1. 引言
1.1目标检测概况
近些年来,随着深度学习的快速发展,目标检测在计算机视觉中的应用越来越广,尤其是行为识别中,目标检测将是里面很重要的一步。同时,目标检测一直处在热门研究领域中。
传统的目标检测首先对目标位置进行定位,其次根据特征提取算子提取特征,常用有HOG、SIFT等特征提取算子,最后使用SVM、RF等分类器对提取的特征进行分类。文献 [1] 采用方向梯度直方图(Histogram of Oriented Gradient, HOG)提取特征向量,将提取的特征向量输入支持向量机(Suport Vector Machine, SVM)进行图像分类,最后实现东巴文的自动识别。文献 [2] 在SIFT基础上提出FG-SIFT算法,减少了特征点提取的计算时长,提高了算法的实时性。文献 [3] 采用HOG-SVM通过机器学习进行研究,对电子元件进行了不同角度的特征提取,最后使分类精度得到了提高。文献 [4] 提出一种基于多分类器协同的半监督样本选择方法,利用SVM和RF两个分类器协同训练,最后达到很好的效果。传统的目标检测算法传统的目标检测虽然取得了一些成就,但目标检测的过程中存在时间复杂度高,同时提取的特征往往是人工手动设计的,使得模型的鲁棒性差和泛化性不好。从2014年开始,深度学习开始用于目标检测、行为识别等领域,通过卷积神经网络将深层的特征提取出来,解决了传统目标检测的不足。其中最具有代表性的就是CNN、RNN以及YOLO等一系列基于深度学习的目标检测算法,相对于传统的手工设计特征的方法,能够自动学习视频的深层特征,同时在精度和效率方面大大地提高。Girshick等 [5] 2014年利用Region CNN(R-CNN)通过选择性搜索算法从一组对象候选框中选择可能出现的对象框,然后将这些选择出来的对象框中的图像输入到CNN模型提取出特征,最后将特征送入分类器经行检测和分类。最终使mAP值在PASCAL VOC2007上最好结果的30%提升到66.0%,但是精度脱离实际应用,检测速度更是达不到实际的要求。Girshick等 [6] 2016年的Faster R-CNN将原始图片输入卷积中得到特征图,使用建议框提取特征框,使得计算量大大减少,同时,分类和预测框的位置大小都是通过CNN输出的,最后的检测精度和速度明显得到提升,在PASCAL VOC2007数据集上mAP达到73.2%。R-CNN系列等 [7] [8] [9] [10] 两阶段目标检测算法,在精度检测效果上很好,但检测的速度仍然是个很突出的问题。Redmon等2016年的YOLO (You Only Look Once)单阶段检测算法,将图片给卷积神经网络输入,最后得到边界框的信息以及置信度,在mAP为63.4%的同时FPS达到45,检测速度得到了极大提升,但是检测精度却比不上Faster R-CNN检测算法。YOLO单阶段检测算法检测速度快是一个优势,但是发展到现在存在的问题依旧是精度比起两阶段目标检测算法仍有不足。在目标检测中,精度和FPS一直都是研究的重点,在前者满足的情况下来追求实时性是YOLO [11] [12] [13] 单阶段系列检测算法能够得到广泛应用的重要优势。
1.2. YOLOX-s改进
但是目前单阶段检测算法的检测精度以及mAP不足的情况,提升目标检测算法的检测精度以及推理速度成为发展的必要之处。本文以提高Ultralytics公司2021年开源的YOLOX-s检测算法的精度和mAP为目的,采取将注意机制引入YOLOX-s网络,通过在网络中加入SE和CBAM模块,让模型将更多的细节信息获取出来,使得获取网络深层信息更容易,从而探索注意力机制对YOLOX-s检测算法的影响,以提升YOLOX-s检测网络的检测精度和mAP。
2. YOLOX-s网络模型
2.1. YOLOX-s简介
YOLOX-s网络结构有四个部分,分别是输入端、BackBone主干网络、Neck、Prediction。结构如图1所示。

Figure 1. Model network structure of YOLOX-s
图1. YOLOX-s网络结构
在目标检测中,图像模糊、检测的目标小等问题对目标检测算法造成影响,YOLOX-s输入端对输入图片进行Mosaic、Mixup数据增强,Mosaic是利用四张图片进行随机缩放、随机裁剪以及随机排布的方式拼接成一张图片,丰富了检测数据集,使得网络的鲁棒性变强,同时小目标的检测效果也得到了提升;它将MixUp在图像分类的应用借鉴到目标检测中,MixUp对一张图片的两侧、另一张图片的上下进行填充,将两者加权融合后使得图像数据增强。
在Backbone主干网络中使用的是CSPDarknet网络,输入图片在这里进行浅层数据提取,Backblone主要包括Focus、CSP、SPP三个结构。Focus结构,是对图片进行切片的操作,如YOLOX-s中,将640*640*3的图片输入进Focus结构,切片成320*320*12的特征图,再经过一次卷积变成320*320*32的特征图。CSP结构将特征图分为两个分支进行处理,一个分支先通过CBL,然后经过多个残差组件BN,再经过一次卷积;另一个直接进行卷积操作,最后将两支处理的特征图进行拼接,在减少计算量的同时加强了网络的学习能力。SPP部分能将任意大小的特征图转换成固定大小的特征向量,其中池化盒的大小有1*1、5*5、9*9、13*13四种方式,对特征图进行空间最大池化后,将得到的不同尺度的特征图进行拼接,加强了主干特征能力的提取,同时增大地网络的感受野,提取出最重要的特征信息。
在Neck模块中,采用FPN和PAN结合的方式,FPN部分通过自上而下的方式,将高层特征通过上采样后,和底层特征进行融合而得到预测的特征图,它用来传达语义特征;PAN部分通过自下而上的方式进行下采样,和深层特征进行融合而得到预测的特征图,达到增强定位的特征。两者结合将不同层的信息融合,从而达到提高特征提取的能力。
在Prediction模块中,主要包括Decoupled Head、Anchor-Free、Muti positives。YOLOX-s使用三个检测头分支,每个分支的开始都使用1个1*1卷积降维,然后各使用2个2*2卷积,特征图经过这个模块后预测出三个结果,一个是预测目标框的类别,其次是目标框是背景还是前景,最后是预测目标框的坐标信息,最后将三个分支输出的特征图进行融合而得到输入图片的特征信息,YOLOX-s使用三个Decoupled Head的方式在提高检测精度的同时也加快了网络的收敛速度。Anchor-Free的使用让预测结果的参数量大大减少。模块中加入Muti positives,也就是让正样本的数量增多,网络模型的性能得到了提升。
同时,在网络的输出端将DIoU作为边界框的损失函数和非极大值抑制(NMS)。DIoU的定义如公式(1)所示,IoU如公式(2)所示,IoU的图如图2所示。
(1)
(2)
其中,公式(1)中a代表预测框中心点,
代表真实框中心点,L代表预测框与真实框中心点间的欧式距离,c代表能够同时包含真实框与预测框的最小闭包区域的对角线距离。公式(2)中两个边界框相交的部分比上它们的并集就是IoU,它在目标检测中可以反映出预测框与真实框的检测效果。
2.2. .SE模板
本文借鉴了在2017年的ImageNet分类赛上夺冠的SENet (Squeeze-and-Excitation Networks),并采用了其中的SE模块对通道进行相关性学习,在计算量上稍有提升的同时,在通道上筛选出关联性和重要性较突出的特征信息。首先对SE模块的输入进行压缩操作,经过全局平均池化之后,特征图会变成1 × 1 × C的向量,其中C代表通道,然后将1 × 1 × C的向量输入到全连接神经网络中,而全连接神经网络有两个全连接层,第一个全连接层的通道数会和一个缩放因子进行乘积,在经过第一个全连接层时会进行缩放操作,达到减少通过数使计算量减少,第二个全连接层则使输出通道数变为C。最后进行Scale操作,将输入的特征图与经过压缩和激励操作的特征图进行通道权重相乘,得到输出的特征图,由于使用了全连接层,参数量会有所上升。本文将SE模块加在主干网络部分,SE模块结构如图3所示。
2.3. CBAM模板
同时本文采用了CBAM (Convolutional Block Attention Module)。CBAM模块由通道注意力部分和空间注意力部分组成,通道注意力的核心是使用1 × 1的卷积核来提取特征,偏置部分在实验时设置为false,空间注意力部分则是通过在通道维度上分别采取求平均和,最后进行聚合,得到的通道数是2的卷积层,再通过一次卷积得到。将通道注意力部分和空间注意力部分进行结合,结合之后使用广播机制对原始特征图进行特征提取,得到CBAM的输出特征图。CBAM模块加强了特征在通道和空间上的表现,使网络学习需要关注和舍弃不需要关注特征信息的能力得到提升,由于CBAM模块的效果是对特征信息采取精细化分配处理,所以本文会将CBAM模块加在主干网络部分。CBAM结构如图4所示。
3. 实验
3.1. 实验数据集及实验环境
本文实验数据集采用PASCAL VOC2007,类别数为20,并混合在学校采景的数据集进行扩充,为了保持PASCAL VOC数据集的格式,对扩充的数据集用LabelImg进行目标标注,将标注好的文件以PASCAL VOC的命名规则命名,以xml作为标注好的文件后缀名,并使标注文件和图片名字一致。划分后的混合数据集如表1所示。
实验环境采用Linux操作系统,编程语言使用Python 3.8,深度学习框架为PyTorch,进行实验以及数据获取,详细实验环境如表2所示。

Table 2. Detailed configuration of experimental environment
表2. 实验环境详细配置
3.2. YOLOXs模型的训练参数设置
训练使用了在Coco和PASCAL VOC上的YOLOX-s预训练模型,优化算法选用Adam,实验所有参数保持一致,迭代数为300轮,BatchSize为16,Adam的动量因子为0.999,初始学习率为0.001。学习率调整方式为:学习率的初始值为0.001,先用线性插值对学习率进行预热,预热动量因子为0.95,轮数为5,再采用余弦退火算法调整。
3.3. 评价指标
本实验对比由原YOLOX-s、YOLOX-s + SELayer、YOLOX-s + CBAM形成,评价指标使用精度(Precision),召回率(Recall)以及平均精度均值(Mean-Average-Precision, mAP),相关计算方式如公式3、公式4所示。
(3)
(4)
TP代表实际为正样本的同时模型预测为正样本的数量,FP代表实际为负样本的同时模型预测为正样本的数量,FN代表实际为正样本的同时模型预测为负样本的数量,TN代表实际为负样本同时预测为负样本的数量。Precession计算的是预测为正样本且预测正确的样本数量占所有预测为正样本数量的比例,Recall计算的是预测为正样本且预测正确的样本数量占所有实际为正确的样本数量。因为每张图像的类别可能不同,所以采用mAP值作为评价指标,根据每个类别的Precision值和Recall值可以分别绘制出各个类别的P-R曲线,AP计算的是PRC (Precision-Recall Curve)曲线下面积,AP指标比较如图5所示。
从图5中可以看出,在加上SE注意力后YOLOX-s算法的训练变得更加平滑和稳定,在加上CBAM注意力模块之后,算法的精度得到显著提高,接近80%,对比原始YOLOX-s的78.5%而言,提高了1.5%,效果较为明显。
3.4. 实验结果及分析
从图6,图7,图8可知,在原始YOLOX-s模型上加了SE注意力模块之后检测效果得到了较小提升,在原始YOLOX-s模型上加了CBAM注意力模块之后检测效果得到较大提升,在从图8可知在
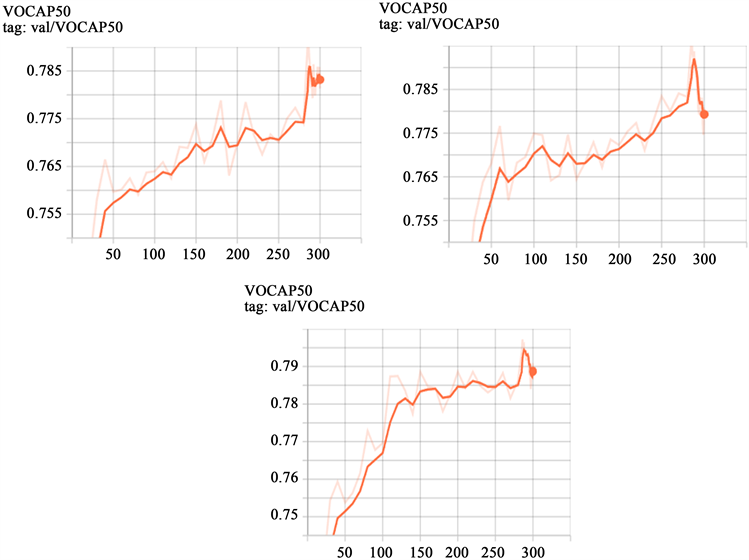
Figure 5. mAP values of the original YOLOX-s, YOLOX-s + SE module and YOLOX-s + CBAM module
图5. 原始YOLOX-s、YOLOX-s + SE注意力模块和YOLOX-s + CBAM注意力模块后的训练过程中mAP值变化图

Figure 6. Detection effect of original YOLOX-s module
图6. 原YOLOX-s模型检测效果

Figure 7. Detection effect of YOLOX-s + SE module
图7. YOLOX-s + SE模型检测效果

Figure 8. Detection effect of YOLOX-s + CBAM module
图8. YOLOX-s + CBAM模型检测效果
YOLOX-s加上CBAM模块改进后,置信度得到提升,对于YOLOX网络而言,注意力机制可以较为明显地提升网络提取图像特征的能力。
本文也同其他的模型作了对比来验证改进后模型的效果,如表3所示。
4. 结论
本文对目前检测效果较好YOLOX-s进行了注意力机制的改进,通过将改进前与改进后的评价指标
Table 3. Comparison of models performance
表 3.模型性能对比
进行对比,得出注意力机制在增加微量计算的同时可以提升模型的检测性能的结论,证明了注意力机制可以改善模型对物体的检测。综上所述,本文所提出的改进方法可以提升模型的性能,但是存在实验环境和条件的限制,召回率低的问题没有解决,后续会从数据集、nms以及注意力机制优化等方向继续改进。
NOTES
*通讯作者。