1. 引言
近年来,随着计算机编程技术和网络通讯技术的不断完善以及进一步发展,在大型项目评估测验中,基于项目反应理论(item response theory, IRT)而构建的计算机自适应测验(computerized adaptive testing, CAT)逐渐取代传统笔试而成为主流 [1]。CAT的核心机制是通过被试当前的能力水平,以项目反应理论为指导,依赖于大型题库,智能化地通过计算机选取适合被试水平的题目并给予其作答,从而达到“量体裁衣”、“因人施测”的自适应化的测量方式 [2]。CAT的主要优点是其测试精度明显高于传统笔试。并且相比于传统笔试,计算机自适应测验因人施测的测验方式可以极大减少测试题量和提高测试效率,同时可以有效防止作弊等行为。CAT其多媒体式的测验方式,可以为被试提供更加全方位的测试方式,如影像,语音,图像等,并且呈现出更为公平,公正,高效的测验结果。目前CAT在各种大型测试中得到了广泛的应用,例如美国研究生入学考试(GRE),企业管理研究生入学考试(GMAT),注册护士执照考试(NCLEX-RN)等 [3]。
随着CAT的广泛使用,研究人员往往面临着一个新的问题,即题库中部分题目存在着过度曝光,过时等问题而不适于继续使用 [4]。因此为了满足CAT的实施,我们需要对题库中已经不再使用的题目进行删减或休眠,同时还要为题库补充新题,即对题库进行题目增补 [5]。这时往往需要对新题进行标定,才能将合适的题目归入到题库中 [6]。对新题的标定主要包括两方面的内容:一是估计新题的题目参数;二是将新题参数置于旧题的参数量尺上 [7]。
目前,相比于单维计算机自适应测验(unidimensional computerized adaptive testing, UCAT),多维计算机自适应测验(multidimensional computerized adaptive testing, MCAT)不仅在一次测验中可以反应被试在多个维度上的能力水平,还极大的提高了测验精度,提供了更多的被试信息,且可以自动平衡满足各个领域的测量要求 [8]。因此,MCAT兼具了多维项目反应理论和计算机自适应测验的优点,近年来得到国内外学者的巨大推崇 [9]。但其作为计算机自适应测验,仍然面临着题库更新的问题,那么仍需对其进行在线标定过程,以确定题目参数及新题插入位置。虽然UCAT的在线标定设计的研究有很多,但是对MCAT的在线标定设计的研究仍处于初步探索阶段。为了实现题库的更新,使得计算机自适应测验得以长久应用,在线标定是其重要环节。
针对MCAT的在线标定设计策略,通过基于不同项目参数的信息量对其进行研究具有重大意义。在线标定设计即新题的施测方式,其核心问题是如何将被试与新题合理搭配以优化题目参数标定的效率。Wainer和Mislevy最早提出了随机和自适应两种在线标定的设计方式 [4]。其中随机标定是从新题库中随机选取固定数量的新题,并且随机嵌入测验给被试作答。游晓峰等人研究发现随机设计中新题的作答次数越多,题目参数估计的越准确 [5]。虽然随机标定操作简单,但嵌入新题的难度与相邻题目的难度可能存在明显差异导致考生容易察觉,导致题目参数估计的不准确,同时也没有体现出计算机自适应的特点。自适应标定设计按照标准选取最能反映项目特征的被试,或者选取最适合被试作答的新题施测。其中最重要的是基于项目信息标准的最优设计。
基于项目信息标准的最优设计的基本思路是通过项目参数的信息量来反映参数估计误差。基于项目信息标准的最优设计包括D-优化,序贯D-优化,两点D-优化和贝叶斯D-优化以及优秀度指标和D-c设计等 [2]。D-优化设计通过最大化项目参数Fisher信息矩阵的行列式来最小化项目参数的广义协方差,它是以优化项目参数估计效率为目标的统计指标。在D-优化设计的基础上,Berger选取能力估计值与真值最接近的被试施测新题,即两点D-优化设计 [10] (two-point D-optimal design, D-Tp)。Chang和Lu基于最优能力准则,在不定长CAT中直接应用两点D-优化设计法,并按序贯的方式选取被试作答新题,称其为序贯D-优化设计 [11]。Hassan和Miller基于限制性最优设计的思想,提出按照在最优能力区间而不是最优设计点进行取样,称其为局部限制性最优设计 [12]。Ren等人认为从单点能力抽样被试不能产生稳定的参数估计值 [13],同时基于D-优化和A-优化视角将最优能力替换为最优作答概率,提出D-Tp1、D-Tp2和D-Tp3方法 [14]。Kang等人还从丰富被试信息的视角,利用被试的反应时信息,在联合反应和反应时模型下考察D-优化、A-优化和随机方法的表现 [15]。van der Linden和Ren在D-优化基础上根据当前考生p的能力估计值,选择使当前累加考生样本与之前累加考生样本相比,能提供项目参数Fisher信息增量最多的项目给考生p作答,提出贝叶斯版本的D-优化设计,称为D-VR设计 [16]。由于D-VR设计中到达嵌入位置的当前考生不一定是最优考生样本,He等人结合D-优化的思路对D-VR改进,他们以D-VR设计表示的最优考生在新题j上提供的信息增量为基准,通过衡量当前考生的能力相对于最优考生的能力在标定新题j上的优秀程度,从而选取优秀程度最高的题目给当前考生作答,将其称为优秀度指标 [17] (excellence degree, ED)方法。He和Chen还从项目参数估计误差的角度提出了D-c设计 [18]。
以往关于在线标定的研究很少关注MCAT中项目的标定,本文将D-最优设计和A-最优设计从单维推广到多维,并且基于Fisher信息的视角,评估不同在线标定设计的表现,并探讨样本大小和能力间的相关系数对不同标定设计的影响,为研究者在MCAT中选择最优设计策略提供参考。
本文剩余部分按如下方式进行组织:下一节将对方法进行描述(包括IRT模型、Fisher信息矩阵的推导以及D-最优和A-最优设计等)。第三节进行了MCAT和在线标定的模拟研究,第四节对其研究结果进行了总结,第五节讨论了本文的不足以及未来的研究方向。
2. 研究方法
2.1. 多维项目反应理论模型
多维项目反应理论模型是表征被试多维潜在能力水平与其在题目上正确作答概率关系的非线性数学函数,通过该模型可以对被试多个维度的潜在能力水平进行推断。多维项目反应理论模型还可被分为补偿模型和非补偿模型。补偿模型是指被试在某一维度上能力不足时可以由其他维度上的能力得到补偿。本文采用补偿的多维两参数logistic模型 [19]。对于一个二分得分的项目j,用补偿多维两参数logistic模型(M2PL)定义的能力向量为
的被试i正确回答该项目的概率见式(1):
(1)
其中,
是一个二进制随机变量取0或1。
表示被试i的p维能力向量。
表示与能力向量相对应的项目区分度向量,反应了被试正确作答项目时每个维度的相对重要性,其中
。
为项目j的难度参数,反应项目对于被试作答的一个难易程度。此处,当维数p等于1时,能力向量和区分度向量退化成一个数值,此时多维两参数logistic模型退化为单维的两参数logistic模型。
在多维计算机自适应测验和新题的在线标定过程中,多维项目反应理论模型中参数的已知情况是不同的。多维计算机自适应测验的目的是为了对被试的能力做出估计,评价被试的能力水平。其过程是在题库的已有题目中抽取合适的题目给予被试作答,所以题库中题目的参数是已知的,即项目区分度向量
和难度向量
已知,而被试的能力向量
是未知的,需要在测试中进行估计。然而在在线标定过程中,我们的目的是为了对题目的参数进行估计,并将新题与旧题至于同一尺度上。这一过程是通过分配能力已知的被试作答新题,从而获得新题的题目参数信息。因此在此过程中,需要基于被试的能力向量
(能力一般也是未知的,可以用估计值替代真值,或者加入先验信息),对新题参数进行估计和研究,而新题的题目参数
和
都是未知,需要我们进行估计和研究。
在本文中,我们主要讨论当被试的能力向量为二维向量时的情况,因此我们假设
,此时被试i的能力向量
,与之对应的项目区分度向量
,
。
依旧为项目j的难度参数,是一个一维数值。接下来本文所描述的模型和模拟实验研究都基于
的情况。
2.2. 自适应在线标定设计
在线标定设计的内涵即在被试作答过程中,在被试到达新题位置时,以一定的准则函数为依据,将待标定的新题合理地分配给被试作答,通过被试作答得到题目信息,达到准确有效地估计新题的未知参数的目的。
在多维计算机自适应测验中,在线标定新题的设计空间不是固定的,因此针对不同的被试,需要在未标定的新题中合理选择合适的新题给予被试作答。对此,van der Linden和Ren研究出UCAT下基于观测信息矩阵的在线标定设计 [16]。本文将在线标定设计中的D-最优和A-最优设计推广至适用于标定MCAT的情境。
2.2.1. Fisher信息量矩阵的推导
D-最优和A-最优设计基于Fisher信息矩阵,而Fisher信息量矩阵是由被试对新题作答所提供的Fisher信息量所构成的信息矩阵 [10]。令
表示被试i对第道新题j提供的Fisher信息量,则:
(2)
其中,
表示作答反应
的似然函数,
表示第j道新题的题目参数,
。在M2PL模型下,Fisher信息矩阵可以表示为:
(3)
下面给出
的计算公式,其余分量的计算可类比
的计算得到。
(4)
同理可计算得到其他分量:
由此可得到,在M2PL模型下,Fisher信息量矩阵的具体表达形式为:
(5)
在局部独立性的条件下,n名被试为题目j提供的Fisher信息量
等于每名被试提供的Fisher信息量之和,
,其中
是n名被试的能力向量矩阵,
和
表示第i名被试的能力的第1和第2维。
2.2.2. D-最优设计
假设被试i达到新题位置时,第j道新题已经被
名被试所作答。则基于Fisher信息量矩阵的D-最优设计应从新题集合中选择满足条件:
(6)
的新题k分配给被试作答 [16]。将旧题的Fisher信息量矩阵设为:
, (7)
结合(7)得:
. (8)
将式(8)代入式(6)得到因式分解后的D-最优设计的表达式为:
(9)
式(9)中,
表示第i名被试的能力向量,
表示nj名被试的能力向量矩阵,
表示前
名被试为j道新题提供的总的Fisher信息量。
表示被试i对第j道新题提供的Fisher信息量。
表示
省略第
行和第
列的子矩阵。D-最优设计的含义是被试i最有利于增加新题k的参数向量
的广义方差的倒数。
2.2.3. A-最优设计
A-最优设计应从新题集合中选择满足条件:
(10)
的新题k分配给被试作答 [16]。新题的Fisher信息量矩阵的逆矩阵为:
, (11)
其中新题和旧题的Fisher信息量矩阵和的逆矩阵的迹为:
, (12)
将式(11)和式(12)代入式(10)得:
. (13)
式(13)中,
为总的Fisher信息量矩阵的逆矩阵。
表示
省略第
行和第
列的子矩阵。
表示
省略第
行和第
列的子矩阵。A-最优设计的含义是被试i最有利于降低新题k的被估计参数向量
的方差之和。
2.2.4. 图形示例
为了对两种最优性准则的选题标准有一个初步印象,本文绘制了两个二维项目的曲面。本文主要考虑以下两名被试:
被试1:
,
被试2:
。
第一名被试的两维能力分别是−1和1,第二名被试的两维能力分别是0和2,两名被试的相同点是两维能力都相差2,不同点是被试1的两维能力以0为对称点,而被试2的能力以1为对称点。对于所
有的新题,将前
名被试对第j道新题提供的总的Fisher信息量
设置为
,可以较为显著的观察出不同最优设计的曲面的区别。
下图显示两名能力固定的被试在不同区分度下的D-最优设计的Fisher信息量,更高的曲面代表了更高的信息量。由于被试的能力一样,曲面的信息完全由公因数
决定,D-最优设计和A-最优设计之间的差异仅仅是由于它们将
映射到一维空间的不同方式造成的。
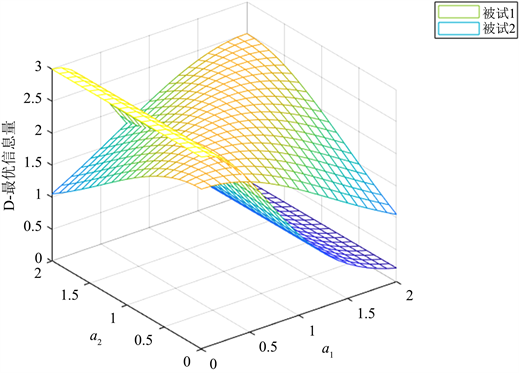
Figure 1. Parametric surface diagram of differentiation degree of D-optimal design for two examinees
图1. D-最优设计在两名被试上的区分度参数曲面图
图1的曲面说明了被试1在两维区分度相等时D-最优设计的信息量比较大,而在单一区分度较大而另一维区分度较小时,D-最优设计的信息量比较小。对于被试2,D-最优设计的信息量随着a1的增大而减小,而不随着a2的变化而变化。综合来看,被试1的曲面要比被试2的曲面高,说明被试1较被试2的D-最优设计的信息量大。图2显示了两名能力固定的被试在不同区分度下的A-最优设计的Fisher信息量。
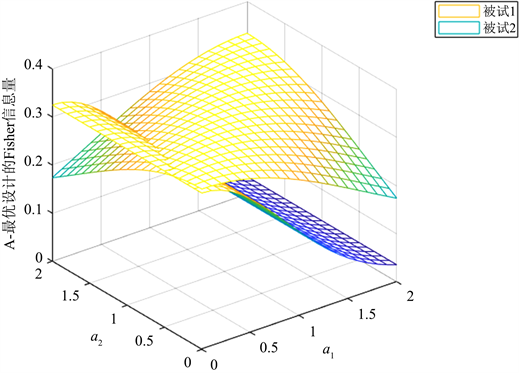
Figure 2. Parametric surface diagram of differentiation degree of A-optimal design for two examinees
图2. A-最优设计在两名被试上的区分度参数曲面图
图1的曲面和图2的曲面的相同点是形状相同,不同点是对比D-最优设计,在A-最优设计中被试1要比被试2的曲面高的更加明显,说明A-最优设计对被试1的偏好更强。
3. 模拟研究
本文考察基于可补偿的2PL模型上的MCAT,探究在线标定过程中的D-最优设计和A-最优设计两种新题分配策略,并且基于Fisher信息量比较不同样本量和能力间的相关系数对这两种策略的影响。
3.1. 数据的生成
本文参考Chen等人的方法,随机生成1000道基于M2PL模型的题目的题库 [7],同前文相同,我们将多维模型设定为二维进而对其适当简化,以方便我们研究。其中题目区分度参数
中的两个分量
分别从服从[0, 1.3]的对数正态分布,且在[0.25, 2]的区间之中抽取,题目难度参数
从服从标准正态分布的总体之中抽取。
本文模拟20道新题进行在线标定过程。其中,这20道新题的参数模拟同题库中旧题的参数模拟方式相同,题目区分度参数
服从对数正态分布,且在[0.2, 2.5]的区间之中抽取,题目难度参数
从服从标准正态分布的总体之中抽取。题库与新题的项目参数的描述性统计见表1。
借鉴以往MCAT的研究 [20],为了更为准确的选择新题进行在线标定过程,随机生成1000、2000、3000名被试,对应的每道新题分别由200、400、600名被试作答。其中,被试的二维能力向量
从服从均值为0,方差为1,相关系数分别为0.2、0.5、0.8的二维正态分布的总体中抽取。
3.2. 新题的在线标定过程
新题的在线标定过程包括对新题的标定和MCAT两个部分,两个部分同时进行,被试在进行MCAT的过程中同时植入新题,对新题进行标定。首先我们对被试的MCAT的过程进行描述。
CAT的模拟主要由五个部分组成,分别为题库、初始题目选择方法、能力估计方法、选题策略和终止规则 [21]。具体来说,1) 以M2PL模型为指导选择题库。2) 从题库中随机选取一道题目作为试题的初值。3) 采用极大似然估计方法对能力进行更新。4) 采用D-最优选题策略。5) 采用固定测验长度作为终止规则。
本文将旧题的题目参数和被试的能力值代入两维的2PL模型中,可以计算被试i对于题目j的作答概率
,作答概率
是一个介于0到1之间的数。同时我们在0到1内随机生成一个随机数
,若作答概率
大于这个随机数
,则认为被试i答对了题目j,被试的作答反应
则记为1。反之,若作答概率
小于这个随机数
,则认为被试i没有答对题目j,被试的作答反应
则记为0。随后依据上文所提到的D-最优选题策略,在题库中选择合适的题目给予被试作答。
同时,本文实验的主要目的是研究对新题的在线标定,因此在被试作答时需要同时植入新题,植入新题时,新题的分配方法通过上文提到的D-最优设计和A-最优设计分配。而在何时植入新题的问题上,本文参考van der Linden等人模拟实验的研究 [9],当每个被试作答5道新题时,我们在被试作答的所有题目的后八个位置中随机选取五个位置植入新题。在被试作答完成20道题目时,则停止作答,结束该被试的MCAT过程。
在本文的实验中,作答长度为20题,其中被试作答5道新题和15道旧题。本文设置了每道新题被作答次数的对比实验,假设每道新题分别被作答200,400,600次后则表示标定完成。所以在此设定自适应在线标定过程的终止规则,即每名被试作答5道新题,在这两种作答情况下,当每一道新题都被作答过200,400,600次后,则完成新题的在线标定过程,整个实验结束。
3.3. 评价标准
为了观察不同条件下两种在线标定设计策略的表现,我们需要构建信息函数,作为评价两种不同分配策略的准则。在此处我们构建4个信息函数,分别为被试为题目提供的总信息函数,以及题目参数向量
中三个题目参数分量各自的信息函数。信息量越大说明被试为新题提供的信息量越多,越有利于在线标定。
前文提到,Fisher信息量矩阵的含义是被试对新题作答后为新题所提供的总的信息量,因此Fisher信息量矩阵可以作为衡量被试为新题提供信息量的大小的准则。本文不单独探究每一位被试对新题提供的信息量,而是研究所有参与作答新题的被试所提供的总的信息量,因此本篇文章将所有作答新题的被试的Fisher信息量矩阵进行加和,从而得到一个总的Fisher信息量矩阵,这个总的Fisher信息量矩阵我们用
来表示,表示所有被试对新题所提供的Fisher信息量矩阵。
. (14)
其中i表示被试,n表示作答新题的被试总数,j表示第j道新题。我们对这个Fisher信息量矩阵取行列式,即可将其数值化从而便于我们进行比较。因此我们可以设新题的总信息函数
,其内涵是将作答新题的所有被试为新题提供的Fisher信息量矩阵相加,再取其行列式,则可以得到被试为新题提供的总的信息量。具体表达形式为:
. (15)
其中加和对矩阵中的每一个分量都单独相加,可以得到:
,
,
,
,
,
,
则
. (16)
杜文久等人曾提出,当作答被试的数量很大时,题目参数分布近似于正态分布,即
服从三维正态分布,其中各个题目参数均服从一维的正态分布 [22]。令:
. (17)
其中
表示Fisher信息量矩阵的伴随矩阵,
表示Fisher信息量矩阵的行列式的值,Fisher信息量矩阵的逆矩阵的对角线元素:
(18)
(19)
(20)
分别为题目参数
的方差。则:
(21)
(22)
(23)
由此可分别构造三个题目参数的信息函数
。
令:
(24)
(25)
(26)
三个题目参数的信息函数分别表示所有被试对新题作答为新题的三个题目参数所分别提供的信息量,该信息函数的数值越大,说明被试的作答为不同的题目参数所提供的信息越多。
由此,经过上文所构造的四个信息函数,根据被试的作答结果分别计算信息函数,从而来判断在不同实验条件下两种不同策略能够给予新题的信息量的大小。
4. 实验结果与分析
表2、表3和表4分别呈现了在能力相关性分别为0.2,0.5,0.8时,不同数量被试下D-最优设计和A-最优设计的总信息量
、区分度参数的信息量
和
以及难度参数的信息量
。本文将总信息量和题目参数的信息量分别除以相对应的作答人数,对平均后的信息量进行比较分析。

Table 2. The D-optimal and A-optimal Fisher information of different number of examinees when the ability correlation is 0.2
表2. 能力相关性为0.2时不同数量被试下D-最优和A-最优的Fisher信息量
Table 3. The D-optimal and A-optimal Fisher information of different number of examinees when the ability correlation is 0.5
表3. 能力相关性为0.5时不同数量被试下D-最优和A-最优的Fisher信息量
Table 4. The D-optimal and A-optimal Fisher information of different number of examinees when the ability correlation is 0.8
表4. 能力相关性为0.8时不同数量被试下D-最优和A-最优的Fisher信息量
将表2、表3和表4结合来看,D-最优设计和A-最优设计的总信息量
以及题目参数的信息量
、
和
并没有显著的差别,而作答新题的不同数量的被试以及能力系数的相关性对在线标定的信息量影响较大。随着作答人数的增多,无论哪种能力参数的相关性,平均后的总信息量都逐渐变大,而题目参数的信息量都是先减小后增大。随着两维能力相关系数的增大,总信息量和题目参数的信息量都逐渐变小,这是因为能力的相关性越强,被试提供给题目的Fisher信息量越小。当两维能力的相关性等于0.2或0.5时,区分度参数和难度参数的Fisher信息量并没有显著差别,随着作答人数的增多,题目参数的信息量都呈现先减少后增加的趋势。而当两维能力的相关性等于0.8时,总信息量和题目参数的信息量几乎不随着作答人数的变化而变化。
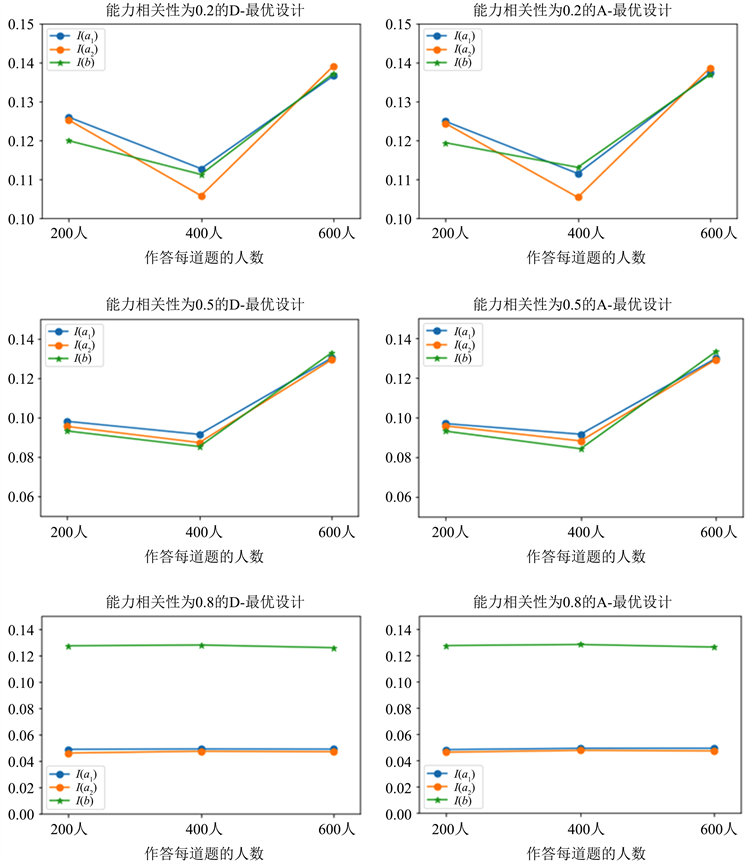
Figure 3. Information values foritem parameters under different sample size and correlations in ability component generated by the D- and A-optimal designs
图3. 不同样本量和能力相关性条件下D-最优和A-最优设计的题目参数信息量
为了更直观的看出不同的能力相关性和作答人数对两个最优设计的影响,本文绘制了D-最优设计和A-最优设计在不同的能力相关性和作答人数的题目参数信息量的图形。
图3展示了在相关性为0.2、0.5和0.8,每道新题分别由200人、400人和600人作答时,在D-最优设计和A-最优设计下被试为新题提供的两维区分度参数与难度参数的信息量。对于最优设计对题目参数信息量的影响,图中可以看出D-最优设计和A-最优设计在能力相关性为0.2,作答人数为400时,D-最优设计的
稍大于
,而A-最优设计则相反。对于能力的相关性对题目参数信息量的影响,随着能力相关性的增大,题目参数信息量显著降低。对于新题的作答人数对题目参数信息量的影响,能力相关性为0.8时,在不同作答人数的情况新题的下,题目参数的信息量几乎持平,且
显著大于
和
。
5. 结论与讨论
理论上,本文将D-最优设计和A-最优设计从单维推广到了二维。首先可以弥补UCAT只能考察被试的单维能力以及题目的单一区分度,其次还为未来对二维以上的在线标定的MCAT提供了理论依据。对于其他相关文献基本都是以题目的偏差和均方误差作为在线标定的评价指标,本文基于Fisher信息量进行在线标定研究,因此本文对评价指标总信息量
、题目参数信息量
和
以及难度参数
的Fisher信息量矩阵都进行了推导。
实践上,本文以Fisher信息量为评价指标,在不同实验条件下对D-最优设计和A-最优设计进行评价。首先本文对题库、新题以及被试进行了模拟,使用极大似然估计方法得到能力的估计值。然后通过模拟MCAT以及在线标定的过程来完成对新题的在线标定。最后以总信息量
、题目参数信息量
和
为评价指标,在不同能力的相关性以及样本量的实验条件下,研究不同样本量和能力间的相关系数对D-最优设计和A-最优设计的影响。
并且本文还可以得出以下结论:1) 随着作答人数的增多,平均后的总信息量逐渐增大,当能力间的相关性为0.2和0.5时,平均后的题目参数的信息量呈现先减少后增加的趋势;而当能力间的相关性为0.8时,平均后的题目参数的信息量几乎不会改变。2) 随着能力间相关性的增大,平均后的总信息量和题目参数的信息量都呈现逐渐减少的趋势。3) 当能力间的相关性太大时,作答新题的人数对Fisher信息量几乎没有影响。
对于第一道题目的选择本文采用随机方法,由于题目的初值一定程度上会影响到后面的CAT过程,从而对新题的在线标定过程产生影响。张雪琴(2021)使用两阶段方法来确定题目的初值,一定程度上减少了它对新题标定的影响。因此在后续的研究中,将两阶段方法或其他方法对第一道题目进行选择是必要的。
本文研究的结果表明在不同样本量和能力间的相关系数的条件下,D-最优和A-最优设计的结果相差很小。这可能是由于题目长度较小导致的,未来可以在不同实验条件下探究D-最优和A-最优设计的区别,或者是使用其他评价指标,如均方差、KL信息等对新题的在线标定进行评价,这对于探究两种最优设计之间的联系与区别是十分必要的。
基金项目
本研究获得国家自然科学基金资助,项目编号为32000778;和南京信息工程大学科研启动经费资助,项目编号为2018r041。
NOTES
*通讯作者。