1. 引言
交通标志识别 [1] (Traffic Sign Recognition, TSR)是智能交通系统中的一个重要分支,在辅助驾驶、无人驾驶等多个安全应用领域有着重要意义。主要实现方法有基于云端服务器和基于终端嵌入式设备。云端检测方法受限于网络条件,无法应用于网络信号较差的交通环境。基于终端嵌入式设备的交通标志识别很好地解决了这一类问题,但受限于计算资源,大多数基于深度学习的算法无法有效部署,所以本文对交通标志识别算法轻量化进行研究,在有效压缩模型大小的同时保证其检测准确率不受较大影响。
传统的交通标志识别方法有基于颜色、基于形状和基于机器学习 [2] 的方法,此类方法的特征提取较弱,无法适应较为复杂的交通场景。随着基于深度学习的目标检测算法的不断发展,其拥有特征提取能力强、检测准确率高等优势。以R-CNN系列为代表的两阶段算法,该类算法先进行区域推荐,然后利用卷积神经网络进行分类。因此这类算法检测准确率较高,但是其模型内存大、识别速度较慢。以SSD [3]、Yolo系列为代表的一阶段算法,其主要基于回归的思想,不生成候选区域,直接通过卷积神经网络进行分类,这类算法检测速度较快。在交通标志识别领域中,Zuo Z等人 [4] 采用Faster R-CNN对交通标志进行检测,并优化其检测性能。汪辉辉 [5] 在Yolov3中引入深度可分离卷积,以提高检测速度。陈梦涛 [6] 在Yolov4中融合注意力机制和RFB模块提升网络的特征融合能力,最后mAP指标提升近4%。闫志峰 [7] 将MobileNet引入SSD算法中以提升实时性。Tabernik D等人 [8] 通过卷积神经网络对交通标志进行端到端的检测识别,取得了较好的效果。Yolov5s [9] 作为Yolov5系列中最小的模型,对比大部分模型在内存上已拥有轻量的优势,但为了更好地适应嵌入式交通标志识别的应用环境,实现更为高效的运行,还需对其模型大小进行压缩处理。
为了在计算资源受限的嵌入式设备更高效运行交通标志识别算法,降低模型占用内存,本文提出一种轻量交通标志识别算法Yolov5s-lite。新算法通过在Yolov5s中使用Fire Module结构进行通道变化,以降低模型参数量和计算量;其次降低网络中的残差模块数量,以抑制无用背景信息的多次叠加。在检测准确率相当的前提下,有效地压缩了模型大小。
本文后续内容安排如下:第2部分为Yolov5算法原理;第3部分为Yolov5s-lite的优化设计;第4部分为实验结果与分析;第5部分为结论。
2. Yolov5算法原理
Yolov5算法网络结构如图1所示,Yolov5共推出四个版本,模型从小到大依次为Yolov5s、Yolov5m、Yolov5l、Yolov5x。Yolov5系列算法大小不同在于网络整体通道数和C3中的残差模块数量,网络整体结构基本一致。本文考虑嵌入式应用场景,以其中模型最小的Yolov5s为基础进行改进。
在输入端,Yolov5采用了Mosaic数据增强、自动计算锚框等方式对输入图像进行处理。主干网络 [10] (Backbone)的作用是对图片的特征进行提取。主要组件包括:Focus,Conv,C3,SPP。网络的第一层采用Focus结构,是一种特殊的下采样操作,其操作过程如图2所示。Focus将特征图每隔一个像素取一个值,即通道维数扩大为原来的4倍。Conv是Yolov5网络中的基本单元,由卷积、BN以及激活函数(Silu)组成。C3由多个Conv和多个残差模块组成。其思想为将梯度的变化从头到尾地集成到特征图中,减少网络参数和运算量,既保证速度和准确率,也减少模型尺寸大小。SPP是空间金字塔,采用四种不同尺度的卷积核做最大池化操作,将所得结果进行拼接,以获得不同尺度的感受野。
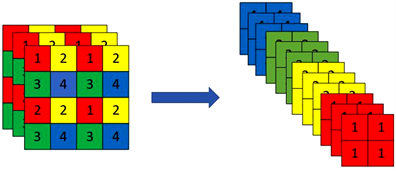
Figure 2. Schematic diagram of Focus operation
图2. Focus操作示意图
特征增强网络(Neck)由特征金字塔 [10] (Feature Pyramid Networks, FPN)和路径聚合网络(Path Aggregation Network, PAN)组成。FPN和PAN结构实现高层特征与低层特征融合互补。FPN结构将高层的大目标的类别特征向低层传递,PAN结构将低层的大目标的位置特征和小目标的类别、位置特征向上传递,两者互补并克服各自局限性,强化模型特征提取能力。
不同于传统的目标检测算法只利用高层信息对图像进行检测,Yolov5s检测网络(Head)设置了大、中、小三个检测层,满足了不同大小物体对于检测网络的要求。
3. Yolov5s-Lite交通标志识别算法
3.1. Fire Module结构
Iandola等人 [11] 提出的SqueezeNet网络模型将3 × 3卷积使用1 × 1卷积和较低通道数量3 × 3卷积来代替,通过分解成多个卷积,降低通道数可以有效的减少模型大小。对于3 × 3卷积核,输入通道数为M,输出通道数为N,其参数量为3 × 3 × M × N,通过减少M和N的数量可以有效的降低网络模型的参数量。
SqueezeNet网络由卷积层、池化层、全连接层以及若干个Fire Module模块组成。其中Fire Module结构是SqueezeNet网络中提出的一个用于减少卷积层参数量的创新点。Fire Module由两部分组成,分别为Squeeze结构和Expand结构,其总体结构如图3所示。其中Squeeze层包含低通道数量的1 × 1卷积层,负责压缩模型参数量;Expand层则由一组1 × 1卷积层和一组3 × 3卷积层分两路组成,负责对模型进行扩充。激活函数选择简单快速的ReLU函数,最后的输出为两路卷积后结果的拼接。
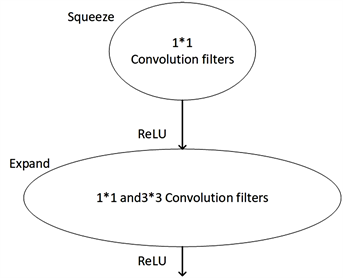
Figure 3. Fire Module structure diagram
图3. Fire Module结构图
Fire Module结构中Squeeze层1 × 1的卷积通道数记为s1,Expand层中1 × 1和3 × 3卷积通道数分别记为e1和e3。在Fire Module中,作者建议s1 < e1 + e3。在SqueezeNet网络模型中,作者使用的策略为4 × s1 = e1 = e3。在本文中采用同样的策略。为详细解释Fire Module的结构,以输入特征图为20 × 20 × 128,卷积核大小为3 × 3 × 256,步长为1为例,其输出特征图为20 × 20 × 256。如图4所示,使用Fire Module代替3 × 3 × 256卷积核,则输入图像首先经过Squeeze层1 × 1 × 32的卷积核进行通道变换,输出特征图为20 × 20 × 32。接着该图像再分别与Expand层中的1 × 1 × 128和3 × 3 × 128的卷积核进行卷积,得到两个20 × 20 × 128的特征图。最后将这两个特征图进行拼接,得到最终输出20 × 20 × 256的特征图,与3 × 3 × 256卷积核,步长为1的输出结果相同。
为了体现Fire Module压缩的有效性,分别计算两种方法的参数量,在使用3 × 3 × 256卷积核时,参数量计算公式如下:
(1)
其中128为输入通道数,256为输出通道数。其次使用Fire Module结构时计算参数量为:
(2)
Fire Module结构参数量相较于原卷积层下降了约85%。由此可见,Fire Module结构可以有效地压缩模型参数量。为兼顾检测速度与检测精度,本文将Yolov5s网络中3 × 3,步长为1的卷积层使用Fire Module结构代替,以用于压缩模型大小。
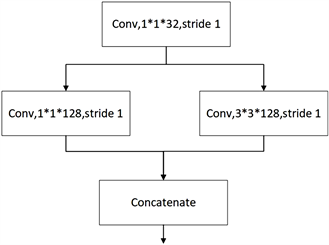
Figure 4. Detailed connection diagram of Fire Module
图4. Fire Module详细连接图
3.2. 降低残差模块深度
为了提取更深层次的目标特征信息,CNN的深度也越来越大。但是当网络深度增加到一定程度时,出现了梯度消失和网络退化现象。残差模块的出现很好地解决了这些问题,Yolov5s的残差模块(Bottleneck)的结构如图5所示。由于在上节中,使用Fire Module结构代替了3 × 3,步长为1的卷积层,所以改进后的Bottleneck如图6所示。
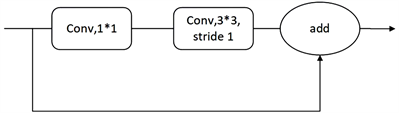
Figure 5. Bottleneck structure diagram
图5. Bottleneck结构图
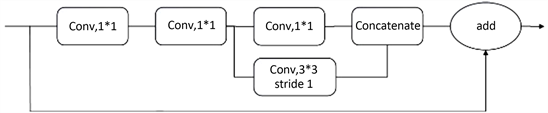
Figure 6. Structure diagram of Bottleneck after improvement
图6. 改进后的Bottleneck结构图
Bottleneck对特征的深度传递有着积极影响。由于改进后的Bottleneck相较于之前,进行了卷积分解,卷积层次变得更深。过深的残差模块容易造成无关背景的多次
叠加,小目标的语义信息容易消失且增加模型大小。Yolov5s网络中,Bottleneck模块位于C3模块之中,主干网络中共有4个C3模块,分别有1,3,3,1个Bottleneck模块。重新适配Bottleneck模块深度后,降低为1,2,2,1个。
4. 实验结果和分析
4.1. 计算机实验环境
本文计算机硬件环境使用的显卡型号为NVIDIA GEFORCE RTX 2070 (spuer),8G运行内存,整个实验框架都基于Window10操作系统实现。表1是实验环境的具体配置。
4.2. 交通标志数据集
本文使用的交通标志数据集来源于TT100K数据集 [11]。由于数据集中交通标志种类相差过大,所以挑选出具有重要语义信息的16类交通标志,共计训练集2725张,测试集624张。16类交通标志依次命名为:i4,i5,il60,io,p11,p26,pl100,pl30,pl40,pl5,pl50,pl60,pl80,pn,pne,po,如图7所示。
4.3. 性能评价指标
在分类任务中,TP (True Positives),预测为正样本,实际也为正样本的个数。FP (False Positives),预测为正样本,实际为负样本的个数FN (False Negatives),预测为负样本,实际为正样本的个数。在目标检测领域中,常用以下几种指标评价算法性能。
精确率(Precision, P)定义为所有预测值为Positive的样本中真实值为True的样本所占比例,精确率直接反映了模型的错检程度,其计算公式如下:
(3)
召回率(Recall, P)定义为所有真实值为True的样本中预测值为Positive的样本所占比例,召回率直接反映了模型的漏检程度,其计算公式如下:
(4)
平均精确率(Average Precision, AP)是将P和R相结合的指标。将P和R分别当作横纵坐标轴,然后得到一条曲线P-R,P和R是不可兼得的指标,一方的上升往往伴随着一方的下降,PR曲线下面所包围的面积为AP,采用AP能够更好地评估模型的检测性能,计算公式如下:
(5)
在目标检测领域中,通常不是简单的二分类任务。对于多分类任务,只需将所有类别的AP值取平均值,即为mAP,其数学公式如公式6所示,其中C代表类别的数量。
(6)
4.4. 训练过程
本文实验过程在超参数文件中设置训练参数:训练批次数量为16,线程数为4,初始学习率为0.01,循环学习率为0.2,采用随机梯度下降法(SGD)作为训练优化函数。在正式训练之前,首先进行3轮预热学习,其中预热学习动量为0.8,预热初始学习率为0.1,目的是为模型经过预热学习趋于稳定后,再进行正式训练效果更佳。
由图8可知,三种损失函数在前期均处于下降趋势,当epoch达到300时,三种损失函数在测试集上基本不再变化,即代表训练已经趋于稳定,可终止训练。
4.5. 算法对比
如表2所示,Yolov5s-lite相比于Yolov5s,模型参数量下降22.8%、计算量下降27.9%、实际模型内存下降21.7%,mAP仅下降0.5%。Yolov5s-lite模型内存仅有10.8M,更好地满足了嵌入式交通标志识别的应用场景。
4.6. 测试结果展示
图9给出Yolov5s-lite不同交通场景下的检测效果。图9(a)表明可以在交通标志侧面准确识别。图9(b)表明可以准确在阴影和强光处识别交通标志。这验证了Yolov5s-lite在不同交通环境下拥有较强的鲁棒性。
 (a) 交通标志侧面
(a) 交通标志侧面  (b) 阴影和强光下交通标志
(b) 阴影和强光下交通标志
Figure 9. Test results
图9. 测试结果
5. 结论
本文针对计算资源受限的嵌入式交通标志识别应用场景,提出一种轻量交通标志识别算法Yolov5s-lite。新算法通过使用Fire Module结构和降低残差模块深度,有效压缩了模型大小。在TT100K数据集的实验结果表明,Yolov5s-lite相较于Yolov5s,模型参数量下降22.8%、计算量下降27.9%、实际模型内存下降21.7%、mAP仅下降0.5%,改进后的模型内存仅有10.8 M。
综上,本文所提的Yolov5s-lite交通标志算法具有轻量化的优势。未来可进一步结合实际交通应用场景展开研究。
NOTES
*通讯作者。