1. 引言
目标检测是目前计算机视觉和数字图像处理领域的一个重要研究方向,在目标检测的实际应用场景中,室内人数统计一直以来都是一个具有挑战性的问题。像教室、商超、银行及候车室等地方,都需要进行人数的统计,这些场所往往人数较多,位置分散,且监控画面往往是俯拍角度,所以视频中的人像较小的同时也存在相互遮挡问题,因此如何有效的进行特征提取,提高室内人数统计的准确度不仅具有理论意义,也具有重要的实用价值。
目前基于深度学习 [1] [2] [3] [4] 且应用前景 [5] [6] 比较广泛的目标检测 [7] [8] [9] 算法可以分为两类:1) 两阶段目标检测算法:基于Region Proposal的R-CNN (Region-Convolutional Neural Network) [10] 系列算法,需要先产生目标候选框,卷积神经网络对候选框做分类与回归。常见的算法有Fast R-CNN [11] 、SPP-Net [12] 、Corner-Net [13] 、Faster R-CNN [14] 、Mask R-CNN [15] 等。2) 一阶段目标检测算法:不需要产生候选框,仅使用卷积神经网络直接将目标框定位问题转化为回归问题,预测不同目标的类别与位置。常见的算法有YOLO (You Only Look Once)系列 [16] [17] [18] 、SSD (Single Shot MultiBox Detector) [19] 等。基于候选框的两阶段方法,经过两次分类和位置回归,在检测准确率和定位精度上占优。由于存在选框和检测两个阶段,会比一阶段算法效率低,而室内人数统计往往需要满足实时性,因此一阶段目标检测算法更适合用来进行人数统计。
近年来,用目标检测进行人数统计的研究取得了一定的突破,陈晓 [20] 等人针对目标检测中的误检漏检问题,提出了一种基于视频的人数统计方法,通过对特征提取、损失函数以及后处理阶段的改进,使得检测准确率以及召回率有一定提高,且处理速度较快。成玉荣 [21] 等人为了统计当前监控环境下的人数,引入了通道注意力机制,改进了Tiny-YOLOv3算法,训练人体头部的目标检测模型,实验的平均检测精度高达80%。郑国书 [22] 等人基于SSD模型,提出了一种基于人头检测的视频室内人数统计方法,该算法可以对小尺度人头进行检测,准确度高,实时性好,但由于SSD模型使用低级特征检测小目标,特征提取不够充分。
基于YOLO V3检测算法,本文提出了一种改进的YOLO V3室内人数统计模型,并应用于教室人数识别统计中。在自建室内人群检测数据集中训练新模型,结果表明改进后的YOLO V3算法能更好的提取特征,测试的召回率和平均精确度有明显提升。本文的主要贡献如下:
1) 自建数据集包括动态视频数据和静态图片数据,且利用对比度增强、亮度增强等方法增加数据量,提高了训练数据的多样性;
2) K-means算法重新聚类锚框;
3) 提出了F-YOLO V3模型,其中改进了YOLO V3特征提取网络以及多尺寸检测算法。改进点包括:利用低层特征图包含更多特征细节的特点,增加104 × 104尺寸的特征图输出,进行类别判断与边框预测;为提高网络对小目标的召回率和检测准确度,取消了13 × 13尺寸特征图的输出;用上采样小特征图后与大特征图拼接的方式融合不同粒度的特征图,进而从小目标中得到更细粒度的特征以及位置信息;将输出层前的5个卷积变成了1个卷积和2个残差单元,以此减少人头小目标在复杂场景的漏检率,提高网络对小目标的检测率;
4) 增加一个ADIOU (Area Distance) loss分支,增强检测框定位准确度。
2. 相关知识
2.1. YOLO V3模型
YOLO V3算法以YOLO V1和YOLO V2算法为基础。YOLO V2借鉴了R-CNN的思路,引入了锚框(anchor),并通过聚类进行选取,增加了细粒度特征,将浅层特征图连接到深层特征图,网络修改为全卷积网络,YOLO V3进一步加入了特征金字塔网络的思想,利用多尺度特征进行对象检测,在保持速度优势的前提下,提升预测精度,尤其是加强了对小目标的识别能力。
在基本的图像特征提取方面,YOLO V3采用了称之为Darknet-53的网络结构,共包含53层卷积层,Darknet-53由5个残差模块构成,每个残差模块由多个残差单元 [23] 组成。每个残差单元由两个CBL单元和一个快捷链路构成,其中CBL单元包含卷积层、Batch Normalization层和Leaky Relu (Rectified Linear Unit) [24] 激活函数,这样有利于解决深层次网络的梯度问题。YOLO V3网络结构如图1所示。
2.2. YOLO V3损失函数
YOLO V3的损失函数由四项组成,分别是预测框的中心点坐标损失、预测框的宽高损失、置信度损失和类别损失,其损失函数计算式见式(1)。
(1)
其中:
是预测框的中心点坐标损失,其详细公式如式(2):
(2)
、
分别是预测第i个网格的第j个锚框的中心点坐标,与之对应的真实值为
、
。
为权重系数,
表示为分段函数:当第i个网络的第j个锚框包含检测目标对象的归一化值时
,否则
。
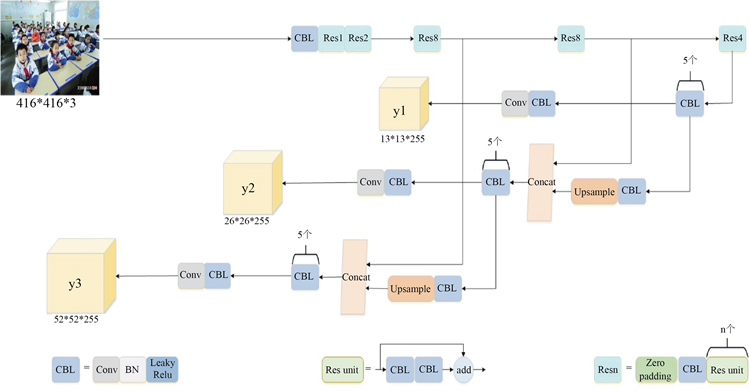
Figure 1. YOLO V3 network structure
图1. YOLO V3网络结构
是预测框的宽高损失,其详细公式如式(3):
(3)
、
分别是预测第i个网格的第j个锚框的宽高,与之对应的真实值为
、
。
为置信度损失,包括有目标和无目标两种情况,其详细公式如式(4):
(4)
为类别损失,其详细公式如式(5):
(5)
3. 基于F-YOLO V3模型的人数统计方法
本节首先自建并丰富数据集,提高训练数据的多样性,并通过K-means算法重新聚类锚框;然后进行YOLO V3特征提取网络以及多尺寸检测算法的改进,提出了F-YOLO V3模型;为了衡量检测框定位准确度,增加一个ADIOU Loss分支。
3.1. 自建室内人群检测数据集
由于多数情况检测对象人头目标较小,分辨率和信息有限,使得基于深度学习的目标检测算法在常规目标检测数据集上的检测效果并不理想,需要专门针对该检测对象特征的数据库,完成训练和检测任务。因此,本文首先利用动态数据集和静态数据集相结合自建室内人群检测数据集,并且利用对比度增强、亮度增强等方法进行了数据增强,丰富了数据集,提高了训练数据的多样性。
静态数据集是利用Python网络爬虫技术在必应、百度上面爬取室内场景人群的图片,部分图片如图2所示。动态数据集采集于北京建筑大学不同教室不同时间的监控视频,视频大小共20G,格式为MKV,本实验将视频以8秒一帧的标准输出成相应的图像序列,部分图片如图3所示。
为丰富数据集,对静态数据集和动态数据集所获得的图片进行数据增强,如对比度增强、亮度增强等,并经过人工筛选得到符合要求的图片组成数据集,最终数据集含有1000张图像,只有1个类别person,然后采用开源的Labelimage软件对采集到的1000张图像中的人头进行标注,得到1000个对应的xml文件,作为室内人群检测的数据集标签。

Figure 2. Several images on the static dataset
图2. 静态数据集的部分图片

Figure 3. Several images on the dynamic dataset
图3. 动态数据集的部分图片
3.2. 聚类候选锚框
锚框是从训练集真实框(ground truth)中统计或聚类得到的几个不同尺寸的框。避免模型在训练时的盲目性,有助于模型快速收敛。设每个网格对应k个anchor,也就是模型在训练时,只会在每一个网格附近找出这k种形状。anchor是对预测的对象范围进行约束,并加入了尺寸先验经验,从而实现多尺度学习目的。
YOLO V3网络在常规目标数据集COCO上通过边框聚类预设了9个共3类锚框,预设的锚框检测的目标尺寸差距很大,对于普通常规数据集有较好的适应性。但对于一些小目标数据集或者大小尺寸较平均的数据集来说,继续使用这个预设尺寸不利于目标框的收敛,严重影响检测性能。
本实验利用K-means算法对自建人群检测数据集所有样本真实框(ground truth)的宽高进行聚类,得到先验框大小,关于锚框数量,原网络输出3个尺寸的特征图,所以取了9个锚框,由于改进的算法多输出了104 × 104尺寸的特征图,当k取12时,在自建人群检测数据集中聚类得到这12个先验框的尺寸分别是:(11 × 20),(19 × 32),(25 × 52),(37 × 89),(43 × 56),(58 × 106),(68 × 106),(89 × 125),(108 × 187),(110 × 295),(166 × 230),(213 × 339)。最后为了提高网络对小目标的召回率和检测的准确度,取消了13 × 13尺寸特征图的输出,因此我们将13 × 13尺寸特征图所对应的3个先验框去掉,最终的9个先验框尺寸分别是: (11 × 20),(19 × 32),(25 × 52),(37 × 89),(43 × 56),(58 × 106),(68 × 106),(89 × 125),(108 × 187)。
3.3. 改进特征提取网络与多尺度预测的F-YOLO V3模型
为了使网络能够获取更多特征信息,增强对模糊或者较小目标检测能力,本文改进了YOLO V3算法的特征提取网络与多尺度检测网络,使其充分学习浅层特征,改进的F-YOLO V3网络结构如图4所示。
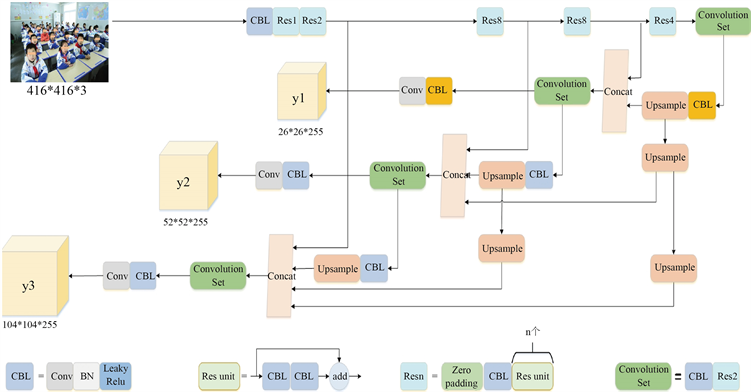
Figure 4. F-YOLO V3 network structure
图4. F-YOLO V3网络结构
首先利用低层特征图包含更多特征细节的特点,将原网络输出的8倍降采样52 × 52的特征图进行上采样,再将得到的结果与Darknet-53中第2个残差块输出的4倍降采样特征图进行拼接,得到104 × 104尺寸特征图的输出,可以提取更多的特征信息,提高模糊或者较小目标的检测精度。同时为了提高网络对小目标的召回率和检测准确度,取消了13 × 13尺寸特征图输出,最终输出26 × 26、52 × 52、104 × 104三种尺寸的特征图。
然后将原网络上采样后的26 × 26尺寸特征图再进行2倍上采样和4倍上采样,得到52 × 52和104 × 104的特征图与原网络的52 × 52和104 × 104的特征图进行拼接,同样将原网络上采样后的52 × 52尺寸特征图再进行2倍上采样,得到104 × 104的特征图与原网络的104 × 104的特征图进行拼接,这样可以从小目标中得到更细粒度的特征以及位置信息,从而增加目标识别与其位置的准确率。
最后为了增强特征的充分提取,将输出层前的5个卷积变成了1个卷积和2个残差单元,以此减少人头小目标在复杂场景的漏检率,提高网络对小目标的检测率。
3.4. ADIOU Loss
在YOLO V3中,smooth L1 Loss来对检测框的位置做回归,当使用这个Loss来做损失函数时,是通过4个点回归坐标框的方式,独立的求出4个点的Loss,然后进行相加得到最终的Bounding Box Loss,这种做法的假设是4个点是相互独立的,实际是有一定相关性的,实际评价框检测的指标是使用IOU,这两者是不等价的,多个检测框可能有相同大小的smooth L1 Loss,但IOU可能差异很大,为了解决这个问题就引入了IOU Loss。
但IOU只是面积比值,当两个框不存在交集时,IOU为0,这时网络无法判断两个框之间距离远近,并且从面积比值中无法知道两框的重叠状态,因此本文中增加了一个ADIOU Loss分支对预测框和真实框的位置x、y、w、h进行计算,ADIOU增加了一个基于真实框未重叠部分面积的惩罚项;并且针对IOU相同但两框相交情况多样的问题,增加了一个基于中心点距离的惩罚项,通过最小化两个框中心的距离来使预测框定位更加准确。
两框之间的重叠度IOU定义为:
(6)
IOU Loss定义为:
(7)
而ADIOU的定义为:
(8)
为ADIOU Loss,其详细公式如式(9):
(9)
其中B表示预测框的位置信息,G表示真实框的位置信息,C表示包含B和G的最小矩形框,b为预测框B的中心点,
为真实框G的中心点,
为欧氏距离,d为预测框与真实框重叠部分对角线长度。
因此,F-YOLO V3模型的总损失函数为:
(10)
4. 实验设计
本节将进行三组实验来验证改进的效果,1)将所提的F-YOLO V3模型与传统YOLO V3模型、鞠 [25] 改进的YOLO V3模型以及YOLO V5模型在自建人群检测数据集上进行对比实验;2)消融实验,证明每个改进部分有利于模型的提升;3)将所提的F-YOLO V3模型与传统YOLO V3模型、成玉荣 [21] 等人对Tiny-YOLO V3改进得到的模型在SCUT-HEAD数据集的测试集上进行检测性能的对比。
4.1. 评价指标
本节主要采用主流的目标检测模型的评价指标精确率Precision、目标召回率Recall和平均精度AP。精确率Precision一般指模型检测出来的目标有多大比例是真正的目标物体,定义如式(11)所示。
(11)
召回率Recall指所有真实的目标有多大比例被我们的模型检测出来了,定义如式(12)所示。
(12)
本文以室内人群检测为例,TP为正确检测出来的人数,FP为被错误检出的人数,FN为没有被检测出来的人数。
以Recall为横坐标,Precision为纵坐标,绘制P-R曲线,AP就是对PR曲线上的Precision值求均值,对于PR曲线可用积分求AP的值,定义如式(13)所示,AP@0.5指将IOU阈值设为0.5;mAP是AP的平均值,c表示类别数,定义如式(14)所示,mAP用来衡量模型好坏,值越大说明模型识别的越好,本文只有一个类别person,因此AP就等同于mAP。
(13)
(14)
(15)
(16)
4.2. 数据集
本文使用了自建室内人群检测数据集以及SCUT-HEAD和Brainwash两个公开的数据集,下面我们从数据集大小和数据特点等方面分别介绍这3个数据集。
自建室内人群检测数据集来源于视频提取和网络爬虫两部分,最终数据集含有1000张图像,然后采用开源的Labelimage软件对采集到的1000张图像中的人头进行标注,得到了VOC格式的xml文件,作为室内人群检测数据集标签,以9:1的比例将数据集标签分为训练样本和测试样本。
SCUT-HEAD是一个大规模的头部检测数据集,数据集由两部分组成。Part A包括2000个图像,采样自大学教室的监控视频,67321个注释。Part B包括2405张从互联网上抓取的图片和43930个头部注释。我们用xmin,ymin,xmax和ymax坐标标记每个可见的头部,并确保注释覆盖整个头部,包括被阻塞的部分,但没有额外的背景。我们将Part A按照9:1的比例分为训练和测试两部分。SCUT-HEAD数据集遵循Pascal VOC标准。
Brainwash数据集是一个密集人头检测数据集,拍摄的是在一个咖啡馆里出现的人群,包含三个部分,训练集约有6500张图像,测试约有900张图像。
4.3. 实验环境和训练参数
实验条件:所有实验是基于Pytorch和Python实现的,深度学习框架为Darknet 53,配置Intel Core i7处理器,内存为32GB,GPU为NVIDIA Quadro M1200,4G显存,16G内存。
训练参数设置为:1) 训练迭代次数epoch设置为100;2) 每次迭代训练的图像数目batch_size设置为2;3) 将batch_size进行分组后送入网络的subdivision设置为1;4) 网络输入尺寸为416 × 416;5) 学习率为0.001;6) 降低参数率ratio为0.25。
5. 实验与结果
5.1. F-YOLO V3模型性能测试及对比实验
在自建人群检测数据集上,硬件平台为NVIDIA Quadro M1200,将提出的F-YOLO V3模型与传统YOLO V3模型、YOLO V5模型以及复现鞠 [25] 等人提出的改进的YOLO V3模型进行对比实验,实验结果如下表1所示。

Table 1. Performance comparison of different algorithms
表1. 不同算法性能对比
结合表1对比不同算法在自建人群检测数据集上的检测精度可以看出F-YOLO V3模型相较于传统YOLO V3模型在AP指标上提高了约22.7%,虽然P值有所降低,但是R值有很大的提升,因此漏警率降低了许多。从下面识别检测效果图5中就能看出漏检显著减少;相较于YOLO V5模型提高了约13.3%,相较于我们复现的鞠 [25] 等人提出的改进的YOLO V3模型提高了3.58%,为了进一步体现F-YOLO V3模型在精度上的提升,绘制精度趋势图如图5。
从识别测试效果图6中可以看出,YOLO V3模型和YOLO V5模型的都存在一些误检和漏检问题,比如将包检测成人的情况,我们复现的鞠 [25] 等人提出改进的YOLO V3模型存在严重的漏检问题,而F-YOLO V3模型可以检测出其他三种算法没有检测出来的目标,并且框的定位准确度提高了很多,对于误检漏检的情况也有显著改善。
5.2. F-YOLO V3模型的效能评估和分析
本实验将改进的地方分为A、B、C三个部分,Part A为增加一个ADIOU (Area Distance) loss分支;Part B为将原网络输出的8倍降采样52 × 52的特征图继续进行上采样,与更低层的104 × 104尺寸特征图拼接,增加104 × 104尺寸的特征图输出,同时取消13 × 13尺寸特征图的输出,并且将输出层前的5个卷积变成了1个卷积和2个残差单元;Part C为将原网络上采样后的26 × 26尺寸特征图再进行2倍上采样和4倍上采样,得到52 × 52和104 × 104的特征图与原网络的52 × 52和104 × 104的特征图进行拼接,同样将原网络上采样后的52 × 52尺寸特征图再进行2倍上采样,得到104 × 104的特征图与原网络的104 × 104的特征图进行拼接。
将这三部分在自建人脸检测数据集的训练集上进行训练,并在测试集上对模型进行评估,对比原YOLO V3的模型性能,来证明改进的每一部分对于模型的提升效果,实验结果如图6和表2所示。
 (a) YOLO V3模型
(a) YOLO V3模型  (b) YOLO V5模型
(b) YOLO V5模型  (c) [25] 中的YOLO V3模型
(c) [25] 中的YOLO V3模型  (d) F-YOLO V3模型
(d) F-YOLO V3模型
Figure 6. Recognition test results
图6. 识别测试效果图
Table 2. Detection performance under different thresholds
表2. 不同阈值下的检测性能
图7显示了四种模型在训练第50个和第100个epoch时训练模型在测试集上返回的mAP值,其中测试集上的IOU阈值设为0.5,可以明显看出每一部分的加入都使精度有了一定的提升。表2是训练完100个epochs后不同阈值下的测试结果,P值虽然有所降低,但是R值可以看出是在持续增长的,证明我们想要减少漏警率的目的达到了,图8是将表2数据绘制成了簇状条形图,最终的AP值可以明显看出改进的每一部分都对模型有一定的提升效果。

Figure 7. When the four models train the 50th and 100th epoch, they train the map value returned by the model on the test set
图7. 四种模型在训练第50个和第100个epoch时训练模型在测试集上返回的map值
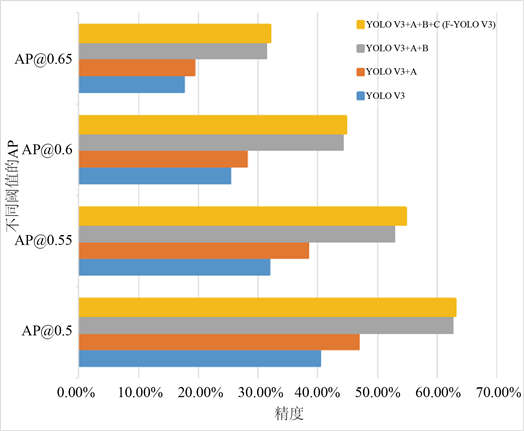
Figure 8. Detection performance under different thresholds
图8. 模型在不同阈值下的精度
5.3. 在公开数据集上F-YOLO V3模型的性能评估
将F-YOLO V3模型与传统YOLO V3模型、成玉荣 [21] 等人对Tiny-YOLOv3改进得到的模型在SCUT-HEAD公开人脸数据集的测试集上进行对比,结果列于表3中。
从表3可知,F-YOLO V3模型比传统YOLO V3模型平均精度提升了19.8%,相较于成玉荣 [21] 等人对Tiny-YOLOv3改进得到的模型平均精度提升了1.27%。
在Brainwash数据集上,硬件平台为NVIDIA GeForce RTX 2080Ti,将F-YOLO V3模型与传统YOLO V3模型、我们复现的鞠 [25] 等人提出的改进的YOLO V3模型在Brainwash数据集的测试集上进行对比,结果列于表4中。
Table 3. Experimental results on SCUT-HEAD public face dataset
表3. SCUT-HEAD公开人脸数据集上的实验结果
Table 4. Experimental results on Brainwash dataset
表4. Brainwash数据集上的实验结果
从表4可知,F-YOLO V3模型比传统YOLO V3模型平均精度提升了7.87%,相较于我们复现的鞠 [25] 等人提出的改进的YOLO V3模型平均精度提升了2.32%。
从以上两个实验结果可以得出F-YOLO V3模型在公共数据集的检测效果也令人满意,进一步说明F-YOLO V3模型的有效性。
6. 结论
本文基于改进的YOLO V3算法来进行人数统计。首先,利用动态数据集和静态数据集相结合自建数据集,并对部分数据集进行了数据增强;通过K-means算法重新聚类锚框;然后进行了YOLO V3特征提取网络以及多尺寸检测算法的改进,提出了F-YOLO V3模型,以提取更多特征信息,增强对模糊或者较小目标检测能力;最后为了衡量检测框定位准确度,增加一个ADIOU Loss分支,最后根据识别出来的人进行统计,输出画面中的实时人数。实验证明,改进后的YOLO V3算法在进行室内人数统计时,漏检率和误检率都大大降低,检测准确率有明显提升。
但是,改进后的模型在训练速度、网络结构的复杂度方面还有一定的缺陷,下一步将针对这些缺陷做进一步研究。
基金项目
北京建筑大学科学研究基金(KYJJ2017017, Y19-19, Y18-11);住房和城乡建设部科学技术计划北京建筑大学北京未来城市设计高精尖创新中心开放课题(No. UDC2019033324, UDC201703332);北京市教育委员会科学研究计划项目资助(KM202110016001, KM202210016002)。
参考文献
NOTES
*通讯作者。