1. 引言
P2P (Peer To Peer)网贷模式 [1] [2] [3] 自出现在人们的视野后就成为了金融行业的焦点,围绕此模式衍生出的平台也渐渐浮出市场,加之我国科学技术和经济社会的高速发展,使得P2P网贷的发展更为安稳。本文将某公司作为研究对象,构建适用的P2P平台风险评估模型,主要选取了传统的logistic回归模型、贝叶斯决策树、支持向量机和随机森林算法,以便于为平台提供具有参考价值高的数据,更好的判断客户的借贷行为是否可靠,将公司的损失降到最低。
2. 文献综述
在美国等西方国家,个人信用评价体系已比较成熟。尤其以美国为例,它作为世界上信贷消费最高的国家,开创了信用评价的先河。正是因为美国倡导先消费、后还款的生活理念,美国人的一生都将伴随着信用交易,这些信用记录贯穿在他们生活的方方面面,包括申请贷款、就业、购置保险、交通出行等。
David Durand是个人信用体系构建史上第一个认识到能将所学的数学公式等方法应用在信用评价上的学者,他首次使用线性判别来判断消费贷款以及个人信用的好坏,他成功地拉开数学方法应用在个人信用评价的序幕 [4]。紧接着1941年较为完善的信用评价模型Z-score模型被Altman建立,同时也奠定了他在企业信用研究方面的地位 [5]。1977年,Altman、Haldeman和Narayanan在Z-score模型的基础上,加入二次判别模型思想,形成了第二代信用评价模型,ZETA信用风险模型(ZETA Credit Risk Model) [6]。ZETA模型内含多种数理分析方法:Logistic分析与判别方法、神经网络分析法、聚类分析法、判别分析法(Discriminant Analysis,简称DA)、多元判别分析法(Multivariate Discriminant analysis)、层次分析法等等 [7]。
第一个应用且至今仍在使用的信用体系评价模型是基于线性判别分析,在众多学者的研究过程中,不断地引入了新的统计模型和算法模型。目前我国对于个人信用体系模型构建的研究主要分为两个方面,一方面是评价指标体系的构建,另一方面则是评价体系信用分计算和风险预测。何建奎和岳慧霞结合我国现实情况与西方国家经验总结出适合中国个人信用体系构建的模式应是 [8]:政府推动与市场运作相结合的模式,即采取以政府和中央银行为主导,以股份制资信公司为支撑,以现有信用中介公司为主体,以地区会员制为框架的全国个人信用体系 [9]。
3. 模型简述
3.1. Logistic回归模型
本文研究的因变量是贷款状态,违约者赋值为1,未违约者赋值为0。对于这种二元离散现象的数量分析,首先使用Logistic模型进行回归分析,模型的被解释变量Y是一个0~1变量,事件的发生概率是依赖于解释变量,即
,依赖于其影响因子解释变量的研究需要。
(1)
根据Logit变换的定义:
,
称为发生比(odds),得到最终的Logistic回归模型:
(2)
3.2. 贝叶斯决策树
贝叶斯决策树是一种利用先验信息处理数据间非同质关系的树型分类法。该模型不需要分布的假定,它的求解采用非参数技术;贝叶斯(策树算法的关键是选择节(的分裂属性,常将((Entropy)、卡方(χ2)以及基尼系数(Gini Index)作为计算信息增益的算法。熵是表示随机变量不确定性的度量,将
定义为分类变量U取值为i时的发生概率,若事件类型共有s类,则随机变量的熵定义为:
(3)
在本文中,s取值为2;又假设自变量为自变量
,则自变量i对应的2,因子水平k记为
;将信息增益定义为:
(4)
因此,对于自变量
,计算其对应的
,
取值越大,则表示自变量
;对于贝叶斯决策树分类具有更多的信息,则优先将
;作为识别。
3.3. 支持向量机
支持向量机(Support Vector Machine, SVM)是基于统计学习VC 维理论和结构风险最小原理共同建立的,它区别于经典统计学模型的最大特点是只需要将小样本作为特定的训练样本,通过训练得到学习精度和学习能力的最佳选择,便于获得最好的推广。上世纪九十年代,Cortes和Vapnik提出了线性支持向量机,而后Boser、Guyon与Vapnik引入核技巧,提出了非线性支持向量机,功能较为完整的支持向量机应用于当今社会的诸多方面。总的来说,SVM主要解决了两类问题,一是寻找到最优的超平面二是能够划分非线性可分的样本 [10]。
由于非线性均在线性的基础上进行研究,如图1所展示的线性支持向量,其中小叉叉和空心圆点分
别表示两类样本,w表示该平面的法向量,H1和H2为上边界和下边界,且令
为间隔距离,
H为最优分割线。
3.4. 随机森林
随机森林(Random Forest,简称RF)是Bagging的一个扩展体,它在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了属性选择。随机森林相比于单纯的决策树算法消除了许多局限性,减少了数据集的过拟合、提供了一种处理丢失数据的方法,因此提高了精度 [10]。具体算法结构如图2所示:
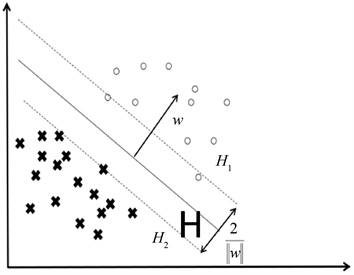
Figure 1. Schematic representation of the linear classification
图1. 线性分类示意图

Figure 2. Random forest algorithm structure
图2. 随机森林算法结构
3.5. 评价指标
评估指标是用来衡量模型优劣水平的算法,对于分类很多指标可以对其进行评价,如精确率、召回率(precision-recall)、错误率(error rate)、精度(accuracy)、误差(error)、训练误差、泛化误差等等。对于本文的分类模型,就是区分客户是否违约,分别对应正、负样本数,用P、N来表示。在统计分析当中,我们可以用一个混淆矩阵(见表1)来表示分类正确与否的情况,并在此基础上计算:

Table 1. Classifies the resulting confusion matrix
表1. 分类结果混淆矩阵
正确率(precision/accuracy):测试集上被模型正确分类的样本数所占的百分比。即:
(5)
错误率(precision/accuracy):测试集上被模型错误分类的样本数所占的百分比。即:
(6)
召回率/真正率(sensitive/recall):即在所有实际为正样本的情况下,成功预测为正样本的百分比。即:
(7)
精度(sensitive/recall):即即在所有预测为正样本的情况下,实际上为正样本的百分比。即:
(8)
假正率(False Positive Rate, FPR)即被预测为正的负样本结果数/负样本实际数。
(9)
F度量即(F1和FP)度量的方法就是将精度与召回率的计量方法结合后组成新的计量方法。定义如下:F1是精度和召回率的调和平均数
(10)
FP加的权系数是召回率和精度的β倍:
(11)
当β = 1时,模型对于准确率和召回率都一视同仁。
当β < 1时,模型主要重视准确率。
当β > 1时,模型主要重视召回率。
β的取值通常是2或者0.5,基于本文是研究客户的违约风险,故越精确越好,也就是尽可能地避免有违约风险的客户被预测为没有违约风险,这里选取β的取值为2,即
(12)
ROC全称是“受试者工作特征”(Receiver Operating Characteristic),AUC (area under the curve)其实就是ROC曲线的面积,两者相结合还有AUROC (area under the receiver operating characterstic curve)指标。
ROC曲线和AUC曲线常常作为衡量二分类分类器的重要指标,其中ROC曲线越靠近左上角说明在FPR很小时TRP很大,AUC在分析中常类似成绩一样地被分为五个区间:
意味着优秀(Excellent);
意味着良好(Good);
意味着尚可(Fair);
意味着不好(Poor);
意味着失败(Fail);
也有学者对AUC的评价准则做出了不同的解释:
AUC = 1,最好的分类器,若使用此种分类器,可以得到不止一个阈值的最优预测结果。但是大部分的猜测状况下并不会出现最好的分类器。
0.5 < AUC < 1,优于随机猜测,这个分类器若是选择合适的阈值,会有预测价值;
AUC = 0.5,与随机猜测原理相同,模型是没有预测价值的;
AUC < 0.5,比随机猜测还差;
但不管是哪种评价准则,都有样的规律,即AUC值越大,分类结果越好。
4. 实证结果分析
数据说明
本研究使用的数据集主要包含各种属性,例如资金金额,位置,贷款,余额等,具体说明如表2:
Table 2. Variables introduction table
表2. 变量介绍表
将数据集的前百分之八十作为训练集用以训练模型,将后百分之二十作为测试集,比较不同模型的预测结果(表3):
Table 3. Comparison table of the model prediction effect
表3. 模型预测效果对比表
比较模型预测结果,以得到以下结论,logistic回归模型和决策树模型在精度上都较低,支持向量机模型和随机森林模型的精度较高,但效果最好的是随机森林模型。为了更好的观察随机森林模型的预测效果,接着做出ROC曲线图AUC图进行观察,通过图3可以看出,该模型的ROC曲线远离纯随机分类器的ROC曲线(AUC等于0.5),AUC等于0.889∈(0.8, 0.9),故该模型的违约风险预测效果良好。

Figure 3. The ROC plot of the random forest model
图3. 随机森林模型ROC图
5. 结论
本文基于某公司信贷数据集,通过比较logistic回归模型、贝叶斯决策树、支持向量机和随机森林算法构建违约预测能力,根据结果得知对于此数据集,随机森林的预测效果最佳。
随着市场经济的不断发展与成熟,信息时代的到来,金融信用发展到一个新的层次与水平,加之我国法制的进步和人民法院强制执行力的不断加强,我们越来越频繁地从媒体上听到“老赖”这个词,一旦被列入“老赖”行列,既坐不了高铁,也乘不了飞机,出行非常不方便,而且还会影响到孩子的教育。但是近年来,在个人消费的各个方面出现的失信行为,信用缺失已成为当前经济社会发展的“瓶颈”,不仅影响到人们的日常生活,也影响到我国市场经济的健康发展。
为了国家更好的建设和完善社会信用体系,也为了自身的金融信用、日常生活不受影响,客户要做到以下几点:
1) 按时归还欠款,防止贷款逾期或欠息;
2) 若无法一次性付清借款可分期;
3) 理性做好规划,加强个人金融管理,避免超前消费和过度消费。
同时我国现在处于建全违约风险相关法律法规的重要阶段,国家和政府的相关部门也需要付出相应的行动,以下是对相关部门提出的建议:
1) 加快个人征信体系的建设;
2) 加强对借贷人的教育;
3) 推动金融惠普发展。
模型考虑的影响因素较单一,基本为微观数据,后期尝试引入部分宏观影响因素如:国际环境、国家政策、社会舆论等,自2019年新冠疫情的爆发,不仅对我国经济发展造成了严重的影响,甚至对国际经济而言影响都很大,故在后续的研究当中,会收集资料将新冠疫情也作为影响因素之一构建借贷风险预测模型。
基金项目
国家级大学生创新创业项目(202110638006)。