1. 引言
随着人类社会的工业革命发展,金属就逐渐成为生产生活以及工业制造中极为重要的原材料。冶炼金属与加工金属的技术不断创新,使得以铁、铝、铜等金属及其合金为主要材料的制品广泛用于汽车、船舶、建筑、航空航天、生产制造等工业领域。在金属零件制造加工环节中,由于人员操作不当或者加工工艺的问题,金属零件会出现如毛刺、条痕、孔洞、裂纹、磨损、尺寸偏差等缺陷 [1]。为了保证金属产品的精度,质量和性能,需要对金属产品的表面缺陷进行检测。
对金属产品缺陷检测的方法主要分为人工检测、X射线检测、超声波检测 [2]、机器视觉与深度学习检测 [3] 等等。其中,人工检测、X射线检测、超声波检测等主要依赖于人工肉眼或者物理特性来检测,存在检测效率低,精度低等问题。基于深度学习的图像检测方法克服了人为提取特征的缺点,能够实现快速、准确、自动化的缺陷识别 [4]。近年来,关于金属图像检测的深度学习方法不断发展,2020年,李维刚等 [5] 提出了一种改进的YOLOV3模型用于带钢表面缺陷检测,通过调整网络结构与优化锚框聚类算法等手段改善基准模型性能。2021年,孙连山等人 [6] 提出了一种改进YOLOV3模型(AM-YOLOV3),改进措施包括添加设计的注意力引导模块、增加预测尺度和使用K-medians聚类生成锚框,在铝材缺陷数据集上mAP达到了0.9905。2022年,Tian和Jia [7] 提出了一种基于CenterNet改进的钢表面缺陷目标检测器(DCC-CenterNet),改进措施包括扩展特征增强模块、新的中心权重函数和CIOU等,在NEU-DET数据集上mAP达到了0.7941,速度为71.37 fps。上述大都在YOLO-V3的基准图像检测模型上进行改进,YOLO-V3网络结构的性能存在滞后的问题,逐渐不能满足金属产品表面缺陷新的检测要求。
本文选取最新的单阶段、无锚框的YOLOX模型,将其作为基准图像检测模型改进,采用NEU-DET数据集 [8] 与自制金属插头表面缺陷数据集,包含有六种典型表面缺陷,即轧制氧化皮、斑块、开裂、点蚀表面、内含物和划痕,实现金属表面缺陷图像检测。
2. YOLOX-S算法模型
Yolo [9] 目标检测系列算法自从2015被提出以来,不断地进化发展,成为单阶段目标检测模型中最杰出的物体检测器之一。2021年,旷世科技提出了以YOLOV3-SPP和ultralytics公司YOLOV5系列为基准模型改进的YOLOX系列 [10]。YOLOX-S的组成主要包括三部分,分别是CSPDarkNet模型构成的主干特征提取网络、FPN-PAN结构组成特征提取加强Neck和实现结果预测的解耦头,其具体结构见图1所示。在主干网络与颈中存在两种跨阶段局部(CSP)结构,分别为CSP_block1与CSP_block2。CSP_block1的后缀表示残差组件个数,CSP_block2的后缀表示卷积组个数,YOLOX通过设定CSP结构大小来控制模型深度。YOLOX-S由YOLOV5-S改进得来,其在网络结构方面的主要区别在于:第一,将基本卷积模块中的激活函数由Leaky ReLU换为SiLU;第二,将预测头部分由传统的耦合的YOLO Head改为解耦头。使用解耦头能提高模型精度,还能加快网络的收敛速度。在整体上,YOLOX使用强大的数据增强、无锚框、多正样本、SimOTA标签分配策略等技巧来优化模型性能。

Figure 1. Diagram of the network structure of YOLOX-S model
图1. YOLOX-S模型的网络结构图
3. YOLOX-S模型改进
本文YOLOX-S模型的改进方向主要包括两部分,第一,在图像检测模型的基本网络不同位置添加注意力机制,第二,图像检测模型使用改进的损失函数。通过以上改进,本文的检测方法优势在于通过注意力机制可以提高对某些形状发散,边界模糊以及位置信息难以判断的缺陷分类的准确率,同时改进损失函数考虑了预测框回归的重叠面积,中心点距离、长宽边长真实差,基于CIOU解决了纵横比的模糊定义,并添加Focal Loss解决预测框回归中的样本不平衡问题,提高了金属缺陷检测定位的精度。
3.1. 添加注意力机制
注意力机制是机器学习中一种数据处理方法,广泛应用在自然语言处理、图像识别及语音识别等各种不同类型的机器学习任务中。针对金属检测中某些形状发散、缺陷核心微小、边界模糊的缺陷检测问题,可以对YOLOX-S检测模型进行相应的改进,在主干网络与特征加强颈之间的三个特征图中添加注意力机制模块CBAM,提升模型在该问题上的性能表现。CBAM是通过通道注意力模块CAM和空间注意力模块SAM串联组成的,并且通道注意力模块在前,空间注意力模块在后。CBAM与只关注通道域注意力SE模块相比,增加了空间域的注意力机制,强调了空间和通道两个维度上有意义的特征;同时,在实施过程中增加了全局最大池化,两种不同的池化意味着提取更高层次的特征更加丰富,CBAM的具体实现见图2。
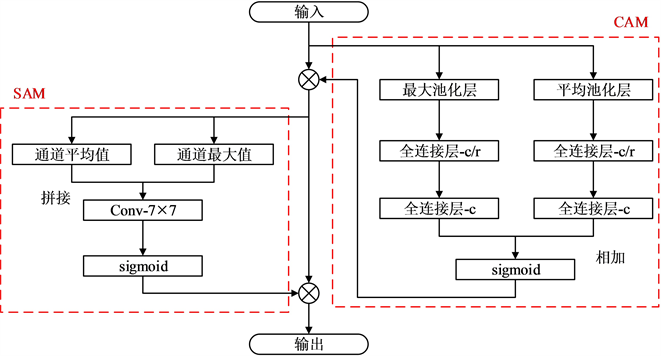
Figure 2. Diagram of attention mechanism CBAM
图2. 注意力机制CBAM图
3.2. 改进损失函数
YOLOX的损失函数的计算公式如(1)所示,由三个部分组成,分别是类别损失
、置信度损失
和边界框位置回归损失
。其中类别损失与置信度损失均采用二值交叉熵损失函数计算,而位置损失采用传统的IOU_Loss实现。
(1)
对于YOLOX-S图像检测模型原有的IOU_Loss,存在两个不足:一是预测框与目标框不相交时是不能反映两个框的距离远近的,此时IOU为0,其损失函数不可导,无法回传梯度进一步学习;二是对于确定大小的预测框与目标框,相同的IOU值不能反映两个框的相交情况。改进YOLOX-S的损失函数主要考虑置信度损失与位置损失,其中置信度损失采用Focal_Loss [11] 函数来进行衡量。
Focal_Loss的计算公式如(2)所示,其主要解决的是在单阶段的目标检测器中正负样本不平衡的问题。Focal_Loss通过给正样本较大的权重,对于负样本更小的权重,使得正样本在损失函数中的贡献更大,有利于提高网络模型对正样本的识别能力。
(2)
式中,
为调制因子;
是可调的专注参数,范围为[0, 5];
表示的模型预测属于前景目标的概率
的函数,
是用于调节样本权重参数
的函数。
GIOU_Loss解决了IOU_loss未考虑预测框与目标框如何相交的问题,但是存在无法区分预测框在目标框内部时相对位置的问题。与IOU_Loss相比,引入了两框最小外接矩形与两框并集的差集形成的惩罚性项,计算公式如(3)所示。
(3)
式中,
是预测框与目标框的最小外接矩形。
EIOU_Loss [12] 在CIOU_Loss的基础上将长宽比的影响因子拆开,分别计算目标框与预测框的长和宽。EIOU_Loss主要组成包括三部分,分别是重叠损失、中心距离损失和宽高损失,计算公式如(4)所示。
(4)
式中,
和
两框的最小外接矩形的宽和高。
3.3. 实验与分析
本文实验采用NEU-DET数据集与自制金属插头表面缺陷数据集,NEU-DET数据集是东北大学的NEU数据集中目标检测部分的数据集,其图像数据部分是NEU-CLS数据集构成。数据集的缺陷边界框的标注信息采用xml格式文件保存,标注的边界框信息共4186个,其中夹杂种类缺陷标注数最多,达到了1011个,麻点种类缺陷标注数最少,为432个。对于自制金属插头表面缺陷数据集,使用图像标注工具LabelImg对含有缺陷的图像进行目标的边界框标注,形成标签数据集。
将数据集按照7:3的比例划分为训练集与测试集,训练集中10%的数据用于验证。采用的实验配置环境见表1,相关的实验主要分为两个主要部分,一是在主干网络与特征加强颈之间的三个特征图中添加注意力机制模块CBAM;二是改变网络的置信度损失函数为Focal_Loss和预测框位置回归损失函数为EIOU_Loss。

Table 1. Description of experimental environment configuration
表1. 实验环境配置说明
为了观察数据增强的效果,通过设置COCO数据集的预训练权重,设置批次大小为6,训练的epoch数设置为100,在最后的15个epoch中关闭MixUp与Mosaic数据增强策略。由图3可以看出,在训练的最后的15个epoch中,目标检测模型的mAP值增长明显。这说明,在训练末尾去除数据增强能够有效地改善YOLOX-S模型训练指标情况。

Figure 3. Diagram of mAP changes in model training
图3. 模型训练mAP变化示意图
通过多次改进损失函数和添加注意力机制训练,YOLOX-S网络改进实验结果见表2,首先考虑应用单个改进的YOLOX-S的目标检测性能指标情况。其中,添加注意力机制CBAM与采用预测框的位置回归损失EIOU_Loss对基准模型的识别性能都略有提升,分别提高了0.21%和1.23%,注意力机制表明在获取特征时关注不同特征的情况下,对某些缺陷检测的提升,会影响模型对其它种类缺陷的特征提取,整体识别性能提高不明显。但是,采用置信度损失Focal_Loss使mAP下降了4.38%,可能的原因是受到噪音的干扰,存在正负样本标注错了的情况,就会一直针对训练标错的样本,同时在推理时间方面有较大增加,另外单独使用该技巧在模型训练的验证评估环节的时间大幅增加。就单个改进措施而言,EIOU_Loss考虑了预测框的宽高差异值,解决样本中预测框回归不平衡的问题,对模型整体性能提升较好。
接下来主要考虑添加多个改进措施时的情况。由于CBAM对模型提升微小与Focal_Loss对模型的负优化,因此主要讨论EIOU_Loss与其他两种技巧的组合情况。从表2中可以看出,采用EIOU_Loss与Focal_Loss作为改进损失函数时,模型的mAP指标为89.87%,相比基准模型减少了4.36%,推理时间大幅增加。EIOU_Loss与CBAM组合对基准模型的性能最好,解决了缺陷检测中预测框的回归问题,以及通过空间和通道上两个维度提取更加丰富的特征,提高了整体缺陷类别识别准确率,其mAP值提高了1.91,推理时间仅增加0.45 ms。
最后,添加了GIOU_Loss与CBAM组合的补充对比实验,结果表明其组合能略微改善单一采用CBAM的模型性能。
综上所述,采用EIOU_Loss加注意力机制作为模型预测框位置回归损失对YOLOX-S性能提升最为明显,同时仅增加较少的推理时间。
Table 2. Improved YOLOX-S index comparison results
表2. 改进YOLOX-S指标对比结果
以改进实验中mAP指标最高的模型,即采用EIOU_Loss加注意力价值改进的YOLOX-S检测模型,多种类别金属表面缺陷的平均检测准确率达到96%以上,其中单张检测时间为14.24 ms,实验中T用于评估图像检测模型的识别速度。其中T表示的是单张图像推理时间,单位为毫秒,推理时间越小,图像检测模型识别速度越快。实际中,考虑金属工件在流水线过程中的图像动态获取时间一般低于0.3 s,再
加上单张推理时间,为检测每个金属工件的总时间。由式(5)计算可知检测速率约为每分钟200个以上。
(5)
式中,
为检测每个金属工件的总时间。
图像预测样本如图4所示,包括六类表面缺陷,其对应的缺陷的真实标签图像如图5所示。对照预测结果样本与真实标签样本可以看出,在预测框的类别检测方面未出现错误,整体识别效果较好。在图4中,目标检测模型成功识别了斑块和夹杂缺陷,存在的识别误差主要来自于缺陷的位置判断偏差与缺陷检出偏差上,图像算法模型的检测效果达到预期要求。
4. 结论
本文提出了一种改进的YOLOX-S网络的金属表面缺陷图像检测方法,首先引入了金属表面缺陷目标检测数据集NEU-DET,分析了新一代的YOLO模型YOLOX的网络结构与算法特点。针对YOLOX-S模型在金属表面缺陷数据集上检测存在的问题,提出了添加注意力机制模块与改进损失函数的优化措施。在NEU-DET数据集上通过空间和通道多维度提取缺陷特征,以及EIOU_Loss损失函数利用预测框和真实框的宽高差异值取代纵横比,并添加Focal_Loss解决预测框回归中的样本不平衡问题。实验结果表明,在不影响其它缺陷种类的检测情况下,重点提升了裂纹和氧化铁皮压入的缺陷分类准确率和定位精度,其模型整体mAP值达到了96.14%,FPS仅为14.24 ms,即金属表面多种类别缺陷平均检测准确率96%以上以及检测金属工件速率每分钟200个以上。同时由于实验中的缺陷数据集存在分布不均的问题,后续可以通过扩展更加丰富的自制数据集,提升网络结构的稳定性,进一步提高模型的泛化能力。
基金项目
四川省重点研发计划项目:高速、高精度机器仿生视觉外观检测方法研究与系统研制(2020YFG0113)。