1. 引言
古往今来,农业一直是人类生存发展的基础,其中粮食更是与人民生活息息相关。伴随着粮食产业的多元化发展,粮食生产行业的研究意义逐渐凸显,充足的粮食供应对国民经济长期稳定发展具有重大意义。同时,我国土地粮食产量预测一直都是农业问题中的重点,其工作意义重大,对国家规划国民经济发展起决定性作用 [1],精准预测粮食产量也有利于国民经济等领域的发展。只有国家粮食储备充足,民众才能过上更好、更丰富的生活,追求更高层次的精神领域富足 [2]。山西省作为我国农业大省之一,相关政府部门十分重视粮食生产情况,并一直加大对农业产业的投资以保证粮食产量的稳速增长,故对山西省粮食产量的预测研究具备实际意义。
目前,国内外对相关粮食产量的预测方法主要有气象统计预测、遥感技术、动力学模拟、灰色系统、线性回归及时间序列等 [3]。例如,国外学者Hansen等通过反复测量冠层反射率后构建偏最小二乘回归预测冬小麦和春大麦的籽粒产量和蛋白质含量,预测结果较为精确,但此方法耗时较久 [4];Bail等利用土壤、作物分析仪器(SPAD)的测量不同冬小麦品种的籽粒质量和产量值并进行预测,但此法潜在限制因素较多,结果可能差异较大 [5];Mkhabela等下载美国宇航局研制的中分辨率成像光谱仪(MODIS)里的归一化植被指数数据(NDVI)后对加拿大大草原作物产量进行预测,其建立的模型在预测加拿大大草原作物产量方面显示出一定的潜力 [6]。以上介绍的方法都各有优劣,虽在其本身研究课题上具有一定的优越性,但仍存在如精确性、耗时长等局限性,有待进一步的改进。而国内主要将目光集中在粮食产量数据及其相关影响因素上,并基于此进行统计分析建模。郭晓婷通过多元回归和时间序列分析了安徽省粮食产量,并对比预测精度,选取多元回归模型进行预测,预测效果良好 [7];李铭通过多元线性回归模型分析了15个可能影响山东省粮食生产的因素,并构建MLP神经网络模型,结果表明MLP模型具备稳定性和准确性且预测精度较高 [8]。也有不少研究将灰色预测应用到粮食产量上,如雷蕾等基于四川省粮食产量构建灰色模型且预测精度较高,表明其未来粮食产量呈增长趋势 [9];孟凡琳基于河南省粮食产量构建灰色模型并进行改进,预测效果良好 [10],但有相关研究显示使用灰色线性组合模型对河南省粮食产量进行预测的预测精度更优 [11];薛晋芳对山西省的粮食产量进行了分析和预测,利用灰色线性组合模型进行预测,结果符合预期 [12];陈婷怡等将二次指数平滑模型、灰色模型和支持向量回归模型进行组合优化,利用线性组合预测模型对云南省2021~2023年的粮食产量进行预测 [13]。戴剑勇等将灰色预测模型与逻辑斯蒂预测模型组合,并对相关数据进行预测,虽然不是对粮食产量进行预测,但其组合模型的预测思想值得借鉴 [14]。综上所述,组合模型的预测在总体上来说较单一模型的精度更优,也考虑了更多的可能性,才使得预测的结果更加接近现实,更有说服力,同样推测组合模型对山西省粮食产量的预测也具备较好的能力。
本文基于2000~2021年的山西粮食产量构建了灰色预测模型、灰色修正预测模型以及灰色线性组合模型,从中选取精度最优的预测模型对山西省粮食产量进行预测,并结合预测结果以及实际情况提出合理建议,以期为调整和发展我国粮食产业提供理论参考,为政府部门以及相关生产者们提供依据与决策。
2. 资料与方法
本文基于灰色系统理论对山西省粮食产量进行建模研究,其中粮食产量数据来自国家统计局 (http://www.stats.gov.cn/)。由于粮食产量受环境等多种未知因素的影响,符合灰色理论中的灰白不确定性特征,结合2001~2021年山西省的粮食产量呈上升趋势(图1),经初步分析可建立灰色预测模型。
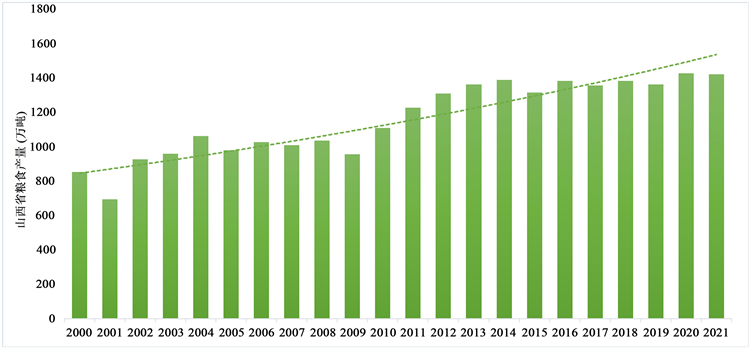
Figure 1. Histogram of year-on-year change of grain production in Shanxi Province from 2000 to 2021
图1. 2000~2021年山西省粮食产量逐年变化柱状图
1982年,邓聚龙教授为解决数据缺乏及不确定性问题提出了灰色系统理论,其相关模型又被称为灰色模型或灰色动态模型(简称GM模型)。构建灰色模型即可进行灰色预测,其核心是基于不确定背景下,通过数据处理分析建立模型,对发展趋势进行有效合理的预测评估。实现灰色预测首先需要确定处于某一范围内并与时间有关的灰色过程中的数据,再根据关联分析鉴别系统因素之间发展趋势的相异程度,其次对原始数据进行生成处理去寻找该系统内部的变动的规律,以最终生成的具有较强的规律性的数据序列建立相应的微分方程模型,最后,通过该灰色模型对事物未来的发展趋势进行预测。这里主要介绍灰色建模中数据检验与处理、建立模型以及模型检验三个部分的理论知识,并基于此进行山西省粮食产量灰色预测模型的构建。
2.1. 数据的检验与处理
首先,为保证建模方法的可行性,需要对已知数据列做必要的检验处理。设参考数据为时间序列
,计算序列的级比:
(1)
若(n − 1)个级比
都落在
范围内,则序列
可以作为灰色模型的数据进行灰色预测。否则,需要对序列
进行变换,使其落入
范围内。变换方法为取适当的常数l,令
(2)
使序列
的级比:
(3)
2.2. 灰色模型
已知的时间序列
,对其一次累加生成新的序列:
(4)
的均值生成序列:
, (5)
式中,
。
建立灰分方程:
(6)
相应得白化微分方程为
(7)
式中,a为发展灰数,b为内生控制灰数。
记a为待估参数向量,
,
,
, (8)
利用最小二乘法,可得u的估计值为:
(9)
求解白化微分方程,得
(10)
2.3. 灰色残差修正模型
灰色残差修正模型是对灰色预测模型进行残差检验后,根据实际值与预测值的误差,为提高灰色预测模型的预测精度而构建的模型,其主要目的是为了丰富和完善灰色预测模型。过程如下:
首先,根据原始序列得其残差序列为:
为便于计算,改写为:
(11)
的累加生成序列为:
可建立相应的GM (1, 1)模型:
的导数为:
加上修正项,得到修正模型:
(12)
其中,
为修正系数。
2.4. 灰色线性组合模型
灰色线性组合模型适用同时具备指数增长趋势和线性趋势序列,利用线性回归方程和指数方程的有用信息来拟合之前的累加生成序列,可以将生成的序列写成:
(13)
v和
、
、
是待定参数。
确定组合模型参数。设有参数序列:
(14)
又假设
(15)
可得:
将累加生成的序列代入公式(14)中可以得到v的近似值
,不同的m得到不同的
,然后对其取平均得到估值
。即
(16)
代入公式(2.1)中,利用最小二乘法可以解出
、
、
的估计值。
GM (1, 1)模型对序列处理结果记为:
,
,
(17)
可得:
然后计算出累加生成序列的预测值,再通过累减生成进行还原,就可以得到原序列的预测序列。
2.5. 模型检验
对灰色预测模型得检验主要包括残差检验、关联度检验以及后验差检验。
1) 残差检验
令残差为
,计算
(18)
这里
,若
,则认为达到一般要求;若
,则认为达到较高的要求。
2) 关联度检验
计算出
与原始序列
的关联系数,然后计算出关联度,根据经验,当
时,关联度大于0.6即可。
3) 后验差检验。计算原始序列的标准差:
(19)
计算绝对误差序列的标准差:
(20)
计算方差比:
(21)
计算小误差概率:
(22)
令
,
,则
,关于P与C的取值对应的拟合效果如下:
若
,则拟合效果好;
若
,则拟合效果合格;
若
,则效果不合格。
3. 模型构建
这里仅以2000~2017年山西省粮食产量数据进行三类模型构建,并预留2018~2021年的粮食产量数据进行预测精度检验,选取最优模型。
利用R软件进行灰色预测模型的构建,可得到其待估参数向量为:
故其灰色预测模型为:
在构建灰色残差修正模型前,需要根据实际值和由灰色预测模型得出的预测值计算残差,并利用残差序列构建残差序列的GM模型,得到其待估参数向量为:
基于残差序列得到的灰色预测模型为:
其导数为
故可得到灰色修正模型为:
其中,
为提高模型的预测精度,尝试构建灰色线性组合模型,首先将生成的序列写成:
形式并确定组合模型参数。
设有参数序列:
再假设
可得:
最后进行灰色线性组合模型预测,得到
灰色线性组合模型的预测值为:
4. 模型检验与分析
4.1. 模型检验
模型检验主要包括残差检验、关联度检验以及后验差检验三部分,分别计算三个模型的平均误差、关联度、后验差(表1)。经对比分析可知,三类模型的平均误差均小于0.1,通过残差检验;关联度均大于0.6,通过关联度检验;同时,这三类模型的后验差比值检验C值均小于0.35,小误差概率大于0.95,故三类模型均通过后验差检验,且模型的拟合效果好。

Table 1. Three types of model test results
表1. 三类模型检验结果
4.2. 模型预测
由第3节和第4节的第1小节可知三类灰色预测模型均可适用,接下来分别计算相对误差(表2),根据2018~2021年的实际值与绝对值的平均绝对百分比误差(MAPE)确定最优模型。
Table 2. Grey forecast of grain production in Shanxi Province from 2000 to 2017
表2. 2000~2017年山西省粮食产量灰色预测
如表3所示,GM (1, 1)模型的MAPE为12.01%,相对于残差修正后的GM (1, 1)模型(11.99%)和灰色线性组合模型(4.49%)的预测精度更低。残差修正后的灰色预测模型相较于与灰色预测模型而言只提高了较小精度,考虑到粮食产量的增长是呈现不完全指数增长,还有存在一定的线性关系,于是使用灰色线性组合模型,其MAPE相对于灰色预测模型提高了62.61%,这说明灰色线性组合模型的预测效果更优。同时,在预测模型相对误差表中可以观察到在2001、2004、2009年的粮食产量的相对误差较高,但是总体预测精度良好。
Table 3. 2018~2021 gray prediction accuracy comparison and MAPE
表3. 2018~2021灰色预测精度对比及MAPE
综上所述,结合三种模型检验以及MAPE,从灰色模型、灰色预测模型以及灰色线性组合模型中选取灰色线性组合模型对山西省的粮食产量进行预测,得到2018、2019、2020、2021年的粮食产量分别为1322.4、1330.8、1338.1、1344万吨,实际值与预测值散点图如图2所示。

Figure 2. Comparison chart of the actual and predicted changes in grain production in Shanxi Province from 2000 to 2021
图2. 2000~2021年山西省粮食产量实际值与预测值变化对比图
5. 结论与展望
本文基于2000~2021年的山西省粮食产量数据分别构建了灰色预测模型、残差修正的灰色预测模型以及灰色线性组合模型,三类模型的平均绝对百分比预测分别为12.01%、11.99%以及4.49%,拟合精度分别为87.99%、88.01%、95.51%,灰色线性组合模型的预测精度最优,较灰色预测模型其预测精度提高了62.61%。虽然构建的灰色预测模型未考虑到山西省粮食产量的环境影响因素以及品种因素,但仍可应用灰色系统理论的特性构建灰色预测模型或进行改进对数据进行预测。结合本文分析,虽然未分析影响山西省粮食产量因素,但在实际情况下,政府部门仍需加强对农业产业的调控,尽可能地控制认为因素,比如农作物的化肥使用量、农药使用量等,在后续工作中需要对影响因子进行分析,解决部分数据误差大的问题。