1. 引言
随着科技时代的发展与变迁,当今的世界,已经从网络时代迈向了数据时代。众所周知,互联网打破了人们获取信息的传统方式,使得人们能够从网上轻松便利的获取信息;然而当走进数据时代时,面对大量的数据,人们的需求和喜好在某些方面不明确时,人们大多是漫无目的的在接受或寻求信息,这不仅没有节省人们的时间,反而会消耗更多的精力和时间去过滤这些超载的信息,这种现象称为“信息过载”。面对信息过载 [1],消费者如何更高效的找到对自己有用的信息呢?生产信息的平台如何推出更加适合用户需求的信息呢?
推荐算法由此而生,推荐算法就是利用用户与物品的交互数据,通过一些数学算法,推测出用户可能喜欢的东西。推荐算法主要分三种,分别是:基于内容、协同过滤和混合推荐算法,其中研究最多的是协同过滤,协同过滤中的算法非常丰富,本文主要研究的是隐语义模型算法,隐语义模型是推荐算法中最常见的一个算法 [2],该算法使用的是用户的历史评分和用户的交互信息,挖掘出数据中用户及物品隐含的特征,然后推荐出用户个性化的数据。
在传统的隐语义模型中,都是根据用户的反馈数据进行建模,训练一次可能需要更大的训练维度和更高的复杂度 [3],并且上下文信息使用率很低,尤其是时间信息;在实际生活中,人们对事物的兴趣很可能会跟随时间的推移而出现变化,当不考虑时间信息的时候,很可能对推荐结果产生影响,推荐的准确率就不一定满足人们的实际需求了。本文结合了时间信息,将时间差定义为逾期因子,改进了传统的隐语义模型,降低了训练维度,降低了训练复杂度,提升了训练速度,减小了误差,同时也提高了推荐的准确性。
2. 基于隐语义模型的推荐算法
隐语义模型又名为隐因子模型(latent factor model,简写LFM) [4],属于协同过滤算法的一种。它先基于矩阵分解算法建立潜在因子模型,再依据机器学习和优化理论处理评分矩阵,从而获取用户的潜在特征并预测用户对未评分物品的评分 [5]。
假设存在n个用户和m个物品,先获取每个用户对每个物品的评分,构建出一个评分矩阵Rn×m。而LFM是在设置特征的维度K后,寻找两个低维矩阵Pn×k和Qm×k,分别将其作为用户和物品的特征矩阵,再通过对特征矩阵相乘得到预测的评分矩阵
。在为用户推荐时,根据用户对每个物品的预测得分进行降序排序,选出前N个当前用户未评分的物品推荐给用户 [6]。
为了使预测的结果更加精确,需要不断迭代改变维度K和矩阵Pn×k和Qm×k的值。本文使用平方损失函数cost来量化预测评分矩阵与实际评分矩阵的差别,其计算公式如下:
(1)
为了防止过拟合的情况出现,本文在损失函数的基础上增加了正则化项,修正后的损失函数如下:
(2)
其中Rui表示第u个用户对第i个电影的评分,Pu表示第u个用户的特征向量,
表示第i个物品特征向量的转置,λ表示正则化系数。
为使损失值降低,推荐结果更加精准,本文采用梯度下降法进行迭代,不断迭代用户特征矩阵Pn×k和物品特征矩阵Qm×k,本文实验中的迭代次数为10,000次,根据实验结果得知,预测矩阵
已经取得最优值。用梯度下降法进行迭代的公式如下:
(3)
(4)
其中α表示学习率,即梯度下降的步长;
表示损失函数cost对用户特征矩阵P求偏导;
表示损失函数cost对物品特征矩阵Q求偏导。
3. 改进的隐语义模型算法
3.1. 对数函数
对数函数是6类基本初等函数之一。一般地,函数y = logax叫做对数函数,其中x是自变量,a为底数 [7]。当a > 0时,对数函数是单调递增函数,且其斜率逐渐减小,在趋于无穷大的时候,其斜率趋于0,函数值将趋于一个固定值。根据这一特性,结合时间信息对梯度下降函数中步长的影响,即时间间隔越久,逾期因子越大,对推荐结果影响越小,对应步长应该增大,当逾期因子越来越大的时候,对应步长应该趋于一个固定值。
本文中底数为e,e的定义为:
本文采用的对数函数是以e为底,逾期因子为自变量x的对数函数,以e为低的对数函数的可表示为Ln(x),其图像如图1所示:
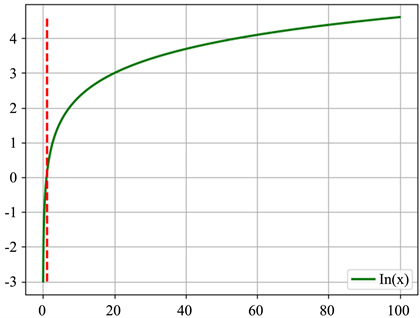
Figure 1. y = Ln(x) function image
图1. y = Ln(x)函数图像
3.2. 反比例函数
一般的,如果两个变量x,y之间的关系可以表示为y = k/x (k为常数,k ≠ 0,x ≠ 0),其中k叫做反比例系数,x是自变量,y是x的函数。当k > 0时,图像在一、三象限;当k < 0时,图像在二、四象限。k的绝对值表示的是x与y的坐标形成的矩形的面积 [8]。当k > 0,且x > 0的时候,反函数在第一象限是单调递减,且斜率逐渐增大,当x趋于无穷时,斜率趋于0,函数值趋于0;根据这一特性,结合逾期因子对正则化系数的影响,即逾期因子越大,过拟合的影响就越小,正则化系数对应的应该减小;当逾期因子趋于一个无穷大的值时,正则化系数应该趋于0。
本文中令k = 1,逾期因子为自变量的函数,可表示为y = 1/x,其图像如图2所示:
3.3. 改进的隐语义模型
根据对数函数和反比例函数的函数特性,融合逾期因子,构造出改进的隐语义模型。令逾期因子为
,其对应的损失函数为:
(5)
对应的梯度下降公式可更改为:
(6)
(7)
4. 实验结果分析
4.1. 平均绝对误差
平均绝对误差(Mean Absolute Error,简称MAE),它是所有单个观测值与算术平均值的偏差的绝对值的平均 [9]。平均绝对误差可以避免误差相互抵消的问题,因而可以准确反映实际预测误差的大小。平均绝对误差可表示为:
4.2. 均方根误差
均方根误差(Root Mean Square Error,简称RMSE),它是预测值与真实值偏差的平方与观测次数n比值的平方根,在实际测量中,观测次数n总是有限的,真值只能用最可信赖(最佳)值来代替 [10]。均方根误差可表示为:
4.3. 实验结果比较
本次实验使用MovieLens数据集,利用平均绝对误差、均方根误差和损失函数值作为评价指标,分别对传统的隐语义模型和改进隐语义模型算法进行训练、计算,最终统计出对比结果。如图3~5所示,其中绿色线代表传统隐语义模型,蓝色线代表改进的隐语义模型,对应图中横轴表示K值大小,竖轴表示对应的结果值。
根据图3和图4所示,改进隐语义模型算法的平均绝对误差和均方根误差均比传统隐语义模型下降的快,并且能够在保证优先找到最小K值的前提下,对应误差值减小到最小值后保持不变,且改进的隐语义模型比相同K值下的传统隐语义模型误差要小。
根据图5所示,改进隐语义模型算法的损失值比传统隐语义模型的损失值相差无几,但改进的隐语义模型能够优先找到最小K值,并且优先达到最小损失值。

Figure 3. Mean absolute error comparison chart
图3. 平均绝对误差对比图

Figure 4. Root mean square error comparison chart
图4. 均方根误差对比图
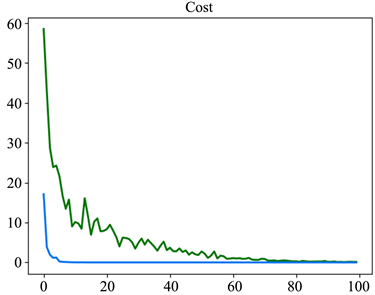
Figure 5. Loss function comparison chart
图5. 损失函数对比图
5. 结论
根据上述分析,改进的隐语义模型算法,降低了训练维度,降低了训练复杂度,同时提升了训练速度,降低了训练误差。 此次研究改进隐语义模型算法有效的提高了传统的隐语义模型。