1. 引言
2022年1月,北京市人民政府发布了《北京2022年国民经济和社会发展计划报告》 [1] (以下简称“北京2022年经济发展计划报告”)。对2022年度的工作提出了新要求和新目标。其中提到:保持经济运行在合理区间,兼顾发展和需要,要求北京市地区生产总值增速保持在5%以上。
北京作为全国经济发展较好的城市之一,拥有国家级的经济技术开发区和众多发展示范区,担负着我国经济发展风向标的作用。以2021年为例,北京地区生产总值达到了4万亿元以上,创造了新的记录,增长幅度高于全国平均增速。
因此,北京的经济发展状况在一定程度上与国家战略息息相关,研究和短期预测该地区的生产总值,有利于北京市政府对经济及时进行宏观调控,能加快推动北京经济的高质量发展,也为制定下一年度本地区的经济发展目标、产业布局调整提供了参考依据,其取得的成果和经验对全国能起到示范作用。利用SARIMA模型去分析和预测生产总值,国内曾有很多学者研究过,本文参考陈玉霞 [2]、耿春燕 [3]、赵喜仓 [4] 等人的研究思路和研究方法,利用49个北京地区季度生产总值时间序列{G},简要分析各产业对北京地区生产总值的贡献情况。用差分处理的平稳序列{SdG}确定模型的阶数和参数,构建出拟合度较高的ARIMA(1,1,1)(0,1,1)4模型。本文从两方面对模型拟合情况进行检验,得出该模型拟合度较高的结论,并来于预测2022年后三季度和2023年的北京地区生产总值情况,再结合实际情况对该模型进行评价和说明。
2. 数据获取与分析
生产总值是一个国家(或地区)上所有常住单位在一定时期内生产最终产品和服务的价值总和,是衡量和判断经济发展水平最核心的指标。通过该指标可以判断该地区经济发展的快慢,可以从地区生产总值的组成情况分析出该地区的产业结构,也可以用来对比不同国家(或地区)的发展情况,是评估经济运行状况最广泛的指标之一。因此,北京2022年经济发展计划报告中直接提到了对该指标的发展要求。
对于一个国家而言,生产总值称之为GDP;但是对于一个地区而言,生产总值称为地区生产总值。两者的核算方法完全一致,只是核算区域有所不同。目前,GDP核算方法主要有三种:支出法、收入法和生产法 [5],三种核算方法的角度不一样。无论用以上哪种方法,所计算出的GDP数据应该是一致的。虽然在实际核算工作中数据会有偏差,但是偏差在可控范围内,对数据的后续分析结果影响不大。我国目前采用生产法核算GDP,在实际核算工作中,通常以产业作为核算单位,即分别计算三大产业的增加值,加总后作为该地区的生产总值,具体公式如下:
GDP (或地区生产总值) = 第一产业增加值 + 第二产业增加值 + 第三产业增加值 (1)
2.1. 数据来源
对于北京地区每个季度的生产总值及各产业增加值的数据,可以从北京市统计局官方网站的月季度数据处获取。由于数据是累积的,即没有每个季度的单独数据,因此需要对数据进行处理,用本季度累计数据减去上一季度累计数据,可得到本季度地区生产总值数据。本文用此方法,得到了2010年第一季度至2022年第一季度,共49个季度的北京地区生产总值数据。本文后续的任何分析和研究均根据此数据,具体数据见附表A1。
2.2. 北京地区生产总值简要分析
我们利用附表A1的数据,绘制图1折线图和图2簇状条形图,以此直观反映北京市地区生产总值的状况和各产业占比情况。
2.2.1. 北京地区生产总值现状
从图1中看出,除2020年第一季度因新冠疫情造成大面积停工停产,使2020年第一季度生产总值同比下降4.14%外,北京地区生产总值时间序列整体呈上升趋势,并有明显的季节性波动趋势。每年第一季度地区生产总值明显低于其他三个季度,且低于上一年第四季度的数据。可以用春节假期的因素解释此现象。春节是中国的传统节日,生产单位通常在春节期间放假停工,人们一般会提前准备置办年货,消费发生在第四季度,促进了第四季度的生产活动,以此拉高第四季度的生产总值。再加上天气因素,第一季度时个别地区会受到严寒天气影响,难以开展生产活动。

Figure 1. Line map of GDP in Beijing
图1. 北京地区生产总值折线图
2.2.2. 北京地区生产总值构成情况
为研究各产业对生产总值的贡献,绘制簇状条形图进行说明。由图2可知,第三产业的增加值是目前北京地区生产总值的主要部分,占比达到70%及以上,特别是2022年第一季度占比创新高,第三产业占比达到85.84%。这与北京大力发展高端制造服务业、高科技新技术产业的政策是密不可分的。北京2022年经济发展计划报告中再次提到要优化调整高科技、尖端产业的发展,形成新的产业集群,这标志着第三产业将继续作为北京经济发展的绝对主力,其生产总值所占比例将继续上升。
第二产业占比整体呈不断下降趋势,从2010年第一季度的23%降至2022年第一季度的14%,12年里占比降低了8%。造成下降的原因一方面,是由于第三产业相比第二产业的发展速度更为迅速,使第二产业占比相对下降;另一方面,也与北京市大气污染治理和助力“双碳”目标有关。以首都钢铁厂为代表的工业单位外迁,使第二产业比重不断下降。第一产业农、林、牧、渔业的增加值总体趋于平稳,占比一直处于较低水平。其中2010年第四季度占比最高为0.99%,占比也不超过1%。这与北京城市化程度越来越高有关。通常情况下,第一产业比重越高,说明该地区的城市化和工业化进程越低。北京作为城市化进程较高的地区之一,第一产业的发展受到了空间上的限制。根据《北京市第三次国土调查主要数据公报》北京市耕地为93,547.90公顷,占全市总面积的5.7%。
总体来看,北京的经济发展主要依靠第三产业。只要第三产业可以稳步发展,北京市的经济就能实现预期增长。
3. 模型构建与检验
AR(I)MA模型是研究时间序列数据的重要方法,是对自回归模型(AR)和移动平均模型(MA)的有机结合,常用于研究长期数据。结合图1来看,北京地区生产总值季度数据具有明显的季节性趋势。查阅相关资料后,SAR(I)MA模型考虑到了季节性因素的影响,构建此模型可以使后期预测更为准确。结合参考文献 [6] 和参考文献 [7] 的建模流程图,绘制了本文研究流程图见图3所示。
3.1. 序列处理与检验
建立SAR(I)MA模型,首先需要该时间序列具备平稳的特性。因此需要对北京地区生产总值序列{G}进行平稳性检验。
3.1.1. 数据异常值检验
在平稳性检验之前,通过绘制箱式图,查看序列中是否存在异常数据。统计学上认为,数据从小到大排列后,若处于
范围之外,则认为数据为异常值。其中,
代表下四分位数,
代表上四分位数,
(Inter quartile range)为四分位差,
。
图4箱式图表明,序列中无异常数据。下面对序列进行平稳性检验。
3.1.2. 平稳性检验
平稳性检验亦称ADF检验(Augmented Dickey-Fuller test),用于检验序列是否平稳,能排除回归分析中可能存在的伪回归现象。利用SPSSPRO软件,对序列{G}进行平稳性检验。检验结果如表1所示:

Table 1. Original sequence ADF test
表1. 原序列ADF检验
所检验统计量的p值为0.995 ? 0.05,表明在95%的显著下,{G}为不平稳序列。这一结论也可以从图1印证:观测值不是围绕某一区域内上下波动。因此需要对序列{G}进行差分处理,即:
(2)
Table 2. First-order phase-by-phase differential sequence ADF test
表2. 一阶逐期差分序列ADF检验
Table 3. First-order phase-by-phase differential-season differential ADF test
表3. 一阶逐期差分一次季节差分ADF检验
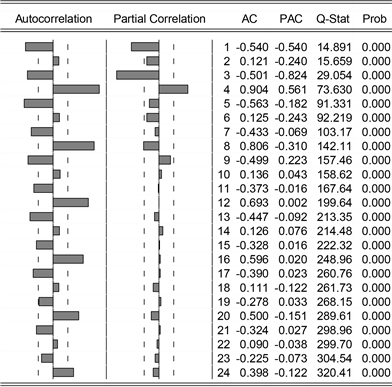
Figure 5. {dG} sequence ACF plots and PACF plots
图5. {dG}序列ACF图和PACF图
我们对一阶逐期差分后的{dG}序列进行平稳性检验,结果见表2。其p值 = 0.05,即{dG}为平稳序列。图5是Eviews软件针对序列{dG}绘制的自相关图(ACF)和偏自相关图(PACF),当滞后阶数k = 4,8,12时样本自相关系数分别为0.904,0.806,0.693与0有显著性差异,表明该序列有周期为4的季节波动,需要对序列进行季节性差分,即:
(3)
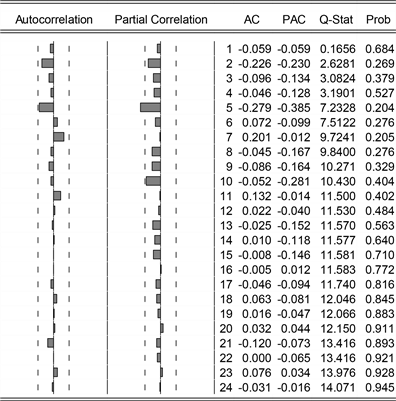
Figure 6. {SdG} sequence ACF plots and PACF plots
图6. {SdG}序列ACF图和PACF图
我们对一阶逐期差分一次季节差分后的{SdG}序列进行平稳性检验,检验结果见表3。其检验统计量的p值 = 0.05,结合图6来看,相关图有明显的衰弱趋势,即便后期有上升趋势,但是在可控范围内。表明在95%显著水平下,该序列为平稳序列。后续将用序列{SdG}构建SARIMA模型。
3.2. 模型建立
SARIMA模型亦称季节性差分自回归滑动平均模型,常用于短期预测研究中。模型共有6个阶数p、d、q、P、D、Q,其中p表示自回归的项数,q表示移动平均的项数,d表示序列的差分阶数,P表示季节自回归的项数,Q表示季节移动平均的项数,D表示序列季节差分的次数,对于季节性为s的SARIMA模型记为ARIMA(p,d,q)(P,D,Q)s具体表达式为 [8]:
(4)
各部分具体表达式如下:
序列自回归部分:
(5)
序列自移动回归部分:
(6)
序列季节性回归部分:
(7)
序列季节性移动平均部分:
(8)
其中
为白噪声序列,L可以借助差分算子求得。一阶逐期差分算子可以定义为:
(9)
则序列{Gt}一阶逐期差分算子为:
(10)
以此类推,对于季节性为s的时间序列{Gt}一次差分算子为:
(11)
3.2.1. 模型阶数确定
因一阶逐期差分一次季节差分后的序列为平稳序列,因此d = 1,D = 1。通过对平稳后序列的ACF图和PACF图来看,自回归项数p = 1,移动平均项数q = 1。对于阶数P和Q,本文借助AIC (Akaike information criterion)准则和拟合度R2进行确定。AIC信息准则是日本学者赤池弘次创立,常用于衡量模型的拟合度。通常情况下P和Q不大于2,可以通过遍历法,选取AIC值较小、R2较大时的阶数作为模型的阶数。
Table 4. AIC and R2 at different orders
表4. 不同阶数下AIC和R2
由表4可知,当P = 0,Q = 1时,AIC达到最小,R2较大。因此构建ARIMA(1,1,1)(0,1,1)4模型。
3.2.2. 模型参数估计
ARIMA(1,1,1)(0,1,1)4模型中包含4个参数
、
、
和常数C。利用SPSSPRO软件,确定P = 0,Q = 1时的4个参数。结果如下:
Table 5. ARIMA (1,1,1) (0,1,1)4 model parameter table
表5. ARIMA(1,1,1)(0,1,1)4模型参数表
注:***、**、*分别代表1%、5%、10%的显著性水平。
根据表5,具体的SARIMA模型方程为:
(12)
3.3. 模型检验
为检验模型拟合程度,也为使后期预测更具有参考意义,我们从拟合值与真实值偏差、残差序列两个方面入手,分别计算统计量MAPE和Q6。
3.3.1. 拟合值与真实值对比
我们可以将真实值和拟合值绘制一张图中,以此直观的说明对比模型拟合效果。拟合值详见附表A2。
图7中拟合曲线多出接近于真实值,直观来看拟合程度较好。为客观衡量该模型的拟合度,参考郝军章,崔玉杰等 [9] 人评价模型时使用的指标,本文将平均绝对百分比误差(Mean Absolute Percentage Error,简称MAPE)作为评价指标。
MAPE常用于衡量和描述拟合值与真实值之间离散程度的指标,适用于比率有意义的数据(分母不为0),其百分比取值范围为
。MAPE取值越小,说明拟合值与真实值偏差程度越小,模型拟合效果越好。当MAPE > 50%时,直接拒绝该模型。其具体计算公式如下:
(13)
其中n表示观测值数量,
表示序列中第i个数据的拟合值,
表示第i个真实观测值。
如表6所示,MAPE = 3.96%,即平均下来二者的偏差不会超过4%。从拟合与真实的偏差看,说明该模型拟合效果较好。

Figure 7. Model fitting and prediction plots
图7. 模型拟合和预测图
3.3.2. 残差检验
当方程拟合效果较好时,其残差序列仅受到随机因素影响,不受到自相关的影响。即残差序列
,属于白噪声序列。我们可以借助统计量Q6,即通过残差序列前6阶的相关系数来判断残差序列是否为白噪声序列,结果如下:
由表7可知,统计量Q6的p值为大于0.05,表明在显著性水平为95%的情况下不能拒绝原假设,即序列为白噪声序列。从残差序列角度来说,模型拟合效果较好。
综合以上两个方面来判断,该模型的拟合效果较好,用此模型进行预测准确会比较高。
4. 预测
由于模型拟合效果优良,因此采用ARIMA(1,1,1)(0,1,1)4模型对2022年后三季度及2023年的北京地区生产总值进行预测,结果如下:
表8显示,预测的七个季度地区生产总值呈上升趋势。2022年第四季度生产总值将突破11,000亿元;2023年第一季度生产总值接近10,000亿元,与上一年同比增长6.14%。
5. 结论与说明
结合2022年第一季度地区生产总值数据和模型预测的结果,相加后得出2022年北京地区生产总值预计为42,404.92亿元,同比2021年北京40,269.60亿元的生产总值,增速为5.30%,完成了北京2022年经济发展计划报告中5%的增速目标;预测出2023年北京地区生产总值44,718.48亿元,同比2022年的预测数值增速为5.46%。
截止到本文完成之时,北京市统计局已在官方网站上公布了2022年第二季度北京部分经济数据。经过查询,北京2022年第二季度地区生产总值为9938.7亿元,比预测值低,偏差了7.84%,略高于5%,但总体可以接受。本文认为可以从实际角度出发分析偏差略高的原因。结合2022年第一季度的生产总值来看,同比增长幅度接近于5% [10],经济实现了平稳开盘,呈现出稳步恢复的态势,为2022年北京经济打下了基础,但是奥密克戎引起的新型冠状肺炎疫情突如其来。特别是2022年4月底朝阳区、房山区等15个区域相继出现病例,并连续多日新增感染者总和超过50例以上。为减少人员聚集,很多门店采取闭店措施,部分公共交通采取甩站停驶的措施,人员不出户居家办公。这在一定程度上打破了恢复经济的步伐,使得第二季度的生产活动受到一定限制,第二季度的实际生产总值低于预测结果。
综上所述,SARIMA模型的短期预测结果具有重要的参考意义,长期预测结果偏差会很大,主要原因在于该模型未考虑到外界变量对事物本身的影响,这是该模型的主要缺点。例如本文的SARIMA模型,没有考虑到新冠肺炎疫情对第二季度生产活动的影响。但是即便如此,预测结果仍可接受的原因在于短期预测时事物自身的影响远远大于外界其他变量对事物的影响。因此本文的预测结果,可以用于判断未来短期内北京地区的经济走势,为北京地区的经济发展规模、发展结构提供重要的参考依据。
附录
Table A1. Beijing’s GDP and industrial added value in 49 quarters (Unit: 100 million yuan)
表A1. 49个季度北京地区生产总值及各产业增加值(单位:亿元)