1. 引言
针对高分辨率无人机遥感影像中的交通车辆进行目标检测,可用于分析交通拥堵、道路交通违法行为,收集交通变化规律,加入交通管制,促进交通管理更加合理,对缓解交通拥堵具有重要作用 [1]。基于深度学习的车辆检测算法通过卷积神经网络自动提取从原始图像浅层位置信息到高层语义信息的多层次车辆特征,利用基于神经网络的深度学习算法检测图像中的目标车辆已成为车辆检测领域的研究趋势 [2] [3]。由于无人机航拍影像的视角特殊性,针对无人机遥感影像中的车辆检测目前主要面临的问题有:复杂背景 [4]、目标的尺度变化 [5]、特殊视角 [6] [7] [8] 等问题。
目前基于深度学习的图像目标检测算法模型主要使用Faster R-CNN [9],Mask R-CNN [10],Retina Net [11],Dynamic R-CNN [12],PAA [13] and ATSS [14],YOLO系列 [15] [16] [17] [18] 等算法框架。邢宇驰等 [19] 基于YOLOv5的遥感图像目标检测在公开的10类地理空间物体数据集进行了检测实验,以评估所提出模型的目标检测性能。李珂泉等 [20] 按照是否存在显式的区域建议和是否定义先验锚框两种分类标准对已有的目标检测算法分类,对代表性的目标检测算法在公开数据集中的表现进行了比较和分析。马跃等 [21] 在分段反卷积改进SSD的目标检测算法中提出了分段反卷积结构降低了噪声信息加入,又采用了新的融合结构对高层特征图和低层特征图进行融合,丰富了检测特征层的信息,加入了不同长宽比例的候选框和多尺度特征图对小占比目标增强检测,减小了小占比目标的误检和漏检。杨锦帆等 [22] 对比了各类常用单阶段车辆检测算法,列举其改进措施以及在车辆检测方面存在的问题,介绍了车辆检测相关数据集,对现阶段车辆检测中亟待解决的问题与难点进行了分析,提出了车辆检测未来的研究方向。冯加明等 [23] 提出通过删减部分残差以降低卷积层通道数并通过K-均值聚类与手动调节相结合的方式提高检测的精度。汪昱东等 [24] 通过在检测网络中加入物浓度判断模块来提高网络的适应性和鲁棒性。YOLOv5算法在YOLOv4的基础上提出,其速度与精度都得到了极大的性能提升,被广泛应用于遥感影像目标检测。本文针对YOLOv5算法中损失函数仅使用长宽比并不能反映边界框宽高分别与其置信度的真实差异的缺点,对损失函数进行了改进,消除了损失函数因为不能反映宽高真实差异引起的收敛过慢问题,提高了算法的检测精度。
2. 基本概念
2.1. YOLO系列算法
YOLO算法首先通过卷积神经网络将目标图像划分为S × S个方格的特征图像,计算机可以预测到方格中所落入的目标的边界框、置信度和所属类别的概率图,如果目标对象的中心落在正方形中,则会在正方形周围预测N个边界框,并计算每个边界框所包围的目标的置信度。最后通过非极大值抑制算法(NMS)消除单个目标冗余的边界框并得到检测结果。YOLOv2是在YOLOv1的一些基础上做了优化,并提供了一个全新的联合训练算法。YOLOv2算法将骨干网络由224 × 224换为448 × 448的Darknet19,采用了全卷积网络结构Conv + BatchNorm,并且在YOLOv1的基础网络上去掉了一个全卷积层,利用随机梯度的下降从而能够在COCO数据集上获得良好的检测结果。YOLOv3算法使用了骨干网络Darknet53、采用了多尺度预测、跨尺度特征融合等。YOLOv4算法使用了Mish激活函数,引入了CIOU,进一步提升了检测效果。YOLOv5算法几乎与YOLOv4算法同时提出,在性能上略弱于YOLOv4,但在灵活性和速度上比YOLOv4更好。YOLOv5在Backbone部分没太大变化。在Neck部分的变化相对较大,首先是将SPP换成成了SPPF,在PAN结构中加入了CSP,加强了网络特征融合的能力,在损失函数上YOLOv5采用了CIOU。
2.2. IOU介绍
IOU [25] 的提出是为了衡量预测框与真实框的关系。IOU即计算预测框与真实框的交并比,IOU损失函数将四个点构成的边界框,作为整体进行回归。设置(xt, xb, xl, xr)进行计算,反应真实框和预测框的关系。IOU = 1 − IOU。IOU具有尺度不变性,但存在的缺点是当IOU等于0时,即预测框与真实框没有交集时,无法进行梯度回传,从而无法判断预测框与真实框的距离。另外IOU损失无法判断两个框的相交方式。GIOU [26] 针对该问题做出了相应的改进,GIOU对于任意的两个A、B框,首先确定一个能够包含它们的最小方框C,计算
,然后计算该值与C面积的比值,再用A、B的IOU减去该比值得到GIOU,GIOU损失函数如公式(1)所示,
(1)
虽然GIOU克服了IOU因为预测框和目标框没有交集时,梯度无法回传的问题,但当A包含B时,
将为零,反之亦然,在这种情况下,GIOU损失减小为借据损失。因此,GIOU损失的收敛率仍然很慢。针对该缺点,Zheng Z等 [27] 提出了DIOU,DIOU的损失函数如公式(2)所示,
(2)
其中,
,
分别代表了预测框与真实框的中心点,
代表两个中心点之间的欧式距离,C代表能够同时包含预测框和真实框的最小闭包区域的对角线距离。DIOU损失函数惩罚项可以直接最小化预测框和真实框中心点间的距离,因此比GIOU损失函数收敛快。CIOU在DIOU基础上加了一个考虑预测框纵横比拟合真实框的纵横比的影响因子,进一步提升了算法的收敛速度,CIOU的损失函数如公式(2)所示。
(3)
其中,
表示真实框与预测框中心的欧式距离,c表示真实框与预测框最小闭包区域对角线距离,
,
。
3. YOLOv5算法的改进
CIOU损失虽然考虑了边界框回归的重叠面积、中心点距离、纵横比。但是通过其公式中的v反映的是纵横比的差异,而不是宽高分别与其置信度的真实差异,所以会阻碍模型有效的优化相似性。针对这一问题,Zhang Y F等 [28] 在CIOU的基础上将纵横比拆开,提出了EIOU损失函数,定义如公式(4)所示:
(4)
该损失函数包含三个部分:重叠损失,中心距离损失,宽高损失,前两部分延续CIOU中的方法,但是宽高损失直接使目标框与锚框的宽度和高度之差最小,使得收敛速度更快。其中IOU表示预测框和真实框相交区域面积和合并区域面积的比值,
和
是包含预测框和真实框的最小闭包区域的宽度和高度,b与bgt分别表示预测框和真实框中心点的位置,
表示预测框与真实框中心的欧式距离,w与wgt表示预测框与真实框的宽度,
表示预测框与真实框宽度的欧式距离,h与hgt表示预测框与真实框的高度,
表示预测框与真实框高度的欧式距离,将纵横比的损失项拆分成预测的宽高分别与最小外接框宽高的差值,加速了收敛提高了回归精度。本文对YOLOv5算法中的损失函数进行了改进,利用EIOU损失函数,替换原始YOLOv5算法中的CIOU损失函数,改进后的算法记为YOLOv5-EIOU,改进前记为YOLOv5-CIOU,并在无人机遥感影像数据集上进行了车辆检测实验验证。
4. 实验结果与分析
4.1. 实验环境配置
本文实验计算机配置32 GB的内存,NVIDIA GeForce GTX 2080Ti显卡,CPU主频3.6 GHz。cuda版本为10.2,使用开发环境软件为Pycharm,语言为Python3.8,深度学习框架为Facebook开源的pytorch。
4.2. 数据集准备与训练
本文实验使用数据集为UAV-ROD,是国科大提供的面向无人机的汽车数据集,UAV-ROD由1577张图像和30,090个汽车类别实例组成,训练集和测试集中的图像数分别设为1150和427,实验使用其coco格式标注成果。实验对YOLOv5算法中的s、m、l三种模型分别进行了损失函数改进前后的实验验证,训练过程中s、m模型,设置epoch为150,batch大小设为10,l模型的batch大小设为4。
4.3. 训练结果验证
模型训练完成后得出精确度(Precision)和召回率(Recall)两个数值指标,为综合评估目标检测的性能,通过平均精度均值(Mean Average Precision, mAP)来进行评价模型的优劣。以召回率Recall为横坐标轴,精确度Precision为纵坐标轴可以得到PR曲线,其中曲线下的面积是平均精确度AP值,目标检测模型中每种目标均可计算出一个AP值,对AP值求平均则可以得到模型的mAP值。mAP是介于0到1之间的一个数值,该数值越接近于1,就表示模型的性能更好。本文实验分别训练了YOLOv5-CIOU算法的s、m、l模型和YOLOv5-EIOU算法的s、m、l模型来检测目标,通过对模型的验证可以分别得到3类模型的PR曲线,计算将IOU设为0.5时,无人机遥感影像中汽车目标的AP值,由于本数据集只有一类目标,所以AP值即为mAP值,mAP值越接近1表示所训练的模型的性能越好。实验同时给出了不同IOU阈值(从0.5到0.95,步长0.05)上的平均mAP。结果如表1所示。
由表1可以看出经过将YOLOv5算法损失函数由CIOU改进为EIOU后mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5值都有不同程度的提升,其中YOLOv5s的mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5值由0.971提升到0.973提升了0.2%,YOLOv5m的mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5值由0.968提升到0.969提升了0.1%,YOLOv5l的mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5" target="_self">mAP@0.5值由0.972提升到0.973提升了0.3%,为3类模型中mAP值提升最多的算法。mAP@.5:.95值在算法改进后同样有不同程度的提高,其中YOLOv5m模型在改进后提升了1.5%,为三个模型中提升最多的模型。图1给出了各模型PR曲线的对比结果。由PR曲线下方面积对比也可看出改进后的算法AP值较原算法均有提升。

Table 1. Experience result comparison
表1. 实验结果对比
 (A) s
(A) s 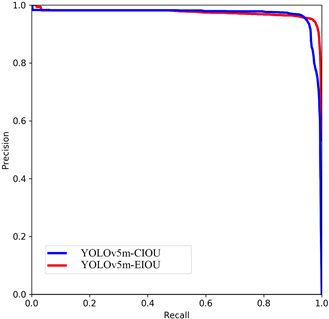 模型 (B) m模型
模型 (B) m模型 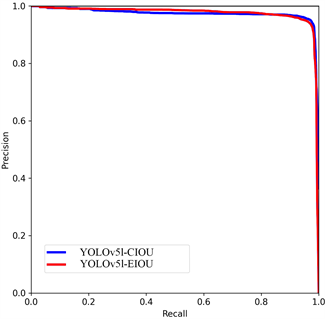 (C) l模型
(C) l模型
Figure 1. P-R Curve comparison of YOLOv5s, m, l-CIOU and YOLOv5s, m, l-EIOU model
图1. YOLOv5s、m、l-CIOU与YOLOv5s、m、l-EIOU三种模型P-R曲线对比
图2给出了三种模型部分检测结果对比,由对比结果可以看出YOLOv5算法各模型针对无人机遥感影像中的汽车车辆检测问题,均有很高的检测准确率。仅在图2(C)中针对第7张影像的检测,YOLOv5l-CIOU模型存在一个错检车辆,而YOLOv5l-EIOU模型没有错检该车辆。比较原始模型与损失函数优化后的YOLOv5模型之间的均值平均精度,发现优化后的YOLOv5算法表现出了较高的性能,究其根本,在于EIOU损失函数能够更好地反映目标框与锚框宽度和高度之差,加速了收敛提高了回归精度。
5. 结论
针对无人机遥感影像中车辆目标的识别问题,本文对原始YOLOv5算法中的损失函数进行了改进,并分别训练了YOLOv5算法三种模型YOLOv5s、YOLOv5m、YOLOv5l,对改进前后的算法利用无人机遥感影像数据集进行了训练和验证,验证了改进后的算法在车辆检测中的优越性。
基金项目
河南省科技攻关(212102310419),智慧中原地理信息技术河南省协同创新中心、时空信息感知与融合技术自然资源部重点实验室联合基金(212109),许昌学院科研反哺教学项目(2022FB004)。