1. 引言
如今,心肌病 [1] 的发病率日益增长,严重的心肌病会引起心血管性死亡或心力衰竭,据统计,2015年有1770万人死于心血管疾病,占全球死亡人数的31%。而心肌病往往是全身疾病的一部分,不同的心肌病与其他全身疾病之间有着紧密的联系。2018年,Gupta [2] 等概括了心肌病会引起内分泌疾病。2019年,Zapolski [3] 等提出了尿毒症患者肾移植后,心肌功能得到了改善,从而进一步缓解尿毒症。因此,研究不同类型的心肌病纤维化模式,不仅可以用来诊断原发性心肌病,而且对于其他全身疾病的术前治疗与术后康复具有重要意义。CMR可根据需要显示人体任意角度的层体图像,具有高分辨率,在诊断心肌纤维化模式方面,是无创性评估心脏结构与功能的“金标准”,在临床上被广泛使用。
随着CMR技术的发展,通过对心脏MR图像进行分析来辅助医生进行心肌病的诊断已在临床上得到了广泛的应用,也是当前医学图像分析领域的热门研究课题之一。Baessler [4] 等证明了T1加权的心脏MR成像可以用来观察肥厚型心肌病(HCM)患者心肌的改变。Shao [5] 等证明了T1加权的心脏MR成像可以用来区分扩张型心肌病(DCM)与正常心肌。这表明心脏核磁共振图像中,存在着一些潜在的纹理特征可以用来纤维化模式的诊断。
潜在纹理特征的挖掘依靠纹理描述方式的改进以及合理的特征选择方式,两者都至关重要。多角度的纹理描述方式会提供更多有效的纹理信息,但随着纹理描述方式的改进,特征维数会不断增加,特征之间的关系更加复杂,冗余特征也会随之增加,一味的累计特征维数并不会提高分类精度,反而因为样本数量远小于特征维数,引起维数灾难 [6],使得识别精度下降。因此,如何从大量的特征中选取最优的特征子集,即特征选择,一方面可以减少计算成本,提高心肌病的分类精度,另一方面可以更有力地验证某种新加入的纹理特征是否具有额外的价值。
ReliefF算法 [7] 作为一种以距离为度量的过滤式特征选择方法,在各个领域都得到了很好的应用。传统RelieF算法虽然可以解决多分类的特征选择问题,但在面对带有噪音的数据集时,往往特征权重的计算并不准确。同时作为过滤式的特征选择方法,ReliefF算法也存在冗余特征无法剔除、特征相互关系无法判断的问题 [8]。蚁群优化(ACO)是Dorigo [9] 等人提出的一种演化算法。蚂蚁之间的通信会产生正反馈行为,以信息素为媒介引导蚁群收敛到最优解。Nemati [10] 等人提出了使用蚁群算法(ACO)进行特征选择,主要思想是通过某种搜索策略和信息素更新策略来优化蚂蚁路径,从而一步步缩小搜索范围并找到最优特征。Ding [11] 等人使用F-srore,提出了ACOFS标准作为启发式,重新规定了更新策略,相比于ReliefF算法,这种通过蚁群优化来进行特征选择的方式在识别精度方面取得了不错的效果,但是作为一种包裹式的特征选择方法,由于初始蚂蚁分布的随机性,收敛效果并不好,而且容易陷入局部最优。
近年来,包括灰度共生矩阵(GLCM)在内的传统纹理描述算法在模式识别方面得到了广泛的认可。Raju [12] 等人在GLCM的基础上提出了模糊c均值分割算法,在超声肾图像上进行了肿瘤和肾囊肿的分类。El-Rewaidy [13] 等在一个独立数据集上,通过GLCM等算法提取了心脏MR图像的纹理特征,通过支持向量机(SVM)进行HCM、DCM与正常心肌的分类,在测试集上准确率达到了89%。但是,由于GLCM算法在进行灰度级的压缩时限定了压缩方向,图像的纹理信息将更多集中在限定方向,对于一些纹理信息偏向于弧形的图像而言,GLCM算法会忽视掉一些关键的纹理特征。
通过对心脏MR图像的观察研究发现,正常心肌细胞呈环状,以串联的方式形成圆环,各个环之间又以并联的形式构成心肌。HCM患者的心肌纤维化通常呈区域性,分布不均匀;DCM患者的心肌纤维化通常呈全局性,扩散式分布 [14]。因此,环方向上可能存在一些具有额外价值的纹理特征。本文首先将原始的心脏MR图像进行了内接矩阵化操作,以用来更好的发掘环方向上的潜在特征。然后通过GLCM在内的四种纹理描述方式,分别对重构后的图像和原始的心脏MR图像进行了特征提取,总共获取了422个纹理特征。与此同时,为了保证在众多的纹理特征中选取最优特征子集,本文提出了一种集成式的特征选择方法并在4个公开的基因数据集上进行了算法可靠性的验证,改进ReliefF算法,在样本点到K近邻点距离的基础上引进动态平衡系数,降低了噪音数据的干扰,从而得到每一个特征更加准确的权重,这些权重将用作之后蚁群算法的改进参数;改进蚁群算法,以特征权重和皮尔逊相关系数为基础制定搜索策略,以识别精度和特征子集长度为基础制定信息素更新策略,大大的减少了计算量的情况下,避免了算法陷入局部最优。最终,经过特征选择的6个纹理特征用于三种心肌纤维化模式(正常、HCM、DCM)的识别,并在测试集上取得了93.8%的准确率。
本文提出了一种新型的特征选择算法,在较短的时间内大幅度降低特征维数,提高了识别精度。同时证明了心肌环方向上的纹理特征为心肌纤维化模式的识别提供了额外价值的信息。
2. 方法
本文提出的方法主要包括以下四个步骤:
1) 以线性插值的方式对心脏MR图像进行重构。
2) 对原始心脏MR图像和重构图像进行目标区域纹理特征提取,并按照1:3随机生成训练集和测试集。
3) 通过改进的ReliefF-ACO算法对纹理特征进行纹理特征选择,并保证特征之间的低相关性。
4) 最优特征的训练集在SVM上以十倍交叉验证的方式进行心肌病模式识别,在测试集上验证泛化能力。
方法步骤如图1所示。
3. 数据处理
本研究使用的数据来自医学图像计算与计算机辅助干预学会(MICCAI) 2017中自动心脏诊断比赛(ACDC),该数据集分别使用的是1.5 T和3 T的西门子MRI扫描设备,在病人屏气时使用稳态自由进动序列以短轴方向开始采集,扫描间隔为5~8 mm,空间分辨率为每像素1.37~1.68 mm2,每个患者扫描28~40副图像。本文从该数据集中选取了HCM患者、DCM患者及正常人各30例作为本次实验的数据集。三组类别(正常、DCM、HCM)的划分诊断手段包括了左心室容积、左心室射血分数、左心室收缩功能、左心室腔大小和壁厚。
本文提出了一种心肌重构方法。对于每一个原始的心肌环图像分别从基部到顶端拿取5个切片,并进行了内接处理,使得所有的像素矩阵都完全内接一个心肌环。通过线性插值 [15] 的方式将每个内接心肌环的切片重构为64 × 64的像素矩阵。为了保证纹理信息的完整性,选取内接后像素的中心点作为环心O,以32为最大内接圆半径。将图像转化为极坐标,通过确定中心点、最大内接圆半径将心肌环像素以垂直于水平方向向上为起点,按照时钟方向重新采样成了32 × 201的像素矩阵,每个切片分别在三个固定坐标处采样出只包含心肌部分,大小为12 × 36的像素矩阵,并在水平方向拼接成12 × 108的像素矩阵。五个切片最终重构的像素矩阵按照顺序在垂直水平方向上排列,构成了一个样本的内接矩阵化的心肌像素矩阵,大小为60 × 108。心肌重构的整个过程如图2所示。

Figure 2. Process of reconstruction and this texture
图2. 重构流程以及重构后的心肌纹理图像
纹理特征提取
通过四种传统纹理描述对内接矩阵化心肌环和原始心肌MR图像提取纹理特征(表1)。这些特征包含了从单独到整体的像素统计以及全局上像素之间的依赖关系。特征提取方式包括:灰度共生矩阵(GLCM)、灰度游程矩阵(GLRLM)、局部二值模式(LBP)以及基于直方图。最终本研究总共提取到了的422个特征,并进行了基于均值和方差的归一化处理,用于纹理特征的选择。如表1所示。

Table 1. Overview of the feature extraction
表1. 特征提取概况
4. 算法改进
4.1. 改进ReliefF
传统的ReliefF算法在进行特征选择时,没有考虑噪音数据对权重计算的干扰。在特征权重计算的过程中,可能存在某个样本点较大偏离该类样本中心的情况,这些带有噪音的样本在进行权重累加的过程中会给权重的计算造成误差。为了减少噪音数据对实验的影响,本研究对ReliefF算法进行了改进,降低这些带有噪音的样本在权重计算时的重要性,使得合理样本主导权重的计算。所选取样本的同类近邻点与不同类近邻点由欧氏距离计算 [16] 得出,由于欧氏距离在计算时考虑到了样本的所有特征,不会被某个偏差特征过度影响,可以很好的表达两个样本的相似程度,样本间的的欧氏距离越小,样本越相近。本研究引入并表示为:
(1)
本研究引入了样本偏移度的概念,即在进行ReliefF特征选择之前,计算每个样本在本类数据中的整体偏移程度。每个样本将赋予一个偏移度的属性,记为
,特征总数记为n,同类某个样本的某个特征记为
,样本总数记为N,首先在每类样本中寻找中心样本点
,具体操作如下:
(2)
(3)
根据所得出的每类样本的中心点,同样以欧氏距离计算每个样本相对于本类型中心样本的偏离程度,具体操作如下:
(4)
通过以上的操作,本研究将初步得出一个表示各样本点相对于本类别中心点偏移程度的矩阵,然后在该矩阵中计算所有样本与本类型中心样本的平均距离,记为
,该值直接从矩阵各个部分取平均即可。在某个特征进行随机样本权重计算的时候,会将
与
加入到同类与非同类近邻的距离计算当中,作为系数来对同类样本的距离计算进行动态惩罚。系数的另外部分由每次选取的非同类近邻中心点
距样本点的距离所决定,其计算与
类似,记非同类近邻的中心点与该类中心点距离记为
,具体的操作如下:
(5)
样本
在进行特征权重计算时,会参考以上参数来构造动态平衡系数。
表示了同类近邻距离计算的系数,
表示了异类近邻距离计算的系数,具体的操作如下:
(6)
(7)
其中的
和
代表了非负的距离因子,当某类数据的离散程度过大时,两者的值需要适当变大。最终针对每次样本点所计算特正权重的公式如下:
(8)
当默认距离因子为0的情况下,在随机选取的样本处于边缘位置时,其到同类中心点的距离
将大于平均距离
,若
越大,即样本的偏离程度越高,那么
将在0附近且变化缓慢,从而惩罚同类特征的权重计算,此时如果偏离样本点的某异类近邻中心点离该类中心点的距离越大,说明越接近误差样本,则
越趋近于0,从而惩罚异类权重特征的权重计算,反之则说明边缘样本距离该异类的边缘点仍旧很远,因此其在异类中计算的权重可以得以保留。
当随机选择的样本为合理样本时,随着样本逐渐靠近中心点,
将以越快的速度接近于1,此时若某异类近邻点离该类中心点越远,则代表将其两个类别较为接近,此时
越接近于0,从而惩罚异类权重的计算,反之则代表所选取离中心点近的样本,其某异类近邻点离该类中心点同样很近,此时
与
都接近于1,此时由该样本所计算的权重更加准确,其值也将在最终的权重累加中占据更大的比例。图3展示了所改进的ReliefF算法在应对各种样本时的表现。
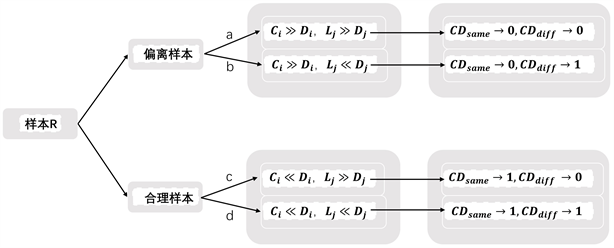
Figure 3. Dynamic balance coefficients respond to the results of different situations
图3. 动态平衡系数应对不同情况的结果
本研究针对ReliefF所引入的动态平衡系数,在应对边缘偏差样本时,将同类各个特征计算的结果统一处理为接近于0的值,将异类特征权重按照实际情况判断舍弃与保留。在应对合理样本时,保留同类各个特征计算的结果,依据各异类近邻的位置与该类型中心点的距离判断权重的保留与舍弃。通过这种方式,特正权重可以由合理的样本点所主导,由于在上图的b,c情况下分别放大了异类和同类的权重计算,特征的权重值将整体上向负方向偏移,因此,经过数据经过本研究的改进的ReliefF算法,将会更加精准的按照权重值对所有特征依次进行高低排序,这些权重值将作为本研究所改进的蚁群算法的参数来对特征进行特征选择以及相关性的剔除。
4.2. 改进ACO
通过原始的ACO算法来进行特征选择具有很大的随机性,由于初始状态下信息素时平均分配的,导致了算法很难收敛到最优的特征子集范围,同时由于特征维数较大的影响,某些特征之间可能存在较强的相关性,使得算法很容易陷入局部最优的情况。针对这些不足,本研究对ACO算法进行了改进。主要思想是改变蚁群算法每次迭代结束的条件以及信息素分配的方式,具体为改变原始算法中每次迭代中路径问题的约束。
与城市距离问题不同,最优特征子集的特征之间没有顺序之分,若将原始算法不加改进的迁移到特征选择中,在每只蚂蚁完成选择以后,信息素分配所考虑的路径会是特征子集中每两个特征之间,这将大大的增加计算量,因此本研究将信息素作为每个特征上的属性,制定特有的策略来对所选择的每个特征进行信息素的分配。每代蚂蚁所选择特征子集的长度以及在SVM分类器中的精度作为本代蚂蚁所产生的总信息素参数,从而使得更具有代表性的特征获得更多的信息素。为解决原始蚁群算法容易陷入局部最优或难以收敛的问题,本研究将引入上个阶段所得到的特征权重以及特征间的皮尔逊相关系数作为路径选择的初始参数,搭配原始算法中的信息素概念来对特征进行挑选。为了加速算法的收敛,本研究根据选择特征数制定了相应的剪枝策略。整体上讲,改进的蚁群算法通过制定新型的路径选择策略、信息素分配和挥发策略以及剪枝策略来完成特征选择任务。
首先将改进后ReliefF所计算的特征权重进行最值归一化,作为各个特征点的初始信息素浓度,路径的选择基于每个特征点的信息素浓度来进行。为了避免算法陷入局部最优,本研究设定了一种带有一定随机性的路径选择方式,这主要考虑到一些权重较小的特征相互组合也可能会表现出关键信息。初代蚂蚁的数量固定为特征总数的整数倍,将平均分配依次从各个特征开始出发,其接下来的路径选择不以固定的特征数作为结束条件,而是当搜索不到满足条件的特征时结束。每只蚂蚁在确定起始特征后将通过图4所示的搜索策略得出最终的选择结果。

Figure 4. Path selection strategy of a single ant
图4. 单只蚂蚁的路径选择策略
如图所示,每只蚂蚁确定初始点之后,会将剩余特征通过标签值R来随机等分为两部分,
部分的特征选择依据是特征自身信息素在阈值
之上且与初始点特征之间的相关性不高于0.6,浓度阈值
用来控制迭代过程中冗余特征剔除的速率,由所有特征当前信息素浓度的平均值M和当前的迭代次数N所得出,则
表示为:
(9)
代表了速度因子,当特征总数较大时,增大
的值,会考虑更多的随机组合,且浓度阈值
在最初的几代会增长的相对迅速,使得所选取特征的数量快速下降,随着代数的增加而逐渐变化缓慢,
较小时,冗余特征剔除的速度从一开始就增长缓慢,且每一代相对平均。在某只蚂蚁完成
部分的特征选择以后,统计出在该部分选择特征的总数n,作为
进行相关性判断后选择特征数的上限,因此该部分选择的特征数将不会大于n。通过这样的方式,初代信息素浓度大的特征会更容易被选择,浓度较小的特征也会被适当的考虑,同时因为加入了皮尔逊相关系数的判断,保证了所选择的特征之间具有较低的相关性。往后代数蚂蚁的初始特征选择将随机进行,剩余部分的特征将依据上述的路径选择策略来进行。
每只蚂蚁在完成特征的选择以后,会将只包含这些特征的样本进行训练集和测试集的划分,并基于SVM分类器进行训练,在测试集所得到的精度记为ACC,本研究所制定的分配给每个特征的信息素增量将由该值和特征子集长度共同决定,表示如下:
(10)
Q为信息素常量,该值用来控制每代相对于初始信息素所增加的幅度,防止算法因某一代信息素增量过大而使得后代陷入局部最优。当每代所有蚂蚁进行完上述步骤以后,会先对当代特征的信息素进行适度挥发处理,然后按照每只蚂蚁所贡献的信息素之和进行更新。下一代中某个特征A的信息素浓度表示为:
(11)
以上为每次迭代过程中蚁群选择特征、生成分配和挥发信息素的过程。除了上述的改进以外,本研究还提出了一些供参考的小技巧。
首先是当出现每代蚂蚁从一开始选择的特征基本上都一样的情况时,应适当放大初代蚂蚁数与特征总数的倍数值,这是为了克服局部最优的发生。当出现难以收敛的情况时,需要增加蚂蚁自增长速率,即每代蚂蚁数量按固定比例递增,该技巧可以应对迭代过程中信息素增长不明显的情况。另外是剪枝策略,连续若干代蚂蚁所选择的特征总数有所下降但在之后的几代中特征数不再下降时,将从来没有被选中的特征剔除,剪枝条件如下:
(12)
最终,当达到先定的迭代次数后,蚁群会统一选择信息素浓度最高的若干个特征,将其将作为本算法所提取的最优特征子集。相对于原始的蚁群算法,本研究在蚁群选择阶段使用了整体的弱概率代替了各个节点的具体概率,从而将随机的因素加入到选择的过程中。从计算量的角度来讲,不必对每次的节点单独进行概率计算,这是由于特征选择的任务的特征之间的选取并不存在特定的顺序关系,一些权重较低的特征与其它特征的组合可能更有效果,其次改进后的算法可以控制特征维数下降的速度,在维数较高的情况下,前期可以适当加快下降速度,后期则缓慢进行特征剔除。图5展示了整个特征选择算法的流程。

Figure 5. Algorithm flow chart for ReliefF-ACO
图5. ReliefF-ACO算法流程图
4.3. 算法验证
本研究在几个公开的基因表达数据集 [17] 上对提出的算法进行了可靠性验证,这些基因表达数据集的特征维数在2000~6000之间,通过BSL-FSRF [18]、无监督特征选择ACO [19]、ReliefF-Kmeans [20] 聚类算法以及本研究所提出的算法对以上四个数据集进行了特征选择,然后通过SVM分类器在四种算法所选择的最优子集上进行了十倍交叉验证。最优子集长度和识别精度结果如表2所示。
Table 2. Algorithm verification for feature selection
表2. 特征选择算法验证
本研究所提出的特征选择方法在4组数据集上取得了可观的识别精度,比ReliefF与Kmeans的组合平均高出7.2%的正确率。虽然基于ACO的特征选择算法在3组数据集上的识别精度要优于本研究提出的算法,但是ACO算法所使用的特征要比本文算法平均高出102个特征,特征之间也具有较大的相关性。本文算法能够在较大特征维数的数据中选择出最重要的特征,并保证较高的识别精度。
4.4. 算法参数分析
在验证了算法的性能后,本研究在LUNG数据集上对一些超参数进行了调整分析。这些参数包括采样率/数、初始蚂蚁数量、蚂蚁自增率和速度因子阈值等。结果如表3所示。
Table 3. Algorithm hyperparameter analysis
表3. 算法超参数分析
当使用所有样本计算特征权重时,剔除权重计算的随机性,精度最高,但采样率升高会消耗更多时间。蚂蚁的初始数量将从初始阶段影响信息素的分配,增大初始数量可以避免陷入局部最优。因为数据样本较少,增长率较大反而使得性能下降。速度因子决定了信息素的阈值,由于该数据集的特征数较多,当速度因子较小时,每代阈值变大,特征数下降较为缓慢且随机性考虑不充分。由于ReliefF所计算的特征权重值进行了归一化处理,当信息素常量过大时,将掩盖初始的信息素,将在初始信息参高的特征中陷入局部最优,同样,信息素常量过小会使得每代变化不明显,从而难以收敛。信息素挥发系数的原理与信息素常量相同。本文建议样本选择率设置在0.5~0.8之间,当特征总数较大时,应通过增大速度因子来考虑更多的随机组合,同时在前几代将冗余特征迅速剔除。蚂蚁初始数量和蚂蚁的自增率由特征维数和样本总数来决定。
5. 实验结果与讨论
本文提出的特征选择算法在422个心肌纹理特征中选择了6个最优纹理特征,分别是重构0˚反差(F_Contrast)、重构0˚灰度不均匀度(F_GLN)、重构局部二值(F_LBP)、重构定向梯度直方图方差(F_Var)、原生90˚和0˚反差(O_Contrast)。如图6所示。

Figure 6. Feature selection result graph
图6. 特征选择结果图
基于测试数据集,对每一个纹理特征单独进行了心肌病识别能力的评估,以箱线图的方式呈现,如图7所示。
为了验证心肌重构纹理特征具有额外价值,实验随机抽取了66个样本,将重构与原生图像共同选取的纹理特征和原始心肌选取的纹理特征分别通过t-SNE [21] 在二维平面进行了可视化,两组实验聚类能力如图8所示。
由图8可以看出,加入重构图像特征的最优特征子集聚类效果更为突出。为了进一步验证重构图像特征的潜在价值,本文将原始心肌和重构心肌通过本文提出的算法单独进行了特征提取与选择,作为对照实验。包含6个特征的训练集分别通过了KNN、XGBOOST、高斯核函数的SVM以及集成两种SVM和决策树的集成学习分类器(Soft Voting Classifier)进行十倍交叉验证,并在全部数据集上进行10次随机划分计算了测试集的平均准确率。结果如表4所示。
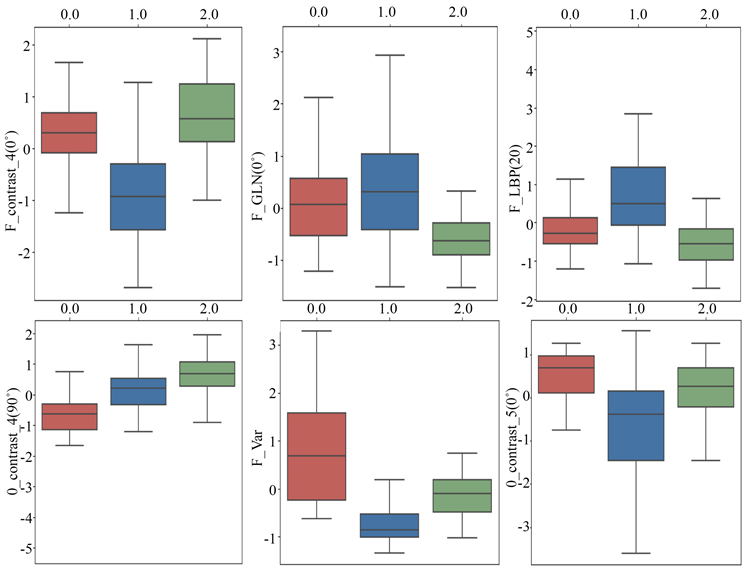
Figure 7. Single feature recognition ability
图7. 单特征识别能力箱线图
Table 4. Comparison of three groups of experiments
表4. 三组实验的比较
最后,本研究绘制DeLong方法的受试者工作特征曲线(ROC) [22] 对分类模型的性能进行评估。如图9~11所示。

Figure 9. ROC curve of native features
图9. 原生特征的ROC曲线
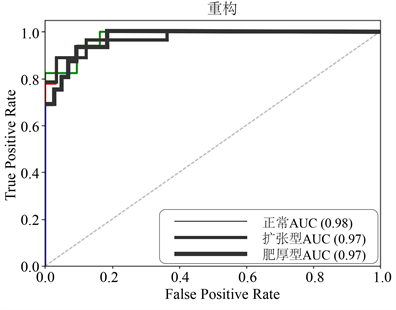
Figure 10. ROC curve of reconstructed features
图10. 重构特征的ROC曲线

Figure 11. ROC curve combined with original and reconstructed
图11. 原生和重构结合的ROC曲线
结果分析
本实验首先通过4个特征维数较高的基因数据集对所提出的改进ReliefF与改进ACO相结合的特征选择算法进行了可行性验证,从实验结果可以看出,在高维的特征集合里,该算法的效果显著。
在对心肌病模式识别的过程中,本研究将原生特征和重构特征作为对照,通过提出的特征选择算法分别在原生、重构以及原生与重构中进行了特征提取以及最优特征选择。从聚类角度来看,加入重构特征会表现出更好的聚类能力。从识别精度角度来看,原生特征的识别精度要远远小于重构的纹理特征,而两者结合后,训练和测试的识别精度会进一步提高。原因在于本研究所重构的心肌图像优先考虑了环方向上的特征。实验结果验证了本文所提出的内接矩阵式的图像重构方式可以更好的反映心机纹理特征,同时所提出的特征选择算法也可以很好的适配各种分类模型。在提高识别精度同时,也证明了在心肌环方向上存在着一些潜在的纹理特征是值得研究的。
6. 结语
本研究提出了一种集成式的特征提取算法,该算法在大幅度降低了特征维数的同时,提升了分类精度,同时可以适配大多数的分类模型。通过改进ReliefF算法,减少了噪音数据对特征权重的影响,得到了更加可信的特征权重。这些特征权重将使得ACO算法快速收敛,大幅度减少了计算量,同时改进ACO算法,制定新的剪枝策略以及信息素分配、更新以及挥发规则,避免了算法陷入局部最优。两种改进的算法以皮尔逊相关系数和特征权重为中介,进行结合,在特征维数较高、样本数据较少的场景中,该算法表现出了优越的性能。
本文最终将提出的特征选择方法用于心肌纤维化模式识别当中。在包含原始心肌与重构心肌的纹理特征中,选择了6个纹理特征来进行分类识别,在测试集上,将精度提升到了93.8%。在6个被选择的纹理特征中,有4个特征来自于重构后的心肌图像,这也证明了重构心肌的特征纹理可以为纤维化模式的分类提供更有价值的信息。
基金项目
上海自然科学基金(17ZR1443500)中国自然科学基金(U1831133, 61701296)。
NOTES
*通讯作者。