1. 引言
视觉数据在日常生活中有着十分重要的角色。我们每天都要面对各种各样的视觉内容。学习生成真实的视觉数据将帮助我们理解和开发机器学习模型来感知视觉世界。此外,由于视觉数据的复杂性和多样性,真实视觉数据的自动生成仍然是一个重大挑战。图像等视觉数据的真实感合成在广告、游戏、虚拟现实等领域有着广泛的应用,长期以来一直是计算机视觉和计算机图形学的研究热点。随着对深度学习应用需求的增加,图像合成也显示出巨大的潜力。
在生成对抗网络(GANs) [1] 提出以来,图像合成领域取得了许多令人印象深刻的进展。除了从随机潜在变量生成高质量图像的随机方法外,条件图像合成也因其可控制性的实际优势而受到同等甚至更多的关注。条件图像合成是以一定的输入数据作为条件,从数据集中生成新图像的任务。引导合成的条件输入可以有多种形式,包括RGB图像、语义标签、边缘/梯度图等。本文关注的是一种特殊形式的条件图像合成。具体来说是将语义分割掩膜转换为逼真的图像,这一过程被称为语义图像合成。语义图像合成有着广泛的应用,如内容生成和图像编辑 [2] [3]。
之前的工作 [2] 提出了通用的图像到图像翻译框架内的解决方案,该框架直接将语义掩码提供给编码器–解码器网络。为了提高质量,最近的基于空间自适应归一化的语义图像合成(SPADE) [4] 采用了空间变化的条件归一化,以避免传统归一化层造成的语义信息丢失。通过研究SPADE的模型结构并分析实验结果,本文发现了模型中的不足之处,SPADE仅仅在网络最开始的部分输入风格信息。而在最近的方法 [4] 中已经证实将风格信息作为归一化参数输入到网络的多个层中可以起到更好的效果。本文的主要想法是将由风格信息获得的特征输入到网络的多个层中,并由此在不同的层中获得不同的归一化参数。为了评价所提出的方法,本文在人脸数据集CelebAMask-HQ和场景数据集ADE20K进行了实验。结果表明,本文的方法获得了高质量的结果。
2. 相关工作
2.1. 生成对抗网络
最新的深度生成模型包括变分自动编码器(VAE) [5] 和生成对抗网络(GAN) [1]。GAN由生成器和鉴别器组成,其目标是生成真实的图像,从而使鉴别器无法区分合成的图像和真实的图像。随着GAN结构、正则化和损失函数的不断改进,GAN合成的图像越来越逼真。例如,由StyleGAN [6] 生成的人脸图像质量非常高,不仔细对比几乎无法与真实图片区分开来。最初,GANs只能生成从随机分布中抽取的样本,因此缺少用户控制能力,但很快出现了能够进行条件图像合成的模型。用户可以通过向生成器提供条件信息来控制合成。本文的方法建立于GANs上。
2.2. 图像到图像翻译
图像到图像翻译是一种学习数据分布以生成新样本的方法,以图像作为条件的GAN被视作各种图像到图像转换问题的通用解决方案。语义图像合成是众多图像到图像的翻译问题中的一种特殊类型,它可以通过修改输入的语义布局图像来方便用户控制 [7]。针对这一任务,迄今为止已有许多出色的方法。其中最具代表性的是Pix2Pix [2],它采用编码器-解码器结构进行统一的图像到图像的转换。Pix2pixHD [3] 通过提出从粗到细的生成器和判别器改进了Pix2Pix。随后的方法 [8] 进一步探索了如何从语义掩膜中合成高质量的图像,并取得了显著的改进。最近的SPADE [4] 通过改进归一化层,在语义图像合成中得到了比以往更高质量的合成图片。本文的想法是通过改变风格信息的输入方式来改进SPADE。
2.3. 风格转换
图像到图像翻译问题的一种变体是引入附加的指导图像,由此获得更多的用户控制能力。这种指导图像可以采取多种形式,可以是风格转换问题中的风格图像。目前的方法主要分为三处地方进行风格编码:1) 图像特征的统计 [9];2) 网络权值(如快速样式传递 [10] );3) 归一化层参数)。第一类方法对图像分类网络提取的图像特征进行匹配统计,优化过程缓慢,时间开销大。第二类方法的泛化能力弱,需要为每一种风格的图像训练一个单独的神经网络。第三类方法不存在前两类方法的缺点,此类方法如StyleGAN和SPADE可以实现任意风格转换。因此本文的风格转换也建立在归一化层的基础上。
3. 语义图像合成
给定一个输入风格图像及其对应的分割掩膜,本节展示如何根据提取风格图像中的风格信息与分割掩膜中的语义信息来合成逼真图像。
3.1. 自适应归一化
设Ireal为真实图像,Iz为从Ireal经过Encode所得的隐含量分布采样而来的特征图。本文提出一种类似批归一化的自适应归一化。与批归一化类似,自适应归一化以通道方式进行归一化,然后学习尺度参数γ和偏差参数β进行调整。图1展示了自适应归一化的主要构成。自适应归一化层的激活值为
(1)
其中,μ和σ为各个通道激活的平均值和标准差,h为前一层的激活值,ε为一个给定小值。
图2展示了自适应归一化残差层的整体结构,残差层基本遵循方法 [11] 和方法 [12] 的设计,由卷积层、归一化层和激活层组合构成。图2下半部分表明残差层也学习了跳过连接。
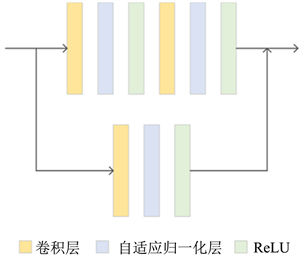
Figure 2. Residual layer with adaptive normalization
图2. 自适应归一化残差层
3.2. 生成器
如图3,本文方法的生成器采用编码器-解码器结构,对方法 [10] 中提出的生成器进行了调整。调整包括两个下采样层、一个由多个残差层组成的语义核心、两个上采样层和一个Encoder部分。残差层分为自适应归一化残差层和SPADE残差层。自适应归一化残差层与Encoder组合,以真实图像作为额外信息学习归一化层的调整参数。在进行风格转换任务时,作为额外信息的真实图像就是风格图像。对SPADE残差层添加掩膜图像作为额外信息,SPADE残差层中的归一化层的参数都使用SPADE进行学习。传统归一化层倾向于消去输入中的语义信息,SPADE的目的是尽可能保留语义信息。
3.3. 判别器
本文使用与pix2pixHD [3] 相同的多尺度判别器,它将掩膜图像和需要判别图像拼接后作为输入。每个判别器都基于PatchGAN [2],判别器的最后一层是卷积层,所以最后的输出并不是一个标量,而是一个矩阵。这样有利于实现更高分辨率的图像生成。
3.4. Loss
本文使用以下损失以对抗的方式训练生成器:作为对抗损失的铰链损失 [13] [14] [15] 以及特征匹配损失 [3]、感知损失 [10] 和KL散度损失。其中,使用KL散度损失训练Encoder部分,目的是用于进行风格引导图像合成训练任务。
4. 实验
4.1. 实现细节
继SPADE [4] 之后,本文将谱范数 [14] 应用到生成器和判别器的所有层中。基于方法 [15] 的研究结果,本文将生成器的学习速率设置为0.0001,判别器的学习速率设置为0.0004。对于优化器,本文选择β1 = 0,β2 = 0.999的ADAM。所有实验都是在2张NVIDIA RTX 3090 GPUs上进行的。此外,本文使用的是批归一化的同步版本。
4.2. 数据集
本文在实验中使用了以下的数据集:1) CelebAMask-HQ包含了用于CelebAHQ人脸图像数据集的30,000个分割掩码,有19个不同的地区类别。2) ADE20K由20210个训练图像和2000个验证图像组成,包括150个不同语义类的场景。
4.3. 评价指标
本文采用以下指标对本文方法进行评价:
1) Frechet Inception 距离(FID),FID用于计算生成器生成分布与真实图像分布之间的差异,FID越小,则图像多样性越好,质量也越好。计算FID需要使用inception network。可通过以下的公式计算:
(2)
其中,
和
分别为真实图像在inception network输出特征的均值和协方差矩阵,
和
分别为合成图像在inception network输出特征的均值和协方差矩阵,Tr为矩阵的迹。
2) 通过平均交并比(mIoU)和像素精度(accu)测定的分割精度,mIoU和accu越大图像质量越高。为了计算分割精度,本文使用了目前主流的分割网络DeepLabV2,用其生成的分割结果计算mIoU和accu两个性能指标。mIoU计算公式为:
(3)
其中i为真实值,j为预测值,
为将i预测为j,k为类别数。此外,accu的计算公式为:
(4)
与式(3)类似,k为类别数,
为真实像素类别为i的像素被预测为类别j的总数量。
4.4. 定性结果与定量结果
表1展示了本文方法与最近的方法在CelebAMask-HQ数据集上进行语义图像合成的实验数据对比。可以观察到,本文方法在平均交并比和像素精度比Pix2PixHD和SPADE两种方法略低,但FID低于这两种方法。所以本文方法的合成图像质量与Pix2PixHD和SPADE相差无几,但多样性要优于这两种方法。

Table 1. CelebAMask-HQ experimental data
表1. CelebAMask-HQ实验数据
本文在图4中展示了本文方法用于CelebAMask-HQ数据集的结果可视化对比。可以观察到,对网络输入标签图像后输出的合成图像具有较高的图像保真度,合成图像的脸部细节质量高,只在占比很少的图像会存在与真实情况不太符合的部分。

Figure 4. Synthetic image of CelebA-HQ experiment
图4. CelebA-HQ实验的合成图像
图5展示了使用ADE20K数据集训练风格转换任务的部分结果。(a)是真实图像,为了更直观的对比,真实图像内还加上了对应的分割掩膜。(b)~(f)是在输入不同风格图像时输出的合成图像。可以观察到,通过输入不同的风格图像,本文模型的合成图像具有不同外观,但在输入掩膜中都具有相同的语义布局。作为参考,输入分割掩膜显示在真实图像之内。
5. 结论
本文提出了一种用于风格控制的自适应归一化,这是一种简单而有效的生成对抗网络(GANs)构建块,它基于对部分模块的归一化层输入风格信息。主要想法是扩展最近的SPADE网络,以多个通道的方式控制语义的风格。该模型可以产生人脸和景观的逼真图像,并且还可以对图像进行风格控制。在公开数据集上进行的实验结果表明,本文提出的语义图像合成方法相比于目前的主流算法能够生成更精准、更多样性的合成图像。在保留用户控制能力的基础上,生成的图像与真实图像更为接近。