1. 引言
随着网络上的社交媒体逐渐流行,人们很愿意在例如微博、推特等社交网络上发表自己对某个产品、事件等主体的情感,对这些有着情感倾向的数据进行分析,可以了解用户的想法和意见 [1]。因此,文本情感分析一直以来都是自然语言处理的研究热点。
早期的大多数情感分析方法都是在手动提取的有效特征上训练浅层模型,这些模型通常采用传统机器学习的情感分析方法,包括支持向量机(SVM) [2]、主题模型(LDA) [3]、朴素贝叶斯 [4] 等等运用统计学的知识对文本的情感进行分析。这类方法存在不能充分利用上下文文本的语境信息的问题。近年来,深度学习方法被应用到情感分析任务中,其中,递归神经网络(RNN)和卷积神经网络(CNN)较为流行。基础的RNN不擅长处理较长的数据,此时数据会存在梯度消失和梯度爆炸 [5]。长短期记忆网络LSTM和门控循环神经网络GRU的提出解决了这一问题,可以对长期依赖关系进行建模。Kim [6] 提出通过一维卷积来获取句子中n-gram的特征表示,其对文本局部特征的抽取能力很强,在情感分析任务有着不错的表现。随着注意力机制在图像领域的兴起,Google团队 [7] 实现了一种带有注意力机制的递归神经网络,可以帮助模型关注更重要的情感内容。注意力机制可以通过分配权重来突出上下文重要的信息,并有效地结合RNN和CNN。Yang等 [8] 利用GRU对单词和句子编码,结合分层的注意力,来捕捉重要的单词和句子。基于CNN和RNN的优点,人们也在探索这两个神经网络的结合。Behera等 [9] 将单层CNN的输出输入到LSTM中,发现组合的性能要优于单独的CNN或RNN模型。Pasupa等 [10] 以不同的方式融合了卷积神经网络和长短期记忆网络,发现最好的混合式深度学习是BLSTM-CNN。Basiri等 [11] 应用两个独立的双向LSTM和GRU层,同时考虑两个方向的上下文来预测情感极性。然而,传统的基于LSTM的模型具有一定的局限性,且没有考虑文档的结构层次,尤其是在对长文本数据进行情感分析的时候,过长的序列会存在丢失信息的问题。此外,它们没有充分利用所有的语料。具体地说,它们只利用了局部的上下文信息,没有利用整个文档的统计信息,这样得到的情感信息不够准确,影响模型得分。
为了解决上述问题,受到生成摘要中的LDA分布结合神经网络 [12] 的启发,本文提出了一种以分层注意网络为基础的新模型THAHNN (Topic-Aware Hierarchical Attentional Hybrid Neural Networks)。THAHNN主要思想是将预训练生成的LDA分布分配给文档词级和句子级的编码层,将数据集中全局共现的信息和编码层的局部内容窗口的语义特征相结合,使得模型既包含了局部的上下文信息,又融入了整个文档的统计信息,充分利用了所有的语料。与此同时,使用带有主题感知的分层注意网络对模型进行训练,有效地将文档结构的知识融入到体系结构中,来关注文本中更重要的单词和句子。此外,引入卷积神经网络来降低特征空间的维度,解决模型参数数量过多的问题。为了验证框架的有效性,在两个数据集上进行了实验,分别是超党派新闻情感检测任务和亚马逊商品评论数据集。并将其情感分类的结果与几个流行的神经网络模型进行了比较,结果表明,该模型具有更高的精度。
2. 模型
结合主题的分层注意混合网络的总体结构如图1所示,为了解决传统神经网络无法融入文本统计信息的问题,本文将主题模型LDA生成的主题词分布和文档主题分布分别作为单词编码层的附加特征和句子编码层的附加特征,使得模型充分利用了所有的语料。单词编码层的附加特征和词嵌入技术glove相连接作为模型的输入,同时,联合CNN层来学习重要的主题信息,减少参数数量,提取更丰富的特征。最后,使用分层注意网络对单词和句子依次进行编码,有效地结合了文档的层次结构,将得到的文档表示与文档主题分布作为附加特征连接起来,以做出最终预测。
2.1. 神经主题模型
传统的LDA主题模型采用词袋的方法,将每一篇文档视为一个词频向量,通过分析文档数据,抽取出它们的主题分布,之后根据主题分布进行文本分类。但是词袋方法没有考虑词与词之间的顺序,导致模型不能利用文本上下文语义。本文提出一种将主题与神经网络语言模型联合训练的机制,既保证了句子的序列语义,又加入了语义主题信息,充分利用了文档的所有语料。
对于主题信息,采用LDA模型计算出与文档相关性最高的主题词,之后预训练得到主题–词分布矩阵
和文档–主题分布矩阵
,
是维度为T的向量,T是训练文本语料库的主题数,整个语料库由m个文档组成,
是一个m*T的矩阵,对应于每个文档的主题概率分布。
得到主题矩阵后,为了将tw和dt矩阵融入模型,在词嵌入阶段,把主题–词分布矩阵作为embedding层的权重得到主题嵌入向量
,同时,句子中的每个单词
匹配glove预训练的词向量
,最终代表每个句子的词嵌入
表示为:
(1)
其中,
代表Concatenate操作,由此,每个输入语句
被表示为n*k的矩阵。同理,将
与神经网络生成的文档嵌入进行Concatenate操作,之后输入到分类层,得到预测结果。神经主题模型将文档统计信息与神经网络联合起来,充分利用了文档的所有语料。
2.2. 卷积主题网络
由于引入LDA分布后模型的参数数量过多,为了更加准确地描述数据特征,本文采用卷积神经网络来降低特征的维度,同时,可以通过迭代卷积和池化操作学习关键的主题信息。
本文的卷积运算是在一维卷积中进行,将e个h字窗口的卷积滤波器
重复应用于带有主题信息的词嵌入矩阵中产生新的特征。比如,在单词窗口
我们可以得到新特征
:
(2)
其中,f代表RELU激活函数,模型使用激活函数用于输入矩阵,b是偏置项。对于长度为n的句子每个过滤器取到的可能窗口为
,由此产生的特征映射为M:
(3)
卷积层可以帮助模型提取文本的重要特征,明确主题信息。卷积层完成相应的操作后紧接着是池化层,池化的目的是对数据进行降维。本文采用最大池化,对卷积层产生的带有主题信息的特征地图应用最大值池化,来获得池中的最大元素
:
(4)
模型在卷积层应用不同大小的多层,来生成多个特征映射,最后池化层生成的元素表示为M:
(5)
其中,m表示特征映射的数量。模型在引入卷积神经网络后,不仅减少了参数数量,也学习到了重要的主题信息。
2.3. 分层注意网络
注意力机制可以通过分配权重来突出上下文重要的信息,新模型THAHNN采用分层的注意力网络来更好地利用文档的结构层次特征,可以关注到对情感分析更有帮助的单词和句子,同时,联合文档–主题分布,来加强主题词的权重,使得输出的情感既与序列语义有关,又不偏离文本的主题。
本文根据文档的结构层次分为两个不同的部分,第一部分是词序编码器和词级注意力层,第二部分是句序编码器和句级注意力层。在单词编码器中,使用BiGRU来对单词进行编码,利用了前向和后向的上下文信息。对于给定的句子
,得到加上主题信息的词嵌入
,通过双向的GRU层得到前向的
和后向的
:
(6)
(7)
前向的隐藏状态
读句子的顺序是从
读到
,而后向的
读句子的顺序是从
读到
,将前向隐藏状态
和后向隐藏状态
拼接起来得到
,它包含了整个句子的信息。每个词对句子的重要性是不同的,模型使用注意力机制来量化单词对句子的重要性,具体地说,
(8)
(9)
(10)
模型通过全连接层得到
的隐藏表示
,计算
与词级上下文向量
的相似度来评估单词的重要程度。再通过Softmax层得到归一化的关注度权重
,之后通过加权得到句子表示
。单词上下文向量
在训练过程中被随机初始化并联合学习。
类似地,模型使用BiGRU来对句子进行编码,对于给定的句子向量
和文档表示D,得到的句子表示为:
(11)
(12)
将前向隐藏状态
和后向隐藏状态
拼接起来得到
,
概括了整个文档的上下文句子。然后使用注意力机制关注文档中重要的句子:
(13)
(14)
(15)
在上面的等式中,d是通过注意力加权得到的文档表示向量。为了将主题信息融入神经网络,模型THAHNN将预训练的LDA主题模型得到的文档–主题分布dt与d相连接,输入到sigmoid层得到预测结果。
模型THAHNN的损失函数采用binary_crossentropy,其中
是真实标签,
是输出
标签的概率。
(16)
3. 实验
3.1. 数据集
模型在两个公开的数据集进行实验,使用80%的数据进行训练,10%的数据用于评估模型,10%的数据用于测试。两个数据集的描述如下:
SemEval-2019 Task 4 [13]:这是一个检测新闻政治偏见的数据集,任务是确定新闻文章的情感倾向是否含有超党派偏见。它包括两个部分,出版社自动分类的语料库和手动标注的文章语料库。手动标注的语料库相对更可靠,本文只使用了文章语料库的数据。它包含645篇训练集,测试集的数据不对外开放,所以从中选择一些数据作为评估集和测试集。
Amazon Review [14]:该数据集出自亚马逊商品的好评和差评,它包含了2065个商品评论。
表1描述了上述数据的详细信息,图2展示了SemEval-2019 Task 4数据集的文档长度分布。

Table 1. Statistics for the dataset
表1. 数据集的统计信息
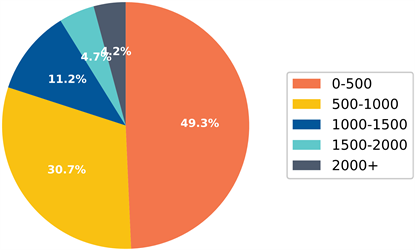
Figure 2. SemEval-2019 Task 4 dataset document length distribution
图2. SemEval-2019 Task 4数据集文档长度分布
3.2. 参数设置
由于数据集的文档大小差异较大,为了尽可能地多表达出句子描述的内容,每句话最多选100个单词,每篇文档最多30个句子。在单词嵌入层中,所有模型都使用公开的预先训练的Glove词向量作为权重,词向量的维度是300维。LDA主题模型的主题数量采用一致性模型来确定,在SemEval-2019 Task 4和Amazon Review评论数据集中,得到最佳的主题数分别为425和625。本文使用Gensim LDA模型生成主题词分布和文档主题分布。对于CNN层,使用了32个滤波器并且窗口大小分别为4,5,6。对词和句子编码的BiGRU的存储维度设置为50,分类器使用sigmoid激活函数。在训练过程中,所有数据集的batch_size设置为64,Dropout为0.2,训练8个epoch,采用学习率为0.001的adam优化器进行反向传播训练,损失函数为binary_crossentropy,每次在评估集中验证模型的性能,并保存效果最好的模型。
3.3. 基线方法
本研究以以下五种深度神经网络模型为基准进行情感极性分类,取得了良好的效果。五种深度神经网络模型如下所示:
CNN [6]:使用一维卷积来提取文本重要特征。
LSTM [15]:长短期记忆网络,可以学习到文本序列的长期依赖信息。
HAN [8]:利用文档的结构特征,分别对词和句子进行编码来施加注意力机制,可以关注到文档中对分类起着重要作用的单词和句子s。
Transformer [16]:是一个sequencetosequence的模型,使用自我注意力机制,同时采用位置嵌入来表示输入序列的顺序,使用多头自我注意力机制来理解词在上下文的含义,在很多NLP任务中有着不错的表现。
AC-BiLSTM [17]:使用卷积层从词向量中提取更高级别的短语表示,基于注意力的双向LSTM模型来同时考虑前向和后向的输入,从而能发现句子中重要的语义层面的信息。
4. 结果讨论
实验采用精确度(Pr)、召回率(Re)、F1度量(F1)和准确度(ACC)等四个指标来评估模型,这四个指标被广泛用于情感分析任务中,它们的计算方法如下:
(18)
(19)
(20)
(21)
其中,TP、FP、TN和FN分别代表真正类、假正类、真负类和假负类。文中将THAHNN与上述5种情感分析基线模型进行了比较。
Table 2. Comparison of results under the SemEval 2019 Task 4 dataset
表2. SemEval 2019 Task 4数据集下的结果比较
Table 3. Comparison of results under the Amazon Review dataset
表3. Amazon Review数据集下的结果比较
首先,在SemEval 2019 Task 4数据集下的实验结果如表2所示,新模型THAHNN的准确率提高了1.71%,对于F1衡量标准,正类的改进为4.98%,负类的改进为0.9%,正负类差距较大的原因主要是此数据集不平衡,正类的数据更多。可以注意到,LSTM和Transformer模型的效果相对较差,由于该数据集的文本长度较大,LSTM关注不到更重要的句子,而Transformer缺少对序列建模所以表现的不好。基线模型中,AC-BiLSTM的效果最好,它同时考虑到了上述两个模型的缺陷。本文提出的THAHNN在准确率和F1衡量标准方面都要优于其他5个模型,这些改进主要得益于主题模型结合分层结构丰富了特征空间,同时加入了CNN来提取最重要的特征。
在Amazon Review数据集下的实验结果如表3所示,新模型THAHNN的准确率提高了1.16%,对于F1衡量标准,正类的改进为1.62%,负类的改进为0.94%,从结果可以看出,THAHNN在准确率和F1衡量标准方面同样都要优于其他5个模型,但是,改进的数量相较于SemEval 2019 Task 4数据集要少。主要还是因为评论数据集的文本长度相对要小,对于短文本来说,THAHNN不会有显著的改进,因为模型采用了分层的双向GRU层进行编码,这个设计可以捕获长期的依赖。
5. 结论
本文提出了一种结合主题模型和深度神经网络的文档情感分析模型THAHNN,该方法将LDA分布和混合神经网络的分层模型结合起来,以预测文本的情感。通过在词嵌入层和文本表达层都融入主题信息,使得模型既考虑了文档的结构层次,又充分利用了语料库的信息。除此之外,使用卷积神经网络帮助模型学习关键的主题信息,提取到更重要的局部特征。在文档长度差异较大的两个数据集中,相较于对比模型,本文的模型都取得了很好的结果。
基金项目
天津市自然科学基金(19JCYBJC18700)。