1. 引言
近些年来,在线社交网络(Online Social Networks, OSNs)成为人们日常交际、信息传播的重要平台,数以亿计的用户以及他们的朋友每天拥有海量的数据信息传播量。研究社交网络特性,分析社交网络应用,成为当前热门话题。一些研究者对OSN建模与度量,研究网络拓扑之间的结构,分析社交网络的影响力 [1],预测社交网络的发展趋势 [2]。部分学者通过挖掘OSN传播性质与结构性质,研究其传播领域、用户行为与隐私等方面 [3]。Viswanath等人 [4] 通过区分弱连接与强连接对Facebook数据集的活动网络进行了时序上的研究,发现大部分社交联系强度都会随着时间逐渐变弱,然而社交网络图结构基本上不会变化。研究社交网络的结构属性、传播特性、演变规律以及用户之间的交互属性 [5],可以应用到现实生活诸多领域,如疫情风险监控、股市预测、推荐适合广告等各种场景 [6] [7]。
截至2021年6月30日,Facebook月度活跃用户(MAU)达到29.0亿人,Twitter也有着数以亿计的用户量。然而面对如此庞大的OSN,如果直接对其进行整体研究,将是一个不可估算的工程量。并且,为了保护用户个人信息,很多OSN公司都对部分数据进行了限制访问与隐私保护。因此,在有限的计算环境约束之下,如何才能获取一个代表性的子图样本,用以估算原图,成为目前正在研究的热门话题。
2. OSN采样
通常把OSN建模为社交图,用G = (V, E)表示,其中,顶点集合V表示OSN中的用户,边集合E表示用户之间的关系或连接,这种关系根据图的类型分为有向与无向。对于无向图,顶点v的邻接节点数量称为节点v的度,其中,v∈V。对于有向图,定义节点v出发指向其邻接节点的数量称之为v的出度,从其他邻接节点出发指向v的节点数量称为v的入度。
为了获取一个具有代表性的样本,学者们先后研究出各种算法进行测评。一开始最常使用广度优先搜索算法(Breath First Search, BFS),Ahn等人 [8] 通过采样获得网络图拓扑结果,分析了OSN中用户的交流状况与发展趋势。Ferrara等人 [9] 对Facebook数据集进行采样,分析研究了社区网络的统计特征与个人的组织模式。同时,Chau等人 [10] 研究并行爬行采样机制,可以大幅度提高网络效率,然而效率提高并不能改变采样结果的评测。经研究 [11] 比较BFS采集到的子图度数偏高,在采样比率不足时,度分布存在较大的误差 [12]。部分学者使用用户均匀采样方法(Uniform Sampling of User IDs, UNI),以获得对于网络的无偏估计,然而网络用户id的长度复杂性导致采样方法的命中率相当之低,且频繁的拒绝–接受采样又会导致带宽消耗较大,文献 [13] [14] 提出通过改进UNI自适应方法,提高采样命中率,需要研究网络id的大致分布有足够的研究。随机游走算法(Random Walk, RW)广泛运用于OSN采样,在计算机科学、数学物理和金融领域等多方面进行展示
与应用 [15],然而RW采样获取到的子图也是偏于高度节点 [16],部分学者通过改进随机游走或者重新估算样本的方法对网络进行采样。Salehi等人 [17] 提出一种新的链接跟踪采样方法,将网络进行社区划分,然后分别在每个社区进随机游走,用以研究网络特性,需要事先了解网络结构使用聚类划分的策略 [18]。文献 [19] 采用将静态网络拓展为时态网络的方法,基于个性化PageRank,使用随机游走采样理论分析。Gjoka等人 [11] [16] 通过研究对比普通的游走算法、重新加权随机游走算法(Re-Weighted Random Walk, RWRW)、以及蒙特卡罗随机游走(Metropolis-Hastings Random Walk, MHRW)对社交网络图进行了采样与检测,研究表明,这两种方法均可获得一个不错的样本用以估算原图结构,然而RW容易陷入局部重复采样,MHRW有较高的自环率,RWRW本身可用的估算因子有限。Dong等人 [20] 使用USRS采样算法,通过跳转之前将一部分节点的自环率分配给邻接节点中自环率大于0的节点,从而提高采样效率,USRS不仅需要访问当前节点的邻接节点,还需要访问其邻接节点的邻接节点,计算出自环率的分配值,该过程较为复杂且易受到OSN访问权限的影响。Jin等人 [21] 使用AS采样算法,在MHRW算法基础上加入了随机跳转策略,提高了采样效率,同时避免陷入局部子图死循环无法出来的情况。文献 [22] 用UD算法通过添加缓存区进行同度数节点替换的方法,实现采样率提高,然而在一些OSN图采样时,所得到的子图平均度数与聚类系数是均是明显偏低的。Rezvanian等人 [23] 研究最短路径,随机选取网络的两个节点,将最短路径所涉及的节点记录,最后进行排序对网络进行研究与分析,以此获取的比较好的样本,最短路径需要实现知道网络结构以及计算过程较为复杂。
综合以上采样算法研究对比,各有优势,也同时有些不足之处,例如,采样效率、运行时间、算法复杂性、参数可调性、偏差性等等,在每个评测方面难以同时维持最佳性能效果 [24]。实际对OSN采样的时候,又可能受到网络权限的访问限制,以及频繁的网络请求可能会导致采样难以继续。本论文基于随机游走算法,为了修正样本构造的诱导子图带来的误差问题,本文对节点的跳转权重重新进行了调整,弥补了某些情况下,MHRW算法自环率较高的缺陷,在提高了采样效率的同时,依旧保持采集子图具有很好的代表性,能够还原原图。
3. 相关研究
3.1. 随机游走(RW)
随机游走是目前广泛运用于OSN的采样算法,选择若干初始种子节点,然后从当前节点出发,每次随机选择其中一个邻接节点作为下一个跳转的目标,每次跳转的概率为1/ku (ku节点u的度数),转移概率公式如下:
(1)
简单的随机游走算法能够在短时间内构造一个诱导子图,然而这样的采样是偏向于高节点的 [11] [16],其随机游走采样算法服从概率分布:
(2)
每个节点的采样概率均与其度数成正比,该算法并不是无偏的,对于度数越高的节点,被采样到的概率越高。文献 [20] 显示,简单随机游走在每一步对于每个节点选中概率为1/du,当随走过程收敛后,所采集到的样本平均度数与原图节点度数平方成正比:
(3)
其中,ku表示当前节点度数,S表示采集到的样本,G表示原图,d表示原图的平均度数,N表示节点数,Ns表示样本节点数,
表示原始网络图的平均度数。
3.2. 蒙特卡罗随机游走(MHRW)
基于Metropolis-Hastings对于随机游走进行一种改进。该算法从当前节点开始,选择一个邻接节点作为目标节点,产生0~1之间的随机数p,若p小于等于当前节点度数与目标节点度数的比值,则跳转至目标节点,否则停留在当前节点,重复迭代以上过程。转移概率公式如下:
(4)
在任意时刻t,当前游走到节点u时,其邻接节点vi的跳转概率为(Pv1,Pv2,…,Pvn)。当Kv ≤ Ku时,Pv = 1/ku,当Kv > Ku时,Pv = 1/kv。在MHRW算法构建的状态转移矩阵中,从图中所有点到达节点v的概率之和为1,并且对于图中的任意点u和v,均有Puv = Pvu,该过程可以建模为马尔科夫链模型 [20],当t趋于无穷大时,每个节点的采样率均相等,其静态分布收敛于πu = 1/|V|,由此算法所采集到的样本能够精确估算原图度分布。然而高度自循率以及重复采样,大幅度降低了算法的采样效率,MHRW算法高度重复的节点在生成诱导子图的时候只生效一次,有时并不能很好地代表原图。
4. RWSS算法
4.1. 问题描述
本文针对采样子图中的度数偏差以及采样效率问题展开研究。
首先,本文使用MHRW算法对Twitter数据集进行采样,比较采样节点在原图的度分布以及其生成诱导子图的度分布图。
 (a)
(a)  (b)
(b)
Figure 1. Degree distribution diagram of 10000 nodes in Twitter data set by MHRW algorithm: (a) Degree distribution diagram of sample nodes in the original graph; (b) Degree distribution diagram of induced subgraph constructed by sample
图1. MHRW算法在Twitter数据集采样一万节点的度分布图:(a) 样本节点在原图中的度分布图;(b) 样本所构造诱导子图的度分布图
 (a)
(a)  (b)
(b)
Figure 2. Degree distribution diagram of 10000 nodes in Epinions data set by MHRW algorithm: (a) Degree distribution diagram of sample nodes in the original graph; (b) Degree distribution diagram of induced subgraph constructed by sample
图2. MHRW算法在Epinions数据集采样一万节点的度分布图:(a) 样本节点在原图中的度分布图;(b) 样本所构造诱导子图的度分布图
对比图1(a)、图1(b)与图2(a)、图2(b)的度分布图,研究发现,MHRW的无偏特性仅体现在节点的取样方面,所采集的样本度数在原图中均是无偏,然而在构建诱导子图时,多次自环以及重复游走过的节点只能生效一次,尤其是对于一些连通性相当差、度数过于偏低的图而言,过低的采样效率以及过度自循环引起的偏差估计,采集样本所构建的诱导子图,有时并不能很好地代表原图,如图3所示,对于Epinions数据集分别按一定比例进行采样,研究其采样效率与自环率。实验对比发现,这类图由于稳定偏高的自环率,导致采样效率持续很低,并且随着样本量逐渐增大,采样效率呈逐渐下降的趋势。
针对MHRW算法的样本构建子图过程中的度数偏差,本论文提出了一种采样高效、修正子图度数偏差的算法(Random Walk Subgraph Sampling, RWSS)。
4.2. 算法改善
根据上述研究结果,分析随机游走的采样偏差,简单随机游走算法中,跳转节点的选择概率与其度数成正比,在其采样之前,本文将其邻接节点的跳转概率序列(Pv1,Pv2,…,Pvn),Pvi=1/ku,均除以其度数为跳转权重进行研究,得到新的序列(Pv1’,Pv2’,…,Pvn’),Pvi’ = 1/kukv。其概率转移公式为:
(5)
本文使用Twitter以及Epinions数据集做实验比较。
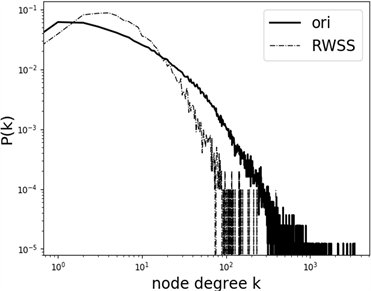 (a)
(a) 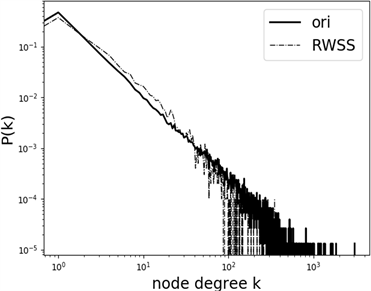 (b)
(b)
Figure 4. Degree distribution diagram of induced subgraph constructed by sample: (a) Twitter; (b) Epinions
图4. 样本所构造诱导子图的度分布图:(a) Twitter;(b) Epinions
图4为使用公式(5)修改后的跳转概率,采样一万节点所展示的结果图,图4(a)为采样Twitter数据集的样本构造诱导子图的度分布图,图4(b)为采样Epinions数据集的样本构造诱导子图的度分布图。从图中可以看出,修改了跳转概率后的算法,严重倾向于低节点的采样,对于相当稀疏的图有着极佳的采样效果,但并不是适用于多种场景。
本文结合RW算法的采样偏差以及MHRW算法的无偏特性,提出一种适用于各种社交网络图的采样算法,通过本文采样算法获取的样本诱导子图,具有非常良好的代表性,能更显著体现原图特性。当kv ≥ ku时,其跳转概率与采样算法MHRW一致(Puv = 1/kv),当kv < ku时,由于先前的MHRW算法在其自循环过程中对很多低度数节点进行了多次重复采样,而这种重复采样在诱导子图的构图过程中是无效的,因为每个节点只能生效一次。由公式可知,MHRW算法在kv < ku时,其邻接节点的跳转概率为Puv = 1/ku。
根据MHRW算法采样无偏特性,本文对于邻接节点度数小于当前节点的跳转概率进行权重参数调整Puv = α/kv + (1 − α)/ku,α Î [0,1]。转移概率公式如下:
(6)
4.3. 参数确定
由公式(6)推算,当α = 0时,该算法完全等价于原先的MHRW算法,随着α值逐渐增大,算法将逐渐偏向于低度数节点的采样。接下来,本文描述如果获取一个最佳α值。对于一个完全不了解属性的社交网络图而言,是无法直接根据图形属性结构进行分析的,首先利用MHRW算法的无偏特性,对其进行无偏采样获取原图度分布,求出其平均度数:
(7)
这里的N记为原图中节点度数类型数,
表示平均度数,pi表示度数为ki的节点数占网络中节点类型总数的比例。
根据α值取值范围,划分区间,进行多次采样测试调整参数,将采样的诱导子图平均度数
与原图
作比较,以获取最佳α值,如图5所示,获取最佳参数值。
由于各个社交网络图的属性结构不一样,以及每次采样大小不同,在对多个图进行不同比例抽样时,α取值也受到各个不同的社交网络图以及同一网络图的采样比例的影响。
4.4. 采样流程
RWSS Sampling
1 Input: Graph G = (V, E)
2 get S by MHRW
3 calculate average degree
by S
4 get α by
5 Select a seed vertex u from V as initial node
6 Add u to the S’
7 While stopping criterion not met Do
8 Select v by Puv based on Formula (6)
9 Add v to the S’
10 u←v
11 end
12 generate G’ by S’
13 output S’, G’
4.5. 采样偏差
本文使用MHRW算法与RWSS算法分别在Twitter数据集与Epinions数据集各采集一万个节点,比较他们的度分布图。
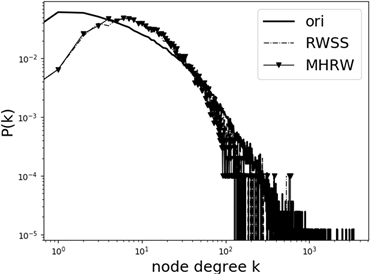 (a)
(a) 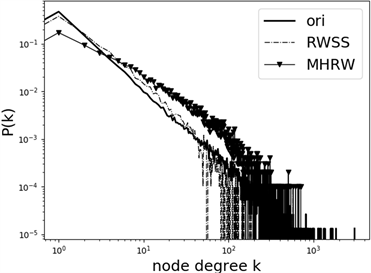 (b)
(b)
Figure 6. Degree distribution diagram of induced subgraph constructed by sample: (a) Twitter; (b) Epinions
图6. 样本所构造诱导子图的度分布图:(a) Twitter;(b) Epinions
图6(a)为采样Twitter数据集的样本,所构造诱导子图的度分布图,图6(b)为采样Epinions数据集的样本,所构造诱导子图的度分布图。从图中可以看出,本文提出修正后的采样算法,不仅在较为稀疏的社交网络图上表现优异,对于之前采样表现不佳的社交网络图(如Twitter)亦与MHRW算法相媲美。并且,通过后续研究发现,随着样本数量增多,本文提出的采样算法将会表现更加优异。
5. 评估实验
复杂网络的连通性和拓扑结构的测量对于分析、分类、建模和验证是必不可少的,本论文使用其中一部分指标进行检测采样效果 [25]。先后研究了多个不同的数据集,本文分别测试了RW、MHRW以及RWSS算法,对于每个数据集,通过数十次不同的样本量进行对各种网络图进行采样,并比较测评采样子图结果。本文对社交网络图的度分布误差(ks值校验)、聚类系数(cluster)、同配性(assortativity)、传递性(transitivity)进行了研究对比。其部分数据集如表1所示。
5.1. 评估属性
本文采用ks值检测图的度分布,ks是算法所采样子图节点度分布与原图节点累计度分布函数差值。如公式所示:
(8)
其中,F(x)是指原图累计分布函数,Fs(x)指采样子图的累计分布函数,ks值越小代表采样子图的度分布与原图度分布越接近,反之,则表示采样子图与原图的度分布差距过大。
聚类系数用来表示一个网络集结成团的系数,对于单个节点来说,即该节点的邻接节点的连接程度。
同配性用来描述网络中,拥有某属性的节点倾向于与其相同属性链接的程度。本文使用度数作为校验结果。
5.2. 实验验证
先前的学者使用MHRW对比研究过广度优先搜索算法(BFS)、滚雪球采样算法、森林火灾算法。研究结果[11]证明,由于BFS的高度节点偏差,MHRW的采样结果在大多数情况下均是优于BFS以及其修正算法。综上,本文不再重复对比BFS以及其类似的修正算法。本文分别使用RWSS、RW、MHRW三种采样方法对数十种社交网络图进行了测评验证,研究结果表明,对于大部分情况下,本文所提算法的采样结果均是优于原先的社交网络采样算法。由于本文使用的RWSS在Twitter数据集上的最佳参数α取值为0,此时采样效果等价于MHRW算法。故不再重复展示Twitter数据集以及类似取值α = 0数据集的研究结果。
本文将其中效果较为显著的社交网络图(表1)的数据集进行度分布、聚类系数、同配性以及传递性采样评测。对于每种图,根据该图大小,按照一定比例的节点采样采样50次以上,将其样本生成诱导子图,所求属性的平均值与原图进行比较。
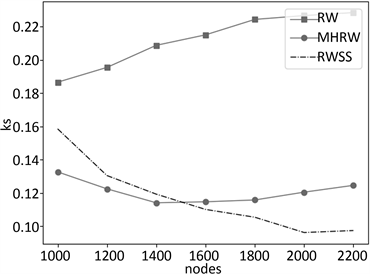
测试实验结果如图7~9所示,其中,横坐标为采样节点数,图(a)的纵坐标为度分布垂直距离ks平均值,图(b)的纵坐标为聚类系平均值,图(c)的纵坐标为同配性平均值,图(d)的纵坐标为传递性平均值。ori为对应的原图数值属性。
图7展示了平均度数、聚类系数、同配性、传递性均偏低的Epinions数据集所构建的社交网络图采样结果,其中参数α取值0.2,实验显示,RWSS采样算法在平均度数与聚类系数的表现效果均远远优于
 (a)
(a) 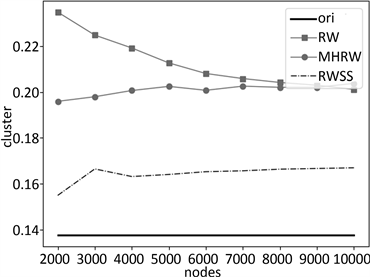 (b)
(b) 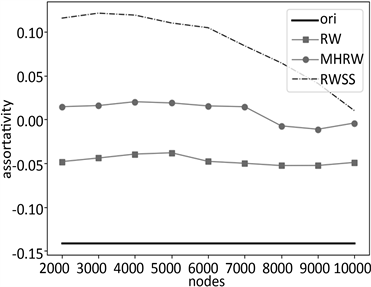 (c)
(c) 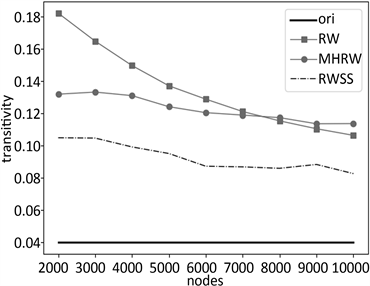 (d)
(d)
Figure 7. Epinions: (a) Degree distribution vertical distance ks; (b) Cluster; (c) Assortativity; (d) Transitivity
图7. Epinions:(a) 度分布垂直距离ks;(b) 聚类系数;(c) 同配性;(d) 传递性
 (a)
(a)  (b)
(b)  (c)
(c)  (d)
(d)
Figure 8. Tvshow: (a) Degree distribution vertical distance ks; (b) Cluster; (c) Assortativity; (d) Transitivity
图8. Tvshow:(a) 度分布垂直距离ks;(b) 聚类系数;(c) 同配性;(d) 传递性
 (a)
(a)  (b)
(b) 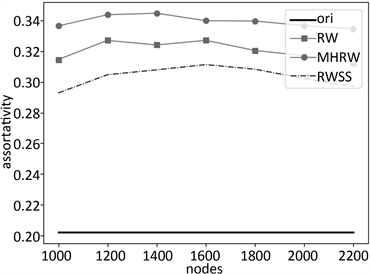 (c)
(c)  (d)
(d)
Figure 9. Public_Figure: (a) Degree distribution vertical distance ks; (b) Cluster; (c) Assortativity; (d) Transitivity
图9. Public_Figure:(a) 度分布垂直距离ks;(b) 聚类系数;(c) 同配性;(d) 传递性
传统的采样算法,其次对于传递性的表现亦是较为优异。图8研究结果展示了平均度数、聚类系数、同配性、传递性均偏高的Tvshow数据集所构建的社交网络图采样结果,其中,参数α取值0.12,RWSS采样算法在各个方面的表现均优于传统的采样算法,且较为接近原图。最后,图9研究结果展示了节点数较少、平均度数与聚类系数较低的Public_Figure数据集所构建的社交网络图采样结果,其中,参数α取值0.05,RWSS算法在度分布、聚类系数、同配性、传递性等方面均优于传统的采样算法,尤其是随着采样节点数量的增多,在度分布方面的误差逐渐减少。综上所述,本文所提的采样算法在大部分情况下,相对于原有算法,均进行了改善优化,其表现效果更加接近原图。
6. 总结
本文在传统的随机游走算法基础上,对采集样本构造诱导子图的偏差问题提出了新的算法。该算法在大部分社交网络图采样所构造的诱导子图,相比较原先的随机游走算法,均进行了优化改善。无论是平均度数、度分布,还是聚类系数、同配性、传递性校验,通过对数十种社交网络图进行研究,每种图按照一定比例进行多次采样,每次样本构造的诱导子图与原图对比度分布、聚类系数、同配性、传递性。结果表明,本文所提算法的综合表现均优于原先游走算法,所生成的诱导子图更加精确接近于原图,并且节点的采样效率相比较MHRW算法,也得到大幅度的提高。
最后,通过对大量实验数据研究证明,RWSS算法在面对不同类型的OSN进行采样时,对于各个方面的指标,均有着十分优异的表现。
参考文献