1. 引言
民用航空发动机的制造成本大约占其全生命周期成本的百分之四十,制造成本的高低直接决定了发动机制造商的市场竞争力和利润空间。有关分析表明:民用航空发动机百分之八十五以上的制造成本通常在设计方案冻结之前就已确定,发动机制造商若想对制造成本进行有效控制,就必须在设计方案冻结之前就尽可能准确地估算出批产阶段的制造成本,从而及时优化设计方案。然而,我国民用航空发动机行业尚处于起步阶段,可参考的历史成本数据非常少。对于民用航空发动机制造商而言,在贫数据条件下开展发动机的制造成本估算工作具有非常大的挑战性。
早在20世纪80年代初,世界航空发动机主制造商就启动了基于参数法的发动机成本估算模型的研究工作,并将研究成果应用于优化发动机的设计方案之中。普惠公司开发了一套发动机全生命周期成本分析模型(Engine/Airframe Generalized Life-cycle-cost Evaluator, EAGLE),可在初步设计阶段估算出发动机在全生命周期各个阶段的成本。GE航空公司开发了一套辅助成本估算模型(Auxiliary cost estimation, ACE),模型中嵌入了发动机各部件的成本估算关系式(Cost Estimation Relationships, CERs)。随后,GE公司持续改进ACE并形成了COMPEAT$TM模型,其中囊括了34类零部件的技术和成本数据。罗罗公司也自主开发了一套发动机成本估算模型,其中的制造成本估算模块是内嵌在设计软件Genesis之内的工作包,估算原理同样是发动机各部件的CERs。根据以上标杆企业成本估算模型的发展经验可知,基于参数法建立CERs是一种能够快速实现制造成本估算的方式。然而,以上标杆企业在初期都是基于传统的参数法(例如,多元线性回归模型、指数回归模型)拟合得到CERs,估算精度并不高。当前,他们正在通过自主研发或与第三方机构合作等方式探索新的成本估算模型以提高估算精度。
我国虽然早在20世纪60年代就开始了航空发动机研制,但却长期处于测绘、仿制、改进改型的发展状态,自主研制发动机的时间较短,将成本作为独立变量融入到发动机研制设计之中的观念还未成为主流。在航空发动机的成本估算方面,国内关注的较多的是航空发动机的研制成本和维修成本的估算问题。刘若泠 [1] 在对弹用发动机研制成本和生产成本的详细分解和分析的基础上,采用了灰色系统参数建模方法建立了弹用发动机的研制成本估算模型,并且使用国外型号发动机成本和性能数据进行了算例分析。刘芳和张海涛 [2] 研究了小样本理论中的偏最小二乘法在航空发动机研制费估算中的适用性,形成了基于主要性能指标的军用航空发动机研制费参数估算模型。韩朋 [3] 利用偏最小二成回归法建立了发动机性能与维修成本关系模型,并且根据维修费用和航空发动机性能恢复的程度进行费用-效益分析。赵曼 [4] 则对国内外采用的参数法发动机维修成本估算模型进行了梳理,给出了具体的估算关系式和涉及的模型参数。以上研究虽然可以为民用航空发动机的制造成本估算工作提供一定的方法和经验借鉴,但仍然不能解决在民用航空发动机成本可用数据量不足对成本估算精度的制约问题。
增加数据集的大小是提升成本估算精度的重要途经,但收集数据往往缺乏渠道或者十分耗时、耗力。虚拟数据生成方法是实现数据集扩充的一种有效途径,常被用于机器学习中对训练数据的预处理过程。虚拟数据生成的基本原理是:基于提取出的原数据自身固有的特征、数据之间的关联关系等信息,人工合成或采用计算机生成具有相同特征和关联关系的新数据。这种方法在图像识别、大气环境检测等领域已获得广泛地应用,尤其是在提升深度学习模型的精度和训练速度方面,采用虚拟数据生成方法可以获得很好的效果 [5] [6]。
本文通过将因子分析方法与灰色预测模型结合运用,提出了一种虚拟数据生成方法 [1] [7] [8]。它可以生成任意数量的与原始数据集有相似特征的虚拟数据,显著增加可用于训练成本估算模型的样本数量,从而在一定程度上克服成本数据的贫乏对制造成本模型估算精度的制约问题。算例分析结果表明,本文提出的虚拟数据生成方法可以显著提高模型的估算精度,建立的成本估算模型的性能也显著优于常用的参数法估算模型。该项研究成果可为航空发动机设计方案优化中的制造成本控制工作提供方法支撑,以及为航空发动机的产品定价和市场营销等决策提供依据。
2. 虚拟数据生成方法
假设要生成一个样本量为H的虚拟数据集,相应的实施步骤如下:
1) 提取数据特征,重构数据:① 将用于生成虚拟数据的数据集记为
,其中,
是
维矩阵,代表收集到的n个不同型号发动机的制造成本值,
是
维的矩阵,代表与n个不同型号发动机相对应的m种性能指标的取值。② 计算
的相关系数矩阵
,以及
的特征值
和特征向量
,计算因子载荷矩阵:
,
其中,
是选取的数据特征的个数并且
。③ 对因子载荷矩阵进行最大方差正交旋转,得到旋转后的因子载荷矩阵
。④ 计算数据特征的取值:
,得到重构的数据集
。
2) 生成虚拟数据的特征值:设置迭代计数器k的取值为1,在数据特征矩阵
中每一个数据特征的取值范围
之内,随机生成一个
维的数据特征矩阵
,然后将
映射为一个
维的矩阵:
将矩阵
中包含负值或零值的行删除,并更新矩阵
。
3) 虚拟数据特征值的筛选与更新:按照第2)步的方法生成
,将
与
按行合并作为新的
。若更新后的
的行数小于H,则令
,返回第2)步;否则,随机筛选出H行数据组成最终的
,转到下一步。
4) 得到虚拟数据集:基于重构的数据集DATA2,利用灰色预测方法估算出数据集
对应的成本值
,得到一个拥有N条数据的虚拟数据集
。
在第4)步中,利用灰色预测方法估算出数据集
对应成本值
的过程如下 [2]。记原数据集DATA1中的成本值为
,性能指标序列值为:
,其中,
。首先,按照如下公式计算Y与
之间的灰色关联度
:
,
其中,
,
,
。
取
中的一条虚拟数据,令其对应的成本值等于
,组成一条临时成本数据
。将d插入到原数据集DATA1中,组成一个
维的数据集Datatemp。然后,选取灰色关联度
最高的性能指标值
作为主关键值,对Datatemp进行升序排序。记临时数据
在排序之后的序号为p,按照如下公式更新临时数据d的制造成本值
:
,
。
其中,
称为下界估算值
的比例系数,又称为白化参数。白化参数通常基于数据列之间的灰关联性和样本点之间的间隔计算得到。本文采用如下白化参数计算方法:对任意样本点
,令
,表示第p个样本点与前一个样本点的间隔,白化参数则由如下公式计算得到:
。
将更新之后的临时数据d从Datatemp中取出,放入DATA3之中。然后,从
取出下一条虚拟数据,重复上述步骤,直到全部虚拟数据的制造成本都被更新,最终得到一个拥有H条数据的虚拟数据集
。
3. 结合BP神经网络建立制造成本估算模型
3.1. 建模过程
在基于参数法的成本估算建模相关研究中,常用的参数法有:多元线性回归、偏最小二乘回归、指数回归以及BP (Back Propagation)神经网络。与前三种方法相比,BP神经网络可以隐式地学习和存贮任何“输入-输出”之间的映射关系,而无需事前提供显式的数学公式来描述这种映射关系,并且具有较好的泛化能力和容错能力 [9]。因此,本文选择采用BP神经网络方法进行制造成本估算建模。应用BP神经网络进行建模的基本原理是:将收集到的原始数据集随机划分为两个子集:训练集和测试集,利用训练集的数据训练出一个BP神经网络模型,然后用测试集中的数据评估模型的预测能力。
1) 数据集的划分与预处理
记收集到的民用航空发动机的制造成本数据集为
,其中,
代表N个不同型号民用发动机的制造成本值,
则代表N个不同型号民用发动机的m个性能指标取值。首先,将数据集D0随机划分为两个子集
和
。其次,采用上一节中所述的虚拟数据生成方法,基于训练数据集D1生成一个数据条数为H的虚拟数据集D3。然后,将D3作为训练数据集,将D2作为测试数据集。
2) BP神经网络的基本结构
BP神经网络的训练是通过输入层到输出层的计算来完成的。BP神经网络通常由1层输入层、多层隐藏层和1层输出层组成。通常来说,增加隐藏层的层数可以提升模型的训练效果,但也会增加模型的训练时间。假设共有X层隐藏层,第
层隐藏层中的神经元个数表示为
,则BP神经网络的结构可以表示为:
。其中,模型的输入是航空发动机的m个性能指标,因此,第1层输入层中有m个神经元,最后1层中只有1个神经元,代表模型的输出,即发动机的制造成本值。
3) BP神经网络的超参数优化
除了上述结构参数之外,BP神经网络中还需要设置目标函数与优化算法所需的参数,例如:学习速率lr、激活函数
、最大训练次数
、训练算法,等等 [10] [11]。以上参数被统称为BP神经网络的超参数。为了提升BP神经网络模型的性能,在应用中通常需要反复试验去获得较好的超参数组合,整个过程会耗费大量的时间和人力成本。本文将采用贝叶斯优化算法实现BP神经网络超参数的自动优化,以便用较低的成本来快速提升BP神经网络模型的估算精度。在本文建立的BP神经网络中,将对隐藏层的层数X、每个隐藏层中的神经元数量
以及学习速率lr这三类超参数进行优化。其他参数则设置如下:激活函数选择ReLU函数:
,最大训练次数取1000次,模型训练算法采用Nesterov Momentum优化算法,未述及的参数均采用默认值。
3.2. 模型的评估标准
用于评估成本估算模型性能的指标通常有两种:拟合优度R2和估算精度
。用
表示样本的实际值,
表示样本的估算值,
表示样本实际值的均值,n表示样本数据集的大小,这两种指标的计算方法可以表示为:
,
.
为了客观地评估快速成本估算模型的性能,本文将分别计算训练数据集和测试数据集上这两种指标。
4. 算例分析
4.1. 收集数据
通过对《世界航空发动机手册》(1996年)、《世界中小型航空发动机手册》(2006年)、《国外航空发动机简明手册》(2014年)以及公开的网络资源等信息的整理,收集到了34条国外涡扇航空发动机的成本与性能数据,详见表1 [12] [13] [14]。表1中的制造成本是在综合考虑报价年份、基准利率和货币单位之后,按照65%的目录价格折算得到的,折算的基准年份为2020年,统一的货币单位是美元。此外,出于信息保密的需要,表格中隐去了具体的发动机型号信息。
取上述数据集中的前30条数据组成训练数据集D1,取后4条数据组成测试数据集D2。在训练数据集上应用本文提出的虚拟数据生成方法生成一定数量的虚拟数据,从而得到一个虚拟数据集Dvirtual。将虚拟数据集Dvirtual作为输入BP神经网络模型的训练数据,训练出BP神经网络模型之后,用测试数据集D2来测试模型的预测能力。BP神经网络中的隐藏层层数X的取值范围是
,每层隐藏层中神经元的个数
的取值范围是
,学习速率lr的取值范围是
。模型的损失函数采用平方损失函数,如下:
,
其中,
代表BP神经网络模型中各层神经元的阈值和连接权等参数组成的向量,
代表采用当前参数下的模型根据输入的
计算得到的估计值,
则是相应的实际值,i代表数据的编号,m则代表数据集中的数据条数。

Table 1. Example of aeroengine cost data set
表1. 航空发动机成本数据集示例
4.2. 模型估算性能的影响因素分析
模型参数的选取是影响模型估算性能的重要因素。在上述建模过程中,共有两类模型参数:虚拟数据生成过程中的参数和BP神经网络模型的超参数。其中,虚拟数据生成过程中的参数主要是指虚拟数据生成的样本数量H,BP神经网络模型的超参数则主要包括:隐藏层的层数X、每个隐藏层中的神经元数量
以及学习速率lr。下面,将分别对这两类参数对模型估算性能的影响进行算例分析。
4.2.1. 虚拟数据生成的样本数量
为了评估虚拟生成样本数量的多少对模型估算性能的影响,在保持BP神经网络模型的隐藏层层数X为2,两层隐藏层中的神经元个数依次为:
,
,学习速率取0.01,最大迭代次数为1000次的前提下,分别记录了虚拟样本数量等于50条、100条、300条、500条、1000条、3000条、5000条和10,000条时模型的估算性能指标取值,见表2。其中,模型对测试集数据的估算误差如图1所示。观察发现,随着虚拟生成的样本数量的增加,模型对测试集的估算误差得到了明显的降低,但在样本数量大于3000条之后,估算误差基本维持在20%~25%。上述结果表明:增大虚拟生成的样本数量有利于提升模型的估算性能,但是这种提升效果会随着样本数量的增大而逐步减弱,虚拟生成的样本数量达到一定数值之后,性能提升效果将在维持在一定的水平(上下波动)。此外,由于BP神经网络的超参数采用人工随机选取,即使采用了虚拟数据生成方法来增大可用的数据量,模型的性能仍然不尽人意。如表2中所示,模型在训练集上的性能表现尚可,但在测试集上的估算误差却只能降到22.92%,拟合优度也只能达到55.32%。由此可见,模型还需要进一步通过优化超参数来提高估算性能。
Table 2. The performance of BP neural network model under different number of virtual data generation samples
表2. 不同虚拟数据生成样本数量下的BP神经网络模型的性能

Figure 1. The improvement effect of different numbers of virtual generated samples on model performance
图1. 不同虚拟生成样本数量对模型性能的提升效果
4.2.2. BP神经网络的超参数
为了评估BP神经网络的超参数选择对模型估算性能的影响,本文保持虚拟数据生成的样本数量为5000条,分别在BP神经网络的不同隐藏层数X的情况下进行了超参数优化,超参数优化的对象是学习速率lr和每个隐藏层中的神经元数量
。BP神经网络的相关研究表明,隐藏层数越多模型的性能越好,但模型的训练难度和训练时间也会大幅提高。因此,隐藏层数X的取值通常在3以内。本文分别令X等于1、2和3,模型的性能优化结果见表3。观察表3可知,在不同的隐藏层数下,模型对训练集的估算误差都可以达到0.00%,对测试集的估算误差也都能控制在15%以内,对两类数据集的拟合优度均能达到90%以上。由此可见,对BP神经网络的超参数进行优化可以显著提高模型的估算性能。当隐藏层层数X等于3时,测试集上的估算误差最小,但程序运行的时间也最长。因此,在实际的应用中,应当根据用户可接受的估算时间和估算误差来选择最适合的模型超参数。
Table 3. Bayesian parameter optimization results
表3. 贝叶斯参数优化结果
4.2.3. 估算结果的比较
根据上述分析,当BP神经网络的隐藏层层数X取3时,隐藏层最优的神经元个数为:2-16-17,最优的学习率为0.23793。基于以上参数设置,模型在训练集和测试集上的平方损失随迭代次数的变化曲线见图2。观察可知,随着训练过程中迭代次数的增加,模型的平方损失越来越小,当迭代次数大于100之后,模型已趋于收敛。这表明BP神经网络的训练速度较快,估算效率较高。此外,为了评估建立的BP神经网络模型的估算性能,本文还采用了其他三种常用的参数法成本估算模型进行了估算,分别是:多元线性回归模型、偏最小二乘回归模型和指数回归模型。这四种不同的成本估算模型的估算性能结果见表4。对比可知,本文结合虚拟数据生成方法建立的BP神经网络模型的估算误差是最小的,其在测试集上的估算误差可以控制被到7.92%,拟合优度高达94.32%。
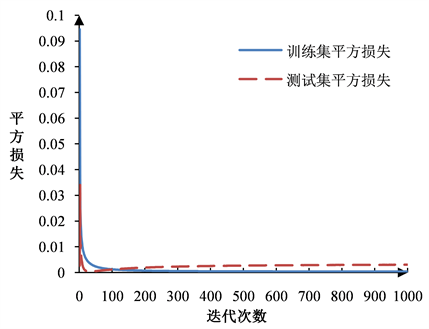
Figure 2. Variation curve of square loss in BP neural network model with the number of iterations
图2. BP神经网络模型中的平方损失随迭代次数的变化曲线
Table 4. Comparison of performance with other three commonly used parameter method models
表4. 与其他三种常用参数法模型性能的对比
5. 结论与展望
航空发动机的设计方案一旦定型,其制造成本就已基本确定。因此,发动机主制造商需要在设计阶段就估算出发动机的制造成本,以便于有针对性地改进设计方案。然而,我国的民用航空发动机行业尚处于起步阶段,在成本估算工作中可参考的历史成本数据很少。本文首先提出了一种虚拟数据生成方法,用于在贫数据条件下对成本数据集进行扩充,从而克服了成本数据量少对成本估算工作的制约问题。然后,将提出的虚拟数据生成方法与BP神经网络相结合,建立了一个制造成本估算模型并采用贝叶斯优化算法对模型的超参数进行了优化。算例分析结果表明:本文提出的虚拟数据生成方法可以显著提高模型的估算精度,建立的估算模型的性能也显著优于三种常用的参数法模型。经过超参数优化之后,模型对测试数据集的估算误差为7.92%,拟合优度为94.32%。本文的研究成果可为民用航空发动机设计方案优化中的制造成本控制工作提供方法支撑,还能够为航空发动机的产品定价和市场营销等决策提供依据。在民用航空发动机成本估算的实际工作中,发动机的构型、材料选用等因素也会对成本造成较大影响,在后续的研究中,还需要增加考虑发动机性能参数之外的因素,使成本估算模型更便于航空发动机制造企业直接应用。
基金项目
本文受航空动力基础研究项目资助。