1. 引言
大数据的迅速发展给我们带来了机遇的同时也带来了挑战,如何从海量的数据中找出有利用价值的信息是我们所关心的。就旅游景点而言,游客的在线评论数据真实客观的反应了出游时的所见、所闻、所感,是影响潜在消费者做出决策的因素之一,从而间接地影响了旅游景点的收入。但是经过实际调查研究,大多网站平台没有对其进行细致的分类,即没有明确区分开好评和差评,有的平台即使作了区分,但是区分的方法不同,甚至有的平台是直接根据综合打分这一项指标来区分好评和差评的,分类的效果很不理想。就打分来说,大部分游客会倾向于给出一个接近满分的评分,而且如果游客没有评论网站会默认满分好评,但是实际评论内容却不一定是非常满意的;就用户评论来说,有些景点会购买网络水军对其提供的旅游产品进行虚假夸赞,以吸引更多的游客。因此,使用机器学习算法对评论文本进行精确分类并对其中隐藏的信息进行深度挖掘,实现对旅游景点客观整体的评价,就显得极具意义和价值。
关于文本的情感分类和主题挖掘研究还是比较多的。基于情感词典的文本分类方法和基于机器学习的文本分类方法是目前文本分类的主要研究方法,许多研究成果表明基于机器学习的性能表现优于词典方法的(2008) [1]。因此,本文采用基于机器学习的文本分类方法训练分类器。刘志明和刘鲁(2012) [2] 使用不同的特征选取算法、不同的特征项权重计算方法和不同的机器学习算法来进行组合,对微博话题进行了文本分类的研究。周咏梅等(2014) [3] 通过采集新闻评论文本数据,利用己有的情感词典和从评论文本中提取的情感词构建出了新闻领域的情感词典,并用于评论文本情感倾向性分析。魏慧玲(2014) [4] 在己有情感词典基础之上配合语义相似度分析实现了手机评论的情感倾向性分析。郭小芬等(2017) [5] 基于贝叶斯网络和支持向量机分类算法,在实际应用中实现了对中文新闻的精确分类。丁照银(2019) [6] 将机器学习分类模型和LDA主题模型相结合,对某品牌连锁酒店用户评论进行了研究,得出支持向量机的分类效果最好。应昊东(2021) [7] 利用LDA主题模型对新能源汽车各车型中用户满意以及不满意维度进行主题提取,来挖掘用户的关注重点。戴维(2018) [8] 讨论了逻辑回归解决文本分类问题,其不仅介绍了逻辑回归的算法原理和使用步骤还结合具体实例对算法进行了评估,其中,特征选取是基于LDA主题聚类模型进行操作的。通过对相关文本分类和主题模型文献的梳理与研究,发现许多文本分类研究工作针对的是新闻、微博、电商评论,很少有学者对旅游评论文本进行研究,本文将以旅游评论文本为研究对象,旨在为文本分类在新领域的研究拓展思路。
2. 数据搜集与预处理
2.1. 数据搜集
利用网络爬虫技术爬取了携程、去哪儿网、同程、马蜂窝、途牛等多个平台上关于著名景点山海关的游客评论数据,为保证时效性,时间范围限定为2020年1月1日~2022年1月31日,共计40281条,将数据文件保存为csv格式备用。每条数据内容包含4个指标:用户名称、评论内容、评论时间、用户评分。部分原始数据见表1所示:
数据来源于:携程、去哪儿网等平台。
2.2. 数据处理
使用Python语言中的Pandas、jieba等库对数据进行预处理,主要包括数据清洗、文本分词、文本向量化。在数据清洗之前,为了保证数据的真实可靠性,需要人工去除网络水军以及恶意差评的评论,包括:明显是营销账号发布的评论,评论中含有xx网站、xx平台、xx酒店等;同一ID发布的多条评论内容,存在人工刷评论行为;评论字数过少,没有参考价值。
数据清洗前后效果对比见表2:

Table 2. Comparison of effects before and after data cleaning
表2. 数据清洗前后效果对比
可以看到特殊符号、重复字段都被去除,可见数据清洗效果很好,清洗之后剩余37491条有效数据。
2.2.1. 文本分词与去停用词
中文分词和英文分词的区别在于,中文字符不像英文单词那样有天然的空格隔开,在中文文本挖掘过程中,为了便于分析词句的特性,需要把评论语句拆分成单个的词语。本研究使用的是jieba分词技术来进行中文文本分词的,是使用Python语言实现的文本预处理软件包,其准确率较高,而且操作起来较为简便,在文本分析领域很受欢迎。
分词之后存在很多像“的”、“了”、“吧”一些并没有实际意义的语气词,“但是”、“然而”之类的转折词,还有标点符号、特殊符号等之类的这些词都称为停用词,这些对文本分析不但没有用处,还会对分析结果造成干扰,需要去除。本文采用哈工大停用词典过滤掉无用的信息,可以减少文本特征向量的维数,加快模型运算速度。
经过分词和去停用词操作后,优化分词与去停用词结果见表3:
Table 3. Partitioning to stop words
表3. 分词去停用词
可以看到许多无意义的符号、语气词等都被过滤掉且分词效果很好。
2.2.2. 文本向量化
经过分词后的文本是结构化数据,而计算机只能识别非结构化数据,文本向量化可以把经过预处理后的数据转换成计算机可以识别的结构化数据,文本向量化的主要步骤为:首先将评论文本通过jieba分词工具分词为N个词组的集合,其次利用Word2vec模型将分词转化为N个对应的词向量,最后采用TF-IDF算法提取每个词向量的关键词,输出最终的文本向量。
至此,数据的预处理全部完成。每条文本评论变成了固定维数的向量,这是一种数学表达,计算机是可以轻松识别的。
3. 描述性统计分析
3.1. 词云图可视化
将游客评论文本经预处理后,使用Python软件中pandas库下的value_counts()函数,统计词频数排名前100词语的词频并绘制词云图。词频越高表现在词云图中的字号就越大,词频越低表现在词云图中的字号就越小。山海关景区整体词云图见图1,可以发现:天下第一关、历史、长城、不错、值得等词语比较突出,可以得知关于山海关景区的一些特色和卖点,大部分游客对该景点还是比较满意的,可以得到很好的游玩体验。但是也有一些基于消极评论产生的关键词,例如,贵、建议、小时、停车场等词。

Figure 1. The overall word cloud map of Shanhaiguan scenic area
图1. 山海关景区整体词云图
3.2. 语义网络图
虽然词云图可以通过词频直观地来反映游客的主要关注点,但无法反映词组在特定意义上的联系以及文本深层次的结构关系,而语义网络分析则能通过构建概念和语义关系的网络图来直观展现要素之间的关系,将评论文本txt文件编码由UTF-8转为ANSI,将文件导入NetDraw软件,最终生成游客对山海关景区整体形象的语义网络图 [9]。从层级结构来看,语义网络图呈现“核心–边缘”特点,箭头指向越密集,越是接近核心的词表示对文档的作用越重要,具体见图2中红色方块。通过图2可以清楚看到,山海关景区语义网络图中包含“历史”、“山海关”、“长城”、“方便”等一系列的节点。从内容要素上看,山海关景区的旅游者主要关注的是景色、知名度、历史文化、服务等旅游目的地要素,主要表现在“长城”、“城墙”、“导游”、“门票”、“方便”等节点上。我们可以初步的了解到,山海关景区购票取票服务很好,可以在网上购买也可以在现场购买,同时导游的讲解服务也被多次提到。

Figure 2. Semantic network diagram of Shanhaiguan scenic area
图2. 山海关景区语义网络图
4. 分类模型
4.1. 模型训练
朴素贝叶斯、逻辑回归分类模型属于有监督的机器学习,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定,所以为了保证分类模型的准确率,需要让模型得到充分的训练,进而防止出现过拟合或欠拟合现象,本文通过网络收集一些人工标注的旅游景点评论组成的训练语料库,根据简单随机抽样原则随机抽取8000条语句进行了人工标注,进一步加大训练集的数量,共计20,214条语料,将处理后的评论语料库按照8:2的比例划分训练集与测试集,最终语料库组成为:训练数据集16,171条语料,测试数据集4043条预料,其中测试集中要包含比训练集中更新的数据。这些数据可以用于验证模型的性能,并且可以用于评估模型应用于实际环境中的表现。
语料库经过第二节预处理后,已经具备构建分类器的条件。首先在训练数据集上构建文本分类器,然后用训练出来的分类器模型在测试数据集上进行预测,根据预测情况对分类器性能进行评估。使用的是Python中sklearn机器学习库进行分类器的训练,把训练好的分类器应用到测试集中预测出分类,然后评估模型的预测效果。
4.2. 分类模型性能的评估
分类模型的性能评估是机器学习中非常重要的步骤,应该从多方面对模型进行评价,比较常见的指标就是准确率(accuracy)、精确率(precision)、召回率(recall)、F(F-measure)值、ROC曲线和AUC值。
评价指标的计算公式如下:
(1)
(2)
(3)
(4)
对于文本分类问题,常用混淆矩阵来展示训练好的分类器在测试集中的表现。混淆矩阵是一种在机器学习分类问题中经常用到的辅助工具,可以直观地了解模型在测试集中的表现。
4.3. 模型构建及分析
4.3.1. 朴素贝叶斯模型
1) 混淆矩阵
构建基于朴素贝叶斯模型的分类模型,利用训练集训练后分类器在测试集上的表现见图3:
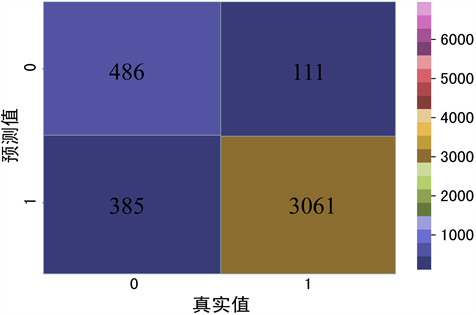
Figure 3. Naive Bayes confusion matrix
图3. 朴素贝叶斯混淆矩阵
如上图3,有111个样本原本是1 (正例)的,却被预测成了0 (反例),还有385个样本原本是0的,却被预测成了1。
具体如见表4:
由公式(1)~(4)计算得出:准确率 = 87.73%,精确率 = 88.83%,召回率 = 96.50%,F值 = 92.51%,都在90%左右,说明分类器的预测效果是理想的。
Table 4. Naive Bayes confusion matrix
表4. 朴素贝叶斯混淆矩阵
2) ROC曲线
ROC曲线的纵轴表示“真正例率”(true positive rate)简称TPR,横轴表示“假正例率”(false positive rate)简称FPR,基于表中的符号,二者公式为:
(5)
(6)
以所求得TPR和FPR的数值作为横、纵坐标,使用Python作图,就得到了ROC曲线见图4,常用ROC曲线的线下面积,即AUC (area under ROC curve)来评估分类模型的性能。
由图4可以看出,朴素贝叶斯模型ROC曲线占据了整个图形的左上方区域,分类器的分类效果十分理想。AUC = 0.9237也就是AUC的值,这个值体现出朴素贝叶斯分类器性能良好。
4.3.2. 逻辑回归模型
1) 混淆矩阵
构建基于逻辑回归模型的分类模型,利用训练集训练后分类器在测试集上的表现见图5:

Figure 5. Logistic regression confusion matrix
图5. 逻辑回归混淆矩阵
如上图5,有151个样本原本是1 (正例)的,却被预测成了0 (反例),还有272个,原本是0的,却被预测成了1。
具体如下表5所示:
Table 5. Logistic regression confusion matrix
表5. 逻辑回归混淆矩阵
由公式(1)~(4)计算得出:准确率 = 89.54%,精确率 = 91.74%,召回率 = 95.24,F值 = 93.46%,分类器的预测效果也是很理想的。
2) ROC曲线
由图6可以看出,逻辑回归模型分类器的分类效果也十分理想。AUC = 0.9338是AUC的值,这个值越接近于1表示分类器性能越好。
4.3.3. 长短期记忆模型
神经网络模型在避免模型过拟合方面比传统机器学习模型表现好,长短期记忆网络(LSTM)是在循环神经网络的基础上改进后的模型,是一种特殊结构的RNN。LSTM能很好地解决长期记忆问题,也能避免出现梯度爆炸和梯度消失问题。
1) 实验与结果分析
为了防止模型过度拟合,本节采用测试集通过设初始参数进行监控,相关参数见表6,当验证集的损失值连续3轮没有改善时,停止模型训练并保留最佳模型。

Figure 6. ROC curve of logistic regression
图6. 逻辑回归ROC曲线
Table 6. Model parameter training table
表6. 模型参数训练表
准确率和损失变化见图7、图8,可以看出模型准确率随着训练轮数的增加不断提高,损失函数值不断下降,从第17轮开始基本没有变化,通过早停earlystopping函数停止训练。
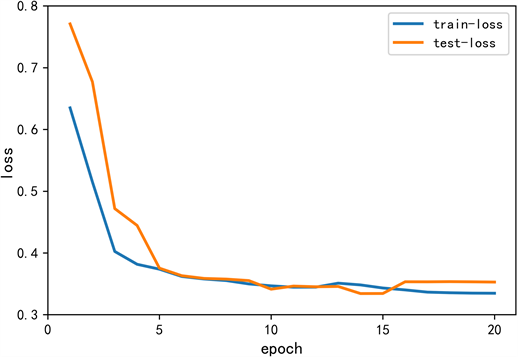
Figure 7. Changes of training loss of LSTM model
图7. LSTM模型训练损失变化图
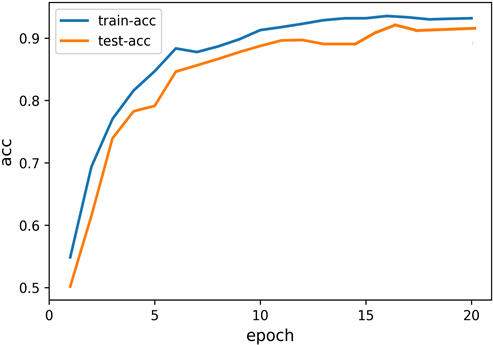
Figure 8. Changes of accuracy of LSTM model
图8. LSTM模型准确率变化图
混淆矩阵见图9,通过混淆矩阵得到模型的准确率为92.15%,精确率为91.66%,召回率为96.72%,F值为94.12%,其中模型的准确率比传统的机器学习模型最高值还高约2.6个百分点,展现出了LSTM的优良性能。
至此,本研究的第一个研究目标已经顺利实现。经过综合评价,LSTM模型可以用来实现该景点游客评论文本的精确分类,可以考虑在线上推广使用。
4.4. 预测分类
在已经构建的3个文本分类器模型中选择性能相对来说较好的LSTM分类模型对山海关景区游客评论文本数据进行分类,把爬取的经过前期数据处理后的景点数据放入训练好的逻辑回归分类器中进行文本情感的分类得到正面评论和负面评论,其中游客评论正面评论占比79.6%,负面评论占比20.4%,即正面评论多于负面,可见山海关景区游客整体满意度很高。
5. LDA主题聚类分析
本节运用LDA主题聚类模型,用以挖掘山海关旅游在线文本评论中蕴含的更深层次的信息,以期获得更有价值的内容。LDA主题模型以文档、主题、词三层贝叶斯模型为核心结构,利用先验分布对数据进行似然估计并最终得到后验分布,模型的训练可以看成是这样一个动态链式:
(7)
LDA主题模型分析过程见图10:

Figure 10. LDA topic probability model diagram
图10. LDA主题概率模型图
其中,
和
分别表示主题分布
和主题词分布
的先验分布参数,将其先验分布视为狄利克雷分布。z和w分别表示模型生成的主题及最终的主题词,M表示文本数量,S表示文本的词语数量。在LDA主题模型中,主题数K需要预先设定,为了得到最为合适的主题数,通过计算对应困惑度大小求得最优主题数K。困惑度越小,说明文本聚类的效果越好。对图像来说,当困惑度下降趋势不再明显或处于拐点处时,此时的K值为最优主题数。
5.1. 确定主题数
在图11主题数–困惑度折线图中,对于游客正面评论数据集,随着主题数K值的增大,模型困惑度逐渐减小,并且当
和
的时候,存在显著的拐点:当K属于
时,曲线急剧下降;当K属于
时,曲线基本趋于平稳。故拐点4即为K的最佳值。同理,在游客负面评论数据集中,
时模型困惑度最小。故最终选择正面主题4个,负面主题3个。
接下来使用Python的gensim库进行LDA主题模型训练求解,分别提取正负面评论集主题的5个特征词以及各每个特征词的权重,更深入地挖掘景点优势和不足。
5.2. 主题展示
山海关景区负面评价的潜在主题模型聚类结果见表7,可以看出负面评论包含三个主题且每个主题有五个主题相关特征词及其权重。主题一中包含山海关、天下第一关、知名、景区、古代五个特征词。故将主题一概括为“景点知名度”,正因为山海关景区拥有较高知名度,反而给景点带来了不小的压力,由于知名度吸引游客慕名而来,但是游客在游玩过程中的实际体验并没有和较高的知名度相匹配,旅游者在看到山海关真实的形象与自己心中想象的截然不同而产生心理落差,由此导致了负面评论的产生。主题二中包含了景点、排队、人多、厕所、取票等五个特征词。将主题二概括为“景点基础设施”,厕所、排队、取票这几个特征词,可以看出景区的基础设施没有满足游客的需求,由此导致取票、上厕所时人过多而排队,影响游客游玩体验。主题三中包含了门票、贵、停车、收费、没有等五个特征词。将主题三概括为“景点收费管理”。主题三的特征词主要围绕收费进行展开,主要是游客对景点门票、停车的收费感觉不合理,由此导致游客负面情绪的产生。
Table 7. Potential topics of negative comments
表7. 负面评论潜在主题
山海关景区正面评价的潜在主题模型结果见表8,通过表可以看出正面评论包含四个主题每个主题有五个主题相关特征词及其权重。主题一中包含历史、长城、城墙、人文、朝代等五个特征词。故将主题一概括为“景点历史文化底蕴”,正面主题一中特征词与山海关负面主题一十分接近,二者主要在围绕山海关的历史人文、知名度来讨论。作为知名历史文化景区,山海关历史底蕴较为充足,吸引了众多游客慕名而来。主题二中包含景点、不错、感觉、雄伟、气势等五个特征词。故将主题二概括为“景点体验感受”,主题二中气势、雄伟用来形容山海关整体留给游客的印象,历经百年历史的山海关在这部分游客的眼里显得更加的雄伟、气势、壮观。主题三中包含门票、导游、身份证、网上、方便等五个特征词。故将主题三概括为“景点服务”,主要反应景点取票、进出等服务的便利性以及导游讲解服务。旅游业作为服务业,就是要以服务立身,服务质量是影响游客印象的关键所在,只有景点服务到位、贴心,才会打造良好的旅游形象,吸引更多的游客前来游玩进而增加景点收入。主题四中包含晚上、灯光、表演、游玩、值得等五个特征词。故将主题四概括为“景点趣味性”,值得注意的是,主题四中出现了体现游客情感倾向的特征词“值得”,可以看出游客对山海关景区的夜景、表演很满意,山海关景点夜景灯光秀以及传统文化表演是吸引旅游者的重要因素。
Table 8. Positive comments on potential topics
表8. 正面评论潜在主题
至此,本研究第二个目标也顺利实现。
6. 总结及建议
6.1. 结论
游客评论文本的分类效果:本文构建了LR、NB和LSTM三个文本分类器模型,通过综合比较各机器学习模型,得出结论:LSTM模型表现最佳,准确率为92.15%,传统机器学习模型也表现不俗,其中LR模型准确率为89.54%,NB模型次之,准确率为87.73%。LSTM分类模型可以实现对游客评论文本的精确分类,可以考虑在线上推广使用,解决旅游平台文本分类不准确的问题。
游客评论文本的情感分析:针对该旅游景点游客评论文本,使用训练好的逻辑回归模型分析了游客对景点的情感倾向,统计得到游客积极评论占比79.6%,消极评论占比20.4%,说明游客对山海关景区整体感受是满意的。
游客评论文本的LDA主题聚类分析:对分好类的文本构建了LDA主题聚类模型进一步提取游客关注点,发现游客的不满意主要集中在景点收费管理、景点基础设施方面,对景点的服务、体验感受、趣味性比较满意。
6.2. 建议
6.2.1. 针对游客建议
山海关景区整体留给游客的印象多是雄伟、气势、壮观,来此地游玩游客获得了极大的满足感和幸福感;同时,部分游客在评论中表示景点的取票很方便,还着重提到了导游解说很专业,服务很到位,使自己的游玩体验很棒,也有部分游客对于山海关景区的夜景以及灯光表演留连忘返,对于喜欢历史文化景点又注重服务体验的游客,山海关景区会是个不错的选择。
6.2.2. 针对景点建议
景区应该关注游客需求,完善基础设施,增加检票闸机,景区还需要常备一些口罩医疗物资,做好防疫措施,保证游客安全游玩,采取预约参观形式,设置阻隔带,合理安排人流。增加公共停车位,统一管理收费制度,集中整治收费乱象,保证游客游玩体验。在旅游资源的开发中应更加注重历史文化的挖掘以及历史底蕴的展现,注重打造历史文化品牌,才更好地吸引游客前来游玩,不能单纯靠“牌子”。