1. 引言
如今,强化学习 [1] 在各个领域的应用十分广泛,尤其当AlphaGo击败人类顶尖围棋选手之后,一股人工智能热潮更是为世界工业文明带来了新的活力。
在强化学习中,如果已知环境模型,通常使用动态规划(Dynamic Programming, DP)的方式解决问题,但实际情况往往复杂且多变,我们常常无法得知环境的状态转移函数和奖励函数的形式。由于没有具体的模型,则只能通过智能体与环境交互,不断采样的方式获得数据,从而进行策略评估和策略迭代直至得到最优策略,在强化学习中称这类算法为无模型算法。蒙特卡洛(Monte-Carlo, MC)算法是其中最为经典的算法。1988年Sutton等人首次结合MC和DP算法的思想,提出时序差分(Temporal-Difference, TD)算法 [2]。如何根据自己的需求,有选择地从环境中选择自己需要的数据,权衡对现在和未来时刻的利用和探索,为了更好地解决这一问题,强化学习算法又分为在线策略(on-policy)和离线策略(off-policy)算法。
Sarsa [3] 作为TD算法中基于无模型的典型在线策略学习方法,大量学者对此都有所探讨。基于Sarsa算法收敛效果不稳定的缺点,VanS等人将下一状态Q值的期望作为目标值的估计,提出方差更小、估值更加稳定的Expected Sarsa算法 [4]。Robards等人考虑使用无参函数逼近函数的核方法,将一种有界的基于核的感知器与Sarsa算法相结合,提出基于核的Sarsa(λ)算法 [5],使得算法更加高效;在此基础上,朱海军从稀疏化算法的角度出发,提出基于聚类的选择性核Sarsa(λ)算法 [6],都有效缓解了强化学习算法中收敛精度低、收敛速度慢的问题。De A.等人在全采样和非采样之间,将经典Sarsa和Expected Sarsa算法结合,提出用两者估值方程的凸组合进行估值的
算法,在实验效果中有着更优的表现 [7];同年,杨瑞分析了
算法的收敛条件 [8],为其提供了理论基础。这几种方法虽然能一定程度上缓解Sarsa算法收敛速度慢、精度低、效果不稳定的问题,但仍然存在各自的局限性。
随着信息技术的不断发展,不仅无模型控制是自动控制领域中的一个重要发展方向,在复杂系统和复杂性科学面前,如何找到简单有效的控制方式也是目前研究的重难点。而PID (Proportion Integration Differentiation)控制作为系统控制经典方法的代表,有着结构简单、稳定性好、可靠性高等优势,在工业控制中有着广泛的应用。在无法得知精确的数学模型,或者涉及的问题过于复杂的情况下,PID控制技术可以仅仅根据系统的误差,利用比例、积分、微分计算出控制量,从而“稳定、快速、准确”地逼近目标值。
在系统与控制科学不断进步的当今,各种复杂系统的精准有效调控显得尤为重要 [9] [10],而PID控制与强化学习方向的有效结合,更是有望将问题化繁为简,使得算法更加高效稳定。部分学者对此也有所研究。陈学松等人将强化学习中执行器–评价器(Actor-Critic, AC)学习算法与PID控制结合,利用AC算法的无模型在线学习能力,对PID参数进行自适应调整,提出AC-PID控制器设计方法,使得控制器的响应速度提高,自适应能力增强 [11];在此基础上,段友祥等人利用多线程异步学习特性,提出基于异步优势执行器–评价器的PID控制器 [12]。在连续型环境下,程丽梅等人以一阶倒立摆系统为例,将PID控制和强化学习算法效果进行对比分析 [13]。甄岩等人将深度强化学习算法应用于PID控制的参数整定,研发出更加智能的复杂飞行控制器 [14]。
Sarsa算法作为一种在线策略算法,一定程度解决了数据的利用和探索困境,但探索的程度也会影响算法收敛速度以及稳定程度。而PID控制在无模型的情况下,不仅能够迅速稳定地逼近目标,并且通过比例、积分、微分部分的参数调整,对现在、过去、未来的误差进行有效地控制和预防,对数据利用与探索的权衡方面也有着很大地启发。因此,本文将PID控制与强化学习Sarsa算法中Q值的更新方式相结合,讨论这种基于PID迭代更新算法的优点和适用性,以期提高算法的收敛速度和稳定程度,使其具有更高的理论和实践意义。
2. 主要知识简介
2.1. 强化学习的Sarsa学习简介
2.1.1. 强化学习基本原理
在强化学习中,智能体通过不断地与环境进行交互,得到反馈,在试错中学习,以此来调整优化自身的状态信息,其目的是为了找到最优策略或是最大奖励。
在现实中的强化学习环境中,一般是基于马尔可夫决策过程(MDP)的相关理论,将问题抽象为五元组
,其中S表示环境的有限状态集,A表示智能体的有限动作集,
表示状态转移函数,R表示奖励函数,
表示折扣因子。需要特别注意的是,智能体从当前状态s,根据某一策略
选择动作a,到达下一个状态s'的概率是满足马尔可夫性质的,如(1)式所示。
(1)
(1)式表明:在给定当前状态时,智能体的未来状态与过去无关,它们之间是条件独立的。
在强化学习中,我们不但要考虑算法的计算量,也要考虑我们产生数据所消耗的成本。如何控制成本提高数据效率,即对应着强化学习中经典的利用探索困境。强化学习的目标是“尽量找出奖励期望值最大的动作”,但由于未来的不确定性,无法真正确定奖励的真值。如何在最大化利用数据的同时又不失对数据的探索,这二者之间的平衡是提高数据效率的关键所在。这一关键不仅运用于选取动作的探索算法中,在对动作价值函数的迭代更新中也有所体现。Sarsa算法、n步Sarsa算法、Q-learning算法都是强化学习中的常用方法,下面仅对Sarsa算法的更新过程做简要介绍。
2.1.2. Sarsa算法简介
Sarsa算法由其迭代过程
得名,是强化学习中经典的无模型方法。
在强化学习中,对目标量的估计更新形式如(2)式所示。
(2)
(2)式中Target-OldEstimate表示估计的误差,也对应着更新的方向,StepSize表示更新步长。
时序差分算法不同于蒙特卡洛和基于动态规划的算法,其无需知道具体的状态转移函数P和奖励函数R,而是直接通过在环境中采样即可得到数据。基于贝尔曼方程的思想,它采用当前获得的奖励加上下一个状态的价值函数来当作在当前状态所获得的回报,其中常数值
为更新步长,
为折扣因子,更新形式如(3)式。
(3)
(3)式中
被称为时序差分误差。
Sarsa算法基于时序差分的思想,直接更新动作价值函数
,再根据
-greedy策略
选择相应的动作,更新方式如(5)式。
(4)
(5)
不同于Sarsa算法只利用一步奖励和下一个状态的价值估计去估计目标值,n步Sarsa算法利用了n步的奖励和第n步时的动作价值函数估计,如(6)式。
(6)
Sarsa算法的收敛性与
-greedy策略有关,智能体以
的概率选择Q值最大的动作,再以
的概率从动作集中随机选择动作。由于
的取值较小,所以可以保证算法以概率1收敛到最佳策略,但也会导致更新过程中对所有Q值的访问时间较长,收敛速度变慢,并且也有陷入局部最优的风险。
针对Sarsa算法收敛较慢、收敛效果不稳定、容易陷入局部最优的问题,本文拟利用PID控制的思想来改进Sarsa算法。
2.2. PID控制简介
2.2.1. PID控制系统
经典的PID控制系统如图1所示,其中输入给定目标值,输出实际值,e(t)是目标值与实际值之间的偏差,而u(t)是控制量,控制系统主要有被控对象和控制器组成,其中控制器是关于偏差e(t)的比例、积分、微分三部分的线性组合 [15]。
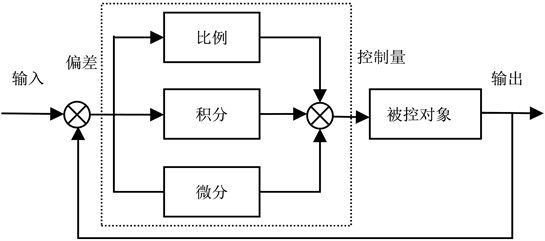
Figure 1. Flowchart of a classic PID control system
图1. 经典PID控制系统流程图
PID控制公式可写为:
(7)
其中为kP为比例系数,
为积分时间常数,
为微分时间常数。
在经典PID控制系统的前提下,离散状态为相应的位置式PID控制,控制公式如(8)式。
(8)
其中
分别为比例、积分、微分系数。
2.2.2. PID学习律
基于迭代学习的思想,在系统控制理论下,学习控制的目的是找到一个合适的学习律,当迭代学习中序列
一致收敛于理想控制输入时,被控系统的实际输出值
尽可能接近目标值
,其中k为迭代次数,
为迭代学习增益矩阵。PID学习律的形式如(9)式。
(9)
而在非线性系统的PID学习律的收敛性在文献 [16] 中已得到证明。
正是考虑到PID控制能够“稳定、快速、准确”地逼近目标值,本文提出Pid_Sarsa算法,以期解决Sarsa算法收敛较慢、收敛效果不稳定、容易陷入局部最优的问题。
3. 基于PID更新的Pid_Sarsa算法
在工程控制中,通常根据系统是否有反馈,将控制分为开环控制和闭环控制,而PID控制在闭环系统中有着独特的优势。在强化学习中智能体与环境的交互过程中,智能体每执行一个动作,都会到达下一个状态,获得一个及时奖励,如图2所示。
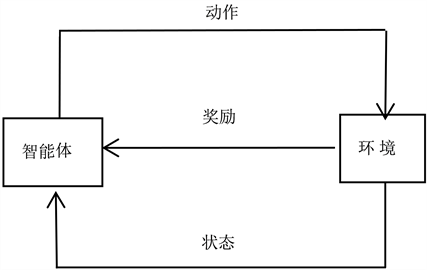
Figure 2. Flowchart of reinforcement learning
图2. 强化学习流程图
另一方面,开环控制只关注输入,而不关注输出结果精度,输出结果是不确定且没有目标的,不会反馈回输入参与控制。而强化学习以找到最优策略、或者找到最大奖励为目标,且拥有及时反馈,所以将PID控制应用于强化学习环境是可行的。
在强化学习中,Sarsa算法具有收敛较慢、收敛效果不稳定且容易陷入局部最优的缺点,由于Q值的迭代方式决定了该算法的收敛效果,所以考虑对Sarsa算法中的迭代方式进行细化。而PID控制能够“稳定、快速、准确”地逼近目标值,在控制误差方面有着十分优良的特性,所以我们将Sarsa算法中Q值的迭代更新方式改进为三项之和,分别对应PID控制中的比例、积分和微分,体现了对当前、过去和未来的误差进行控制的思想。
用误差的比例部分来控制当前误差的变化,比例系数越大,消除能力也就越强。但由于系统存在惯性,比例作用太强不仅不能完全消除误差,还会导致系统的不稳定。由于比例部分不能完全消除误差,总是存在静态误差,所以对过去的误差进行积分直至误差为零,达到无差调节的效果。
误差关于时间的微分体现变化趋势,比例和积分部分都是对当前及过去产生的误差进行调节消除,而微分部分则关注误差产生的趋势,通过调节微分系数,对误差进行超前调节,以达到预防控制的效果。由于微分控制的及时性,可以最大程度地减少动态误差。但微分作用太强也会导致系统的不稳定。
基于PID控制对误差更新调节,本文提出Pid_Sarsa算法。在Sarsa算法中,将时序差分误差作为实际值与目标值之间的偏差
,引入比例、积分、微分部分,来控制误差的大小和变化趋势,其中自然地将比例系数
取为步长
的值,令
,
分别为积分、微分系数,得到以下对动作价值函数的更新方式:
(10)
基于PID控制更新的Pid_Sarsa算法流程如下 [17] [18]:
1) 初始化状态
;
2) 用
-greedy策略选择动作
;
3) 采取动作a得到下一个状态
和奖励
;
4) 用
-greedy策略根据
求得动作
,得偏差
5)
6)
;
7) 直到到达终止状态(到达目标状态或者掉入悬崖)。
4. 实验及结果分析
4.1. 实验环境
路径规划下的悬崖寻路(Cliff Walking)是强化学习的经典环境,属于一种特殊的网格世界游戏。
在这个游戏环境中,每一个网格是一个状态。如图3所示,起点在网格左下角,目标在右下角,其中网格世界底部有一段悬崖。智能体到达目标状态或掉入悬崖都会结束并回到起点,即目标状态和悬崖都称为终止状态。
智能体在每一个状态都可以采取上下左右4种动作。如果采取动作后触碰到网格边界则状态不发生改变,否则就会相应到达下一个状态。每走一步或者掉入悬崖,智能体都会获得相应的奖励值。目标是找到一条避开悬崖到达目标位置的最短路径,使得预期得到的奖励值最大。
为了便于说明,如图3所示建立坐标系,并将悬崖寻路游戏抽象成数学模型进行描述。
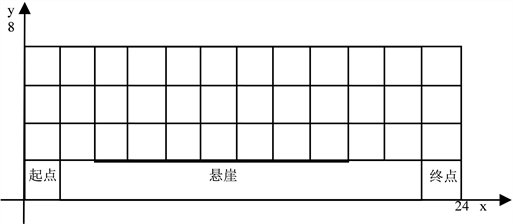
Figure 3. Schematic of cliff walking environment
图3. 悬崖寻路环境示意图
游戏环境由4 × 12的网格组成,每个网格的长度与宽度都是2个单位。状态空间
表示如(11)式。
(11)
(12)
(13)
(14)
类似(11)式,(12)式、(13)式、(14)式分别表示悬崖寻路环境的起点状态、目标状态及悬崖。动作空间
表示如(15)式。
(15)
其中
为一个分段函数,对应上下左右四个动作。设奖励值为
,每走一步的奖励
,掉入悬崖的奖励
。
为了定量地刻画实验结果的安全性,本文引入了三个相关的定义:1) 在y轴方向上,路线里每个状态中yt距离悬崖的长度称为安全距离;2) 将路径所占的网格数量,即状态个数,称为路径长度;3) 将安全距离与最安全距离值的比值称为安全程度。可知最安全路径是指最远离悬崖的路线,安全距离为84;最优路径是指不掉入悬崖的最近路线,安全距离为24,也最为冒险。
在强化学习环境基础上,可知上述游戏为一个马尔可夫决策过程,且该状态空间和动作空间都是有限且离散的。已知当前状态
和动作
,到达下一个状态
的转移概率为
,而由此得到的奖励
也是随机变量。智能体的目标是找到一条避开悬崖到达目标位置的最短路径,即寻找一个策略
,使得预期得到的奖励值最大。
4.2. 实验结果与分析
由于PID控制的积分部分是为了消除静差,且是根据系统环境进行具体调节的,而在悬崖寻路的实验环境下,积分部分会使得系统大幅度振荡且掉入悬崖,所以在实验过程中,本文根据实际情况采用PD控制,PD型学习律的迭代控制结果也是收敛的 [19] [20]。设置积分部分的系数
,再此基础上调节比例系数
和微分系数
的大小。
在悬崖寻路的环境下,首先采用强化学习中经典Sarsa算法和n步Sarsa算法(取n = 5)求在多次实验下智能体通过悬崖的累计回报Returns,如图4、图5所示。
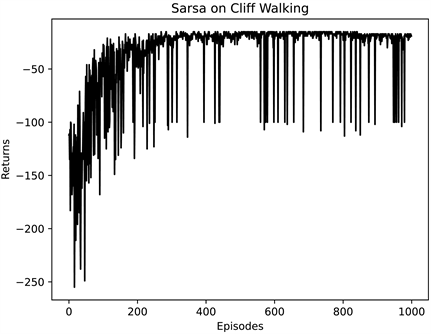
Figure 4. Cliff walking experiment based on Sarsa algorithm
图4. 基于Sarsa算法的悬崖寻路实验
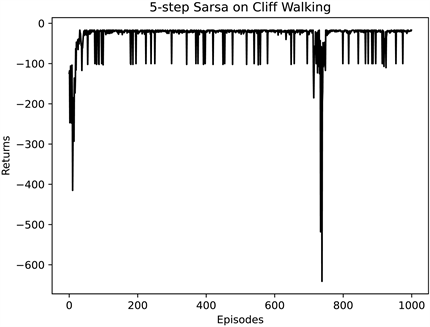
Figure 5. Cliff walking experiment based on 5_Sarsa algorithm
图5. 基于5步Sarsa算法的悬崖寻路实验
由图4和图5可知,经过1000次实验,智能体的累积回报都不断提高,最终收敛在−20左右。但两种经典算法相比,在初始状态,5步Sarsa算法比Sarsa算法的累计回报较低,但收敛速度比Sarsa算法更快。
再采用基于PID控制更新的Pid_Sarsa算法进行实验,调整参数
,得到结果,如图6。
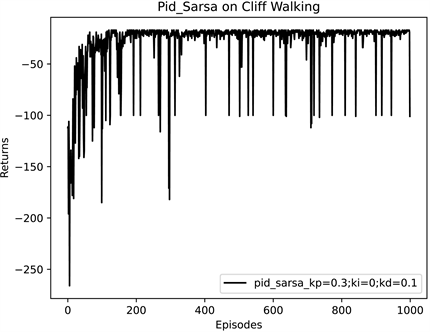
Figure 6. Cliff walking experiment based on Pid_Sarsa algorithm
图6. 基于Pid_Sarsa算法的悬崖寻路实验
从图6可以看出,在悬崖寻路实验中,Pid_Sarsa算法也能使累计回报收敛至−20左右。为了避免一些偶然因素对实验结果产生影响,纵坐标改用累计回报的滑动平均值,将三种算法进行比较,如图7、图8所示。
从图7可知,Pid_Sarsa算法与Sarsa算法相比更快收敛。而从图8中可以看出,5步Sarsa算法虽然收敛速度更快,但前50幕的累计回报更低,且在700幕左右出现十分小的累计回报,波动较大,所以Pid_Sarsa算法与其相比更加稳定。
根据经典的Sarsa和5步Sarsa,以及本文提出的基于PID控制的Pid_Sarsa三种算法,在游戏环境中得到相应的路径图,如图9所示。
从图9可知,三种算法得到的最优路径都是远离悬崖一侧,较为安全保守。在路径长度相同的情况下,Sarsa算法得到的结果在路线的开头会接近悬崖,而5步Sarsa算法在路线末端靠近悬崖,都存在一定的风险。

Figure 7. Comparison of Sarsa algorithm and Pid_Sarsa algorithm in cliff walking experiment
图7. 悬崖寻路实验中Sarsa与Pid_Sarsa算法对比
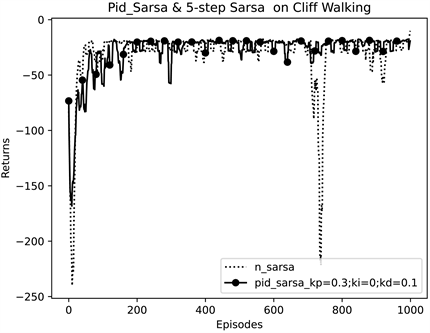
Figure 8. Comparison of 5_Sarsa algorithm and Pid_Sarsa algorithm in cliff walking experiment
图8. 悬崖寻路实验中5步Sarsa与Pid_Sarsa算法对比

Figure 9. Comparison of Cliff Walking paths of three algorithms
图9. 三种算法的悬崖寻路路径对比图
由于不同的算法会得到不同的路径,根据上文定义的三个安全性度量,分别得到不同路径的安全距离和安全程度,如表1所示。

Table 1. Cliff walking path comparison table of three algorithms
表1. 三种算法的悬崖寻路路径对比表
由表1可知,不同于其它两种经典算法,在路径长度相同的前提下,基于PID控制的Pid_Sarsa算法不仅收敛速度更快更稳,而且从路径的安全系数考量,得到的结果也是最为安全的,安全程度比Sarsa算法高2.38%,比5步Sarsa算法高4.76%。
5. 结语
本文在基于经典强化学习Sarsa算法,提出用PID控制对算法进行优化。根据悬崖寻路的系统环境,在对Q值的迭代更新过程中,引入PID控制中的比例部分和微分部分,通过对比例系数Kp和微分系数Kd的参数调优,将优化过后的Pid_Sarsa算法与经典的Sarsa算法和多步Sarsa算法分别进行比较。实验结果表明,在路径长度相同的前提下,经PID优化的Pid_Sarsa算法,收敛速度更快,并且也更加稳定,得到的悬崖寻路的路径也更加安全。适用于风险较大、安全性较高的路径规划问题,如车辆驾驶、灾难避险等。但在不同的环境中,算法涉及到PID控制系统的参数整定,会更加复杂,将更具针对性,也是接下来相关研究的重点。
基金项目
武汉科技大学教学研究项目(Yjg202116)。
NOTES
*通讯作者。