1. 引言
随着云计算的快速发展,许多软件供应商提供了大量具有类似功能的Web服务,从这些具有类似功能的Web服务中为用户选择最合适的服务成为了一个热门问题 [1] [2]。Web服务可以通过用户服务质量(quality-of-service, QoS)来评估。其中,基于用户的QoS数据为用户挑选适合的Web服务提供了重要的依据。
各种各样的方法 [3] [4] [5] 被提出来解决这个问题,Koren [6] 将动态数据沿着时间轴分割成不相交的时间切片,其中每一个切片表示用户在某个时间点对一些服务的调用和交互的数据,然后在每一个时间切片上建立潜在因子分析模型。该模型相比于没有考虑时间的潜在因子分析模型的性能要好,但是该模型反应的时间信息被大大限制,因为如果沿着时间轴将数据切片,将切断每一个时间点之间的内在联系。因此在为动态数据建立模型的过程中应该充分考虑这些时间点之间的关系。
张量分解(Tensor Decomposition, TD)模型 [7] 将不再遭受这个问题,TD模型在高维稀疏(High Dimensionaland Sparse, HiDS)张量上模拟用户–服务–时间(User-Service-Time)之间的交互,然后再进行潜在因子分解。虽然,TD模型将时间信息建模成不同的潜在因子(LatentFactor, LFs),但是它的训练过程是整个动态数据集,而不是时间切片。TD模型考虑了各个时间之间的联系,从而可以更好地刻画隐藏在HiDS张量中的信息。
以前的研究 [8] [9] [10] [11] 表明,Nesterov加速梯度下降法(Nesterov’s Accelerated Gradient, NAG)在加速基于梯度下降法的学习算法的收敛速度非常有效。与动量法相比NAG方法更新过程中更细微的融合历史梯度信息。此外,该方法减弱了训练过程中的震荡,因此可以保证模型更快速的收敛。
基于以上发现,本文提出了基于广义化自适应的NAG非负张量分解模型(NHLFT-NAG)。该模型采用张量来代表随时间变化的QoS数据,因此把数据随时间变化的信息考虑到模型中。
本文的创新点如下:
1) 将广义化的NAG方法融入到SLF-NMU [7] 算法中,提出了广义化的NAG算法来提高学习潜在因子的效率;2) 对用户,服务,时间分别建立了线性偏置,来处理QoS数据的波动性,从而使模型具有更好地鲁棒性和更高的预测精度;3) 通过在训练过程中加入粒子群算法(PSO),使得模型正则化系数和算法的加速系数可以自适应调节。
2. 相关工作
在分析和预测动态的QoS数据时,常将用户–服务–时间的张量作为基本的输入数据源。QoS数据定义在非负实数域上并含有缺失值如图1所示。本文首先定义目标张量。
定义1 (HiDS用户–服务–时间张量):给出I,J和K,
是一个张量,张量中每一个元素
表示某一个用户
,在某个时间
点击某一个服务
。其中Y中已知和未知元素集合用Λ和Γ来表示,当
时Y是HiDS。

Figure 1. Tensor of user-service-time (blank part indicates missing value)
图1. 用户–服务–时间张量(空白部分表示缺失)
2.1. 高阶的潜在因子模型
本文采用的是Charu C [12] 提出了一种特殊的张量分解结构,评分张量
可以被分解为三个矩阵分别是:用户因子矩阵
,项因子矩阵
,环境因子矩阵
,其中
称为潜在因子维数。这种张量分解结构其实是基于非负矩阵分解的潜在因子模型的一种高阶表现形式。此时评分张量Y任意位置上元素的估计值可以表示为:
(1)
其中
表示
中的元素。
为了得到上式中的U,V和W,在已知集合Λ上利用欧式距离建立损失函数来衡量Y和
的差异:
(2)
为了防止训练过程中出现过拟合在(2)中加入正则化项可以提高模型的性能,得到(3)式:
(3)
其中
表示正则化系数。
由于QoS数据通常具有非负性,因此对U,V和W做非负限制,得到了最终的损失函数如下所示:
(4)
2.2. NAG方法
在目标函数的求解中,梯度下降法是一种常用的方法,它的缺点是在迭代的过程中容易陷入鞍点,或者陷入局部最优,导致收敛的速度缓慢。为了解决这个问题,Yurii Nesterov [8] 提出了梯度下降法的一个改进算法,即Nesterov加速梯度下降法(Nesterov’s Accelerated Gradient, NAG),NAG方法更新公式如下:
(5)
其中
表示自变量为
损失函数,u表示
的更新速度,分别u0表示u在训练过程中的初始,
表示第t次和第(t − 1)次的状态,
和
表示训练过程中第t次和第(t − 1)次的状态,
表示加速系数。
从(5)式和图2可以看到NAG方法包涵两个步骤:1) 沿着之前更新的方向移动θ得到一个中间状态
,计算中间状态的梯度,此时计算
的梯度时包含了更多历史梯度的信息;2) 通过线性组合这个梯度和之前的更新速度得到最终的更新方向。
2.3. 广义化的NAG方法
从(5)式可以看到NAG方法显式的采用了梯度,但是单元素非负乘法更新 [7] (single latent factor-dependent, non-negative and multiplicative update, SLF-NMU)算法由于对学习率的设置,隐式的采用了梯度。那么如何把NAG方法融入到SLF-NMU学习方法中得到一个广义化的NAG方法呢?根据 [8] 令
然后重新改写(5)式如下:
(6)
其中
表示
的中间状态包含了之前的更新速度和第(t − 1)次训练迭代后的状态。
在(6)式中可以发现使用NAG方法更新参数时包涵以下参数:1) 原始状态的参数,如
;2) 中间状态的参数,如
;3) 更新参数时使用的算法,其中(6)式中使用的算法是梯度下降法。
实际上,在隐式依赖梯度的算法中,可以更容易的获得更新增量。令
是
在采用某个算法第t次迭代后的状态即:
(7)
因此更新的增量
为:
(8)
为了得到
的广义形式,令
,可以得到下式:
(9)
在梯度下降法中,(6)式和(9)式都等效地将NAG方法纳入到训练过程中。因此,(6)式与(9)式结合得到广义NAG方法:
(10)
3. NHLFT-NAG模型
3.1. 带偏置NHLFT模型
推荐系统中的数据会随着时间的波动,根据 [13],处理这种具有波动数据时,在潜在因子模型中加入线性偏置(Linear Bias, LB),提高了模型的鲁棒性和预测的准确性。类似的在NHLFT中也加入线性偏置(以QoS张量数据为例),分别对用户,服务和时间建立LBs。
该模型的偏置和三个矩阵即用户矩阵
,第一列元素记为
,服务矩阵
,第二列元素记为
,时间矩阵
,第三列元素记为
。每一个矩阵只有一列是LBs的值,其他两列均填充了常数1如图3所示。
提取三个矩阵中的第一列,可以得到三个列向量,然后把这三个列向量做外积(Outer Product),得到张量
。对用户i,
中的元素记为
,由向量外积的计算公式可知
,同理可以得到
。令
,
,
,由
组成的向量分别记做
,再根据(4)式得到带偏置的目标张量中估计值的表达式:
(11)
最终的损失函数如下:
(12)
其中
是正则化系数。
3.2. 模型推导
根据(10)式,令
和
表示LFs中所要训练的参数第(t − 1)次迭代之后的状态,
和
表示第t次迭代时
和W的中间状态。在(10)式的基础上,当t=1时有:
(13)
其中,
是随机产生的非负数,由(10)式可以得到第一次迭代之后的状态:
(14)
因此
的中间状态可以计算为:
(15)
其中
表示
和W第二次迭代时的中间状态。
值得注意是(15)式实际上是将NAG效应纳入学习过程中计算了
和W位置的偏移,但是由于有负项存在,不能保证LFTs中训练的参数非负性。
通过结合(10)和(15)可以得到:
(16)
这表明在第二次迭代时,NAG方法通过(9)式将
和W位置偏移纳入到学习过程中,然后根据(9)将SLF-NMU应用到最终目标中。类似地,可以得到第三到第t次迭代的更新规则。因此,结合(13)~(16)式得到以下训练方法:
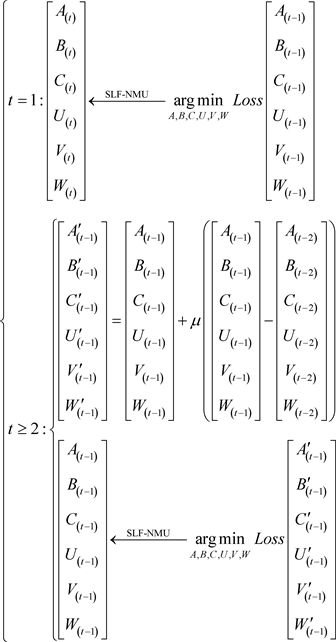 (17)
(17)
通过结合(17)式,(12)式和SLF-NMU算法可以得到
和W学习过程的规则如下:
 (18)
(18)
其中
和
计算方式如下所示:
(19)
(20)
从(18)式有如下发现:
1) 在广义化的NAG中存在
,
,
,
,
和
可能使训练过程中出现负项从而不能保证模型整体的非负性,所以采用了截断策略,始终保证速度项的非负性,从而保证模型整体的非负性;
2) 在第首次迭代时采用的是SLF-NMU方法来更新
和W;
3) 从第二次迭代开始,(18)式不断的把NAG纳入学习过程中。
4. 超参数的自适应性
从(18)式可以看到广义化NAG算法依赖三个超参数,即正则化系数
和速度参数
,为了让参数可以自适应的调节大小,根据 [14] 采用粒子群优化(Particle Swarm Optimization, PSO)算法可以实现训练模型时超参数的自适应。根据这个原则首先建立一个由p个粒子组成的搜索空间。其中,第j个粒子的位置和速度定义分别为:
和
,则第j个粒子在第t次迭代的公式为:
(21)
其中
表示第j个粒子发现的最佳位置,
表示第t次迭代中整个粒子群发现的最佳位置。(21)式采用的是标准的PSO [14],兼容表1中PSO常用的参数。为了简化下面实验这里令
。根据 [14] 限制
和
在如下的搜索空间:
,
,
,
。根据实验经验,本文采用表2中所给的数据。
由于本章的目标是在一个HiDS张量上实现高度精确的缺失数据估计,因此将第j个粒子的适应度函数定义为:
(22)
其中
表示计算集合中元素个数,Γ是测试集并且
,
表示有模型估计出的值,
表示HiDS张量中的真实值。由(21)式、表1和表2可以实现
和
的自适应。
5. NHLFT-NAG算法设计与分析
基于以上讨论,设计出NHLFT-NAG模型的算法如算法1所示。为了增加算法运行的效率在算法中引入了几个辅助矩阵。例如U依赖于
和
。其中
和
表示存储每一次迭代中的学习增量,
和
表示存储U最后两次迭代的中间状态。为了使
和
达到自适应的效果,引入辅助矩阵
和F分别存储了更新的位置,更新速度,最好的位置和粒子的适应度的函数值。
NHLFT-NAG模型的存储耗费依赖于
和相关的辅助矩阵,所以存储耗费为:
(23)
从(23)式可以看出由于存储耗费和
线性相关所以在现实中容易实施。
6. 实验结果与分析
6.1. 数据集
实验采用的两个数据集是由WSMonitor收集的 [7],相关细节由表3给出。从表3可以看到,两个数据集分别描述了吞吐量和响应时间,记录了142个用户在64个不同的时间点对4532个真实的网络服务信息,每个数据集拥有30,287,611个Qos记录。实际上可以得到两个规模为142 × 4532 × 64的用户–服务–时间的QoS张量,每个数据集的密度为73.53%。
为了易于比较,在实验之前将D1和D2两个数据集的数据映射到[0, 5]。将两个数据集随机的划分成70%训练集Λ,20%测试集Γ,10%验证集Κ。为了消除偏差和主观因素的影响采用10折交叉验证,训练过程将被重复50次。训练迭代停止时满足以下条件之一:1) 当误差达到10−5;2) 达到预先设置的最大迭代次数1000次。
6.2. 评估指标
本文关注模型生成数据的准确性,因为它直接反映模型能否精确的挖掘HiDS张量的基本特征,故采用平均绝对误差(Mean Absolute Error, MAE)和均方根误差(Root Mean Square Error, RMSE)作为评价标准。
(24)
(25)
其中Ψ表示验证集,并且
,
表示测试的项目来自测试集的预测。对于一个模型来说, MAE和RMSE的值越小代表模型预测精度越高。
6.3. 对比实验和参数设置
选取了五个模型作对比实验相关细节由表4给出。
M1~M5都是线性模型其预测的精度依赖潜在因子的维数f,统一设置f = 20来平衡预测精度和计算效率。模型M1依赖正则化系数
和学习率
,由表5给出。

Table 5. M1’s hyperparameter settings on D1, D2
表5. M1在D1,D2上超参数的设置
模型M2依赖正则化系数
,由表6给出。
Table 6. M2’s hyperparameter settings on D1, D2
表6. M2在D1,D2上超参数的设置
模型M3依赖正则化系数
和加速度常数
,由表7给出。
Table 7. M3’s hyperparameter settings on D1, D2
表7. M3在D1,D2上超参数的设置
6.4. 实验结果
表8,表9和表10分别记录了五个模型最好的RMSE,MAE和训练时间。
Table 8. RMSE of M1~M5 on D1, D2
表8. M1~M5在D1,D2上的RMSE
Table 9. MAE of M1~M5 on D1, D2
表9. M1~M5在D1,D2上的MAE
Table 10. Training time of M1~M5 on D1, D2 (second)
表10. M1~M5在D1,D2上训练时间(秒)
从表8可以看出在D1上M5的RMSE为0.7437相比于M1的0.9799降低了24.1%,相比于M2的0.7886降低了5.69%,相比于M3的0.7954降低了6.49%,相比于M4的0.7916降低了6.05%。在D2上M5的RMSE为0.4671相比于M1的0.6352降低了26.4%,相比于M2的0.5046降低了7.43%,相比于M3的0.5204降低了10.2%,相比于M4的0.4945降低了5.54%。M4和M5对HiDS张量缺失数据的预测精度相比于M1~M3要高。其中M5由于对用户,服务,时间分别增加了线性偏置,使得模型的预测精度有了进一步提升。类似的结论也可以从表9得到。
从表10可以看出M5的计算效率明显高于它的同类型的算法。例如,在D1上M5的训练时间为573秒,相比于M1的4936秒降低了88.3%,相比于M2的3672秒降低了84.3%,相比于M3的1789秒降低了67.9%。而相比于M4的562秒,M5的训练时间稍长,因为在M5中引入了线性偏置,引入了更多的自由变量,使得模型训练的参数变多因此时间增加。超参数的调节往往是要耗费大量的时间,而表10记录的是M1~M3预先调好参数之后模型的训练时间,本文提出的M5超参数时通过PSO自适应的调节,从而节约了大量的时间。
图4~7分别记录了M1~M5在D1和D2上训练时的RMSE和MAE的收敛曲线。从图4和图5中可以看出当NHLFT模型采用了广义化NAG算法和参数的自适应调节之后模型的收敛速度明显高于同类型的算法(M1, M2, M3),例如在D1上M5 (图4(e))只迭代了94次就已经收敛而M1,M2,M3分别迭代了903,653,206次才收敛,这个结果明显优于同类型的算法。注意当加入PSO调节超参数的自适应之后NHLFT-NAG模型每次迭代都要遍历所有的粒子,因此每次迭代实际上是由p个子迭代构成。但是即使是这样M5的收敛速度依然是最快的。类似的结论在图6和图7中得到。
7. 结论
本章主要目的是预测动态QoS数据中的缺失值,将动态数据建模成用户–服务–时间的张量,进行潜在因子张量分解,为此提出了NHLFT-NAG模型,该模型考虑了:1) 线性偏置;2) 数据的非负性;3) 超参数的自适应性。因此本文提出的NHLFT-NAG模型不仅加快了收敛速度而且在精度上也取得了一定的优势。将来可以对NHLFT-NAG模型进行进一步拓展,如改变模型的正则化项,此外还可以考虑采用其他优化算法来对模型的超参数进行优化。
基金项目
多性能指标下随机Markov跳变系统的预测控制及其在风洞流场中的应用,国家自然科学基金资助(62073223);基于通讯协议的复杂网络同步,上海市自然科学基金资助(18ZR1427100)。