1. 引言
随着机器人技术的快速发展,乒乓球机器人等运动类的机器人也逐渐受到广泛关注。乒乓球运动机器人集视觉系统、决策系统、控制系统于一体,机器人系统设计好坏与机器人控制系统反应时间、击打到来球的概率相关。现有研究工作大多关注于乒乓球本身,对乒乓球进行旋转测量 [1] [2] 或者预测乒乓球的飞行轨迹 [3] [4] [5]。而在实际乒乓球运动场景中,运动员无法像机器一样准确地计算乒乓球的运动情况,基本上都是根据对手击球的姿态动作变化进行判断的,因此对乒乓球击球者进行姿态估计,研究其姿态变化有助于乒乓球机器人视觉系统的设计。文献 [6] 提出了基于轻量化特征融合网络的击球者姿态估计方法,对识别到的对手的姿态序列建立分类模型,判断击球者的挥拍动作。此外,文献 [7] 利用双目视觉系统获取球拍的三位位置和姿态,采用卡尔曼滤波器跟踪球拍姿态,并采用神经网络对姿态进行分类预判球的旋转类型和速度。但目前来说,由于击球者动作变化速度快且幅度较大,且相似动作太多,所以对于击球者姿态估计的发展还处于初级阶段,相关算法还相对较少,并且目前存在的算法在准确性和实时性上还有待提高 [8]。
人体姿态估计在计算机视觉领域发展迅速,姿态估计的任务中包括自顶向下(top-down)和自底向上(bottom-up)两种方式。自底向上的方式是对输入图像的中人体关键点直接进行估计,然后再通过组合算法将各个关键点进行定位,如OpenPose [9] 等。自顶向下的方式就是先对人体进行目标检测,再将人体检测的结果输入到关键点检测的网络中,实现人体姿态估计。因此要准确对击球者进行姿态估计的前提是要能快速且准确定位场景中击球人所处的位置,再通过关键点检测去估计人体所处的击球姿态。人体检测框的误检和冗余都会直接对后续单人姿态估计产生影响,因此在自顶向下的姿态估计算法研究中侧重于对检测器研究,常用的人体检测器有FasterR-CNN、MaskR-CNN、特征金字塔网络等。
传统人体姿态估计是依赖骨架模型的建立重构人体姿态,随着卷积神经网络(Convolutional Neural Network, CNN)的快速发展,2014年Toshev等提出DeepPose [10] 首次用CNN来解决姿态估计问题。由于神经网络层数太深时易出现梯度消失的问题,Wei等 [11] 针对这个问题提出了一种多阶段估计方法——卷积姿态机(Convolutional Pose Machine, CPM)。对于一张包含人体姿态的图像,目前普遍采用的检测方法是“从高分辨率处理至低分辨率”,或者“从低分辨率处理至高分辨率”,前者由细节至整体,后者由整体至细节。两种方法同样有效,且适用于不同的场景,大部分研究均选用其中之一,Stacked Hourglass Network [12] 的提出协调地支持了这两种处理方法,多个Hourglass模块的叠放可以获取更加丰富的多尺度特征,残差结构的运用又避免了Hourglass模块中可能出现的特征信息丢失的情况。Sun K等 [13] 认为在这样一个过程中,可能会导致高分辨信息的丢失,因此针对这一问题提出了HRNet (High-Resolution Network)。HRNet并行地进行高分辨率的特征提取,始终保持高分辨率表示,确保了高分辨率信息不在低分辨率向高分辨率恢复的过程中丢失,从而提高了人体关键点的预测的准确度。2020年Cheng等人 [14] 在HRNet的基础上提出Higher-HRNet,加入多尺度监督和反卷积模块来进一步提高分辨率,从而获得更好的预测结果。上述姿态估计算法研究在提升检测精度的同时也增加了参数量和运算复杂度,如何保证姿态估计精度的同时降低运算量是目前人体姿态估计模型改进要研究的问题 [15]。
综合上述研究,针对本文要解决的实际问题——乒乓球机器人视觉系统识别对手挥拍动作姿态,提出了基于增强高分辨率的姿态估计算法:1) YOLOv5作为人体检测器提高检测精度和速度;2) YOLOv5融入Ghost模块减少模型参数量,进一步提高模型检测速度;3) 结合HRNet网络提高关键点检测精度,在人体姿态估计的第一步人体检测的过程中降低运算量提高运算速度,同时也保证了关键点检测结果的准确性。
2. 研究方法(Approach)
本文提出的乒乓球击球者姿态估计框架是基于Top-down形式的姿态估计方法,主要分为两个阶段。第一阶段,以改进的YOLOv5模型快速准确地定位并获取场景中击球人的具体位置,并将人体检测的位置信息传递给第二阶段——关键点检测模块,从而提高姿态估计的识别精度。输入图像提取特征到检测获得击球者所在的位置,然后通过学习击球者的关键点特征信息,并将学习到的信息作为关键点检测器回归出各个关键点的位置及类别的信息,从而得到此时乒乓球运动场景下击球者的姿态信息,整体姿态估计流程如图1所示。
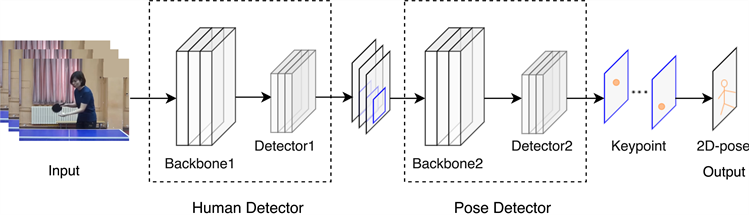
Figure 1. The process of pose estimation
图1. 姿态估计流程
2.1. 人体检测模块(Human Detector)
由于乒乓球运动是一项动作以及位置变换都很迅速的运动,需要快速且准确的定位此时击球者所处的位置,尽可能做到实时的人机交互,因此能快速且准确地定位到击球者的位置对于提高后续的姿态估计准确度至关重要。
2.1.1. Ghost模块
Ghost模块(图2)是GhostNet模型中针对卷积神经网络中存在大量特征图冗余而提出的轻量化解决方法 [15]。它将标准卷积分为以下两部分,由少量计算生成大量的特征图,从而有效减少特征图的冗余问题。
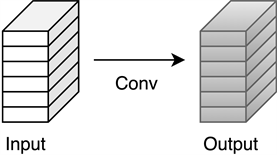 (a) The convlutional layer
(a) The convlutional layer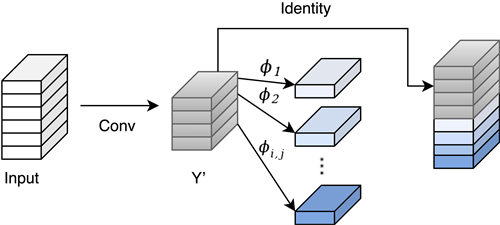 (b) The Ghost module
(b) The Ghost module
Figure 2. The Ghost module
图2. Ghost模块
1) 将输入的特征图
,其中c为输入通道数,h和w分别为长和宽;卷积核
,k和n分别为卷积核尺寸和数量,由经典卷积公式(式1)得到特征图。用少量卷积运算生成m个通道的本征特征图Y' (intrinsic feature maps);
2) 将Y'经过线性变换运算
生成Ghost特征图
,并将两者进行拼接输出特征图Y。
, (1)
式中,b为偏置项,Y为输出特征图,
表示卷积运算。
, (2)
式中,
代表Y'中第i个本征特征图,
代表第j次线性变换生成的阴影特征yi, j。
最终Ghost模块输出
个特征图,输出的特征图大小为
。
普通卷积和Ghost卷积所需运算量分别如式(3)和(4)所示:
, (3)
,(4)
其中
为线性运算核尺寸,s为线性运算的数量,且
。
因此,由式(5)可以看出,Ghost模块在理论上计算量约为普通卷积的
,参数量的计算也同样约为其
,这说明模型中将Ghost模块替换原有的普通卷积能够有效减少模型参数量,加快模型运算速度。
(5)
2.1.2. 融合Ghost的YOLOv5算法
相较于诸如CascadeR-CNN、FasterR-CNN等Two-stage类的目标检测模型,如YOLO、SSD等One-stage模型虽然在检测精度上不如Two-stage模型,但在检测速度上更具有优势,在保证一定检测精度的情况下,减少了模型检测的时间。YOLO系列算法是One-Stage目标检测模型中典型的算法,且YOLOv5模型是YOLO系列算法中具有更高检测精度且推理速度也更快的最新算法,它采用CSPDarknet作为Backbone,并将FPN (Feature Pyramid Networks)和PAN (Path Aggregation Networks)相结合做网络的特征融合和加强提取,加强网络的特征融合能力和定位信息,易于在乒乓球运动场景下保证击球者检测精度的同时也能减少检测时间。
YOLOv5在YOLOv4的基础上根据不同通道的尺度缩放,构建了YOLOv5-N/S/M/L/X 5种模型,本文选用YOLOv5s模型,并在此基础上将网络中颈部层中普通卷积模块替换为Ghost卷积模块,降低模型运算量,加快模型检测速度,改进后的YOLOv5模型结构如图3所示。

Figure 3. Structure diagram of YOLOv5 model integrating Ghost module
图3. 融合Ghost模块的YOLOv5模型结构示意图
2.2. 关键点检测模块(PoseDetector)
将高分辨率网络 [13] (High-Resolution Network, HRNet)作为乒乓球运动场景下击球者关键点检测网络的主干网络可以有效提高姿态检测的精度,通过在第一阶段的高分辨率子网络中逐步并行加入低分辨率子网络,同时进行重复的多尺度表征融合,始终保持高分辨率表征,采用的并联结构避免了串联结构方案中可能存在的细节信息丢失。
本文提出的姿态估计模型将基于Ghost模块的YOLOv5网络作为人体检测器,将人体检测框的结果输入关键点检测网络中对各类关键点进行检测与分类,实现乒乓球运动场景下击球者的姿态估计(如图4)。
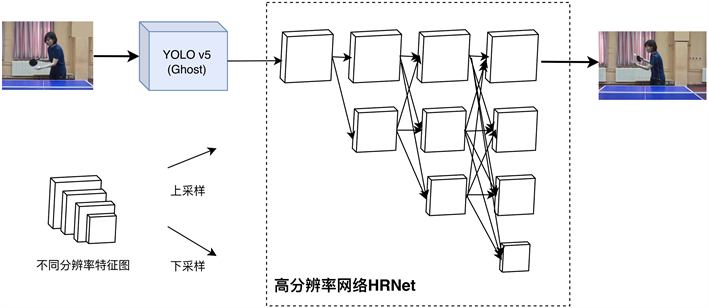
Figure 4. Structure diagram of key point detection module
图4. 关键点检测模块结构示意图
3. 实验与分析
3.1. 数据集处理
本文针对乒乓球机器人的视觉场景制作了一个特定的数据集PP-Person,其中数据集主要来源于从网络爬取的乒乓球比赛视频,实验室采集以及公开数据集中抽取,将球桌对面机位的包含不同光照、轻微遮挡程度、姿态的视频作为可用的数据样例(图5(a)~(d)),而场景中包含大量除击球者以外的无关人员,遮挡程度过高、摄像头在侧面等视频数据作为不可用样例(图5(e)~(f))。本文共收集了不同场地、不同运动员的乒乓球运动场景视频共117段,将每段视频均剪辑至9 s的视频片段,并以30 fps的帧率将各段视频进行分帧,并抽取每10帧中的1帧作为实验数据,一共获得乒乓球运动场景下图像6107帧。为了降低数据间的关联性,本文将同一视频采集的分帧图像统一放入训练集或者测试集当中,具体来说,本文将上述乒乓球运动员姿态估计数据集中100段视频采集的共5091帧图像用于训练,将另外剩余的17段视频中共1016帧图像用于测试,保证两者之间没有交叉。

Figure 5. Table tennis video framing image ((a)~(d): Examples of available data; (e), (f): Unavailable data sample)
图5. 乒乓球视频分帧图像((a)~(d):可用数据样例;(e),(f):不可用数据样例)
本文研究的是乒乓球机器人视觉场景下的运动员姿态估计,需要检测的目标是机器人视觉系统捕捉采集到的对手,需要检测的关键点主要基于运动员的上半身,而下半身膝盖和脚踝的关键点不是本文研究的范围。因此,本文以COCO数据集的标签格式作为范式,在此基础上对关键点的标签进行了修改(如图6),以达到更加契合我们研究场景的目的。

Figure 6. Schematic diagram of keypoints correction
图6. 关键点修正示意图
3.2. 评价指标
本文采用COCO数据集的评测指标——基于关键点相似度(Object Keypoint Similarity, OKS),其定义如式(6)所示:
, (6)
其中,di表示预测关键点与对应grountruth坐标间的欧氏距离;vi代表groundtruth是否可见;ki为用以区分不同关键点类别的常量;s表示目标尺度大小。平均精度和召回分数AP为当OKS = 0.50, 0.55, ..., 0.90, 0.95时取得平均值,AP50和AP75分别表示OKS = 0.50和0.75时预测关键点的准确率。
3.3. 实验平台与环境配置
本研究实验在Ubuntu 18.04系统使用Python语言进行程序代码的编译,软件配置为PyTorchv1.8.0、CUDNNv7.2、CUDAv10.2;硬件配置为Intel i7-9700K 3.60 GHz的CPU,12G NVIDIA 2080Ti的GPU。
本文将数据集PP-Person中的图像固定纵横比,裁剪到固定尺寸为256 × 192,并且为了增强提出模型的鲁棒性,对本标注数据集采用Mosaic数据增强策略提出的姿态估计模型输入尺寸为256 × 192 × 3,Batchsize设置为32,训练50个epoch。
3.4. 实验验证与分析
本文基于PP-Person数据集,对比了HRNet与不同的经典人体检测模型结合的姿态估计结果,同时也将本文提出的姿态估计模型与当下热门的人体姿态估计网络模型进行了对比,对比结果如表1所示。

Table 1. Comparison results of different attitude estimation model algorithms
表1. 不同姿态估计模型算法对比结果
从上表中可以看出,在本文提出的姿态估计算法模型较其他热门的姿态估计算法模型在本文数据集PP-Person上来说关键点的预测精度有所提高,并且在检测速度上最多提高了66.2%。结果表明,本文提出的算法在保证一定检测精度的情况下,能大大减少模型运行的时间,从而使乒乓球机器人能在较短的时间内捕捉对手的姿态变化,有充足的时间做出控制决策作出高质量回球。
3.5. 结果可视化研究及分析
本文在提出的数据集PP-Person上做可视化验证,从验证集中随机选择不同程度的自身遮挡状态以及不同拍摄环境下的图片,得到的检测情况如下图7。

Figure 7. Visualization results of some models
图7. 部分模型可视化结果图
从上图可以看出本文提出的模型在运动员姿态变化幅度较大存在自身遮挡时也能较好地检测出各个关键点的位置,在环境光照条件不足等情况下也能较为准确地检测出各个关键点的位置。
4. 结束语
本文针对乒乓球机器人视觉系统提出的自顶向下的人体姿态估计模型将融入Ghost模块的YOLOv5网络作为姿态估计模型中的人体检测器,在乒乓球机器人视觉场景数据集PP-Person上,模型关键点检测精度达到72.6%,比Hourglass提高了5.4%,比Simplebaseline提高了2.3%,比HRNet提高了1.4%。在提高了关键点检测的精度的同时,降低了模型的运算量,加快了模型的运算速度,实时运行的帧率能达到10.4 fps/s,速度较HRNet提高55.76%,从而能够帮助乒乓球机器人在较短时间内捕捉并识别到对手的姿态,为今后设计乒乓球机器人视觉系统时分析乒乓球旋转状态提供击球者姿态估计的模型基础。