测 [13]。
本文结合主观与客观数据,面向市面上最常见的六种葡萄,针对最能代表风味的六个指标 [14] [15] 检测数据,利用人工品评的方法来获得葡萄样品的主观评价数据,在此基础上使用融合注意力机制的深度神经网络来展示指标变化对葡萄风味偏好的影响。
2. 数据采集
本文问卷参数如表1所示:

Table 1. The parameters of questionnaire
表1. 调查问卷参数
对问卷数据进行分析,口味偏好结果如图1所示。
选取2021年6月份刚刚上市的葡萄,主要有巨玫瑰、阳光玫瑰、巨峰、夏黑、醉金香、金手指。从农贸市场进货的果园订购后,放入23℃恒温保鲜室保存12 h,洗净后,筛选出外表光滑,颗粒饱满的果实,去皮、榨汁、过滤后作为备选样本。
Table 2. Test method for physical and chemical properties
表2. 理化性质检测方法
对上述六种葡萄进行试验,按照表2所示方法测定其理化性质,根据GB/T 10220-2012《感官分析方法学总论》采用直接打分来表征对风味的影响。根据GB/T 14195《感官分析选拔与培训感官分析优选评价员导则》对本院师生(年龄位于21~45周岁)进行感官培训,筛选出12位具有正常味觉辨识能力及描述和表达感官反应能力的品评人员,身体健康且在品评前一天未曾饮酒,并向其介绍品评标准及分数区间含义,如表3所示:
Table 3. Semantic description of scoring criteria
表3. 评分标准语义描述
3. 模型结构
本文采用深度神经网络将表2所示理化性质作为输入参数,得分结果作为输出参数 [17],使用注意力机制聚焦重要指标,以均方误差(RMSE)作为损失函数,构建葡萄评价模型。模型结构如图2所示:
本模型结构分为3大部分:1) 数据处理层:对理化性质及其对应的品评得分进行数据处理,经由多层感知机特征提取以增加模型的非线性表达能力;2) 注意力层:将数据处理层提取的特征通过注意力机制训练出各特征的权重,再与特征进行相乘;3) 预测输出层:将注意力层的输出结果送入多层感知机,最终得到模型的预测得分。
深度神经网络(Deep Neural Network, DNN)是一种多层神经网络,分为输入层、隐藏层、输出层。其每一层包含一个或多个神经元,相邻层的神经元进行全连接从而构成整个深度神经网络,广泛应用于结果预测 [18]。输入层参数X、输出层参数Y表示如下:
(3-1)
(3-2)
其中
到
分别为第 组的输入向量,即表2所示6个理化指标,m指输入样本数,
是第i组的输出结果。
利用深度神经网络解决非线性问题的核心就在于使用激活函数模拟人脑机制将神经元的特征激活然后保留关键特征并映射到下一层的输入 [19]。相比于Sigmoid等激活函数,ReLU函数具有计算简单,效率高且收敛速度快的优点,能够有效地解决激活函数的梯度消失问题,同时更加符合人脑神经激活机制 [20],其表达式如下:
(3-3)
从表达式不难看出,ReLU由于非负区间的梯度为常数,因此不存在梯度消失问题,使得模型的收敛速度维持在一个稳定状态。
注意力机制(Attention Mechanism)是在机器学习中用来自动学习和计算输入数据对输出数据的贡献大小,一般可以视作输入特征的权重。如人类视觉在看到一幅图片时,往往首先聚焦于某些重点区域,忽略掉其他非重点信息 [21]。根据问卷结果,消费者对口味和香味的重视程度有一定的差别,使用注意力机制可以使模型有效的获得所在列中特征的重要因子,有助于特征反馈,使在反向传播计算时只会在梯度最大的特征处进行反馈,使得模型收敛的更快,有效改善了模型的预测性能,其结构如图3所示。

Figure 3. The structure of attention mechanism
图3. 注意力结构
我们采用单层全连接网络实现注意力机制,其表达式如下:
(3-4)
其中
是注意力分数,
是Sigmoid激活函数,
是全连接层权重,b是全连接层偏置项,
和
分别是最大池化函数和平均池化函数,
是输入向量。
均方根误差(root mean square error, RMSE)可以很好的展示实测值和预测值之间误差的方法,能够表示所有区间内的预测误差,是深度学习中最有效的损失函数之一,其表达式如下:
(3-5)
其中
是第i个预测值,
是对应的实际值,m是测试集样本数量。
选取数据总量的80%作为训练集,剩余数据作为测试集。将表2所示作为输入层,品评得分作为输出层,其表达式如下:
(3-6)
其中
是ReLU激活函数,
和
分别是第i个隐藏层的权重以及偏移值,z是初始输入向量。
4. 实验部分
鉴于神经网络、支持向量机、随机森林等方法在葡萄酒品质预测上的良好表现 [11] [12] [13] [14],我们在上述输入输出数据的情况下,进行3组对照试验,分别为支持向量机(SVM)、随机森林(RF)以及未使用注意力机制的DNN,实验环境如表4所示。
5. 实验结果
为证明本文模型优于传统DNN模型,本文与DNN模型进行对照实验,实验结果如图4所示。可以看出本文模型在收敛速度及损失函数大小上均优于DNN模型,RMSE最终稳定在3.0,表明模型预测得分与实际得分平均分差为3.0分。
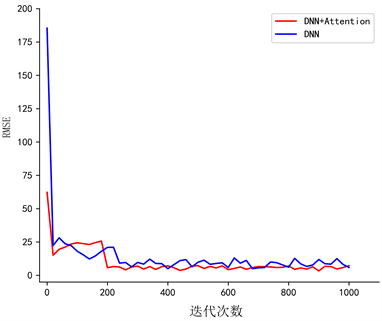
Figure 4. RMSE changes with the number of iterations
图4. RMSE随迭代次数的变化
根据表3设定的打分标准,我们将样品的等级设置为5个等级,每个等级间距为20分,因此设定预测得分和实际得分位于同一等级为正确预测,反之为错误预测。
本文对比SVM、RF等分类模型,实验结果如表5所示,结果表明本文模型准确率相较其他分类模型,准确率提升了9%~15%。
6. 结论与展望
本文采用在不同种葡萄取汁的基础上,检测其理化性质含量,并使用经过专业训练的品评人员打分作为风味偏好的唯一结果。基于此,本文使用融合注意力机制的深度神经网络进行训练,以理化性质含量为输入参数,品评人员打分为输出参数构建葡萄风味评价模型。
结论如下:RMSE稳定在3.0说明模型的预测得分与实际得分的平均差值为3.0分;划分五个等级区间,准确率达到92.6%;与对照组的模型对比,我们模型的准确度优于其他对照组模型。本文提出的融合注意力机制的DNN风味评价模型,不仅可以为葡萄育种及栽培研究提供方向及理论依据,而且为正确定位葡萄最适采摘时机提供参考。
葡萄风味评价模型的构建涉及多方面的理论与方法,本文提出的模型基于6种葡萄的6个指标,在葡萄品种和指标数量方面还有扩充的余地,进而使模型更加精准全面地表征葡萄风味。同时随着机器学习的不断发展,有望未来涌现出更好的算法来使模型预测结果的拟合度更高。
基金项目
现代农业产业技术体系建设专项资金(CARS-29)。
NOTES
*通讯作者。