1. 问题提出
1.1. 研究背景
2019年底,新冠肺炎疫情“悄然出现”。2020年初,该疫情开始在世界各地蔓延,以其极高的传染率以及极快的传染速度被世界卫生组织列为国际关注的突发公共卫生事件,对全国的经济以及金融方面都造成了很大影响,春节假期顺延,员工无法及时返工。尤其是一些中小企业,处于濒危状态面临着破产危机,因此引发了好多人对我国经济发展前景的担忧。疫情来势凶猛,发展迅速,经济发展遭受冲击。相较于“非典”疫情,目前服务业的经济总量显著增加,而此次疫情对行业的冲击极大,并且很难在短期内恢复。同时,中国的经济已经开始从高速向中速过渡,还存在一定的下行压力,这一突发疫情对经济的负面影响不容小觑。因此,通过建模量化预测疫情的走向,对实施相应的手段对抗疫情,积极恢复生产有重要的意义。
1.2. 主要研究动机
为防止新冠病毒的进一步肆虐,快速、高效的检测手段对检测病毒有着不可忽视的作用。而新冠肺炎病毒核酸检测是目前确定病人是否被感染最有效的方法,此方法灵敏度极高,很少出现漏检错检等情况。核酸检测是极为灵敏并且精密的实验,因此对检测实验室有特别要求。同时也需要对每个送检样本进行包装的拆解,还是双层的密封包装。数量之庞大,还要保证每一个做好酒精消毒的工作,步骤繁琐,工作重复且花费的时间极长,难度可想而知 [1]。而混合样本检测是将多个样本混合在一个采样管后进行检测。如果能保证样本质量以及检测效果,混合样本检测将大幅度提升核酸检测的能力,可以将检测速率提高几倍甚至几十倍,极为有效地利用了医疗资源。所以,在实验室中等量取不同样本混合进行核酸检测,虽然有一定程度的稀释效果,低病毒载量的样本存在假阴性的可能。但是考虑混合检测是针对低危人群的筛查,对于节约社会成本与提升检测速度有明显优势 [2]。
1.3. 前人工作简述
针对核酸的混合样本检测,在早期疫情检测能力不足时,已提出对无典型症状者的检测借鉴血站核酸检测的多样本合并检测方法,以扩大筛查对象 [3]。北京市疾病预防控制中心于2020年4月发布混合检测建议,即混合3~5个样本到1支采样管中 [4]。2020年4月,以色列团队的proof-of-concept研究验证了一种新的混合检测方案 [5]。研究选取医疗机构已检测并确认结果的样本进行试验,将384份样品划分为48个样品池,每个样品池中包含48份不同样品,而每个单一样品被加入到6个不同的样品池中。在对48个样品池进行一批次的检测后,根据阳性结果,对比样品分组从而可以直接确认个体阳性样本。该研究结论为,将同一样本分别加入几个样本池的混检方式能够有效提升检测效率,同时对敏感性和准确性影响均在可接受范围。对于以上分组方案,能够检测出的最大阳性样本数为5个,而当阳性率提高时则需要调整分组方案。这种复合混检对检测者要求更高,但是相比单纯混检所需的检测批次更少,对检测时间紧张的场合有一定价值 [6]。
1.4. 问题重述
经过论证,本文认为混合核酸检测是可取的。而一组混检样本中样本数量的不同将对核酸检测结果造成影响。因此,我们将想要解决的问题凝练成如下3个问题,并对实验所得数据进行分析并建立模型以解决:
问题一:经过混合核酸检测后,如结果为阴性,那么每个样本对应的被检测人均判定为阴性;若结果为阳性,说明检测的样本中至少有一个人为阳性,需要进行单人单管检测。为找到最有效率的方法,我们需要建立模型,从而得到采样管中混合几份样本进行检测是最优的。
问题二:问题二需要我们查阅资料,收集有关数据。然后利用问题一中给出的模型验证得到的数据,以此证明模型的可行性,并给出相应的方案。
问题三:疫情发生时,需要在一段时间内进行多轮核酸检测。因此需要我们建立相应模型,提供一份使得混检效率最高的方案。
1.5. 研究贡献
要使经济在疫情背景下持续发展,本文首先确定了混管人数以使得核酸效率达到最高。通过对混管检验和单管检验过程的分析,本文得出了检测时间与混管检验人数的关系,之后采用了SA模拟退火的算法对混管人数进行了迭代模拟,建立了最初的OMNA模型。通过观察模型,我们发现了最佳混管人数与感染率的近似负指数关系,并绘制了混管人数与感染率的关系曲线。
接下来,本文运用上述结论确定的混管人数给出相应方案。考虑使用上海近60日所有地区的日增长无症状患者及确诊患者人数,采用MK突变分析,确定了该时间序列平稳。接着,采用ARIMA时间序列模型对后3日的新增人数进行预测,并采用预测的4月30日的人数求出了对应的实时阳性感染率0.00031。然后将浦东新区2022年常住人口5,681,500带入第一问的OMNA模型中,并利用退火算法,初步得到当日的最佳混检人数为59人。考虑到混检人数过多对样本的稀释及误差作用,本文对模型进行了改进,得到4月30日该地最优核酸混检方案为19人,最优相对时间为8873。
假如需要多轮检测,本文还考虑了以上方案是否仍然适用。使用SI模型对近60日的疫情人数进行函数拟合,得到患者比例函数,进一步得到实时的阳性感染率。考虑到医务人员在连续高强度的工作中存在工作效率低下的情况,本文拟定了Ln函数来表示医务人员的身体状况。本文还兼顾了危急感染率和可防控感染率,在兼顾医务人员的身体状况和疫情防控的情况下,将OMNA模型改进得到ROMNA模型。之后我们重新利用ARIMA时间序列模型对后五天的新增患者人口进行预测,带入ROMNA模型,最终得到65日的实时最佳混检方案。
在得到了最佳核酸混检方案后,本文针对疫情防控要求给出了相应的政策,助力国家经济恢复。
1.6. 主要创新点
本文主要展示了核酸检测中混检问题的解决方法,采用了模拟退火的思想进行逐次模拟,达到预想的最优解。此方法短期预测效益高,稳定性好。同时,模型效益好,统筹全局,其思想和模型在工程应用中十分普遍。并且处于十分重要的地位,具有高适用范围以及科研价值和实际意义,可以解决现实生活中很多类似模拟求解最优的问题。例如:模拟水域污染及污染源的判定,模拟物料资源的调度分配等等。
在使用ROMNA模型时,可以带入时间尺度更久的数据,从而预测的结果将更加准确。此外还可以带入地域面积更小的数据,缩小地域范围,使获得的最优解实际意义更大。本文还进行了人性化的考量,不仅追求了核酸混检的效率,同时考虑到了样本检测数量过多可能导致医务人员的工作时间过长,进而使得效率下降。因此我们对每位工作人员的工作时间都有设限。同时,在运用时还可以增加自变量的维度,从而考虑多方面的因素,如天气,突发事件等一系列因素。
本文对于核酸混管检验问题可以进一步推广到其他传染病混管检测甚至化工成分分析的问题之中。可以进一步改进模型的感染率,每日接触人数等一系列系数实现。
2. 基本假设
1) 假设不考虑14日隔离完后的患者回到原住址,该模型只对短期的数据进行安排,并对过去的核酸检测方案提出最优解。
2) 在第一二问中,假设检验样本均有效,无假阳性情况发生。
3) 假设方案实施过程中,该地医务人员的数量保持不变。
4) 在第三问中,假设所有的医务人员的疲劳系数均为同一个函数。
3. 符号说明
4. 问题分析
4.1. 问题一的分析
问题一需要我们根据混合核酸检测问题构建数学模型。了解完混合核酸检测的测定方法后,我们需要按照实际情况拟定部分参数,并构建相应的总检测次数方程与总时间方程。经过比较各类算法的优劣势,本文最终决定运用模拟退火的算法,运用Matlab将方程的最优值解出。
4.2. 问题二的分析
问题二需要我们进行相关数据的收集,于是我们选择上海市作为样本采集地,采集了从3月1号到4月30号总共61天的数据,部分数据来源于上海市健康委员会。其中感染率可以通过上海整体趋势预测上海的实时阳性率,然后再用实时阳性率进行浦东新区的数据计算。接着我们选择运用时间序列模型预测最后一天的人数以验证其准确性,从而得到准确的感染率。得到感染率后,将其代入第一问构建的模型中,求出混检人数的最佳值。
4.3. 问题三的分析
问题三需要我们指定多轮核酸混检的方案,于是我们选择了SI模型来模拟近60天的阳性异常患者的数量,数据来源于问题二中的真实数据。其中再次考虑到高强度工作对医务人员工作效率以及身心健康的影响,根据引用文献,引入了疲劳系数这一指标,改进原模型,得到ROMNA模型,同时再采用ARIMA时间序列模型得到未来五天的数据,从而得到每日实时的准确感染率,将其带入ROMNA模型中,得到近65日的混检核酸管理方案以及最短相对时间。
5. 模型的建立与求解
5.1. 问题一模型的建立与求解
Step 1:建立数学方程
根据混合核酸检测的特点与要求,我们建立出相应的数学模型。该模型把若干采集样本平均分组进行检测。第一次检测完毕,再对出现阳性的样本分别进行检测。最后在已知阳性率的基础上算出平均每组样本检测次数最小的样本。
我们根据实际情况拟定出对应的参数:总人数m = 5,681,500,检测机构服务量a = 10与感染率alph = 0.001114515。
根据题目描述得到检测次数方程如下:
这里,我们假设单管与混管的检测时间相同,因此认为做单管检测与做混管检测的时间系数均为1。方程的前半部分为混管的检测次数,后半部分为单管的检测次数。
得到有关时间的方程如下:
其中m为总人数,x为混检人数,a为检测机构服务量,alph为感染率。方程的前半部分为混管的检测时间,后半部分为单管的检测时间。
Step 2:构建模拟退火模型
查阅相关资料后可知,模拟退火算法在数据的搜索上具有极大优势。主要采用物理学中的固体退火原理,是一种基于概率的算法。先设定一个最高温度,随着温度参数不断下降,该算法也同时在此空间内搜索退火的最优解 [3]。
基于模拟退火算法相对来说不容易陷入最优解,并且不管函数形式多复杂,此算法更有可能找到全局最优解的优点,本文决定采用此方法进行模型的构架。
该算法的流程图如下图1所示。
本文还考虑到最佳混检人数可能与感染率有关,于是进行了有关最佳混检人数与感染率的计算。通过Matlab绘制出的散点图如图2。
由图可知,当感染率越高时,最佳混检人数反而越低。这也为下文模型的优化提供了新的思路。
Step 3:问题求解
将拟定的参数代入构建的方程中后,运用模拟退火算法,使用Matlab求解得到散点图如下图3。
可以看出,在图上有两处红色的标记。左侧标记是最小时间对应的混检人数,右侧标记对应模拟退火随机生成的初始状态。因此,我们可以得出结论:在总人数m = 5,681,500,检测机构服务量a = 10与感染率alph = 0.001114515的情况下,当混检人数为30时,所花费的时间最少。因此,当30人一组进行混检是比较理想的。
5.2. 问题二模型的建立与求解
5.2.1. 数据收集及数据预处理
问题二需要我们收集相关数据以验证模型的合理性及准确性。于是我们通过查阅各种资料,得到了上海市本土新增无症状与本土新增确诊的人数,以及上海市的总人口数。本文决定使用2022年3月1日到2022年4月30日的上海市本土新增无症状与本土新增确诊的人数,再除以上海市总人口,得到实时感染率。
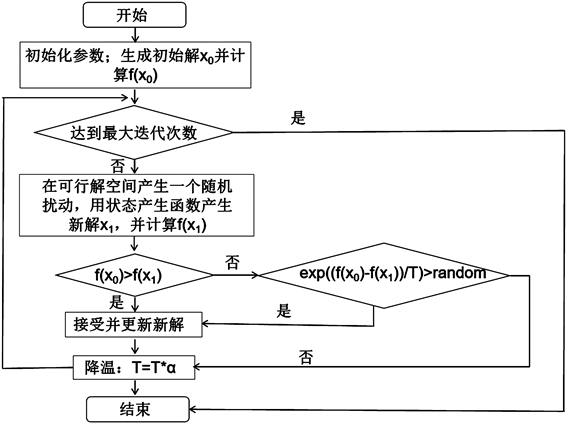
Figure 1. Flowchart of the simulated annealing algorithm
图1. 模拟退火算法流程图
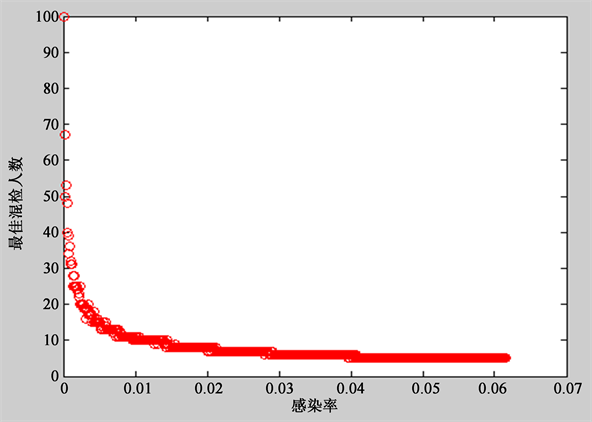
Figure 2. The relationship between infection rate and optimal number of mixed tests
图2. 感染率与最佳混检人数关系
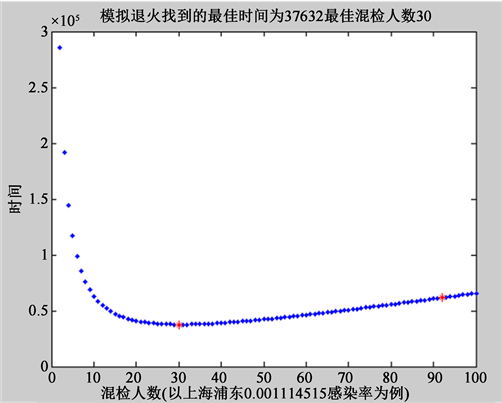
Figure 3. The relationship between the optimal number of mixed inspections and time
图3. 最佳混检人数与时间关系
因此,运用Matlab进行立方插值以软化数据后,我们得到了较为平滑的上海市61日疫情情况汇总曲线图,如图4与图5:
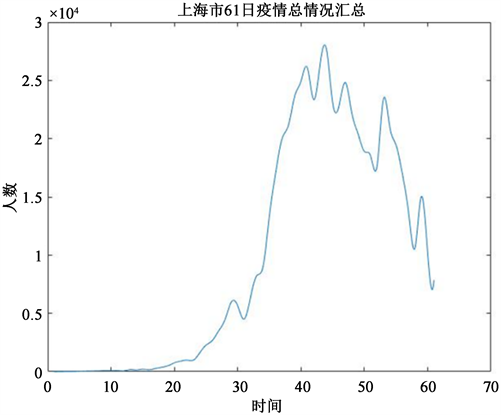
Figure 4. The 61-day epidemic situation in Shanghai
图4. 上海市61天疫情总情况
图4为上海市61天疫情总情况汇总,人数为无症状感染者与确诊者的总和。
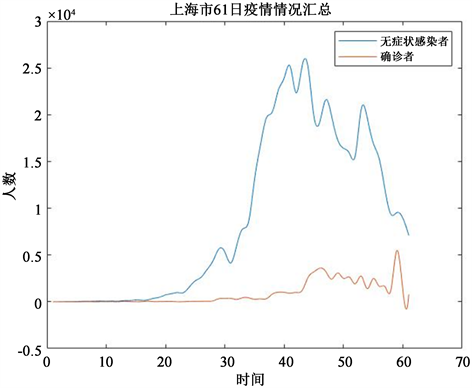
Figure 5. 61-day asymptomatic infections and confirmed cases in Shanghai
图5. 上海市61天无症状感染者与确诊者情况
图5为上海市61天无症状感染者与确诊者分别的感染人数的汇总。
5.2.2. 时间序列模型的构建
MK突变分析:
对于收集到的相关数据,我们对其进行了MK突变分析。
无症状患者的MK突变分析图结果如下图6:
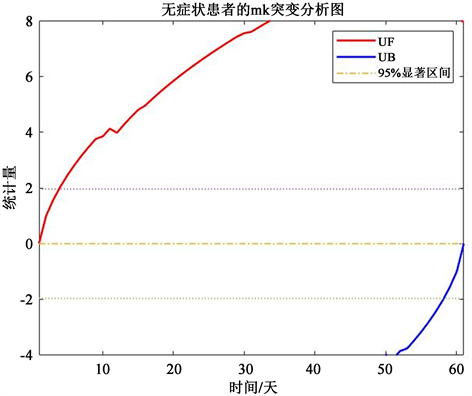
Figure 6. Analysis of MK mutation in asymptomatic patients
图6. 无症状患者MK突变分析
明显看出,UF和UB在置信区间内无明显交点,可知无症状患者的人数在这60天的时间内并未出现突增和突减,较为稳定。
确诊患者的MK突变分析图结果如下图7:
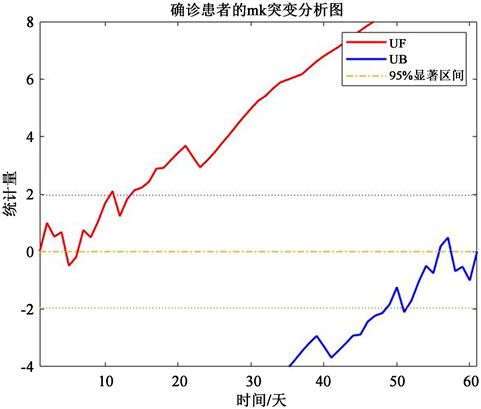
Figure 7. Analysis of MK mutation in confirmed patients
图7. 确诊患者MK突变分析
确诊患者的UF和UB在置信区间内也无明显交点。由此我们可以得出结论,在这60天的疫情中,感染人数未出现突变性跳转,疫情的态势处于可以预测和管控的范围内,因此我们可以通过时间序列ARIMA模型来对人数进行预测。
对上海市新增确诊人数的时间序列模型构建
运用SPSS进行上海市新增确诊人数的ADF检验,如下表1所示:

Table 1. ADF test of newly diagnosed people in Shanghai
表1. 上海市新增确诊人数ADF检验
注:***、**、*分别代表1%、5%、10%的显著性水平。
由上表可得,在差分为0阶时,显著性P值为0.925,水平上不呈现显著性,不拒绝原假设;在差分为1阶时,显著性P值为0.016**,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列;在差分为2阶时,显著性P值为0.000***,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
接下来,我们作出了上海市新增确诊的时间序列图如下图8:
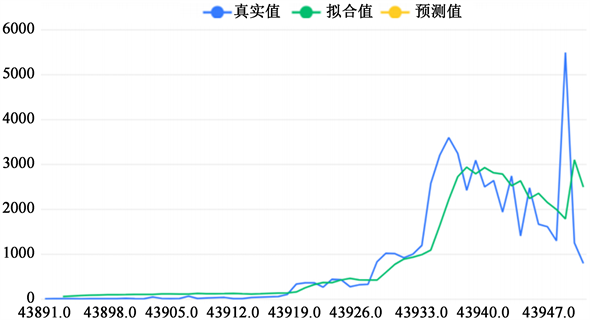
Figure 8. Time series of newly diagnosed cases in Shanghai
图8. 上海市新增确诊时间序列图
上图拟合了该时间序列模型的原始数据、模型拟合值、模型预测值。
接着,我们运用该时间序列模型进行了预测,得到的结果如下表2:
Table 2. Time series forecast of newly diagnosed cases in Shanghai
表2. 上海市新增确诊时间序列预测
运用SPSS进行上海市新增确诊人数的ADF检验,如下表3所示:
Table 3. ADF test of newly confirmed cases in Shanghai
表3. 上海市新增确诊人数ADF检验
注:***、**、*分别代表1%、5%、10%的显著性水平。
由上表可得,在差分为0阶时,显著性P值为0.495,水平上不呈现显著性,不拒绝原假设;在差分为1阶时,显著性P值为0.103,水平上不呈现显著性,不拒绝原假设;在差分为2阶时,显著性P值为0.000***,水平上呈现显著性,拒绝原假设,该序列为平稳的时间序列。
接下来,我们作出了上海市新增无症状感染者人数的时间序列图,如图9:
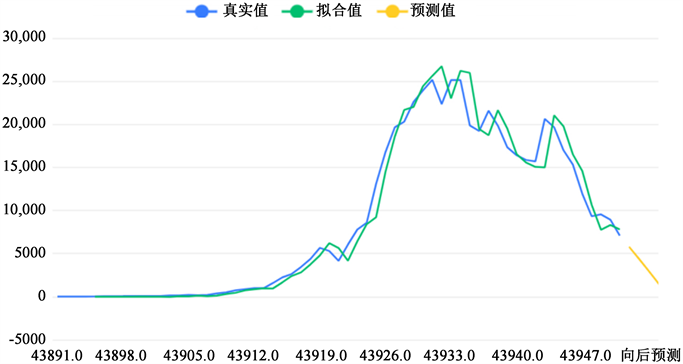
Figure 9. Time series chart of the number of new asymptomatic infections in Shanghai
图9. 上海市新增无症状感染者人数时间序列图
上图拟合了时间序列模型的原始数据、模型拟合值、模型预测值。
接着,我们运用该时间序列模型进行了预测,得到的结果如下表4所示:
Table 4. Forecast of new asymptomatic infections in Shanghai
表4. 上海市新增无症状感染者预测
于是,经过数据的处理与计算,本文估计出上海市这61天中每日新增患者与预测数量,如图10:
将处理过得到的预测值与实际值进行对比,发现差距不大,说明我们得到的感染率是较为准确的。
把感染率与上海市总人数以及上海市总机器数等数据代入第一问所求得的模型中,经过Matlab模拟退火计算,我们得到了下图11。
由图可知,当时间为2022年4月30日时,最佳混检人数为57,即为图中红色点所示位置。
本文还进一步考虑到:随着稀释因子不断减小,取样体积会不断增大,在这种情况下,高锰酸盐的指数和实际数值接近;当稀释因子为常规数值时,高锰酸钾指数和滴定体积呈线性关系。由此可以得知,取样体积的数值越大,滴定体积对高锰酸盐指数的影响就会越来越小 [4]。基于这一点考虑,我们在原有目标函数的基础上进行了优化,考虑和酸溶液稀释带来的准确性降低问题,避免某一参数下大批民众混检带来的感染隐患。
运用改进后的模型进行模拟退火计算得到的人数如图12。
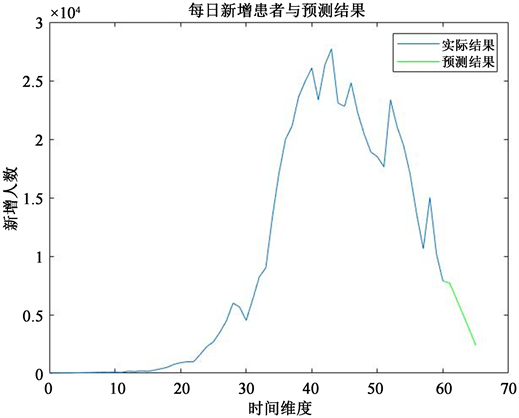
Figure 10. Daily new patients and forecast in Shanghai
图10. 上海市每日新增患者与预测
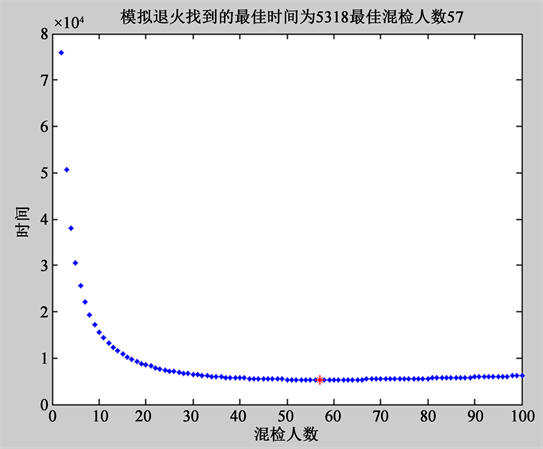
Figure 11. The optimal number of mixed inspections
图11. 最佳混检人数
由图12可知,当时间为8873时,最佳混检人数为19。
因此,最佳混检方案为19人一组进行混合核酸检测,所花费的时间为8873。

Figure 12. The optimal number of mixed checks after improvement
图12. 改进后最佳混检人数
5.3. 问题三模型的建立与求解
5.3.1. 优化模型的初步设想
首先,我们针对61日的疫情情况,重新进行了模型的建立。考虑到正处于疫情期间,大多数的患者仍处于各地的隔离阶段,因此我们简化了模型,忽略了治愈者的影响,从而采用SI模型。
本文假设在疾病传播期内所考察的总人数不变,将所有人群分为易感染者和已感染者两类,下面简称为健康人和病人。时刻t这两类人在人数中所占的比例分别记为s(t)和i(t)。每个病人每天有效接触的平均人数是常数
,当病人与健康者有效接触时,使健康者受感染变为病人。
5.3.2. 优化模型的方案设计
在实际情况中,对于多轮检测的混检方案,主要考虑两方面的方案设计:
1) 第i天做不做核酸检测;
2) 如果做检测,那么几人一组混检才能争取最短时间和较高的准确度。
针对第二点,本文采用问题二建立的改进模型。该模型可以兼顾最短时间和尽量小的混检人数。
针对第一点,我们需要考虑到以下因素:
首先,在感染率比较高的危急情况下,需要调动尽可能多的医疗资源,以最快最准地检测出感染者;
其次,为了让医务人员得到很好的休息,在防控区或低感染率的情况下,可以隔几天做核酸检测。在上述情况下,本文考虑制定疲劳系数 [5],给出一定的标准,以判断医务人员的连续劳动时间是否需要休息 [6];
此外,本文认为,就算再低的感染率,也不能放松警惕。因此规定至少每三天做一次核酸检测。
综合以上考虑,我们给出以下的核酸检测规定(图13)。
关于低感染率,经查阅资料可知,现在许多地方常见混检人数为10人,20人,30人以及50人一组。因此我们认为,当某天预计的最佳混检人数大于等于50人时,没有必要在这天进行核酸检测。并且可以知道,如果某天没有做核酸检测,那么第二天预计的感染率将会有所提高。
5.3.3. 优化模型的建立
我们根据收集到的上海市65日感染率数据,在前两问的模型上进行改动,考虑了检测天数的规划和最佳混检人数的规划。在模拟退火的基础上我们添加了进入退火计算的判断条件,用0~1变量flag来控制危急情况时的第一优先级,并把不需要做核酸检测那一日的最佳人数和最短时间赋值为−1。
具体方案计算如下所示:
先通过对目标函数变形,将待求的参数变形为易求的多项式函数的系数,通过最小二乘法的计算,得到时间影响因子为F(t):
从而进一步得到:
于是我们将其代入改进后的模型中,得到结果如下图14。
我们还考虑到,连续高强度工作的医务人员的工作效率和心理健康会随着连续工作时间的累积而下降。根据文献,我们将材料的疲劳的系数类比于人的疲劳系数,得到函数表达式如下:
其中,t为时间尺度。
运用Matlab绘制的工作时间与疲劳系数的关系图如下图15。
由于SI模型只能应对短期的预测,特别是对于疫情快结束时,误差率显著提高。因此我们重新采用了ARIMA模型进行预测,并将其带入我们优化后的模型。
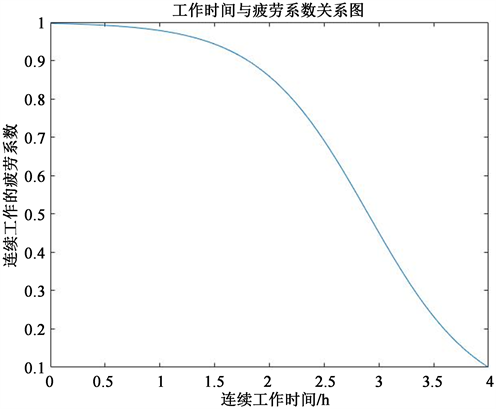
Figure 15. Relationship between working time and fatigue factor
图15. 工作时间与疲劳系数关系
5.3.4. 核酸混合检测方案
经过计算,得到核酸检测方案如下表5。
Table 5. Mixed nucleic acid detection protocol
表5. 混合核酸检测方案
6. 对我国经济金融影响政策建议
1) 短期:及时出台政策应对疫情负面冲击
建议国务院各部门、各级政府紧紧围绕“控疫情、稳就业、保民生”,及时出台相关政策,以确保经济社会稳定。
应对短期困难,可出台相应政策帮助企业渡过难关。货币政策,应保持稳健宽松,使资金流动性合理充裕,降低企业融资成本,鼓励商业银行为因疫情而面临暂时资金困难的企业积极提供信贷支持,帮助企业渡过难关,政策性金融机构要增加对医疗卫生材料和药品生产流通企业的低成本资金支持,协助它们扩大物资供应。
2) 中期:做好疫情有效控制后的经济恢复工作
建议中央政府、地方政府、民营企业、金融机构在应对疫情导致的负面冲击过程中,应致力于共同分担压力和损失。当经济水平随着疫情得到有效控制,可逐渐将工作重心放到社会生产和人民生活的恢复上来。
一是逐步放宽、解除疫情期间相关限制措施,恢复正常的公共服务,为企业生产、商业恢复和学校复课创造有利条件,对疫情期间积压的相关公共服务需求,应加大服务力度,提高办事效率,加快解决人民群众的相关困难。
二是通过财政政策积极支持地方经济恢复,可根据各省区市疫情严重情况,相应增加和调整中央财政转移支付比例;适当加大疫情严重地区的地方债发行额度;对受损严重的企业,特别是中小民营企业,通过税收减免、财政贴息贷款、降低社保缴费等措施给予财政上的支持。
3) 长期:加快医疗卫生体制机制改革和政府治理机制改革
应加快医疗卫生体制机制改革,实现“政府市场双到位、公立民营双发展、医生患者双满意”。一是增加医疗卫生的服务。逐步提高医疗卫生支出占GDP以及总财政支出的比重,确保医疗卫生支出稳定增长,完善基层医疗卫生基础设施建设,持续提升人均床位数、医疗设备数和医生数量;二是积极推进多元化的社会办医格局,降低准入门槛,突破体制机制障碍,鼓励民间资本兴办医疗机构,增加医疗卫生服务主体,全面提升医疗服务水平;三是优化医疗卫生服务效率;四是培养组建专业化人才队伍。
另一方面,应提高政府治理能力。一是强化信息公开透明,实施政府信息公开清单管理和政府信息定期披露机制。加强舆论监督,充分尊重新闻媒体和社会公众对重大公共事件的知情权;二是强化社会治理体系和地方政府治理能力建设。实现从管理到服务的转变,推动政府、社会和公众参与公共协商,畅通信息沟通渠道。
7. 模型的评价与推广
7.1. 模型的评价
7.1.1. 模型的优点
1) 短期预测效益高,稳定性好。
2) 人性化,不仅仅追求效率,同时考虑到了医务人员的身心健康。
3) 模型效益好,统筹全局,考虑到了样本数量过多会对核酸检测的准确性造成影响,实际效益高。
4) 对疫情最严重的时期进行了有效的方法安排,对上海市乃至其他城市的疫情管理有显著的意义。
7.1.2. 模型的缺点
1) 该模型无法进行长期的预测和安排,只能根据已有的数据进行短期的安排和预测。
2) 由于数据收集的匮乏性,选取的数据地域范围过大,一刀切的管理方案,导致缺少了一定的实际意义。
3) 未严格地考虑到长期的疫情防控中存在患者重新成为健康者的情况。
7.2. 模型的推广与改进
本文章主要展示了核酸检测中混检模型的解决方法,主要采用了模拟退火的思想进行逐次模拟,达到预想的最优解。这中思想和模型在工程应用中十分普遍,并且处于十分重要的地位,具有高适用范围以及科研价值和实际意义,可以解决现实生活中很多类似模拟求解最优的问题。例如:模拟水域污染及污染源的判定,模拟物料资源的调度分配等等。
在使用ROMNA模型时,可以带入时间尺度更久的数据,从而预测的结果将更加准确,此外还可以带入地域面积更小的数据,缩小地域范围,使获得的最优解实际意义更大。同时,可以增加自变量的维度,从而考虑多方面的因素,如:天气,突发事件等一系列因素。
本文对于核酸混管检验问题可以进一步推广到其他传染病混管检测甚至化工成分分析的问题之中。可以进一步改进模型的感染率,每日接触人数等一系列系数实现。