1. 引言
机器学习分类实验的效果,主要根据验证集或测试集的分类预测情况用指标进行衡量,而各种分类指标从不同的方面对预测结果进行了计算和度量。各种研究论文中,最常用的是基于混淆矩阵的分类评价指标体系 [1] - [7],其中,最常用的计算指标之一是分类准确率(Accuracy) [2] - [7],用来衡量整体效果,是总整体上看有多少样本被分类正确;其次是分类准确率(Precision) [1] [3] [4],用于衡量正确预测的正类样本数占所有被预测为正类的样本数的比例,这个指标只关注正类样本的情况;经常和Accuracy或Precision一起用,还有召回率(Recall) [1] [2] [3] [4],它关注分类正确的正类样本个数占所有正类个数的比例;再者是混淆矩阵(Confusion Matrix) [4] [7] [8],它给出每类样本被分到各个类别的数目,可以从它计算出很多其它的分类指标,比如Accuracy、Precision、Recall等,其中Precision和Recall都只关注正类样本的分类情况,这可能是在研究某些问题的时候,确实只关注正类样本就够了。在这些可计算的分类性能度量的指标基础上,还有一些别的指标,有的是致力于改进前面一些指标单方面的不足,综合和均衡前面多个指标,比如F1-score [1] [3] [7],目的在于均衡Precision和Recall,构造一个综合的分类衡量指标;G-mean值 [9],是对正类和负类的Recall进行综合表达;和Matthews相关系数 [10],是根据混淆矩阵构造的一个综合指标;Kappa系数也是根据混淆矩阵中的值进行综合的一个衡量样本实际类别与模型预测类别一致程度的指标 [7]。关于分类性能衡量的可视化手段,有P_R曲线 [7] 和ROC曲线 [11] [12],其中,P-R曲线,是根据分类器对于Precision还是Recall的重视程度而取不同的阈值得到;ROC曲线,是利用正类中被预测为正类的比例,以及负类中被预测成负类的比例,分别做成横纵坐标,形成的曲线,该曲线下的面积称为AUC值,这个值越大,分类效果越好。
对于这些指标,多数论文是选择某些指标来衡量其分类效果,很少有论文综合研究这些指标,其中,文献 [13] 对分类指标做了综述,从基于错误率的、基于混淆矩阵的和基于统计显著性检验的三大类性能度量方面进行了指标综述,列出了每一个指标的就算原理,并针对一个取值范围在[0, 1]的数据集,采用最近邻(KNN)和最优子集回归两种方法进行回归和分类实验,将计算得到的各个指标值列在一起进行了对比和相关性分析,得到的结论是:在进行算法性能度量时,应根据实际的任务需求来选择适用的性能度量指标,且应综合分析多种性能度量指标的结果,给出一个相对准确的结论。这说明各个指标具有自己的特点,并不能相互代替,研究者们可以根据不同的需求选择使用不同的指标。但这个论文并没有给出实践代码以供参考,并且对于大家最常使用的基于混淆矩阵的指标体系总结的不够全面。我们希望把最常用的基于混淆矩阵的指标进行更全面的总结,并且给出在一份实际的机器学习数据集上针对BP网络进行的python实验及指标计算过程和相关代码等,为读着提供更有效的参考。
另外,这些衡量指标,大部分指标既可以针对二分类情况,又可以针对多分类情况,但有很少几个指标目前为止都只针对二分类情况,比计算指标中的G-mean值和Matthews相关系数,又比如可视化手段的P_R曲线和ROC曲线。本文针对G-mean值和Matthews相关系数,做了三分类以上的推广,定义出相应的python函数,并进行了相应的验证实验。
2. 实验数据集及混淆矩阵
2.1. 实验数据集
为验证机器学习各种分类评价指标,本文使用UCI数据库中Vehicle Silhouettes (汽车轮廓)数据集中前三个类别的数据和sklearn中的MLPClassifier分类器,进行BP神经网络分类实验,并将各种分类评价指标进行总结、分析。
原始数据利用从汽车轮廓中提取的一组特征,将给定的样本分类为四种类型的车辆之一。其中共前三个类别包括647条样本,每条样本有18个指标,倒数第二列为样本的真实类别,包括opel、saab、bus、van四种类型,最后一列为类别标号。下面表1展示了该数据集的部分数据。

Table 1. Some data of Vihicle Silhouettes dataset
表1. Vehicle Silhouettes数据集部分数据
导入所需的程序包,代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import matthews_corrcoef
from sklearn.metrics import f1_score
from sklearn.metrics import cohen_kappa_score
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import plot_roc_curve
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
先对各指标数据分别进行归一化,再取出归一化后的数据集中前两类的数据,共430条样本,其中70%作为训练集,30%作为测试集。将训练集代入二分类BP网络中进行训练,并得到测试集的预测类别结果,代码如下:
#生成二分类训练集和测试集
X_binary = vehicle.iloc[:430, :18]
X_binary = (X_binary-np.min(X_binary))/(np.max(X_binary)-np.min(X_binary))
Y_binary = vehicle.iloc[:430, 19]
X_binary_train, X_binary_test, Y_binary_train, Y_binary_test = train_test_split(
X_binary, Y_binary, test_size = 0.3, random_state = 8)
#训练二分类BP神经网络
clf_binary = MLPClassifier(solver = 'lbfgs', hidden_layer_sizes = (5, 5),
activation = 'logistic',max_iter = 30, random_state = 0)#共两个隐藏层,每层5个节点,激活函数为logistic函数,最大训练步数30步。
clf_binary.fit(X_binary_train, Y_binary_train)
Y_binary_pred = clf_binary.predict(X_binary_test)
先对各指标数据分别进行归一化,再取出归一化后的数据集中前三类的数据,共647条样本,其中70%作为训练集,30%作为测试集。将训练集代入多分类BP网络中进行训练,并得到测试集的预测类别结果,代码如下:
#生成多分类训练集和测试集
X_multi = vehicle.iloc[:, :18]
X_multi = (X_multi-np.min(X_multi))/(np.max(X_multi)-np.min(X_multi))
Y_multi = vehicle.iloc[:, 19]
X_multi_train, X_multi_test, Y_multi_train, Y_multi_test = train_test_split(
X_multi, Y_multi, test_size = 0.3, random_state = 8)
#训练多分类器BP神经网络
clf_multi = MLPClassifier(solver = 'lbfgs', hidden_layer_sizes = (8, 6),
activation = 'logistic',max_iter = 200, random_state = 0)#共两个隐藏层,第一层8个节点,第二层6个节点,激活函数为logistic函数,最大训练步数200步。
clf_multi.fit(X_multi_train, Y_multi_train)
Y_multi_pred = clf_multi.predict(X_multi_test)
2.2. 混淆矩阵及相应Python实现
混淆矩阵(Confusion Matrix),是评价机器学习分类精度的一种常见指标,其每一行代表样本的真实类别,每一列代表样本的预测类别。
1) 二分类混淆矩阵
在二分类情况下,混淆矩阵如图1所示,由TP,FN,FP,TN组成。
其中TP为实际是正类,预测为正类的样本数;FN为实际是正类,预测为负类的样本数;FP为实际是负类,预测为正类的样本数;TN为实际是负类,预测为负类的样本数。相应Python实验代码如下:
confusion_binary = confusion_matrix(Y_binary_test, Y_binary_pred)
得到二分类混淆矩阵为:
从混淆矩阵中可以看出,第0类只有2个样本被错误预测为第1类;第1类有8个样本被错误预测为第0类,说明整体预测效果较好。
2) 多分类混淆矩阵
在多分类情况下,以三分类为例,把其中一类当正类,另外两类当负类,分别针对三类中每一类进行计算,混淆矩阵如图2所示,由T00,F01,F02,F10,T11,F12,F20,F21和T22九个元素组成。
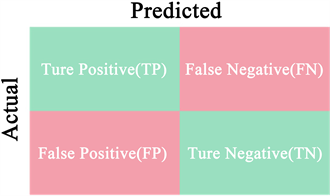
Figure 1. Confusion matrix for binary classification
图1. 二分类混淆矩阵

Figure 2. Confusion matrix for three classification
图2. 三分类混淆矩阵
图中第一行代表第0类的情况,T00表示本身是第0类,又被模型预测到第0类的样本数;F01表示本身是第0类,但是被模型预测到第1类的样本数;F02表示本身是第0类,但是被模型预测到第2类的样本数。
图中第二行代表第1类的情况,F10表示本身是第1类,但是被模型预测到第0类的样本数;T11表示本身是第1类,又被模型预测到第1类的样本数;F12表示本身是第1类,但是被模型预测到第2类的样本数。
图中第三行代表第2类的情况,F20表示本身是第2类,但是被模型预测到第0类的样本数;F21表示本身是第2类,但是被模型预测到第1类的样本数;T22表示本身是第2类,又被模型预测到第2类的样本数。
相应Python实验代码如下:
confusion_multi = confusion_matrix(Y_multi_test, Y_multi_pred)
得到的三分类混淆矩阵为:
从混淆矩阵中可以看出,第0类样本全部预测正确;第1类有3个样本被错误预测为第0类,有17个样本被错误预测为第2类;第2类有5个样本被错误预测为第0类,有17个样本被错误预测为第1类,说明整体预测效果较好。
三类以上情况与以上类似。
3. 计算指标
3.1. 单个计算指标
1) 准确率
准确率(Accuracy),是指正确分类样本数占样本总量的比例,可用来评价模型整体预测效果。
在二分类情况下,如下面的公式:
公式中TP (True Positive)代表本身是正类,又被模型预测到正类的样本数;TN (True Negative)代表本身是负类,又被模型预测到负类的样本数;FP (False Positive)代表本身是负类,但是被模型预测到正类的样本数;FN (False Negative)代表本身是正类,但被模型预测到负类的样本数。相应Python实验代码如下:
accuracy_binary = accuracy_score(Y_binary_test, Y_binary_pred)
得到测试样本的准确率为0.9225,说明模型整体预测效果很好。
在多分类情况下,准确率就等于被模型正确预测的样本数总数占总样本数的比例,如下面的公式:
公式中Tii表示本身是第i类,又被模型预测到第i类的样本数;Fij表示本身是第i类,但是被模型预测到第j类的样本数。相应Python实验代码如下:
accuracy_multi = accuracy_score(Y_multi_test, Y_multi_pred)
得到测试样本的准确率为0.7846,说明模型整体预测效果较好。
2) 召回率
召回率(Recall),是指分类正确的正类样本个数占所有正类个数的比例,可用来评价正类样本的预测效果。由于在实际分类工作中,正类样本数往往是少数,被错分的代价也更高,所以模型拥有较高的正类召回率是很重要的。
在二分类情况下,如下面的公式:
公式中TP (True Positive)代表本身是正类,又被模型预测到正类的样本数;FN (False Negative)代表本身是正类,但被模型预测到负类的样本数。相应Python实验代码如下:
Recall_binary = recall_score(Y_binary_test, Y_binary_pred, average = None)
若设第0类为正类,得到的召回率为0.9683;若设第1类为正类,得到的召回率为0.8788。
在多分类情况下,可以计算每一类的召回率,某类的召回率就是该类正确预测的样本数占该类总样本数的比例,如下面的公式:
公式中Tii表示本身是第i类,又被模型预测到第i类的样本数;Fij表示本身是第i类,但是被模型预测到第j类的样本数。相应Python实验代码如下:
Recall_multi = recall_score(Y_multi_test, Y_multi_pred, average = None)#average参数设为None表示分别计算每一类的召回率
若设第0类为正类,得到的召回率为1,因为第0类的全部样本都被正确预测为第0类;若设第1类为正类,得到的召回率为0.6774;若设第2类为正类,得到的召回率为0.6812,第1类和第2类的召回率较低。
3) 精确率
精确率(Precision),是正确预测的正类样本数占所有被预测为正类的样本数的比例。二分的类情况如下:
公式中TP (True Positive)代表本身是正类,又被模型预测到正类的样本数;FP (False Positive)代表本身是负类,但是被模型预测到正类的样本数。相应Python实验代码如下:
Precision_binary = precision_score(Y_binary_test, Y_binary_pred, average = None)
若设第0类为正类,得到的精确率为0.8841;若设第1类为正类,得到的精确率为0.9667。
在多分类情况下,可以计算每一类的精确率,某类的精确率就是该类正确预测的样本数占所有被预测为该类的样本数的比例,如下面的公式:
公式中Tjj表示本身是第j类,又被模型预测到第j类的样本数;Fij表示本身是第i类,但是被模型预测到第j类的样本数。相应Python实验代码如下:
Precision_multi = precision_score(Y_multi_test, Y_multi_pred, average = None)#average参数设为None表示分别计算每一类的精确率
若设第0类为正类,得到的精确率为0.8889;若设第1类为正类,得到的精确率为0.7119;若设第2类为正类,得到的精确率为0.7344。
3.2. 综合计算指标
1) G-mean值
了解G-mean值之前,首先应明确灵敏度(Sensitive)和特异度(Specificity)。灵敏度(Sensitive)与召回率(Recall)相同,是指正确预测的正类样本数占所有正类样本数的比例。特异度(Specificity)是指正确预测的负类样本数占所有负类样本数的比例。实际上,Sensitive表示正类的召回率,Specificity表示负类的召回率,如下面的公式:
,
在二分类情况下,G-mean值等于灵敏度和特异度的几何平均数。G-mean值以相同的权重综合了正类和负类的召回率,所以对数据样本在各类的分布不敏感,即使数据很不平衡,G-mean值也能综合考虑到各类召回率,很好地评价一个分类器的性能。G-mean值越高,说明模型整体预测效果越好,如下面的公式:
公式中Sensitive表示正类的召回率,Specificity表示负类的召回率,相应Python实验代码如下:
Gmean_binary = np.sqrt(Recall_binary[0]*Recall_binary[1])
得到的G-mean值为0.9224。
在多分类情况下,我们认为也可以将各个类别的召回率求几何平均数得到多分类的G-mean值,其值越高,说明模型整体预测效果越好,如下面的公式:
公式中Recalli表示第i类的召回率,将n个类别的召回率相乘再开n次方,得到其几何平均值,即多分类G-mean值。相应Python实验代码如下:
Gmean_multi = math.pow(Recall_multi[0]*Recall_multi[1]*Recall_multi[2], 1/3)
得到的G-mean值为0.7727。
对于三分类以上的情况,也可以将装有各类召回率的列表代入如下函数求G-mean值,代码如下:
import math
def Gmean(Recall_list):
G = 1; n=len(Recall_list)
for Recall in Recall_list:
G = G*Recall
return math.pow(G, 1/n)
2) Matthews相关系数
Matthews相关系数(Matthews correlation coefficient, MCC),用一个值综合混淆矩阵,度量真实值与预测值之间的相关性。
在二分类情况下,公式中分母含有四项,分子含有两项,如下面的公式:
分母中第一项(TP + FP)表示所有被预测为正类的样本数,第四项(TN + FN)表示所有被预测为负类的样本数,第二项(TP + FN)表示测试集中实际为正类的样本数,第三项(TN + FN)表示测试集中实际为负类的样本数。如果模型将所有测试样本全部预测为正类(分母第四项为0)或负类(分母第一项为0),整个公式分母也为0,应认为这是一个随机分类器,Matthews相关系数应指定为0。如果测试集中本没有正类样本(分母第二项为0),或负类样本(分母第三项为0),则Matthews相关系数没有意义。
分子中第一项(TP × TN)表示所有被正确预测的样本数的乘积,第二项(FP × FN)表示所有被错误预测的样本数的乘积。
Matthews相关系数值介于[−1, 1]之间:
MCC = 1时,FP和FN均为0,则分子第二项为0,分母为
,这表示每一类测试样本全部都正确预测到该类,分类器是完美的,分类结果全部正确。
MCC = 0时,一种情况是由于模型将所有测试样本全部预测为正类或负类,此时分类器是随机分类器;另一种情况是公式的分子两项之差恰好为0,此时MCC值也恰好为0。
MCC = −1时,TP和TN均为0,则分子第一项为0,分母为
,这表示每一类测试样本全部都被错误预测,分类器是最差的,分类结果全部错误。
相应Python实验代码如下:
MCC_binary = matthews_corrcoef(Y_binary_test, Y_binary_pred)
得到的Matthews相关系数值为:0.8489。
在多分类情况下,我们认为也可以将Matthews相关系数推广到多分类问题上,如下面的公式:
以三分类情况为例,如下面的公式:
与二分类情况类似,公式中分子表示所有被正确预测的样本数的乘积减去所有被错误预测的样本数的乘积;分母中第一行共六项,每类两项,共三类,表示实际属于各类的测试样本被正确预测的样本数(Tii)分别与错误预测至其他各类的样本数之和;分母第二行共六项,每类两项,共三类,表示实际属于各类的测试样本被正确预测的样本数(Tii)分别与其他各类错误预测至该类的样本数之和。
可以将混淆矩阵代入如下函数求得多分类的Matthews相关系数,代码如下:
import math
def MCC(confusion_matrix):
n = confusion_matrix.shape [1]
T = 1; F = 1
for i in range(n):
T = T*confusion_matrix[i,i]
for i in range(n):
for j in range(n):
if j! = i:
F = F*confusion_matrix[i,j]
Actual = 1; Predict = 1
for i in range(n):
for j in range(n):
if j! = i:
Actual = Actual*math.sqrt(float(
confusion_matrix[i, i] + confusion_matrix[i, j]))
for j in range(n):
for i in range(n):
if i! = j:
Predict = Predict*math.sqrt(float(
confusion_matrix[j, j] + confusion_matrix[i, j]))
T_pow = math.pow(T, n-1)
AP = Actual*Predict
return (T_pow-F)/AP
#将多分类混淆矩阵代入函数中
MCC_multi = MCC(confusion_multi)
得到的多分类Matthews相关系数为:0.4520。
将二分类混淆矩阵代入函数中验证,得到的Matthews相关系数结果与sklearn中matthews_corrcoef函数得到的结果同为0.8489。
3) F1-Score
F-Score也称F-Measure是一种用来综合衡量模型召回率和精确率的指标。召回率(Recall)和精确率(Precision)是一对矛盾的度量,一般情况下,Recall值高时Precision值往往偏低,Precision值偏高时Recall值往往偏低。当分类置信度高时,准确率Precision偏高,召回率Recall值偏低;而分类置信度低时,准确率Precision偏低,召回率Recall值就偏高。
其中a表示权重因子,P (Precision)表示精确率,R (Recall)表示召回率,将上式变形后可得
。用类别数2分别除以上式两边,并将系数整理至右边可得
可以看出,F-Score是召回率和精确率的加权调和平均值。且对于参数a,当a > 1时表示精确率比召回率更重要,当a < 1时表示召回率比精确率更重要。a = 1时二者同样重要,由此可以引出F1-Score。
F1-Score是F-Score在a = 1时的特例,是最常用的综合衡量模型召回率和精确率的指标,是召回率和精确率的调和平均值。
在二分类情况下,如下面的公式:
,
公式中P表示精确率,R表示召回率,相应Python实验代码如下:
F1_binary = f1_score(Y_binary_test, Y_binary_pred, average = None)
若设第0类为正类,得到的F1-Score值为0.9242;若设第1类为正类,得到的F1-Score值为0.9206。
在多分类情况下,需要为f1_score函数设置合适的average参数(如表2所示),不能使用默认的‘binary’,可以根据需求计算几种不同的F1-Score值。
Table 2. Some parameters of average
表2. Average部分参数
相应Python实验代码如下:
F1_multi = f1_score(Y_multi_test, Y_multi_pred, average = None)
若设第0类为正类,得到的F1-Score值为0.9412;若设第1类为正类,得到的F1-Score值为0.6942;若设第2类为正类,得到的F1-Score值为0.7068。
F1_multi_micro = f1_score(Y_multi_test, Y_multi_pred, average = 'micro')
得到的全局F1-Score值为0.7846。
F1_multi_macro = f1_score(Y_multi_test, Y_multi_pred, average = 'macro')
得到的各类简单平均F1-Score值为0.7807。
F1_multi_weighted = f1_score(Y_multi_test, Y_multi_pred, average = 'weighted')
得到的各类加权平均F1-Score值为0.7797。
4) Kappa系数
Kappa系数是一种基于混淆矩阵计算的,用于衡量样本实际类别与模型预测类别一致程度的综合指标。如下面的公式:
其中,Po值是指正确分类的样本数除以总样本数,也就等于模型的分类准确率Accuracy;Pe值是指各类实际样本数与被模型预测到该类的样本数的乘积之和,除以混淆矩阵中各项之和的平方。
在二分类情况下,如下面的公式:
,
Pe公式中分子含有四项,其中第一项(TP + FN)表示正类的实际样本数;第二项(TP + FP)表示被模型预测到正类的样本数;第三项(TN + FP)表示负类的实际样本数;第四项(TN + FN)表示被模型预测到负类的样本数。分母表示混淆矩阵中各项之和的平方。相应的python代码如下:
Kappa_binary = cohen_kappa_score(Y_binary_test, Y_binary_pred)
得到的Kappa值为:0.8452。
在多分类情况下,如下面的公式:
,
Pe公式中分子的n项中,每一项又包含两项的乘积,其中第一项表示第i类的实际样本数;第二项表示被模型预测到第i类的样本数。分母表示混淆矩阵中各项之和的平方。相应的Python代码如下:
Kappa_multi = cohen_kappa_score(Y_multi_test, Y_multi_pred)
得到的Kappa值为:0.6768。
Kappa系数取值介于[−1, 1]之间,Kappa系数值越大说明模型分类效果越好,“样本实际类别”与“模型预测类别”这两者的一致程度越高,具体地说,就是:Kappa值在0.21~0.40内可以认为两者具有“可接受”的一致性;Kappa值在0.41~0.60内可以认为两者具有“中等”的一致性;Kappa值在0.61~0.80内可以认为两者具有“较高”的一致性;Kappa值 > 0.81可以认为两者几乎完全一致。根据Kappa系数公式,当
且
时,即所有样本都被正确预测且不全属于同一类别时,Kappa值为1,说明样本实际类别与模型预测类别两者完全一致。
另外,Kappa系数倾向于在不平衡数据集上得到更低的值。根据Pe值的公式,对于样本数在各类别中分布越不平衡的混淆矩阵,Pe值会越高,相应地,在模型分类准确率Accuracy (或者Po)相同时,Kappa系数值会更低。
4. 基于混淆矩阵的可视化指标
1) P-R曲线
P-R曲线是由准确率(Precision)和召回率(Recall)共同构成的曲线,其中横轴为召回率,纵轴为准确率。很多二分类器输出的是一个概率值(因为输出层的激活函数一般用了sigmoid或者softmax函数,它们的输出值都在0到1之间),将这个概率值与一个指定的阈值进行比较,若概率大于阈值,则分为正类,否则分为负类。实际上,可以根据概率值由大到小将测试样本排序,最可能是正例的样本排在最前面,最不可能是正例的样本排在最后面。分类的过程就相当于在这个排序中选择一个介于[0, 1]之间的阈值,阈值越接近1,分类器越重视准确率,阈值越接近0,分类器越重视召回率。选取的阈值大小不同,分类结果不同。通过改变阈值的大小,分别计算P值和R值,就得到了P-R曲线。
在二分类情况下,相应Python代码如下:
Y_prob0 = clf_binary.predict_proba(X_binary_test)[:, 0]
Y_prob1 = clf_binary.predict_proba(X_binary_test)[:, 1]
precision0,recall0,thresholds0 = precision_recall_curve(
Y_binary_test, Y_prob0, pos_label = 0)
precision1,recall1,thresholds1 = precision_recall_curve(
Y_binary_test, Y_prob1, pos_label = 1)
plt.figure()
plt.title('Precision-Recall Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.plot(recall0, precision0, label = 'Class0')
plt.plot(recall1, precision1, label = 'Class1')
plt.legend(loc = 3)
plt.show()
根据代码得到的两分类P-R曲线如图3所示。
图3中蓝色为第0类为正类时的P-R曲线,橙色为第1类为正类时的P-R曲线。现实中的P-R曲线可能是非单调、不平滑的,在很多局部有上下波动。
2) ROC曲线
ROC曲线,又称受试者工作特征曲线 (Receiver operating characteristic curve),其纵轴为真正例率(TPR),即正类中被预测为正类的比例;横轴为假正例率(FPR),即负类中被预测为负类的比例。如下面的公式:
,
利用有限个样本绘制ROC曲线图时,无法得到平滑的曲线,只能得到近似ROC曲线。对指定正类,设真正例个数为
,假正例个数为
,将所有被预测为正类的样本按分类器输出的正类概率从大到小排序。先把分类阈值设置为1,即将所有样本均预测为负类,此时真正例率和假正例率均为0,从坐标原点(0, 0)处开始绘制ROC曲线。再对排序好的测试样本,从第一位开始,每次都将分类阈值减小至该样本的输出概率,即依次将每个样本划分为正类。设前一个标记点为(x, y),若该样本为真正例,则标记
为当前点;若该样本为假正例,则标记
为当前点,用线段依次连接各标记点可得该正类的近似ROC曲线。
如果多数的正类概率大的测试样本确实属于正类,即被分类器正确预测为正类,则ROC曲线会呈现先向上再向右增长的趋势,这样的ROC曲线会靠近图左上角,ROC曲线越靠近左上角说明分类器对该类的预测效果越好;如果ROC曲线与第一象限角平分线重合,说明分类器是随机分类器;如果ROC曲线靠近右下角,说明预测效果比随机分类器还差,分类器没有预测价值。
在二分类情况下,可以通过sklearn中自带的plot_roc_curve函数通过一行代码直接画出各类的ROC曲线图(如图4和图5所示),相应Python代码:
plot_roc_curve(clf_binary, X_binary_test, Y_binary_test, pos_label = 0)
plot_roc_curve(clf_binary, X_binary_test, Y_binary_test, pos_label = 1)

Figure 4. ROC curve of Class 0 for the binary classification
图4. 二分类第0类ROC曲线

Figure 5. ROC curve of Class 1 for the binary classification
图5. 二分类第1类ROC曲线图
从第0类和第1类的ROC曲线图中可以明显看出,第0类ROC曲线的线下面积达到0.97,第1类ROC曲线的线下面积也达到0.97,且两条ROC曲线都靠近左上角,说明分类器预测效果非常好。
也可以通过sklearn中自带的roc_curve函数,将两个类别的ROC曲线画在一张图上(如图6所示)。相应Python代码:
Y_binary_prob0 = clf_binary.predict_proba(X_binary_test)[:, 0]
Y_binary_prob1 = clf_binary.predict_proba(X_binary_test)[:, 1]
FP0_binary,TP0_binary,thresholds0_binary = roc_curve(
Y_binary_test, Y_binary_prob0, pos_label = 0)
FP1_binary,TP1_binary,thresholds1_binary = roc_curve(
Y_binary_test, Y_binary_prob1, pos_label = 1)
plt.title('ROC')
plt.plot(FP0_binary, TP0_binary, label = 'Class0')
plt.plot(FP1_binary, TP1_binary, label = 'Class1')
plt.xlim([−0.1, 1.1])
plt.ylim([−0.1, 1.1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.legend(loc = 4)
plt.show()
在多分类情况下,将多个类别的ROC曲线画在一张图上(如图7所示)。相应Python代码:
Y_multi_prob0 = clf_multi.predict_proba(X_multi_test)[:, 0]
Y_multi_prob1 = clf_multi.predict_proba(X_multi_test)[:, 1]
Y_multi_prob2 = clf_multi.predict_proba(X_multi_test)[:, 2]
FP0_multi,TP0_multi,thresholds0_multi = metrics.roc_curve(
Y_multi_test, Y_multi_prob0, pos_label = 0)
FP1_multi,TP1_multi,thresholds1_multi = metrics.roc_curve(
Y_multi_test, Y_multi_prob1, pos_label = 1)
FP2_multi,TP2_multi,thresholds2_multi = metrics.roc_curve(
Y_multi_test, Y_multi_prob2, pos_label = 2)
plt.title('ROC')
plt.plot(FP0_multi, TP0_multi, label = 'Class0')
plt.plot(FP1_multi, TP1_multi, label = 'Class1')
plt.plot(FP2_multi, TP2_multi, label = 'Class2')
plt.xlim([−0.1, 1.1])
plt.ylim([−0.1, 1.1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.legend(loc = 4)
plt.show()
从图中可以看出,第0类的ROC曲线最靠近左上角,说明分类器对第0类的预测精度最高。第1类和第2类的ROC曲线有交叉,无法直接判断哪一条的线下面积更大,这就要借助AUC值来进行判断。
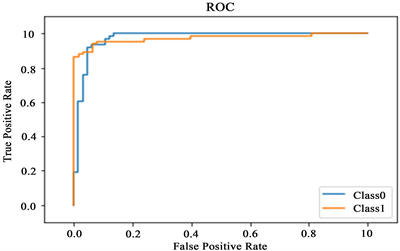
Figure 6. ROC curve of binary classification
图6. 二分类ROC曲线

Figure 7. ROC curve for multi-category classification
图7. 多分类ROC曲线
3) AUC值
AUC值(Area under curve)是指ROC曲线的右侧线下面积,可以直观衡量ROC曲线所表示的分类器预测效果的好坏。如果一类ROC曲线将另一类ROC曲线完全包住,说明分类器对前一类的预测效果好于后一类;如果两类ROC曲线有交叉,则要通过AUC值的大小来判断哪一类的预测效果好。
在二分类情况下,相应Python实验代码如下:
在多分类情况下,相应Python实验代码如下:
5. 结论
本文将机器学习的分类指标的原理进行了全面的整理和分析,针对G-mean值和Matthews相关系数做了三分类及更多分类上的推广定义,并用UCI数据集中的Vehicle Silhouettes数据在BP网络上进行训练和测试,然后根据测试情况计算各个分类指标,并给出相应的python代码,以及推广到三分类以上的G-mean值和Matthews相关系数的python函数定义。从理论和python实践方面都给读着提供参考。
基金项目
北京工商大学教育教学改革研究项目(jg215203)。