1. 引言
在现实生活中,无线通信的环境往往是不稳定的,以往的编解码技术不能提供变速率,在实际的应用中效果往往不理想。为了解决这种现状,我们需要一种提供变速率的编解码器,即随环境质量的不同而提供不同的速率。Codec2语音编解码器支持多速率的工作要求,它能够提供多种不同的编码速率,适应不同网络及终端的实际要求。Codec2语音编解码器还能够动态地改变比特率,使通话质量随着环境的不同而得到优化。因此,研究Codec2语音编解码器具有现实意义 [1]。
语音压缩算法的研究始于上世纪六十年代,人们对于性能良好的语音压缩算法的研究一直没有停止。从20世纪70年代开始,随着数字信号处理理论逐渐走向成熟,工程师们开始对语音压缩算法的进行研究,并取得了一些基础性成果。1978年Lim和Opennheim提出了语音处理的维纳滤波方法,1979年,Boll提出了经典谱减法,1984年,Ephrain和Malah提出了基于MMSE短时谱估计的语音处理算法,1987年,Paliwal将卡尔曼滤波引入语音处理领域,奠定了噪声抑制的理论基础。国际电信联盟(IUT)在1996年提出了G729编解码算法,其核心是共轭结构代数码激励线性预测。
Codec2工程是由David Rowe在2002年启动的一个项目,Codec2编解码器是一套主要针对语音的音频压缩算法。该算法可以在较低门槛的语音应用系统中实现高性能的语音编码。另外与目前其它传统的音频编解码器相比较,Codec2算法的低时延输出性能在网络应用中也表现卓越,尤其在窄带无线网络应用上有着自己独特的优势 [2]。
2. Codec2压缩算法介绍
Codec2编解码器最初目标是为了实现一种能够利用低时延信道传递语音信息的算法,对于业余无线电来说,这种方式格外地适合HF和VHF频段上的语音信号传输。Codec2编解码器是一种开源的D-Star AMBE制式。与闭源模式相比,它是全开放的,爱好者们可以通过自己的修改和剪裁来为其他的硬件来增加Codec2支持 [3]。
2.1. Codec2 算法基本原理
采用正弦波的总和来对语音进行建模如式(1),式(2):
(1)
(2)
正弦波是基频Wo(omega-naught)的倍数,对于每一帧,我们分析语音信号并提取一组参数如式(3):
(3)
{A}是一组L振幅,{phi}是一组L相位。选择L等于4 kHz带宽中可以容纳的谐波数如式(4):
(4)
Wo以归一化为4 kHz的弧度表示,使得pi弧度 = 4 kHz。以Hz为单位的基频如式(5):
(5)
其次,我们需要编码Wo,{A},{phi},并将它们传输到重建语音的解码器。一帧的长度可能为10~20 ms,因此我们每10~20 ms更新一次参数(100到50 Hz更新速率)。
2.2. Codec2编解码器框图
语音音频是通过将语音建模为正弦波谐波的总和来重建的,这些正弦波称为线谱对LSP (Link-State Packet)的独立振幅,位于说话者声音(音高)的确定基频之上。谐波的(量化)音高和幅度(能量)被编码,LSP以数字格式通过通道交换。LSP系数代表频域中的线性预测编码LPC (Link Control Protocol)模型,有助于实现LPC参数的稳健而高效的量化 [4]。其编解码流程图如图1,图2所示。

Figure 1. Codec2 encoding flow chart
图1. Codec2编码流程图
3. STM32F4处理器的应用设计
3.1. STM32F4系列处理器介绍
STM32F405XX系列是基于高性能ARM®Cortex®-M4 32位RISC核心,其工作频率最高可达168 MHZ。Cortex-M4内核配有1个FPU浮点单元(floating point unit,浮点单元),支持所有的ARM (random-access memory)数据类型以及单精度数据处理指令。此外它配有内存保护单元MPU (Micro Processor Unit)可以执行一套完整的DSP (Digital Signal Processing)指令 [5]。
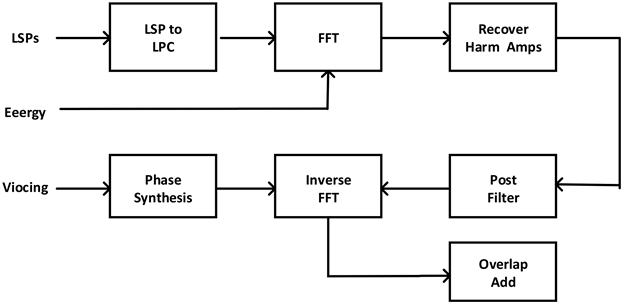
Figure 2. Codec2 decoding flow chart
图2. Codec2解码流程图
STM32F405xx系列配备了最高可达192千字节的高速嵌入式存储器和大容量的备份SRAM (Static Random-Access Memory)以及外围设备和增强的I/O [6]。所有的设备都配备了ADC、DAC、低功耗RTC (Real_Time Clock)、通用16位定时器,这些都提高了芯片的整体性能,为实现许多复杂的算法提供了条件 [7]。
3.2. 硬件流程设计
硬件中断事件驱动WM8974进行数据采集,SRAM来进行数据缓冲暂存,当完成数据采集之后,再次触发中断函数,在中断函数设置数据采集结束的信号标志,主线程通过Codec2来完成数据的编码,编码完成后压缩的Codec2数据再通过串口发送到接收端处理,处理完成后通过iis总线送到WM8947进行语言输出 [8]。STM32F405内部资源配置设计如图3所示。语言系统发送端和接收端的PCB板如图4,图5所示。
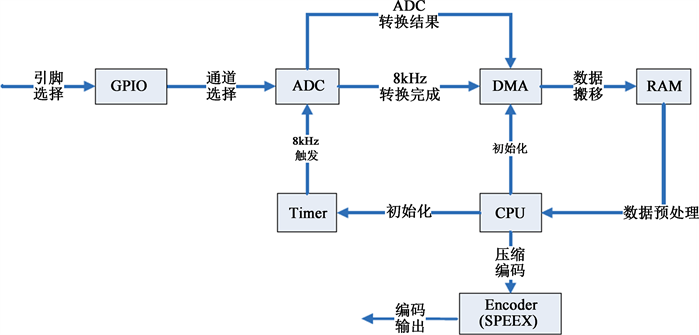
Figure 3. STM32F405 internal resource configuration design
图3. STM32F405内部资源配置设计
3.3. 软件流程设计
软件采用单线程框架结构,当完成一帧数据采集后,触发中断函数,在中断函数中设置数据采集完成标志信号,主线程获取一帧语音数据并调用编码器函数进行数据压缩编码,编码器返回压缩后的Codec2数据及长度值。软件流程如图6所示。
4. Codec2 算法移植
Codec2音频压缩算法的核心部分与硬件平台没有关系。数据采样操作,不需要调整移植算法的代码。只需要更改与特定硬件平台相关的部分,例如音频信号的进入接口,数据缓冲地址以及内存资源的分配 [7]。配置文件config.h的部分内容如图7所示。
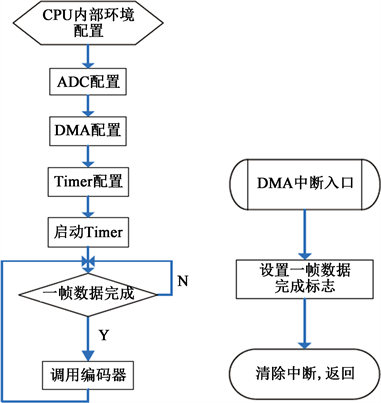
Figure 6. The software process design of speech acquisition and coding
图6. 语音采集编码软件流程设计

Figure 7. config.h file configuration
图7. config.h文件配置
编码步骤:
1) 定义一个CodecBit类型变量ebits和一个Codec编码器状态变量enc_state。
2) 调用Codec_bits_init(&ebits)初始化。
3) 调用Codec_encoder_init(&Codec_nb_mode)来初始化enc_state。其中Codec_nb_mode是CodecMode类型的变量,代表的是窄带模式。还有Codec_wv_mode表示宽带模式、Codec_uwb_mode表示超宽带模式。
4) 调用函数intCodec_encoder_ctl(void *state, int request, void *ptr)来设定编码器的参数,其中参数state表示编码器的状态;参数request表示要定义的参数类型,如CODEC GET FRAME SIZE表示设置帧大小,CODEC_SET_QUALITY表示量化大小,这决定了编码的质量;参数ptr表示要设定的值。
5) 编码结束后,调用函数Codec_bits_destory(&ebits)来销毁编码器。
解码步骤和编码步骤类似,详细过程不再叙述。
5. 整机测试
测试Codec2算法的处理性能时,系统时钟主频为600 MHz,选择的音频文件总长2039帧,语音编码速率设置在2400~9600 bps范围内时。在编码之前和解码之后采集时间值,两个结果的差值就是编解码测试文件的总的时间。测试结果如表1所示。

Table 1. Time-consuming table of different codec algorithms
表1. 不同编解码算法耗时表
以上测试结果表明:将G729A标准算法源代码直接移植到硬件上,在码率为2550以下时,Codec2算法语音质量明显比G729A算法好。处理2039帧语音数据总耗时为19,119 ms,G729A算法平均处理一帧语音数据的耗时为9.37 ms,基本能够达到算法实现实时编解码的要求(<10 ms),但属于临界区域。将Codec2算法移植到硬件上,总耗时减少为4710 ms,平均处理一帧语音数据的时间为2.31 ms,完全满足语音实时处理的要求,在低码率情况下实现了低时延的效果。
6. 结束语
本文基于STM32F4系列处理器实现了Codec2算法移植,在针对语音传输的应用系统中,可根据实际的网络环境,通过配置不同的语音编解码算法,满足了实时语音通话的业务需求。在系统测试中,该算法具有低码率的情况下低时延的优越性。