1. 引言
许多应用程序使用层次结构格式(例如XML或JSON文档)存储和传输数据。这种层次结构的数据模型非常适合本质上是分层的底层数据。此外,由于XML和JSON文档不仅包含数据还包含描述数据属性信息的元数据,因此,这类文档具有自我描述性和可移植性,很大程度提高了以不同的操作系统去使用相同数据集或文件的可能性。由于这些原因,分层的数据格式很流行用于导出数据并在不同应用程序之间传输它们。
尽管分层数据模型很方便,但仍有许多情况需要将它们转换为关系格式。例如,存储在XML文档中的数据可能需要由与关系数据库交互的现有应用程序进行查询。此外,因为分层数据模型通常不太适合高效的数据查询,当查询性能很重要时,将分层数据格式转换为关系格式是很有必要的。但在转换过程中,存在以下问题:
1) 由于源数据和目标数据的表示完全不同,所需的转换通常比结构相似的数据之间的转换更复杂。
2) 由于目标表中的每一行都对应着输入层次结构树中节点之间的关系,所以合成关系表过程中需要发现树节点之间的这些“隐藏链接”。
因此,本文采用了一种基于示例编程的方法,由一组简单的输入输出示例说明所需要的转换,这种方法通过学习生成所需任务的转换程序,并可在尽可能少的用户操作下实现将XML文档或JSON文档转换为关系数据表。
本文提出一种程序合成算法来解决层次结构数据向关系结构数据转换过程中存在的问题,该算法将层次结构数据转换成关系表的任务分解为两个子问题,列学习和行学习。目的是分别学习列和行的构造逻辑:
1) 列学习提取逻辑:给定关系表中的一个属性,本文的方法首先合成一个程序来提取对应于该属性的树节点。换句话说,本文首先忽略不同树节点之间的关系并单独构造每一列。然后取所构造列的叉积会产生一个过度近似目标表的表,这个表中包含多于目标表中元组个数的额外元组。
2) 行学习提取逻辑:由于在上一阶段学习的程序产生了一个与目标关系表过度近似的表,本文算法的这一阶段合成了一个过滤程序,该程序可以过滤掉在上一阶段产生的没有实际意义的“虚假”元组。本质上,算法的第二阶段发现了原始层次结构中不同节点之间的“隐藏链接”。
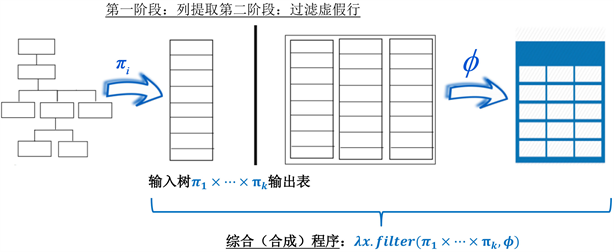
Figure 1. Schematic diagram of the synthesis algorithm
图1. 合成算法的示意图
图1中显示了本文合成算法的示意图。给定输入树T和具有k列的输出表R,本文的方法首先学习k个不同的列提取程序
,其中每个列提取程序
从T中提取存储在R的第i列中的数据。本文的合成算法然后通过将每个
应用于输入树并取其叉积来构造一个中间表。因此,在第一阶段生成的中间表
是可能包含比输出表R更多元组的过度近似目标表。在下一阶段,本文的方法学习一个谓词φ,可用于从中间表中准确过滤掉虚假元组。因此,算法合成的程序形式表达为
。此外,由于合成的程序不应该过度拟合用户提供的示例,本文的方法通过学习生成与用户提供的输入输出示例一致的最简单的程序。
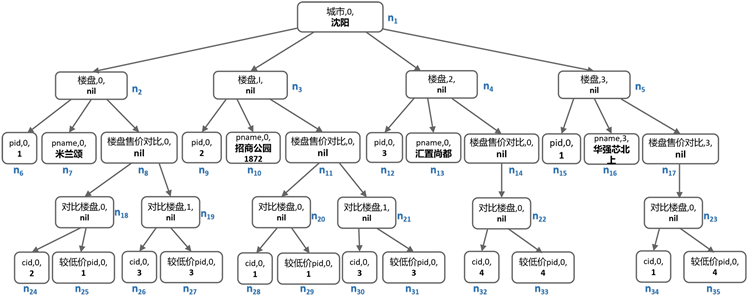
本文引用了实际项目中的城市房地产大数据,该数据是利用网络爬虫从某市房地产交易备案信息网站所爬取,并经过数据集成处理的真实数据。该实例展示了某市部分房地产楼盘的信息(其中包含有关部分楼盘的信息以及它们之间的价格关系)。接下来将使用该实例对本文的方法进行一个总体的验证。假设一个用户想要将图2(a)这个XML文档转换成图2(b)所示的关系表。这种转换非常重要,因为XML文件将这些信息存储为从每个楼盘到与之比较房价的楼盘列表的映射,其中每个对比楼盘都由他们的cid表示。相反,所需的表将该信息存储为元组(A, B, n),表示名为A的楼盘与名为B的楼盘售价比较结果是pid为n的楼盘售价更低。
假设原始XML文件比图2(a)中所示的文件大得多,因此用户决定通过提供图2中的输入输出示例来自动完成XML到关系表的转换任务,并自动合成所需的数据转换程序。
工作主要包括:
1) 引用了一种基于示例编程的方法,用于将层次结构文档迁移到关系格式。
2) 引用了一种从树到表转换的领域特定语言,它便于表达层次结构和关系结构之间的转换,可以实现许多现实世界的数据转换任务。
 (a) 输入XML
(a) 输入XML  (b)输出关系表
(b)输出关系表
Figure 2. Example of input and output
图2. 输入输出实例
3) 提出一种程序合成算法,将关系表合成任务分解,分别学习关系表行和列的构造逻辑。首先通过将每个列提取器应用于输入树并取其叉积生成中间表,然后通过学习合适的谓词过滤掉中间表中的虚假元组。最后生成一个可执行的扩展样式表语言XSLT (eXtensible Stylesheet Language)程序。
4) 通过完成城市房地产大数据实际项目中数据转换,进行实验,证明本文方法的实用性和有效性。
2. 相关研究
将分层结构化文档转换为关系格式的问题是数据转换的一种形式,其目标是将源模式的数据转换为目标模式的数据实例 [1]。由于手动执行此类转换的难度,在自动化数据转换任务方面已经开展了大量工作 [2] [3] [4] [5] [6]。Clio [2] 推广的一种常用方法将数据转换任务分解为两个独立的阶段:模式映射和转换程序生成。模式映射描述了源模式和目标模式之间的关系,通常以声明性逻辑约束的形式指定,例如GLAV (Global-Local-As-View)约束 [7]。给定一个模式映射,第二个程序生成阶段将该映射“转换”为可执行代码 [3]。因为模式映射的手动构建需要数据架构师付出不小的努力,所以在从用户提供的各种非正式规范中自动推断此类映射方面已经开展了大量工作。
例如,用户可以通过在包含相关数据的元素之间画线来指定元素对应关系 [3] [8] [9] [10] [11] [12]。最近,数据转换示例作为用户和系统之间的一种通信方式变得越来越流行。这种基于示例的方法可以根据示例的用途大致分为两类。一种方法使用示例来指定所需的模式映射 [3] [5] [6] [13]。以上这些方法都使用GLAV作为模式映射语言,因此只能处理源模式和目标模式都是关系的情况。另一种方法使用示例来帮助用户理解和改进生成的模式映射 [14] [15]。
本文可以看作是第一种方法的实例化,但在三个方面不同于以前的方法。首先,可以合成将层次结构数据转换为关系数据的程序。其次,设计了一种领域特定语言作为中间语言,它可以表达层次和关系格式之间的映射。最后,合成算法结合了有限自动机和谓词学习,以实现高效的映射生成。
有大量关于使用关系数据库管理系统存储和查询XML和JSON文档的研究 [16] - [24]。这些研究首先将文档的层次结构转换为平面的关系模式,接下来,将XML文档“分解”并加载到关系表中。最后,将XML查询转换为相应的SQL查询。这些研究方法的目标与本文不同,它们的目的是利用关系数据库管理系统有效地完成有关XML文档的查询。而本文的目的是完成关于底层数据所需关系表示的SQL查询。此外,本文实现层次结构到关系结构的转换方法也不同于现有的XML分解技术,现有的技术可以大致分为两类,即以结构为中心的方法和以模式为中心的方法。第一种方法依赖于XML文档结构来指导映射过程 [21] [25],第二种方法利用模式信息和注释来导出映射 [23] [26] [27]。
而本文在映射过程中使用输入层次结构和输出关系结构实例的方法。此外,设计的领域特定语言可以表达丰富的映射程序类别,并且在本文的合成算法中,基于有限自动机和谓词学习的技术的结合不同于以前的层次结构到关系结构的数据转换方法。
3. 基于实例的数据转换类型
3.1. 层次树模型
为了实现统一表示,本文使用层次树对层次结构文档(例如XML、HTML和JSON)进行建模,这是文献 [28] 中使用的数据结构的一种变体。
定义1:层次树(Hierarchical Data Tree)中τ是表示为二元组
的有根树,其中V是一组节点,而E是一组有向边。节点
是一个三元组(tag, pos, data),其中tag是与节点v关联的标签,pos表示v是V的父节点下带有标签tag的第pos个元素,data是对应存储在节点v的数据。
给定层次树中的节点
,符号n.tag、n.pos和n.data分别表示t、i和d。符号isLeaf(n)来表示n是层次树的叶节点。假设只有叶节点包含数据;因此,对于任何内部节点(t, i, d),本文有d = nil。最后,给定一个层次树τ,用τ.root来表示τ的根节点。
 (a) 输入XML的层次树表示
(a) 输入XML的层次树表示 (b) 中间表
(b) 中间表
Figure 3. Column extraction in the instance
图3. 实例中的列提取
XML文件作为层次结构数据,可以将XML文件表示为层次树,其中节点对应于XML中的元素。从节点v′到节点
的边表示v的XML元素e直接嵌套在由v′表示的元素e′内。此外,由于节点v包含标签t和位置i,这意味着元素e是标签为t的元素e′的第i个孩子。本文还将XML属性和文本内容建模为嵌套元素,这种设计选择允许层次树表示包含嵌套元素、属性和文本内容组合的元素。
示例1:图3(a)显示了图2(a)中XML文件的层次树表示。展现了属性如何在层次树中表示为嵌套元素。
JSON文档作为层次结构数据,将数据存储为一组嵌套的键值对。可以通过以下方式将JSON文件建模为层次树:层次树中的每个节点
对应于JSON文件中的键值对e,其中t表示键,d表示值。由于JSON文件中的值可以是数组,因此位置i对应于数组中的第i个条目。例如,如果JSON文件将键k映射到数组 [13] [18] [28],则层次树中包含的形式为(k, 0, 18),(k, 1, 45),(k, 2, 32)。从n′到n的边,n表示的键值对e嵌套在n′表示的键值对e′内。
示例2:图4显示了与图3(a)中的层次树表示相对应的JSON文档。其中JSON对象和数组表示为数据为nil的内部节点。对于给定的节点n,除非n的父节点对应于一个数组,否则n.pos = 0。
3.2. 领域特定语言
在本节中,将介绍用于实现从层次树到关系表的转换的领域特定语言(Domain-Specific Language)。本文将关系表表示为一组元组,其中每个元组都使用列表表示。给定一个关系表R,使用符号column(R, i)来表示R的第i列,并且可以互换使用术语“关系”和“表”。

Figure 5. Domain-specific language grammar
图5. 领域特定语言语法
图5为领域特定语言的语法。这里τ表示输入树,t是绑定到τ中的节点元组,n表示τ中的节点。此外,i和j是整数,c是一个常数值(字符串、整数等)。t [i]给出t中的第i个元素。
图6给出了领域特定语言的语义。在解释领域特定语言中的结构之前,重要的一点是领域特定语言的目的是实现表达能力和综合效率之间的良好平衡。也就是说,虽然DSL可以表达在实践中出现的一大类树到表的转换,但它的目的是使层次结构到表结构自动化合成变得可行。

Figure 6. Semantics of Domain-Specific Languages
图6. 领域特定语言的语义
领域特定语言的结构遵循本文将问题分解为两个单独的列和行提取操作的综合方法。程序P的形式为
,其中τ是输入层次树,ψ是从τ中提取关系R'的表提取器。如第1节所述,提取的表R′过度近似目标表R。因此,过滤器构造使用谓词ϕ过滤掉R'中未出现在R中的元组。
表提取器ψ通过取多列的叉积来构建表,其中每列中的一个条目是指向输入层次树中节点的“指针”。每列是通过将列提取器π应用于输入树的根节点来获得的。列提取器π将一组节点和一个层次树作为输入,并返回一组层次树节点。列提取器是递归定义的,可以相互嵌套:基本情况简单时返回节点的输入集,递归情况使用提取函数children、pchildren和descendants从每个输入节点中提取其他节点。其中,children提取具有给定标签的所有子项,pchildren生成具有给定标签和指定位置的所有子项,descendants返回具有给定标签的所有后代。每个构造的语义在图6中给出。
现在介绍可以在过滤器构造中使用的谓词ϕ。没有布尔连接词的原子谓词是通过将存储在层次树节点中的数据与常量c进行比较或与存储在另一个树节点中的数据进行比较来获得的。特别是,谓词使用节点提取器φ以树节点作为输入并返回另一个树节点。与列提取器类似,节点提取器是递归定义的,并且可以相互嵌套。节点提取器允许访问父节点和子节点,因此可用于从给定的输入节点中提取层次树内的任意节点(图6给出了语义)。
回到谓词的定义,ϕ接受一个元组t并计算为一个布尔值,指示t是否应该保留在输出表中。最简单的谓词
首先提取t的第i个条目n,然后使用节点提取器φ从n中获取另一个树节点n'如果
为真,则此谓词的计算结果为真。
的语义是相似的,它比较了存储在两个树节点n,n'的值。如果n,n'都是叶节点,那么检查关系
是否满足。如果它们是内部节点并且运算符
是相等的,那么检查n,n'是否指的是同一个节点。否则,谓词评估为假。使用标准布尔连接词Ù,Ú,Ø可以获得更复杂的谓词。
 (a) Input XML
(a) Input XML  (b) Output relation
(b) Output relation  (c) Synthesized program
(c) Synthesized program
Figure 7. Synthesis program for example input and output and example 3
图7. 输入输出示例和示例3的综合程序
示例3:考虑图7中所示的数据转换任务,其目的是将XML文件中每个id小于20的对象元素的文本值映射到其直接嵌套对象元素的文本值。图7(c)显示了这种转换的DSL程序。在这里,列提取器π1、π2使用提取函数descendants和pchildren来提取所有带有标签文本的子节点,并且可以从根节点到达任何对象节点的pos 0。谓词ϕ1过滤掉所有元组中第一个元素的id大于或等于20的元组。第二个谓词ϕ2确保元组中的第二个元素直接嵌套在第一个元素内。
3.3. 合成算法
本节中介绍用于将层次树从输入输出示例转换为关系表的合成算法。通过对目标数据库中的每个表执行一次算法,本文的方法可用于将XML或JSON文档转换为关系表。
合成算法的顶层结构在算法1中给出。该算法采用一组形式为
的输入—输出示例,其中每个Ti代表一个层次树(输入示例)和Ri表示其所需的关系表表示(输出示例)。
由于目标表的模式在实际中通常是固定的,本文假设所有输出表(即Ri)具有相同数量的列。给定这些输入输出示例,学习转换过程(Learn Transformation)在本文的DSL中返回一个与所有输入输出示例一致的程序P*外,由于P*是满足规范的最简单的DSL程序,因此预设它是一个不会过拟合示例的通用程序。
本文的方法将合任务分解为提取列和行的两个阶段。在第一阶段,合成了一个列提取程序,该程序提取的列与输出表R中的每一列过度近似。通过这些列提取程序得到的列的笛卡尔积进一步产生了一个过度近似目标表R的表R′。第二阶段,本文学习了一个谓词ϕ,过滤掉R′中没有出现在输出表R中的“虚假”元组。
现在介绍更详细地算法1中的学习转换过程(Learn Transformation)。总体合成算法首先调用列学习提取过程(Learn Col Extractors),该过程学习一组列提取表达式Πj,这样在每个Ti上应用任何
都会产生产生一列,该列高度近似表Ri中的第j列(第4~5行)。
本文算法基于确定性有限自动机的列学习提取过程,将在第3.3.1节中更详细地描述。
当每列有了单独的列提取程序后,就可以通过获取每个列提取程序的笛卡尔积来获得所有可能的表提取程序的集合(第6行)。因此,将每个表提取程序
应用于输入树Ti会产生一个表
,它高度近似输出表Ri。
合成算法的下一步(第7~12行)学习过滤器构造中使用的谓词。对于每个表提取程序
,本文使用学习一个谓词
,使得
与示例一致。具体来说,学习谓词过程(Learn Predicate)产生一个谓词,过滤掉
中的虚假元组。
如果没有这样的谓词,学习谓词过程(Learn Predicate)返回⊥。本文的谓词学习算法使用整数线性规划来推断具有最少原子谓词数量的最简单公式。本文在第3.3.2节中更详细地描述了Learn Predicate算法。
由于可能有多个DSL程序满足提供的示例,本文的方法使用奥卡姆剃刀原理在不同的解决方案之间进行选择。特别是,算法1使用启发式成本函数θ来确定哪个解决方案更简单(第12行),因此保证返回一个最小化θ值的程序。即θ为使用复谓词或列提取器的程序分配了更高的成本。
3.3.1. 列学习提取程序
本文用于列学习提取程序的方法基于确定性有限自动机(Deterministic Fifinite Automata)。给定一棵树(输入示例)和单列(输出示例),本文的方法构造了一个DFA,其语言完全接受与输入–输出示例一致的列提取程序集。如果有多个输入输出示例,则为每个示例构建一个单独的DFA,然后取它们的交集。生成DFA的语言包括与所有示例一致的列提取程序。

Figure 8. FTA construction rules. T is the input tree, R is the output table, and i is the column to extract
图8. FTA构建规则。T是输入树,R是输出表,i是要提取的列
算法2首先构建一组示例ε′,将每个输入树映射到输出表的第i列(第4行)。然后,对于每个示例
,本文构建一个确定性有限自动机,代表所有与e一致的列提取程序(第5~8行)。与所有示例ε′一致的程序集对应于第9行的交叉自动机A的语言。特别是,第8行中使用的Intersect程序是DFA [29] 的标准交叉程序。具体来说,两个DFA,A1和A2的交集只接受A1和A2都接受的程序,并通过取A1和A2的笛卡尔积并将接受状态定义为形式(q1, q2),其中q1和q2分别接受A1和A2的状态。
列学习提取过程的关键部分是构建DFA方法,它使用图8所示的规则从输入输出示例构建确定性有限自动机
。自动机的状态Q对应于输入HDT中的节点集。使用符号qs来表示表示节点集s的状态。字母Σ对应于DSL中列提取函数的名称,具体来说,
本文有:Σ = {childrentag|tag是T中的一个标签}
È {pchildrentag, pos|tag(pos)是T中的一个标签(位置)}
È {descendantstag|tag是T中的一个标签}
字母表中的每个符号对应一个领域特定语言操作符(使用输入层次树的标签和位置进行实例化)。DFA中的转换是使用领域特定语言运算符的语义构造的,给定领域特定语言构造
和状态qs,如果将f应用于s产生s′,则DFA包含转换
。DFA的初始状态是{T.root},本文有
如果s高度近似表R中的第i列。
图8中所示的构造规则。其中规则(1)~(4)处理本文DSL中的列提取器构造并构造状态和/或转换。第一条规则添加q{T.root}作为初始状态,因为层次树的根节点是直接可达的。第二条规则添加状态
和转换
如果children(s, tag)的计算结果为s′。规则(3)和(4)与规则(2)类似,处理剩余的列提取函数pchildren和descendants。例如,如果pchildren(s, tag, pos)的计算结果为s′,则本文有
。图8中的最后一条规则标识了最终状态。特别地,如果s是目标列(即输出示例)的超集,则状态qs是最终状态。
定理1:令A为算法2为一组输入输出示例ε和列号i构造的DFA。然后,A在本文的领域特定语言中接受列提取程序π,iff
。
。
示例4:假设使用图8中的规则构建的DFA接受单词xy,其中x = descendantsobject和y = pchildrentext, 0。这个词对应于以下列提取程序:
如果T是输入示例,而column(R, i)是输出示例,那么本文有
。
3.3.2. 学习谓词
该算法首先构建可用于公式ϕ(第4步)的所有可能原子谓词的(有限) Φ。这些谓词是使用图9中的规则为一组输入–输出示例ε和候选表提取器ψ构建的。其中
表示一组节点提取器,可以应用于为第i列提取的节点。根据这个规则,生成一个最小谓词
。如果i是范围
中的有效列号,c是输入表之一中的常量,并且φ是第i列的有效节点提取器。图9中的规则(1)~(3)定义了节点提取器φ对列i有效的含义,表示为
。如果对生成的中间表的第i列中的任何条目应用φ不会“引发异常”(即产生⊥),可以称φ是第i列的有效节点提取器。

Figure 9. Predicate library construction rules
图9. 谓词库构建规则
算法3的第5步到第10步是构建一组正例和负例用于学习谓词。正例指的是应该出现在所需输出表中的元组,负例对应应该被过滤掉的元组。谓词学习器的目标是在谓词库Φ中的原子谓词上找到一个,使得对所有正例评估为真,对所有负例评估为假。即充当和之间的分类器。
为了学习合适的分类器,本文的算法首先学习了区分
样本和
样本所必需的最小谓词集。由于本文的目标是合成一个不会过拟合输入输出示例的通用程序,因此需要合成谓词
尽可能简单。本文将寻找最简单分类器的问题表述为整数线性规划(ILP)和逻辑最小化 [30] [31] 的组合。使用ILP来学习必须在分类器中使用的最小谓词Φ*集合,然后使用逻辑最小化技术Φ*在上找到具有最少布尔连接词数量的。
本文查找最小谓词集的方法在算法4中给出。通过以下方式将其减少到0~1 ILP来解决这个优化问题:首先引入一个指示变量
,如果
被选择在Φ*中,则
,否则
。然后,对于每个谓词
和每对示例(
),引入一个常数变量
,如果谓词
区分
和
,我们将
赋值为1,否则赋值为0。观察到每个
的值是已知的,而对每个变量
的赋值是有待确定的。
回到算法3,查找最小谓词过程(第11行)的返回值Φ*对应于必须在分类器中使用的最小谓词集;然而,本文仍然需要在Φ*中找到谓词的布尔组合,以区分
样本和
样本。在Φ*中的谓词上找到最小分类器的问题作为逻辑最小化问题 [30] [32]。给定一组谓词Φ*,本文的目标是在Φ*中的谓词上找到最小的DNF公式ϕ,使得ϕ对于任何正例评估为真,对于任何负例评估为假。为了解决这个问题,本文首先构建一个(部分)真值表,其中行对应于
中的示例,列对应于Φ*中的谓词。如果谓词
为真,例如
,则真值表的第i行和第j列中的条目为真,否则为假。目标布尔函数ϕ应该对任何
评估为真,对任何
评估为假。由于本文有一个描述目标布尔函数的真值表,本文可以使用标准技术,例如Quine-McCluskey方法 [30] [32],找到表示分类器ϕ的最小DNF公式。
定理2:给定示例ε和表提取器ψ,使得
,
,如果本文的DSL中存在这样的公式
,使得
,算法3返回最小DNF公式ϕ。
例5:考虑谓词域
,一组正例
,和一组负例
与图7(a)中给出的真值表。此处,图7(a)的第ei行和第
列的条目为真,只要元组ei满足谓词
。谓词学习器的目标是找到一个公式
具有最少数量的原子谓词
,使得它对所有正例评估为真,对所有负例评估为假。为此,查找最小谓词过程首先找到所需的最小谓词Φ*子集,如算法4中所述。

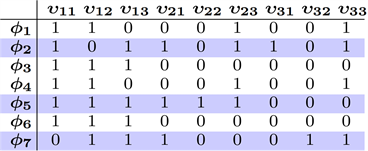

(a) 谓词全域Φ、正例
和负例
的初始真值 (b) 在算法4中分配的
的值。这里
对应于
表(c) 算法3构建的真值表
Figure 10. Truth table and values for Example 5
图10. 示例5的
真值表和值
图10显示了算法4第6行中分配的
值。特别是,图10的行
和列
处的条目为真,当条件是
为真。图10(b)中突出显示的行表示使用整数线性规划选择在Φ*中的谓词。找到
后,第12~14行算法3生成(部分)真值表,如图10(c)所示。与这个真值表一致的最小DNF公式是
,所以本文的算法返回这个公式作为分类器。
4. 实验
4.1. 实验目的
本文进行了两组实验,旨在分别验证合成算法实现层次模型到关系模型数据转换的效果,以及完成现实数据集转换任务的效率。第一个实验在从某地产收集的已经完成树到表转换任务的数据集上评估本文算法的精度和运行时间,第二个实验是使用本文的方法将现实城市地产的层次模型数据集转换为关系模型,实现数据模式转换。
4.2. 实验数据集
本文使用了某城市房地产的相关数据集,也是本文示例中数据集的来源。包含某城市大约四十万条的房地产信息,第一个实验采用的是从相关网站抓取数据后,已经完成层次结构到关系表转换的数据集,包含了具有统一目标结构的楼盘表、楼栋表、户表、许可表、等表结构的数据。第二个实验使用了某地产两个需要转换为目标关系模型的现实城市地产数据集。两个实验使用的数据都包含了XML和JSON文件。
4.3. 精度和运行时间
在评估算法精度和运行时间实验中,使用了38个(21个XML文件,17个JSON文件)某地产收集的已经完成树到表转换任务的数据集。直接从38个基准测试中获取的输入XML/JSON文件作为输入示例。对于输出示例,一部分使用某地产提供的表格,另一部分采用构建所需输出表的方式。对于每个基准,使用算法合成一个执行给定任务的程序。手动检查了输出,以查看合成程序是否执行所需的功能。

Table 1. Summary of trial evaluations
表1. 试验评估总结
表1总结了在这38个基准上评估算法的结果。该表的第一部分提供了有关基准数据集的信息,分别是按照列数划分的每个类别中基准数,能够正确解决的基准数量。本文的方法能够为92.1%的这些基准测试同步目标程序。
“合成时间”下的列显示合成所需程序所需的中位数和平均时间(以秒为单位)。取平均数时,在3.8秒内合成目标转换,中位时间为0.5秒。
4.4. 实现关系模式转换
在这个实验中,首先对于每个目标表,提供一对输入输出示例,以及关系模型中所有主键和外键的列表。然后检查合成程序并验证其正确性。该实验的结果总结在表2中。
Table 2. Hierarchical model real estate dataset to relational model data conversion
表2. 层次模型真实地产数据集到关系模型数据转换
“数据库”下的列显示了目标关系模型中的表数和属性总数。“合成”下的两列分别显示总合成时间和平均合成时间。平均时间表示每个表的合成时间,总时间是合成所有数据库表时间的和。如表2所示,每个数据库表的平均合成时间在1.2到2.7秒之间。
最后一部分显示合成程序在原始完整数据集上的执行时间的统计信息。这些数据表明,本文的方法可用于实现真实数据集的层次模型到关系模型的数据转换。
5. 总结
本文提出了一种基于示例编程的方法,用于将XML和JSON文档等层次模型数据转换为关系模型。方法的核心思想是将合成任务分解为两个阶段,分别进行列学习和行学习。通过给定一个小的输入输出示例,算法合成所需的数据转换程序。根据收集的现实XML和JSON数据集,并经过实验验证,本文提出的方法能够为现实世界的层次结构数据合成所需的程序,实现到关系模型的数据转换。测试结果符合精度和运行时间的要求,并在很少的用户操作下完成将XML文档或JSON文档转换为关系数据表。不仅便于高效的数据提取,满足用户进行存储和查询的需求,而且减少了转换设计工作,减少了人力消耗。
参考文献