1. 引言
新型冠状病毒肺炎是一种严重的急性感染性肺炎,简称为新冠肺炎,可以在人与人之间进行传播 [1] [2]。截至2020年4月,中国的疫情基本得到控制 [3]。自2020年4月以来,中国一些地区多次出现散发病例引起的聚集性疫情。例如,2021年1月2日,河北省石家庄市卫生健康委员会通报了新冠确诊病例(http://wsjkw.hebei.gov.cn)。第二天,邻近的南宫市也确诊了一例新冠阳性患者,随后确诊病例逐渐增加,直到一月底疫情才得以控制。而由于疫情溯源工作复杂,导致统计到的数据不完整。因此,寻找完整的疾病传播网络,是有待解决的问题,链路预测为解决此问题提供了新的角度。
链路预测是通过计算网络中两个没有接触的病例之间产生链接的可能性,来补全疾病传播网络。近年来,复杂网络的链路预测在传染病研究中得到了广泛的应用。例如:吕琳媛等在文献 [4] 中对链路预测的精确度指标和链路预测算法等进行了综述;樊洁茹等 [5] 利用随机分块模型的链路预测算法来预测网络中丢失的边和错误的边,得到更完整的活羊调运网络,为控制该疾病的传播和制定有效的防控措施提供了理论依据;Kaya等 [6] 提出一种基于年龄序列的链路预测算法,表明了病人的年龄与疾病的传播有一定的相关性;McCoy等 [7] 在现有的新冠肺炎的数据集上,利用链路预测算法有效地提取出与新型冠状病毒高度相关的药物;Folino等 [8] 运用一种基于链路预测的方法,考虑网络节点之间的结构相似性来识别患者未来可能会患的疾病。总之,链路预测包含对未知连边的预测,也包含对未来连边的预测,在网络缺失边的预测上有十分重要的意义。
网络的拓扑特征指标能够通过收集到的数据集来量化出网络结构信息,对于这方面的应用也有很多。例如:2016年Relun等 [9] 在国家和社区层面计算了生猪交易网络的度、密度、聚类系数和平均路径长度,为预防和控制生猪的未来疾病的入侵提供了很好的方法;2017年Lichoti等人 [10] 通过计算度、模块化和聚类系数来描述关键的网络属性,表明整个生猪交易网络是比较稀疏的;2021年Jing等人 [11] 通过计算真实网络和重构网络的平均度、网络密度和聚类系数等拓扑特征,得出在重构后的网络指标表现良好;以及2021 年Kuang等人 [12] 在研究基本拓扑特征后,又通过计算各种中心性指标,来找出重要节点和连边。简言之,网络的拓扑特征对研究网络的性质有很重要的意义。
通过链路预测来补全网络对于研究新冠肺炎病例的传播途径有重大意义。本文首先运用基于局部信息的相似性指标进行链路预测,选择出AUC (Area under the receiver operating characteristic curve)值较高的资源分配指标(RA指标)来重构网络,然后通过对拓扑指标进行分析来研究重构前后网络的特征,给出有效的关键病例和路径,为制定快速的防控措施提供了理论依据。
2. 初始网络构建
2.1. 数据来源
自2019年12月以来,新型肺炎疫情在中国蔓延。例如,河北省石家庄市于2021年1月2日发现确诊病例,河北省多个城区也相继发现病例。此后,南宫市3日也出现了新冠肺炎确诊病例,直到27日,南宫市的新冠肺炎疫情才得到控制。本文使用的数据为中国南宫市(2021年1月3日至1月27日)确诊病例的信息。河北省卫生健康委报告确诊病例68例。有关这些病例的数据可在官方每日报告(http://wsjkw.hebei.gov.cn)中获得,包括年龄、性别、与其他已知病例的关系、确诊病例的诊断日期、密切接触者、地理位置和旅行轨迹。由于大规模追溯性调查难以在短时间内进行,导致统计数据不完整。
2.2. 数据预处理
将通报到的信息和数据进行整理,清理了主要信息中不可用的信息。例如,新冠病毒的潜伏期为3~7天,最长不超过14天,病毒在潜伏期内也是具有传染性的,于是只保留病例被确诊前的1~14天的行程轨迹。
数据的预处理即求出所需地理位置的经纬度,进行距离的计算。先从百度地图数据库提取出所有所需地点的名称和位置信息,后使用以下方程(1)计算位置A和位置B之间的距离AB,
和
是位置A和B的经度;
和
是位置A和B的纬度,R是赤道半径 [13]。
(1)
2.3. 初始疾病传播网络构建
将疾病传播网络抽象为无向网络,该网络共有68个病例,以官方通报数据的时间先后为序,对南宫市这波疫情开始至结束(即2021年1月3日至1月27日)的所有病例进行编号。在疾病传播网络中病例看作网络的节点,病例间的接触看作网络的边,并做出如下假设:
1) 根据官方通报的接触信息,有具体的直接接触信息的,则两节点之间存在一条连边;
2) 病例间有共同居住或14天内有来往的亲密接触者,节点之间存在一条连边;
3) 在14天内两病例去过同一个地方,如酒店、商场和公司等,将视为有连边;
4) 根据距离,位于南屯村的56号节点未给出具体的出行路线与密切接触者,于是连边以两地之间的距离为依据进行连接,规定距离在3.5公里之内的两例病例进行连接(3.5公里是该病例所在位置与其他病例所在位置的最小值) [14]。
根据上述假设,将疾病传播网络的246条连边记录在邻接表中,然后运用R语言的igraph包的可视化图形工具绘制南宫市的疾病传播网络,如图1所示。
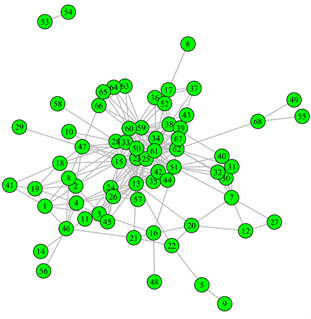
Figure 1. The disease transmission network graph of Nangong City
图1. 南宫市疾病传播网络
3. 链路预测
3.1. 数据集的划分和评价指标
本文研究病例接触的无向无加权网络,
为疾病传播网络,V表示病例节点集合,E表示链接集合,用 表示包含所有
个可能链接的集合,用
表示集合V中元素个数。假设给定一种链路预测算法并得到未连接的链接的相似值,将这些相似值进行从大到小排序,排在越前面表示该连边在网络中出现的概率越大。为了测试算法是否准确,将链接E随机分为测试集
和训练集
,满足
且
,并将属于U但不属于E的链接定义为不存在的链接。
对于数据集的划分,选择随机抽样,这种算法保证了被选择到训练集和测试集中的链接是随机的,没有人为因素的干扰。通过吕琳媛等人 [4] 在综述中的叙述,本文采用从整体上衡量算法精确度的指标AUC来衡量指标的精确度。其中n表示n次循环抽取,且有
次
中链接的相似值大于不存在的链接的相似值,
次两者相似值相等,具体定义如下:
(2)
3.2. 基于局部信息的相似性指标
针对南宫市的疾病传播网络,本文基于网络拓扑结构的局部相似性指标对网络进行预测。下表1给出经典的十种局部相似性指标及其定义,两节点设为
和
,定义
邻居的集合为
,
邻居的集合为
,kx是节点x的邻居的个数。

Table 1. Similarity index based on local information
表1. 基于局部信息的相似性指标
3.3. 相似性指标的算法描述
根据疾病传播网络的结构信息,本文采用基于局部信息的相似性指标进行分数值计算,并采用AUC作为评价指标,对上述指标的预测精确度进行对比分析,从而找出预测效果最优的指标。在实验过程中,我们以90%的比例随机地抽取训练集网络进行预测。算法流程主要分为:邻接表和邻接矩阵的转化;相似值矩阵的求解;AUC值的计算。详细的算法描述见表2。

Figure 2. 2021 COVID-19 transmission network reconstruction graph
图2. 2021年新冠疾病传播重构网络
3.4. 南宫市新冠肺炎疾病传播网络重构
疾病传播网络的网络重构 [25] 表示针对现有的疾病传播网络中连边不全问题,运用链路预测的方法,通过对网络的拓扑结构以及节点属性的分析来挖掘网络中隐藏的关系。即对未知节点对之间预测的分数值大于0的边的连接以及已知链接中可能出现的错误链接的修正,得到更加真实,更能反映病例之间相互影响关系的网络结构。具体做法如下:
通过上一节的算法流程,计算出十种基于局部信息的相似性指标的AUC值,见表3,RA指标的预测精确度明显高于其他九种指标。于是,运用MATLAB软件,采用计算得到的最优链路预测指标RA对网络进行预测,得到测试集和不存在的链接的分数值。若两病例之间的分数值为0,那么这两病例的连边概率为0,不进行连边;若分数值大于0,那么将两病例进行连接。依此,就得到一个新的重构完的邻接表,运用R语言就得到重构完的疾病传播网络,共有68个节点,818条连边,如图2所示,图中红色的边是初始网络的边,灰色的为新添加的边。与初始网络相比,重构完的网络多了300多条边。由于在实际调查的过程中,家庭内部传染经常被忽略,行踪轨迹也不可能记录完全,导致缺失很多实际的病例接触。
Table 3. Comparison of link prediction AUC index
表3. 链路预测AUC指标比较
4. 网络拓扑特征分析
通过链路预测算法,补充了网络中缺失的372条连边,构造出疾病传播的重构网络图。本节对重构前和重构后的疾病传播网络进行拓扑特征分析,选取网络密度 [26]、平均路径长度、聚类系数 [27]、同配系数 [28]、节点度中心性 [29]、节点接近中心性 [30]、节点特征向量中心性 [31] 和边的介数中心性 [32] [33] 等统计特征指标研究疾病传播网络的拓扑性质。以上所说的拓扑特征指标运用R语言(4.0.3版本)中的igraph包来拓扑分析。
4.1. 疾病传播网络的全局拓扑特征
表4给出了本文所研究的相关的拓扑特征的定义以及疾病传播网络重构前后的值,
表示节点数,
表示连边数,
表示网络密度,
表示网络的平均路径长度,c表示网络的聚类系数,r为同配系数。箭头表示重构网络与初始网络相比,各指标的变化情况,
表示数值增加,
表示数值降低。
图3给出了疾病传播的原始网络的度分布图 [34],其中横坐标k为度值,纵坐标
表示度为k的节点数比上整个网络节点数的值。图中可以看出,疾病传播网络的度分布是近似地遵循幂的形式 [35],即
,
为幂指数,说明了疾病传播网络具有异质性和无标度网络特性。具体表现为对于大多数病例具有较少的接触病例,只有少数病例具有较多的病例接触。了解到原始的疾病传播网络拥有这一特性之后,在此基础上,我们详细分析和对比网络在重构前与重构后的描述性指标。
Table 4. Relevant definition and value of topological features
表4. 拓扑特征的相关定义及值大小

Figure 3. Degree distribution graph of the original network of disease transmission
图3. 疾病传播原始网络的度分布图
南宫市病例传播的原始网络的网络密度为0.0538,对于一个病例数为68的网络来说,这个密度是相对偏小的。而重构网络的密度达到0.1793,比原始网络的密度增加了2倍。一方面,由数据监测发现,天一酒店、华座超市、信发商厦、信和商厦、联通公司和凤岗这几处为统计过程中出现频率最高的地方,过半数病例都在这几个地方活动,表明病例接触比较密切;另一方面,疾病传播网络的链路预测就是通过预测缺失边来补全网络,即通过补全缺失边导致网络密度增高。
从表4可知,原始网络与重构网络的同配系数均为负,即拥有较多接触者的病例趋向于与有较小接触者的病例连接。而重构前后的网络的异配性却存在较大的差异,重构后的网络的异配性是明显低于重构前的网络,且同配系数是接近于0的。由于在南宫市1月3日发现确诊病例开始,政府出台了一系列的政策和防控措施;1月7日,南宫市的天地名城小区、天一和院小区和凤岗办事处列为中风险地区;1月8日,要求全市居民居家7天;1月10日,政府发出工作地过年的通知。这一系列的防控措施使得疾病传播网络的疫情传播从1月中旬开始,就有了明显的确诊病例的下降,即网络的传播速度很小。这也证实了该网络就是非相关的网络,即同配系数趋于0。
对比重构前后的疾病传播网络,重构后的网络具有更高的聚类系数和更短的平均路径长度,这表示大多数病例不能直接相互连接,而是通过少量链接到达,这使得新冠肺炎疫情的前期,疾病能够在南宫市快速传播,这种拓扑性质也使得人群的持续感染,符合实际。在实际采取措施时,只能通过对接触者进行核酸检测进行快速甄别患者以达到控制传播的目的。
4.2. 疾病传播网络的重要病例
疾病传播网络中,寻找关键病例对于控制疫情传播是非常重要的。这类型的关键节点的分析可以有利于快速寻找病例的聚集地,为进一步控制疫情的传播节省了大量的时间和精力。测量节点在网络中的重要程度可以利用中心性指标进行分析。一般而言,度中心性分析是最简单和最直接的手段,而对于有相同数量接触者的病例来说,他们对于整个疾病传播网络的影响力与节点在网络中所处的位置有很大的关系。本文利用三种不同的中心性指标来寻找网络的关键节点,即度中心性指标(病例接触的越多,那么病例越重要);接近中心性(病例到网络中其他病例的距离的平均值越小,那么中心度越高)和特征向量中心性(病例的邻居节点越重要,则病例越重要)。
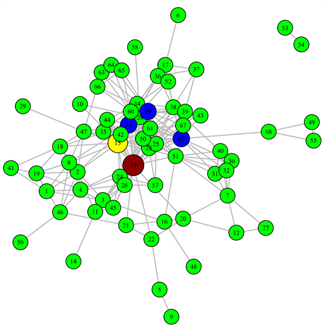
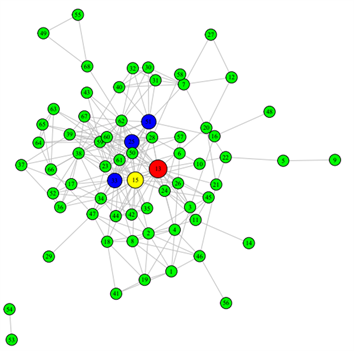
表5给出了重构前和重构后网络的三种中心性指标值(从大到小排列,括号内为该节点对应的中心性值)。由表可得,重构前后,节点v13的度中心性和接近中心性指标的值都是最高的,而特征向量中心性指标中最高的节点是v15,v13仅次于v15。通过分析通报的数据,发现排在前十的病例都曾去过信发商厦和信和商厦,且这两个商厦之间仅有一条街道(胜利街)作为分界线,周围有多个小区,医院等人群聚集地,这些都导致人员围绕这两个商厦大量流动;此外,1月10号确诊的v13病例,是轨迹描述中最早去信和和信发商厦的确诊病例,其次是v15病例。由上表可知,v13和v15这两例病例的三类中心性值都是最高的,表明:这两例病例是此次局部疫情的重要性节点;信和商厦和信发商厦是此次南宫市疫情的部分聚集地。于是在实际的措施采取时,可以针对这两地相关人员进行核酸检测来尽快缩小勘测范围;也可以看出,重构前后网络的重要性节点是没有发生大幅度改变的。表明之前围绕初始网络采取的一系列的隔离措施是有效的,这也是此次疫情在不到一个月的时间迅速控制的原因。从图4~6分别给出三种指标的疾病传播的无向网络图,左边部分为原始网络的中心性指标图,右边为重构网络的中心性指标图,图中最大的红色节点即为中心性指标最高的病例,依次按大小为排在第2位(黄色)和在第3~5 (蓝色)的病例。从图中也可以很容易观察到疾病传播网络中找到的重要性节点都在图中相对中心的位置,表明这些节点与其他节点的联系相对紧密,再一次证实这两处地点(信和商厦、信发商厦)为疫情的聚集地。
 (a)
(a)  (b)
(b)
Figure 4. Degree centrality index. (a) Degree centrality index before network reconstruction, (b) Degree centrality index after network reconstruction
图4. 度中心性指标分布图。(a) 网络重构前的度中心性,(b) 网络重构后的度中心性
4.3. 疾病传播网络的重要连边
此次南宫市疫情有明显的聚集性特点,存在病例之间的单位传播、家庭聚集传播、医院传染和社区传染等。以家庭聚集为例,家庭A和家庭B都患有新冠肺炎,那么连接A和B的那条链接在网络中的“桥梁”作用是至关重要的,否则,网络就是由一个个孤立的“块”组成。因此,对于网络中的边也与节点有类似的重要意义。下面用边的介数中心性来衡量网络中边的重要程度,其具体含义为最短路径中经过这条路径的数目占最短路径的总数目的比值。
 (a)
(a) 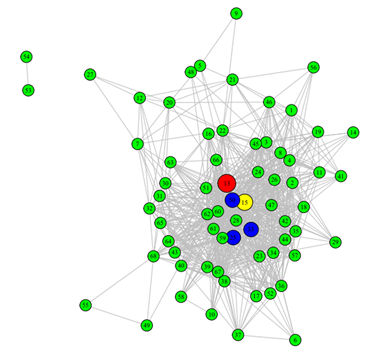 (b)
(b)
Figure 5. Closeness centrality index. (a) Closeness centrality index before network reconstruction, (b) Closeness centrality index after network reconstruction
图5. 接近中心性指标分布图。(a) 重构前接近中心性指标,(b) 重构后接近中心性指标
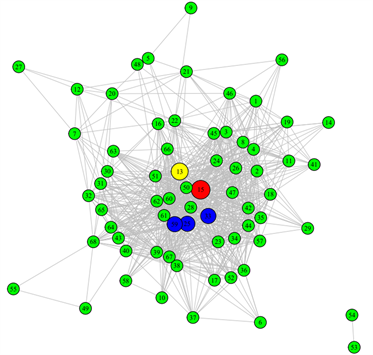 (a)
(a)  (b)
(b)
Figure 6. Eigenvector centrality index. (a) Eigenvector centrality index before network reconstruction, (b) Eigenvector centrality index after network reconstruction
图6. 特征向量中心性指标分布图。(a) 重构前特征向量中心性指标,(b) 重构后特征向量中心性指标
通过计算,重构前的网络边的介数中心性值从大到小排列,排在前面的五条边依次是
,而重构后的网络根据边的介数中心性值进行排序,依次是
。结合实际的连边数据,得出连边的两端节点(病例)分为两种类型:中心性指标较高的节点(重要节点),如v13,v62等;中心性指标较低的病例(边缘节点),如v49,v68等,这些病例分别位于石家庄村、西乞家庄村、青亭路、交警家属等,这些病例所处位置都相对比较偏远。这两类病例的连边都是疾病传播网络的边缘节点与中心性节点的重要“桥梁”,若是剔除这些连边,会出现多个孤立点,疾病传播网络的连通性将会有较大的变化。表明通过介数中心性指标找到的重要连边是合理的。图7给出了重构前后边的5条具有高的介数中心性值的边的无向网络图,图中红色标记的边为值最大的五条边。从图中,很容易看出,这些连边都是位于网络中心的节点和边缘节点的连边,证实了我们所找到的连边的重要性。
通过对节点和连边的中心性指标的分析和比对,较容易找出疾病传播网络的关键病例和关键链接。在实际的采取措施中,就针对这些病例以及聚集地给予相应的防控措施,对于关键连边,尽早切断一切传播路径,达到进一步快速控制疫情继续传播的目的。
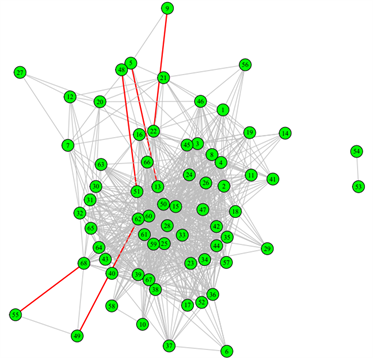 (a)
(a)  (b)
(b)
Figure 7. Edge betweenness centrality index. (a) Edge betweenness centrality index before network reconstruction, (b) Edge betweenness centrality index after network reconstruction
图7. 边的介数中心性指标分布图。(a) 重构前边的介数中心性指标,(b) 重构后边的介数中心性指标
5. 总结
2021年初,石家庄市发现新冠肺炎确诊病例,导致邻近的南宫市连续出现确诊病例。本研究以南宫市为例,分析疾病传播网络。首先,利用提取的数据构建疾病传播网络;其次,基于COVID-19病例的联系数据,通过AUC值对比,选取出资源分配指标(RA指标)进行链路预测,最终构建出疾病传播网络;最后,对重构前和重构后的网络进行拓扑指标的对比和分析,得出重构后网络较初始网络有更高的网络密度,更高的聚类系数以及更短的平均路径,表明大部分病例不能直接连接,而是通过少量边到达,这也是使得疾病在短时间内迅速扩散的原因。在此基础上,本文深入研究重构前后的重要节点和重要连边的变化,分别对节点的度中心性、紧密中心性和特征向量中心性进行计算,得出重构前后网络的重要性节点未发生变化,即第13号病例和第15号病例,根据接触信息现实,这两例病例是最早出现在聚集地的病例,证实所求出的重要性节点的正确性。对于重要连边,选择基于连通性的介数中心性指标进行计算,分别给出重构前后的5条重要链接,并证明若剔除这些连边,网络的连通性会发生很大改变。
这些结果为新冠肺炎的防控提供了很好的建议。比如,在新冠溯源调查时,通过快速控制重要节点,即对这些病例以及密切接触者采取隔离措施,以及通过快速切断这些有较高连通性的连边来使得疫情迅速控制在一个可控的范围内。综上,疾病传播的重构网络不仅适用于南宫市新冠疫情,也为研究其它地方的新冠疫情甚至其他疫病提供了一个很好的理论依据。
致谢
本文作者衷心感谢审稿人的意见;同时感谢其余两位作者对我的培养。
基金项目
本文受到国家自然科学基金(批准号:11801398;12101443)和山西省应用基础研究面上青年项目(批准号:201801D221024;20210302124260)的资助。
NOTES
*通讯作者。