1. 引言
COVID-19的传染性极强,尽早检测出被感染患者是阻断疫情传播的重要手段。临床中,CT的表现是判断患者是否感染和病情发展的一个重要依据,因此从CT图像中分割患者病变区域对提高医生的诊断效率有着重大意义。
由于COVID-19患者肺部感染区域在CT影像中的形状尺寸、位置等因素多样性,患者的感染区域分割比较复杂。相比于传统的图像分割算法,深度学习算法有更好的分割精度。卷积神经网络(Convolutional Neural Network, CNN) [1] 的提出,解决了图像特征提取的难题;Long等在2015年提出将传统CNN中的全连接层换为一个个卷积层,得到了一种全卷积神经网络(Fully Convolutional Network, FCN) [2],解决了语义级别的图像分割问题;Ronneberger等提出基于编码器–解码器结构的U-Net [3] 网络模型,可以在样本量较少的情况下得到较好的分割结果;在U-Net模型提出的基础上,越来越多的研究者对U-Net网络进行改进优化,Zhou等提出U-Net++ [4] 模型,通过改进编码器和解码器之间跳跃连接过程中两者之间的细粒度优化网络模型;Oktay等人在U-Net解码器部分使用注意力机制,提出Attention-Unet [5],使分割模型的注意力集中在感兴趣的区域,并在胰腺的分割中取得了很好的分割效果;Sheng Lian等将Residual learning引入U-Net,提出Res-Unet [6] 并在视网膜血管的分割中成功应用;闫文杰 [7] 提出基于U-Net模型和空洞卷积(Dilated Convolutions, DC)的图像分割算法,并在网络中添加了卷积层来融合更多层的特征信息,空洞卷积可以保证参数不增加的同时,加大了卷积核感受野;朱海鹏 [8] 提出一种新的基于U-Net的改进型深度学习网络,称为Attention Gate-Dense Network-Improved Dilation Convolution-UNET网络(ADID-UNET),用于分割CT扫描图像的病变区域。Kalene等 [9] 人使用U-Net,并结合DCNN,InceptionV3和ACNN等预训练模型对胸部CT图像进行训练测试,以检测感染区域并且取得了不错的分割效果;宋瑶等 [10] 人提出改进的U-Net网络,该网络对于新冠肺炎病变区域分割性能良好。
虽然目前已有一些深度学习方法用于分割病变区域诊断新冠肺炎,但在新冠肺炎CT切片中分割病变区域的相关研究仍然不是很多。且只使用U-Net网络对其训练,存在网络性能退化、图像空间特征利用率低等问题,使得分割准确率偏低。本文将Resnet网络和注意力机制的优点相结合改进U-Net网络同时结合迁移学习思想,提高了U-Net网络的分割效果。
2. 深度学习图像分割算法
随着深度学习技术的发展,基于深度学习的医疗影像分割技术在不断完善。和传统的图像分割算法比较,深度学习算法对图像的特征提取程度更深,有更好的分割精度,且不需要大量人工分析和调参。用深度学习算法替代传统的图像分割算法能得到更好的分割结果。
2.1. 深度学习分割算法流程
本文使用深度学习技术对新冠肺炎患者的CT图像中病变区域进行分割,整体的分割算法流程如图1所示。
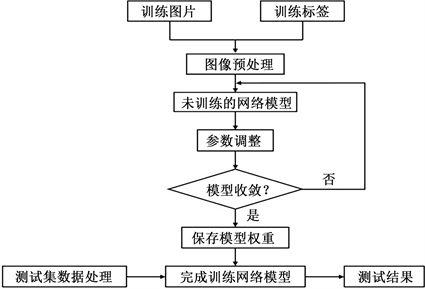
Figure 1. Deep learning image segmentation algorithm process
图1. 深度学习图像分割算法流程
由图1知,一般情况下利用深度学习技术对图像进行分割要先得到训练图片对应的图像标签,图像标签是由医生对原始图像进行标注,即手动分割出病变区域。训练图片及其对应标签构成训练集,将训练集输入网络中不断迭代运算,让网络学习标签数据中的特征,并在每一次迭代后对网络的参数进行更新调整直至模型收敛得到完成训练的模型,即模型已经无法在从标签中学习到更多特征了,此时的模型分割能力较好,损失率最低。测试集用于对模型性能的验证,也包括原图和对应的标签,标签用于定量计算模型的分割性能评价指标,得到的测试结果为评价模型性能的最终结果。
2.2. 肺炎CT图像分割算法构建
2.2.1. 编码器–解码器结构
在图像语义分割领域,编码–解码器结构是最常用的。本文也是采用这种能够端到端分割整个图片的结构,以经典的U-Net网络模型的U型结构为基本框架,编码器部分实质为下采样,将原始的输入图像逐层下采样得到分辨率很低的特征图,解码器实质为上采样,将编码器中的特征图逐层上采样恢复到较高分辨率并进行逐像素预测最终输出得到预测结果。
2.2.2. 编码模块
在深度学习图像分割任务中,一定范围内网络深度越深,网络性能越好。但随着网络深度增大,网络在训练过程中会出现深度退化问题,表现为模型训练难以收敛,模型的梯度消失或爆炸进而模型的分割性能严重下降。随着残差网络(Resnet) [11] [12] [13] 的出现,残差网络相比于普通网络不容易出现深度退化问题。为避免U-Net网络在训练过程中出现这些问题,本文用残差网络Resnet34替换原始的编码器。Resnet34由残差单元连接而成,残差单元如图2所示,公式为:
(1)
Resnet34网络共分为五个层(Layer 0~4),每一层的卷积层的卷积核大小和个数具体构成如表1所示。

Table 1. Resnet34 is constructed in detail layer by layer
表1. Resnet34逐层详细构成
2.2.3. 解码模块
在解码部分,图像尺寸在恢复过程中,保留原始U-Net的上采样和跳层连接结构。跳层连接是将下采样过程中的特征图拼接到对称的上采样层后再进行上采样,目的是用来补充采样过程中丢失的空间特征信息。原始的U-Net是直接将特征图裁剪后拼接过来,会带来许多与需要分割的区域无关的背景特征信息,使最终分割结果准确性较低。注意力机制(Attention Gate, AG)能极大地提高分割精度且已经在实验中得到验证,在解码过程中通过引入AG系统来抑制特征图中的无关紧要的背景信息,帮助模型更多关注目区域,减少分割的错误率,增加模型的灵敏度和预测准确性。AG的结构如图3所示。
其中,
和
分别为上采样和下采样过程中第
层的特征图,
是经过上一层上采样后的,所以两者尺寸一样,分别经过一个
的卷积后点对点叠加,公式如下:

Figure 3. Attention Gate structure diagram
图3. Attention Gate结构图
(2)
A经过Relu激活函数和另一个
的卷积
后得到单通道的B,
(3)
最后,经过一个Sigmoid函数得到注意力系数
,范围为0到1,即为每个像素点的权重。
(4)
为经过注意力机制后输出的特征图,保留了感兴趣区域信息,由注意力系数与原下采样特征图相乘得到。
(5)
2.3. 网络结构
本文算法是基于U-Net改进的,保留了U-Net端对端的原始结构,在编码器和解码器部分都做了相应的改进,提高模型的分割性能。网络具体结构如图4所示。

Figure 4. Diagram of the network structure
图4. 网络结构图
该网络的编码模块由Resnet34构成,利用迁移学习,Resnet34的初始权重为在ImageNet [14] 上预训练过的权重。初始输入图片尺寸为256 × 256,通道数为3,经过卷积层Conv_1,即为Resnet的Layer 0层,输出特征图尺寸为128 × 128,通道数为64,此后经过Resnet34的Layer 1~4层逐层下采样,每下采样一层,特征图的尺寸减半,通道数变为原来两倍。图中残差连接有两种,实现箭头为常规残差连接,每残差单元的输出和输入的通道数一样,可直接叠加,虚线箭头为升维残差连接,由于两层之间卷积核数量不同,每层的初始残差单元输入和输出通道数不同,输出是输入的两倍,进行残差连接时需要对输入用1 × 1的卷积进行升维,使两者通道数一致方可进行叠加;解码模块由4组上采样层和卷积层组成,与编码模块相对应,在每层编码模块和解码模块之间是带有AG模块的跳层连接,图像随着逐层上采样,尺寸逐层恢复,通道数也逐层减小,每层尺寸大小和通道数均与对应的编码模块层相同,方便跳层连接时两者的叠加。为了得到最后的分割结果与输入图片尺寸一致,最后的输出层再进行一次上采样和一次1 × 1的卷积,使图片尺寸恢复为与原图一致,通道数降为1,最终得到尺寸为256 × 256的单通道分割结果。
3. 实验及结果分析
3.1. 实验数据集
本文采用的COVID-19CT图像分割数据集 [15],其中包含20例患者的CT数据,共有1000多个切片和对应的分割标签,分割标签中感染区域的标注由专业的放射科医生完成和验证。由于同一患者的不同图层的CT切片之间具有相似性,最终选出224张切片用于训练,10张切片用于测试。
3.2. 实验内容
本实验是基于Pytorch框架实现的,数据集拆分为224张作为训练集和验证集,比例为9:1,另外10张设置为测试集。按照2.1中深度学习分割算法流程完成对模型的训练和测试。训练过程中,选用二元交叉熵(BCE With Logits Loss)作为网络的损失函数,公式如下:
(6)
其中,
表示每张图片的像素个数,
和
表示预测的像素值和真实值,
表示Sigmoid函数,用来将
值映射到(0, 1)之间。
本文采用Adam优化器优化网络模型,batch size值设置为2,学习率设置为0.0001,模型训练迭代次数设置为200,每轮训练会计算网络的损失函数值,通过反向传播调整参数,损失函数值不断减小最终保持不变,此时模型收敛。保存训练过程中在验证集上分割效果最好的模型参数。
为验证改进的ResAttUnet模型分割性能,本文采用对比实验,将本文算法与原始U-Net、只引入残差卷积的Res-Unet和只有注意力机制的Attention-Unet模型分割性能进行对比。具体实验为设置相同的网络参数,用相同的数据集分别对以上几种网络进行训练和测试,得到实验结果。
3.3. 评估指标
为从多个角度验证本文算法的性能,计算测试集上各个网络分割结果的评估指标并作对比本文采用了准确率(Acc)、精密度(Pc)、敏感性(Sen)、特异性(Sp)和F1评分(F1),计算公式如下。计算这些指标,需要生成混淆矩阵,并定义真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN),如下表2所示。
准确率Accuracy (Acc):表示正确预测的病变像素个数与图片像素总数的比值。计算公式如公式(7);精密度Precision (Pc):正确预测病变占预测病变像素总数的比例计算公式如公式(8);敏感性Sensitivity (Sen):正确预测的病变像素个数与实际病变像素总数的比值,计算公式如公式(9);特异性Specificity (Sp):正确预测的非病变像素个数占实际非病变像素总数比例,计算公式如公式(10);F1评分(F1):综合了精密度率和敏感性结果得出的综合评价指标,F1值越大,网络分割的效果越好,计算公式如公式(11)。
Table 2. Definitions of TP, TN, FP, FN
表2. TP、TN、FP、FN的定义
(7)
(8)
(9)
(10)
(11)
3.4. 实验结果分析
本文针对U-Net网络在COVID-19患者CT图像病变区域分割过程中分割效果不佳的问题,对网络模型进行了相应的改进并成功完成了模型的训练。图5为模型在训练集上的损失曲线。
由图5可以看出,模型在迭代次数达到100左右时,损失函数值基本趋于不变,稳定在0.02左右,代表模型基本收敛。图6为模型训练过程中在验证集上的损失函数曲线,验证集可以真实反应训练后的模型实际。当模型迭代90次后,损失值始终保持在较低水平,基本稳定在0.03左右。说明模型训练完成。
训练好的模型在测试集分割后得到结果,部分视觉效果图如下图7所示。由左向右,各列依次为(a)新冠肺炎患者CT原图、(b) 标签、(c) Unet结果、(d) Res-Unet结果、(e) Attention-Unet结果和(f) ResAttUnet (本文)结果。

Figure 7. Segmentation results for different models
图7. 不同模型的分割结果
从图7中几种模型的分割结果视觉对比图可以看出,几种方法在同样的数据集上均存在一定漏分割和错误分割的现象。图(f)为本文提出的算法在测试集上的分割结果。从图中的视觉对比来看,未改进的网络容易受背景区域影响,错误将背景区域预测为病变区域,病变区域的细节分割也不理想。对比之下,本文改进的算法改善了这些问题,分割更加精确,与专家分割的标签(b)的事实基本相当。
为进一步验证改进的算法分割性能是否提升,定量计算这几种模型在测试集上的评价指标,如表3所示,由表中的数据可以看出,相比于其他模型,本文模型在相同测试集上各项指标均有一定的优势,说明本文算法在新冠肺炎CT图像病变区域的分割中达到较强的分割水平。
Table 3. Quantitative evaluation of segmentation of different models
表3. 不同模型的分割的定量评估指标
4. 总结
通过COVID-19患者CT图像病变区域的分割对患者诊断及治疗和阻断疫情的传播有着重要意义。传统的U-Net虽然能较准确地分割出感染区域,但网络退化、空间特征利用不充分等问题使得U-Net网络的分割性能难以提升。为改善这些问题,本文以U-Net网络的编码–解码结构为框架,用残差网络Resnet34作为编码器,结合注意力机制优点,提出了一种改进的深度卷积网络模型。该模型通过残差网络代替传统卷积网络提高编码器部分的特征提取能力,同时利用注意力机制抑制无关的背景部分来提高模型的分割性能。通过对比实验,本文模型在新冠肺炎病变区域的分割性能有了一定的提升。下一步可以考虑用不同深度的残差网络和性能更好的注意力模块对网络进一步优化。