1. 引言
空气污染预报可指导生产、为防止重大污染事件的发生,减轻污染事件的危害程度起重大作用,空气污染预报是根据气象条件和污染源排放情况对某个区域未来的污染物浓度及空间分布发出预报。按内容可分为两类:一是空气污染气象预报,另一种是空气质量预报,空气质量预报是对各种空间尺度上污染物浓度时空分布以及污染物的输送和演变后的污染物浓度范围做出预报。
空气质量预测技术方法能够提前预测区域空间内的大气污染物浓度,其发展十分迅速 [1]。祁柏林等提出了一种基于GCN和LSTM的空气质量预测模型 [2]。宋宇辰、甄莎运用BP神经网络法和时间序列法,对包头市的二氧化硫、二氧化氮和可吸入颗粒物的年份浓度值和月份浓度值进行预测 [3]。黄思将多模式集合预报和多元线性回归集成方法结合起来减小空气质量预报的不确定性 [4]。周广强等介绍了基于WRF-Chem在线区域化学传输模式和INTEX-B与MEIC人为源排放清单建立的华东区域大气环境数值预报业务系统 [5]。近五年来,中国科学院大气物理研究所(简称大气所)在大气环境数值模拟方面取得了丰硕的成果,通过自主发展和引进,建立了完备的多尺度、多成分的大气环境数值模式,包括全球大气化学输送模式、区域和城市空气质量预报模式 [6]。
频繁发生的大气污染事件严重影响人民生活,能够较为完整和准确地反映气象、源排放以及其它物理化学过程影响的数值预报方法是开展大气污染预报的重要手段,如果能够实现模型的优化,降低各种参数的不确定性,将对人民生活提供极大帮助。
2. 监测点A自2020年8月25日到8月28日实测AQI值和首要污染物
2.1. 数据预处理
提取2020年7月23日至2021年7月13日实测数据进行预处理,变量值缺失和异常值采用拉格朗日插值处理法,用均值法将样本数据从逐小时处理为逐日数据,见图1所示。
2.1.1. 不良数据处理
1) 数据少量缺失或出现异常值(如SO2中含有负值等情况)
采用拉格朗日插值多项式,来对缺失值和异常值进行补充和替换。
2) 大量或整行数据缺失
a) 不影响本题最终结果,题目所选样本中并不包含此情况。
b) 考虑样本量为十万量级,删除部分数据对之后整体预测结果影响较小。

Figure 1. Abnormal data processing flow chart
图1. 异常数据处理流程图
3) 数据单位不一致
CO单位不同于其他污染物单位,根据空气质量指数公式,判断单位不同,对计算结果没有影响。
2.1.2. 逐小时处理为逐日
1) 污染物和气象条件数据逐日处理
监测点A从0点开始每经过一小时监测一次,到23点一共24次。对除臭氧(O3)之外的其他五种污染物和气象条件数据进行均值处理。选取数据样本时间跨度为2020年7月23日至2021年7月13日。得到均值公式如下:
(1)
式中:
是指污染物质量浓度或气象条件数据的均值n是指该天的实际监测次数。
2) 臭氧(O3)数据处理
臭氧(O3)指一个自然日内8时至24时的所有8小时滑动平均浓度中的最大值,其中8小时滑动平均值指连续8小时平均浓度的算术平均值。与计算环境空气质量指数(AQI)相关。
(2)
其中,
为臭氧在某日
时至t时的平均污染物浓度
如果计算得到的臭氧(O3)最大8小时滑动平均浓度值高于800 μg/m3的,就不再进行其空气质量分指数计算
每天都可得到17个臭氧(O3)最大8小时滑动平均的值。再将处理结果进行均值处理,公式如下:
(3)
其中:
是指基于最大8小时滑动平均的均值。
2.2. 计算空气质量指数
首先需得到各项污染物的空气质量分指数(IAQI),其计算公式如下:
(4)
式中:IAQIP是指污染物P的空气质量分指数,结果进位取整;CP是指污染物的质量浓度值;BPHi,BPLo是指与CP相近的污染物浓度限值的高位值与低位值;IAQIHi,IAQILo是指相对应的空气质量分指数。除臭氧(O3)以外的,其余污染物浓度高于IAQI = 500对应限值时,就不再对其进行其空气质量分指数计算。
最后提取逐日样本数据中跨度2020年8月25日到8月28日,利用公式(4),得出4天AQI值。
2.3. 结果分析

Figure 2. Diurnal variation of air quality index
图2. 空气质量指数日变化图
由图2分析比较可知,四天中六种污染物IAQI值最高的始终是臭氧(O3),说明臭氧是影响空气质量等级的关键因素。

Table 1. AQI value and primary pollutant of the day
表1. AQI值及当天首要污染物
通过计算得到的AQI值见表1与空气质量等级对应的AQI范围,可知2020年8月25日的空气质量等级为良,存在首要污染物为臭氧(O3);2020年8月26日的空气质量等级为优,无首要污染物;2020年8月27日的空气质量等级为轻度污染,存在首要污染物臭氧(O3),同时它也是当天的超标污染物;2020年8月28日的空气质量等级为轻度污染,存在首要污染物(O3),同时它也是当天的超标污染物。
3. 基于污染物浓度影响程度的气象条件分类
3.1. 问题分析
预报数据中存在15个气象条件,为了更好看出气象条件与污染物浓度的关系,对气象条件进行降维处理,通过数据样本,建立气象条件与污染物浓度关系方程。由关系系数可知,气象条件分别对各个污染物浓度的影响程度,可以判断出哪些气象条件有利于污染物扩散或沉降,使得该地区的AQI会下降。
为了合理的气象分类,计算得出所有时间AQI的值,使用预报中15个气象条件、六个污染物浓度和相对应的AQI进行无监督聚类分析,然后得出气象分类、相对应污染物浓度的范围和AQI的范围,最后对各类气象条件数据进行分析阐述,如图3所示。

Figure 3. Meteorological classification flow chart
图3. 气象分类流程图
3.2. 气象条件对AQI的影响
灰色关联度分析(GRA算法)
灰色关联度分析(Grey Relation Analysis, GRA),是一种多因素统计分析的方法。简单来讲,就是在一个灰色系统中,我们想要了解其中某个我们所关注的某个项目收其他因素影响相对强弱。
将之前处理完成的逐日预报数据输入GRA算法,得出气象条件分别与污染物浓度的关联度,如图4所示。
通过对上述六个图形的观察比较,选出了五种气象条件与污染物浓度关联较大,包括地面太阳能辐射、大气压、边界层高度、雨量、短波辐射。
将之前处理完成的逐日实测数据输入GRA算法,得出气象条件分别与污染物浓度的关联度,如下图5所示:
臭氧(O3)对空气质量指数影响最大,然后通过图5分析,风向和温度与臭氧(O3)关联度大,由此,可得出风向和温度与空气质量关联度大。
3.3. 多元线性逐步回归算法
1) 模型
多元线性回归分析模型为:
(5)
式中:
是指回归系数(与
无关);
2) 参数估计
利用模型式的参数
用最小二乘法估计,最后经计算可得残差平方和:
(6)

Figure 4. Correlation diagram of predicted meteorological conditions and pollutant concentrations
图4. 预测气象条件与污染物浓度的关联度图

Figure 5. The correlation between measured meteorological conditions and pollutant concentration
图5. 实测气象条件与污染物浓度的关联度
3) 统计分析
a)
的线性无偏最小方差估计;
的期望等于
,在
的线性无偏估计中,
的方差最小。
b)
服从正
(7)
3) 对残差平方和Q,
且
(8)
由此得到
的无偏估计
(9)
其中,
是指剩余方差(残差的方差)
S是指剩余标准差。
4) 对总平方Q进行分解,有
(10)
其中,Q是指残差平方和,反映随机误差对y的影响;U是指回归平方和,反映自变量对y的影响。利用上面灰色关联度分析,得出与预测数据污染物浓度相关的五种气象条件,利用多元线性逐步回归算法,实现气象条件与污染物浓度的回归方程。
Table 2. Correlation coefficient between predicted meteorological conditions and pollutant concentrations
表2. 预测的气象条件与污染物浓度的相关系数
通过表2的比较分析,判断依据是有利于的话,必须是负相关,且越小越好。气象值越大,浓度越小,则空气质量越好,所以得出短波辐射是最有利于污染物扩散或沉降,使得该地区的AQI会下降;判断依据是不利于的话,必须是正相关,且越大越好。气象值越大,浓度越大,则空气质量越差,所以得出地面太阳能辐射是最不利于污染物扩散和沉降,使得该地区AQI会上升。
实测数据中与污染物浓度相关五种气象条件的相关系数见表3,利用多元线性逐步回归算法,实现气象条件与污染物浓度的回归方程。
3.4. K-Means聚类
EM (Expection-Maximun)算法是最常见的隐变量估计方法。EM算法是一种迭代优化策略,每一次迭代都分为两步:期望步(E)、极大步(M)。EM算法的提出最初是为了解决数据缺失情况下的参数估计问题,
Table 3. Correlation coefficient between measured meteorological conditions and pollutant concentration
表3. 实测的气象条件与污染物浓度的相关系数
聚类属于非监督学习,K均值聚类是最基础常用的聚类算法,它的基本思想是,通过变量不断迭代寻找K个簇的一种分类方案,可以使聚类结果对应的损失函数最小,所以本文采用基于EM算法的K-Means聚类算法。
气象条件、污染物浓度和AQI聚类
使用预测驻日数据表中所有的值,包括气象条件和污染物以及所有天数的AQI,输入基于EM算法的K-Means聚类算法,得到如下图6:
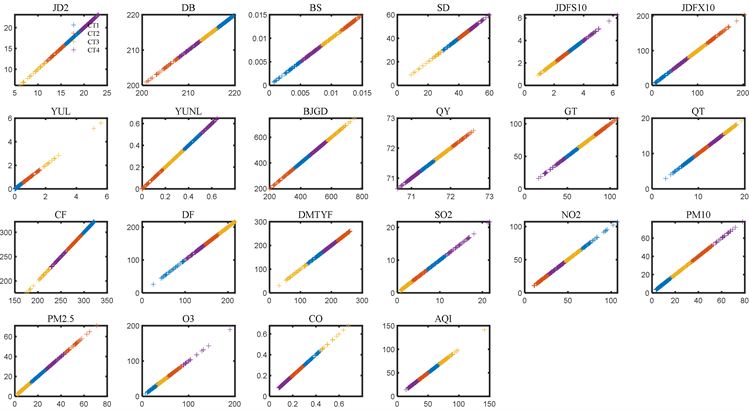
Figure 6. Predicted meteorological conditions, pollutant concentrations, and AQI cluster graphs
图6. 预测的气象条件、污染物浓度和AQI聚类图
分类结果见表4:
1) 对于第一类气象,空气质量等级是良;
特征:近地2米温度、地表温度、长波辐射、NO2浓度处于较高的范围内,气温较高,辐射大。
2) 对于第二类气象,空气质量等级小部分处于优,大部分是良;
Table 4. Table of pollutant prediction, meteorological concentration range and AQI value in four types of meteorology
表4. 预测四类气象中污染物、气象浓度范围与AQI值表
特征:近地10米风向、地面太阳能辐射、PM 2.5浓度处于较高的范围。
3) 对于第三类气象,空气质量等级基本是一半轻度污染,一半中度污染;
特征:边界层高度、潜热通量、短波辐射处于较高的范围。
4) 对于第四气象,空气质量等级是优。
特征:湿度、雨量、O3浓度处于较高的范围,在这种气象下,会感到很舒服。
4. 二次预报模型
目前常用WRF-CMAQ模拟体系对空气质量进行预报。WRF-CMAQ模型主要包括WRF和CMAQ两部分:WRF是一种中尺度数值天气预报系统,用于为CMAQ提供所需的气象场数据;CMAQ是一种三维欧拉大气化学与传输模拟系统,其根据来自WRF的气象信息及场域内的污染排放清单,基于物理和化学反应原理模拟污染物等的变化过程,继而得到具体时间点或时间段的预报结果。
但受制于模拟的气象场以及排放清单的不确定性,以及对包括臭氧在内的污染物生成机理的不完全明晰,WRF-CMAQ预报模型的结果并不理想。故本文在WRF-CMAQ等一次预报模型模拟结果的基础上,结合更多的数据源进行二次建模,以提高预报的准确性。其中,由于实际气象条件对空气质量影响很大,如湿度降低有利于臭氧的生成,且污染物浓度实测数据的变化情况对空气质量预报具有一定参考价值,故目前会参考空气质量监测点获得的气象与污染物数据进行二次建模,以优化预报模型。
4.1. 卡尔曼滤波算法
卡尔曼滤波(Kalaman filtering)一种利用线性系统状态方程,通过利用系统输入输出监测数据,然后对系统状态进行最优估计的算法。而在监测数据中会存在系统中噪声和干扰的影响,所以最优估计也可以看成进行滤波的过程。
4.1.1. 基本原理
对一个线性离散是不变系统,系统方程:
(11)
(12)
其中,x(k)为k时刻的状态向量;u(k)为k时刻的输入;w(k)为k时刻的归一化过程噪声;y(k)为k时刻的输出,反馈误差校正的核心;v(k)为测量噪声,一般为传感器的漂移。
已知卡尔曼滤波算法由两个过程,包括预测和校正,在预测阶段,滤波器上一状态的估计,做出对当前状态的预测,在校正阶段,使用对当前观测值进行修正进而校准当前预测值,实现综合测量值和预测值的一个最优值。
4.1.2. 模型优化
通过上面建立的二次预报模型,预测未来三天污染物浓度数据,题目中要求预测2021年7月13日至7月15日A点这三日的数据,而采用不同的数据样本截点,则会在同一时间产生三种值,如将样本数截点到12号,会产生13,14,15号数据;将截点到11号,则会产生12,13,14,因为样本量不同,导致迭代次数不同,必然导致两次数据处理结果,选择哪组样本数据结果,才更接近真实值。我们对监测点A选择从7月9号至7月12号,通过改变数据截点,产生总共三个数据是对7月9日的预测,最后通过数据可视化将三个数据同时于真实值进行比较。如图7所示:
通过比较,发现模型预测的第二天数据与真实值误差最小,最为准确。
采用优化后的模型,预测A点SO2与CO的31天样本数据如图8,进行数据可视化,发现优化后的二次预报模型产生的数据远比一次预报模型产生很的数据更接近真实值。所以得出结论二次预报模型优于一次预报模型。
5. 结语
1) 针对数据的处理,使用了多种数学原理和计算机软件。利用matlab软件将以小时为单位的数据转化为以天为单位的数据,并准确地算出了要求日期的AQI和首要污染物。
2) 使用了灰色关联度分析和逐步回归方程,找出了对污染物浓度较大的气象条件;使用了K-Means聚类把气象条件分为了4大类,并且说明了这4类各自的特点。
3) 建立了卡尔曼滤波预报数据的模型(二次预报模型),该模型可以对参数进行更新和修正。第一次预测了部分数据,通过对数据的分析和处理,得到了模型的预测规律。通过该发现,用90%的数据进行预测,剩余10%的数据进行验证,证实了模型的准确性。

Figure 8. Forecast value and measured value of point A
图8. A点预报值与实测值
本文在一次预报模型模拟结果的基础上,结合更多的数据源和参考空气质量监测点获得的气象与污染物数据进行二次建模,使得二次预报模型的准确性相比于一次预报模型大大提高。其次设计了可行的方法对原始数据进行预处理。二次预报模型使用了卡尔曼滤波算法,能够不断对参数进行更新和修正,从而实现对数据的合理筛选,有了一定的鲁棒性和泛化能力。