1. 引言
随着科技的发展,信息传播的速度越来越快,各国之间的交流也是空前频繁,翻译作为一种文化交流活动,对讲好中国故事,让世界了解中国发挥了重要作用;同时让中国更好的了解世界也发挥了同等重要的作用。图书翻译是语言服务不可或缺的一部分。当前图书翻译的主要矛盾主要是落后的生产力和不断增加的图书翻译量之间的矛盾 [1]。信息传播速度加快对图书翻译最直接的影响就是要求在更短的时间内快速实现高质量翻译。这对译者提出了新的挑战,单纯依靠人工翻译显然无法适应当前翻译市场的需求,因此将翻译技术应用到图书翻译提高翻译的效率和质量就变得尤为重要和急迫。翻译工具已经成为翻译工作者赖以生存的武器 [2]。但受囿于原有观点认为机器翻译无法完成高质量的翻译,因此不屑于使用机器翻译;另外对计算机辅助翻译的工作原理,不甚了解,也不愿意去学习,虽然翻译从手写转变为键盘输入,在没有使用翻译技术的情况下,并没有对翻译模式带来根本的变化。本文通过实证研究,以作者参与翻译的上海交通大学出版社出版的《远东国际军事法庭庭审记录》《第二辑》25卷为例(以下简称《庭审记录》),探索将多种翻译技术运用图书翻译的整个流程,以期证明多种翻译技术的融合运用加上后期的人工编辑可以极大的提高图书翻译的效率和质量,推动翻译技术在图书翻译中的应用。
2. 翻译技术应用的研究现状
通过在知网检索关键词,统计并进行分析归类,翻译技术的实证研究主要分为三个方面。
1) 计算机辅助翻译研究。主要研究集中在将计算机辅助翻译应用于医学、科技、法律、产品说明书等不同领域的翻译,而其他相关领域的应用较少。研究的重点均是突出如何有效利用翻译记忆库提高翻译的效率。
2) 机器翻译研究。机器翻译的质量研究 [3]。分析机器翻译在法律文本中的局限性,以及解决方案 [4] 机器翻译对语言服务行业发展的研究,探讨了其对语言服务企业绩效的影响,语言服务行业的发展趋势 [5]。通过机器翻译技术在国内外图书馆的案例应用研究,提出机器翻译在图书情报领域的未来应用发展趋势 [6]。通过FAR字幕评估模型,对比机器翻译在字幕翻译中的质量与人工字幕的质量,探索字幕机器翻译技术的发展现状 [7]。
3) 译后编辑研究。由于机器翻译在翻译许多文本时的准确性仍不尽人意,相关的研究主要涉及译后编辑能力的培养 [8]。原文对译员进行译后编辑效率和质量的影响研究 [9]。
综上所述,翻译技术研究的范围越来越广泛涉及机器翻译、计算机辅助翻译、翻译能力、翻译技术、译后编辑等方面。本研究通过实证研究,融合多种翻译技术,并探索了在翻译项目中使用不同翻译技术的具体的策略。
3. 翻译技术定义
机器翻译(Machine Translation)指使用机器(通常为计算机)将语篇从一个自然语言翻译至另一个自然语言 [10]。机器翻译是人工智能在翻译领域的应用,被称为人工智能皇冠上的明珠。机器翻译具有翻译速度快,翻译语种多,翻译成本低,翻译领域广等特点 [11]。2016年谷歌推出了具有深度学习能力的谷歌神经机器翻译引擎,将机器翻译带入新的高度。随后国内互联网巨头纷纷推出了各具特色的神经机器翻译引擎。
计算机辅助翻译技术(Computer Aided Translation)分为广义和狭义,广义是指能够辅助译者进行翻译的所有计算机软件,包括光学字符识别软件、语音识别系统、语料分析工具、术语管理和翻译记忆系统、本地化工具。现在越来越多的学者使用翻译技术来指代广义的计算机辅助翻译技术。狭义的计算机辅助翻译技术通常是指利用翻译记忆的匹配技术提高翻译效率的翻译技术。比如Trados,MemoQ,Wordfast等计算机辅助翻译软件 [12]。
翻译技术涉及人工翻译、机器翻译和计算机辅助翻译中使用的各种技术,包括基本的计算机工具的使用,以及专用翻译工具 [13]。现代翻译研究和翻译实践需要快速高效的解决方案来处理大量的文本。翻译技术是各种技术及工具在整个翻译流程中的使用,也就是说涵盖了译前,译中和译后的整个阶段,因此不仅仅只是涉及计算机辅助翻译工具和机器翻译,而是多种技术的融合。
4. 翻译技术运用于《庭审记录》翻译的可行性
4.1. 丰富的高频术语
《远东国际军事法庭宪章》在日本东京成立了远东国际军事法庭(以下简称法庭)审判日本战犯。法庭成立后审判从1946年5月3日开始到1948年11月12日结束,历时两年半,共开庭817次 [14]。涉及众多的人名、头衔、地名、机构名、事件名、及法律方面的术语,且这些术语重复出现的频率非常高,高频意味着可以将这些词语制作成术语库,通过计算机辅助翻译工具运用于翻译项目,保持术语的准确性和一致性。
4.1.1. 人名及头衔
庭审涉及的检察官、被告、证人、法官、以及律师的名字在庭审中反复出现,比如法庭庭长William Flood Webb (韦伯)、被告律师Roger F. Cole (罗杰·科尔)、甲级战犯SeishirōItagaki (板垣征四郎) ChangHsueh-liang (张学良)等。还有日本军队不同的军衔以及政府部门不同级别的官员。比如War Minister (陆军大臣)、Foreign Minister (外务大臣)、the President of the Privy Council (枢密院枢相)、Minister of Finance (大藏大臣)等。
4.1.2. 事件名及地名
事件名出现频繁,比如theChina Incident (卢沟桥事变)、the Nanking Incident (南京事件)、the Mukden Incident (奉天事件)、the Manchurian Incident (九一八事变)以及事件发生的地名,比如the Changkufeng (张鼓峰)、Tangku (塘沽)、Fushian (抚顺)、kuling (牯岭)、Ryojun (旅顺)、Canton (广东)、Marco Polo Bridge (卢沟桥)等。
4.1.3. 机构名
《庭审记录》包含中日两国政府不同的部门、公司、组织机构。比如Diet (国会)、Foreign Ministry (外务省)、Asahi Shinbun Sha (朝日新闻社)、the Concordia Society (协和会)、the Special Service Section of Mukden (奉天特务机关),Kokusui-Kai (国粹会)等。
4.1.4. 法律术语
不同于一般的法律翻译涉及立法及法律条款,在检辩双方立证、反驳立证、辩论、回答。判决的全过程虽以口语进行,但是庭审中包含大量的法律术语。比如indictment (起诉书)、prosecution (检方)、the record (法庭记录)、affidavit (宣誓证词)、cross-examination (交叉询问)、direct-examination (直接询问)。
4.2. 大量的简单句
《庭审记录》主要采用的方式问答,因此在问答过程中有大量的简单句,比如下面的问答:
Q: You read English also, don’t you?
A: Yes, I do read English.
The President: Give him the original.
这意味可以在翻译过程中可以运用机器翻译,因为对于结构简单,没有歧义的句子,运用机器翻译技术获得的译文完全正确,质量较高达到了出版级别。
4.3. 高频套话
庭审中都会使用与法律相关的表达,比如开庭、休庭时的表述,提交证据、法庭接受证据或驳回证据,证人出庭,宣誓证词都有固定的表达,且在庭审中这些表达都会多次出现。
比如:May it please the Tribunal. (法官阁下) We will recess for fifteen minutes. (休庭十五分钟) He is excused accordingly. (他可以退庭) Whereupon, the witness was excused. (随后证人退庭)这些固定的表达每天都出现庭审中。
实践证明翻译技术的运用可以有效提高多种文本翻译的质量与效率,其运用也越来越普遍。有学者研究探索了如何将翻译技术运用于医学、旅游、科技、立法、说明书、影视字幕翻译,却鲜有涉及翻译技术在图书翻译中的运用。传统翻译往往会有以下两个问题,一是术语不统一,即使将术语做成Excel表,还是需要译者去检索,这是一种被动的检索。对于上百万字的翻译项目来说,仍然耗时较长。上海交通大学出版社出版了索引,方便了翻译过程中术语的检索,但采用传统方式检索查验仍然存在上述问题。二是无法有效利用已翻译的术语及译文,造成重复劳动。
通过分析《庭审记录》的特点,作者发现每天庭审重复内容占据相当部分的比例,且不同庭审记录之间也会存在交叉重复,大量术语重复出现,这些特征表明可以将翻译技术运用于《庭审记录》翻译。以1947年10月19日的庭审记录为例,作者使用Trados统计文本内部的重复句段,文本总字数是14695,文本内部重复的句段字数为1506,重复的比例为10.25%,使用大规模高质量的翻译记忆库情况下,原文与翻译记忆库的匹配率会更高,从而减少翻译工作量,提高翻译的效率。
5. 翻译技术在《庭审记录》翻译中的应用策略
不同于单纯使用Trados等计算机辅助翻译工具进行翻译,通过利用术语和记忆库进行翻译。也不同于采用MTPE机器翻译+译后编辑的模式,对不符合要求的机器译文进行修改。本研究通过在整个翻译过程中融合多种翻译技术手段,将计算机辅助翻译、机器翻译等技术融入翻译,然后发挥译者的主观能动性对其进行译后编辑,通过人机融合,提高翻译的效率与质量,完成整个翻译项目。
5.1. 译前准备
5.1.1. 文本格式转换及处理
《庭审记录》原文件是PDF,属于不可编辑的图片类型的PDF文本,无法直接使用Trados进行翻译。上海交通大学出版社已通过光学字符识别(OCR)软件将PDF文本转换成可编辑的Word文档,转换后的文本整体质量较高,但仍有瑕疵,直接导入Trados翻译将会导致一些问题,因此需要对齐进行编辑,保证原始文本的准确性。对于同类错误,可以通过批量替换的方式更改。文本中许多人名每个字母都是大写比如MR.KISHI。导入Trados后,Trados会将其分为MR. 和KISHI形成两个句段,后期无法进行批量合并,虽然可以单独合并但耗费大量的时间,且对翻译造成一定的干扰。针对这个问题,可以通过批量替换功能将其替换为正确的拼写,从而避免将其拆分为两个句段,影响后续翻译。
5.1.2. 术语库制作
在《庭审记录》翻译项目中,上海交通大学出版社提供了部分Excel术语表,作者通过术语转换工具SDL MultiTerm Desktop和MultiTerm Convert将其转换成术语库。MultiTerm Desktop只接受XML格式的文件,所以需要使用MultiTerm Convert将Excel术语表转换成XML格式文件,然后再转换成Trados可以使用的Sdltb术语库。作者使用的另外一种工具是Glossary Converter,该方法比较简单,设置好导出格式,只需将Excel术语表拖入软件,完成后就会自动导出为Sdltb格式的术语库。另外对于项目组成员通过腾讯在线文档分享的术语,作者先将其下载保存为xlsx格式,对术语的准确性进行审校,通过Microsoft Excel本身的功能删除重复的术语,整理完成后,按照上述方法将其转换为Sdltb格式的术语库。
5.1.3. 翻译记忆库制作
翻译记忆库(Translation Memory)的工作原理是用户利用已有的原文和译文,建立起一个或多个翻译记忆库,在翻译过程中,系统将自动搜索翻译记忆库中相同或相似的句段,给出参考译文,使用户避免无谓的重复劳动,只需要专注于新内容的翻译 [15]。作者主要通过以下两种途径制作翻译记忆库。第一是通过翻译实践积累,在使用CAT工具Trados进行翻译时,新建记忆库,完成翻译时即可更新翻译记忆库。第二是利用对齐工具将机器翻译的译文与原文进行对齐制作翻译记忆库。作者主要使用以下三种方法通过使用机器翻译获得完整的译文,在翻译该日的庭审中,作者使用的是百度翻译制作的翻译记忆库。
第一种是使用谷歌Chrome浏览器。打开原文文档,将其另存为htm格式的文档、然后使用Chrome浏览器打开文档,出现“翻译此页”对话框,点击“翻译”或者点击“选项”后设定翻译的语言对,然后进行翻译。向下拖动网页滚动条,直至翻译完成,最后将译文复制到新建的Word空白文档。
第二种是使用云译客电脑端。通过官网进行注册,打开云译客电脑端,导入文档,点击“预处理”选择机器翻译,然后选择需要使用的机器翻译引擎,翻译完成后,点击“导出译后稿”,导出纯译文。
第三种是使用Transmate电脑端。通过百度官网注册百度翻译API,获得账号及密钥;打开Transmate在API设置中输入API账号及密钥,新建项目导入文档,使用百度翻译引擎进行预翻译,完成后导出译文,也可以直接导出为TMX格式的翻译记忆库。
使用对齐工具将原文和机器翻译的译文对齐制成翻译记忆库。作者常用的工具是Abbyy Aligner (见图1)和OmegaT。设置好语言对,导入源语言文件和目标语文件,选择自动对齐,没有对齐的句段需要人工干预进行对齐,完成对齐后导出为TMX格式的翻译记忆库。
另外两款在线对齐工具也比较容易使用,分别为一者科技的Tmxmall,和中译语通科的Yeekit,使用方法和上述的电脑端对齐工具类似,导入目标文件,进行对齐,编辑调整,完成句句对齐,导出为TMX格式的翻译记忆库。
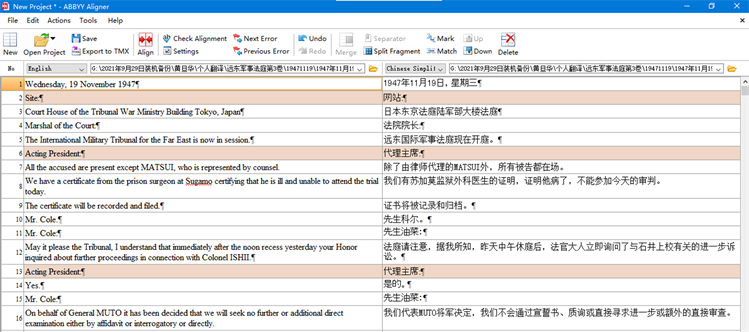
Figure 1. The interface of ABBYY Aligner
图1. 翻译记忆库对齐工具ABBYY Aligner操作界面
5.2. 译中
译中过程包含在翻译项目中使用术语库、前期项目积累的翻译记忆库、以及通过使用机器翻译制作的翻译记忆库,结合译后编辑完成项目翻译。
作者使用计算机辅助翻译工具Trados翻译项目,新建翻译项目,设置翻译语言对,添加原文件,载入制作好的术语库,翻译记忆库用于辅助作者翻译。在Trados中加载了术语库,原文内容和术语库匹配的时候,术语库窗口会自动显示出来,供作者判断选择。使用快捷键即可将正确的术语插入到指定位置,过程快速高效。对于有问题的术语,翻译过程中可以随时编辑修改,修改后的术语会自动更新到术语库。也可以在翻译过程中不断添加新的术语,丰富术语库(见图2)。
Figure 2. The application of terminology in Trados
图2. 原文句段及术语窗口
计算机辅助翻译工具最核心的功能就是翻译记忆库,如果没有翻译记忆库,CAT工具提高翻译效率的功能将大打折扣。因此在计算机辅助翻译项目中使用翻译记忆库尤为重要,对于语言服务公司的专业译员,可能有条件使用公司积累或购买的大型翻译记忆库。但是对于自由译员或兼职译员,往往使用更多的是个人积累的翻译记忆库。作者在使用Trados翻译项目时,将个人积累的翻译项目记忆库,机器翻译制作的记忆库,以及Trados中机器翻译插件融合使用,完成翻译项目。
首先在翻译项目中使用自己积累的翻译记忆库,因为自己通过翻译实践积累的翻译记忆库质量往往较高。先导入之前通过Trados翻译积累的翻译记忆库,设置好匹配率,进行预翻译时Trados会主动调用翻译记忆库与原文进行匹配,符合匹配的译文将会自动填充到译文栏,完成匹配后,更改匹配句段的状态,将其锁住。目的是为了不让匹配的内容受到后面导入的翻译记忆库的影响,因为通过机器翻译制作的记忆库匹配率更高,但质量不如译者通过实践积累的翻译记忆库质量高,如果不锁定通过机器翻译制作的记忆库就会覆盖之前匹配的译文。
然后,导入通过机器翻译以及对齐工具制作的翻译记忆库,使用预翻译功能完成全部项目的翻译。还可以在Trados中使用机器翻译的插件,进行预翻译,或者提供译文参考。
最后,翻译过程中作者会对匹配的内容进行判断,完全匹配准确无误的译文,可以直接使用。对于不符合要求的译文则需要译后编辑(Post Editing),匹配率较高的译文,存在少量问题则采用轻度译后编辑(Light post-editing)的方式处理;问题比较突出的翻译匹配是翻译中的重点也是难点,需要发挥译者的主观能动性,进行深度译后编辑(Full post-editing) (见图3)。

Figure 3. The flowchart of applying different translation memories
图3. 不同记忆库使用策略流程图
《庭审记录》也含大量的主语从句、表语从句、宾语从句、定语从句、状语从句等复杂句。这些句子往往比较长,甚至有时一段就是一句话,机器翻译的译文语序错误非常明显,可读性和准确性都不尽人意。需要发挥译者的主动性和创造性进行分析才能理解,这是翻译中的难点。对于机器翻译完全错误的内容,则需要译者进行人工翻译,保证翻译的质量。下面将通过实例进行分析。
例1:At the close of court yesterday the last question had not been answered.
百度翻译:昨天庭审结束时,最后一个问题还没有回答。
例2:I have no recollection of the contents and I have no familiarity with the matters contained therein.
百度翻译:我不记得其中的内容,也不熟悉其中的内容。
例3:Did the Navy Ministry discuss with officials of the Foreign Office the plan called “Tentative Plan for Policy towards Southern Regions,” which is the exhibit which I just referred to?
百度翻译:海军部是否与外交部官员讨论了我刚才提到的“对南部地区政策的初步计划”展览?
译后编辑:海军省与外务省官员是否讨论了“对南部区域的初步计划”也就是我刚才提到的物证?
例4:The Bureau of Naval Affairs was the political and liaison branch of the Navy ministry, was it not?
百度翻译:海军事务局是海军部的政治和联络部门,不是吗?
译后编辑:海军省军务局是海军省的政治和联络部门,不是吗?
从例1和例2可以看出百度翻译对结构简单的句子翻译质量是非常高的,这种情况,作者只需要确定译文就可,无需逐一打字输入。例3因为包含了术语,百度翻译将日语的Navy Ministry,the Foreign Office,以及exhibit分别译成了“海军部”、“外交部和”“展览”,显然偏离了原文的表达,但是这三个英文表达对应的中文已经在术语库中,只需要选择即可。例4百度翻译译文的句子结构是准确的,只是机器翻译无法判断该句的机构是日本的机构,因此出现了错误。这个问题,只需要通过导入的术语库,即可快速替换错误的术语。由此可以看出虽然机器翻译具备深度学习能力,但还不能根据语境分析文本,造成翻译的不准确性,或者存在歧义。在翻译过程中融合多种翻译技术及策略的使用,既提高了翻译的效率也保证了翻译的质量,有效减轻译者的记忆负担和重复劳动,兼顾翻译的效率与质量。
5.3. 译后质量保证及语言资产管理
翻译完成后审校不可或缺,需要检查拼写、漏译、术语一致性等问题。审校阶段,作者使用了Xbench软件,通过该软件可以检测遗漏未翻译的句段;原文相同译文不同的句段; 译文相同原文不同的句段;未使用项目关键术语的句段;数字错误等。使用工具之前,仍需要认真检查,因为工具不能代替人工检测所有的错误,比如因为同音而造成的汉字错误输入。
翻译过程中不断积累丰富术语库。翻译项目完成后,更新翻译记忆库将其作为语言资产,并可随时进行编辑、更新、并用于后期的翻译实践及翻译研究 [16]。
6. 结语
人工智能时代,翻译技术的发展颠覆了传统的翻译模式,越来越多的译者将翻译技术运用于翻译实践。翻译技术发展日新月译,虽然目前还不能尽善尽美,但整体而言,其在图书《庭审记录》翻译项目中的有效运用,表明译者要善于利用翻译技术,发挥其优势,择其善者用之;积极发挥译者的主观能动性和创造性,实现人机结合各得其所,提高翻译的效率与质量。
基金项目
本文系教育部2021年第二批产学合作协同育人项目(编号202102483011),浙江省十三五省级产学合作协同育人项目(浙教办函[2019] 365号)的阶段性成果。